目标检测:RCNN->Fast RCNN->Faster RCNN
一、RCNN
RCNN(Region with CNN feature)是深度卷积神经网络应用于目标检测问题的一个里程碑的飞跃。2014年提出的,之前都是传统的检测算法。
算法步骤:

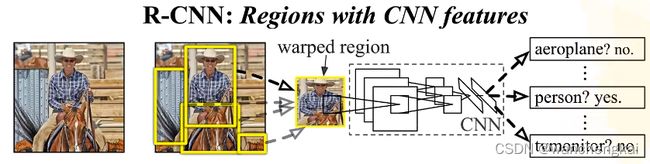
1、候选区域选择:区域建议Region Proposal是一种传统的区域提取方法,基于启发式的区域提取方法,用的方法是ss,查看现有的小区域,合并两个最有可能的区域,重复此步骤,直到图像合并为一个区域,最后输出候选区域。然后将根据建议提取的目标图像标准化,作为CNN的标准输入可以看作窗口通过滑动获得潜在的目标图像,在RCNN中一般Candidate选项为1k~2k个即可,即可理解为将图片划分成1k~2k个网格,之后再对网格进行特征提取或卷积操作,这根据RCNN类算法下的分支来决定。然后基于就建议提取的目标图像将其标准化为CNN的标准输入。

2、CNN特征提取:所有的候选区域都缩放到一个统一大小,进行CNN的特征提取(就是分类网络把全连接之后的输出层去掉),获得各自固定维度输出特征向量。
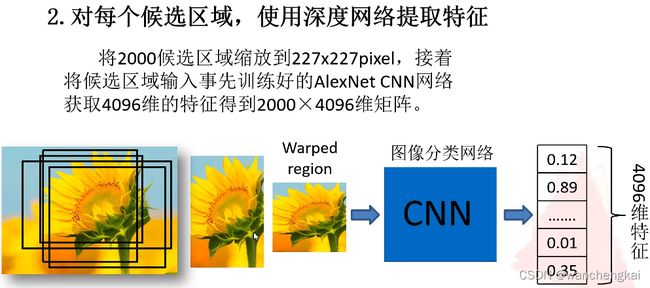
3、分类:对前一步的输出向量进行分类(分类器需要根据特征进行训练)。在分类器的选择中有支持向量机SVM,Softmax等等。SVM是一个二分类的分类器,每一个类别有一个前景背景二分类,多少个类别就多少个SVM分类器。


对每一个类别进行非极大值抑制:寻找得分最高的目标,计算和其他目标的IOU(交并比),大于给定阈值的删除,直到所有框遍历完。

4、边界回归:通过边界回归框回归(缩写为bbox)获得精确的区域信息。目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要Bounding box regression步骤。

RCNN的缺点:
训练时间长:主要原因是分阶段多次训练,而且对于每个region proposal都要单独计算一次feature map,过多的重复的特征提取,导致整体的时间变长。
占用空间大:主要原因是每个region proposal的feature map都要写入硬盘中保存,以供后续的步骤使用。
multi-stage:文章中提出的模型包括多个模块,每个模块都是相互独立的,训练也是分开的。
测试时间长:由于不共享计算,所以对于test image,也要为每个proposal单独计算一次feature map,因此测试时间也很长。

二、Fast RCNN
Fast RCNN的工作流程:

1、 选择性搜索Selective Search(SS)在图片中获得大约2k个候选框。所使用到的候选区域生成方法与RCNN相同,使用的方法都是Selective Search(SS)。
2、使用卷积网络提取图片特征,得到整个图像的特征图。网络只提取一次特征图。
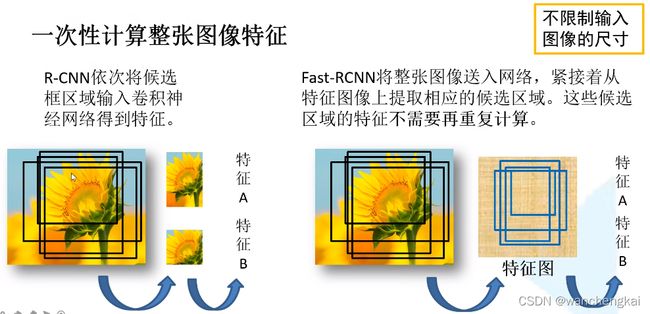
3、将SS算法生成的候选框投影到特征图上获得候选框的特征图(可以理解为将feature map映射回原图像位置), 在最后一次卷积之前,使用 RoI pooling层缩放到统一的7*7的特征图,再展平通过全连接得到预测结果
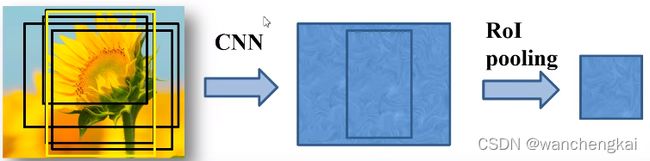
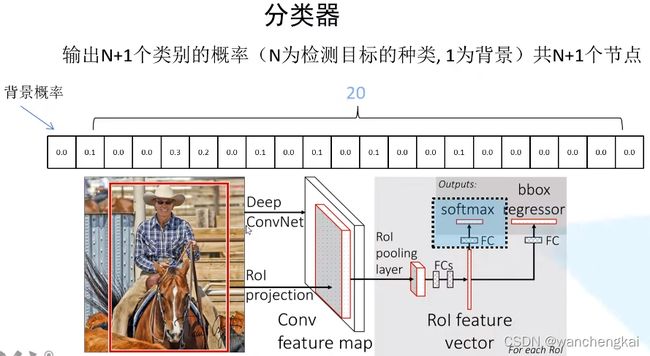
RoI pooling层缩放到统一大小,再展平通过两层全连接层得到ROI feature vector。之后并联两个FC层,一个用于目标概率的预测(分类器),另一个用于边界框回归参数的预测(边界框回归器)。
分类器可以输出N+1个类别的概率。这是经过softmax处理之后的,满足归一。
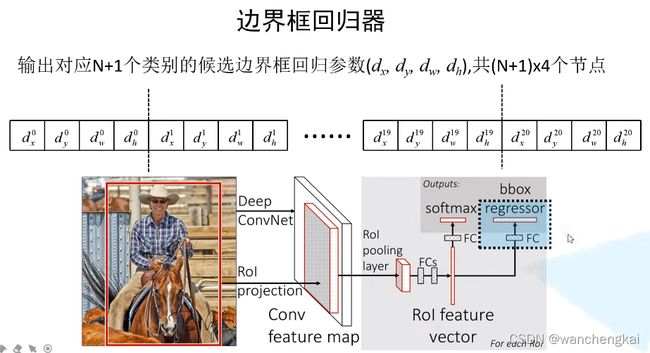
界框回归器输出N+I个类别的候选框回归参数(dx,dy,dw,dh),共(N+1)*4个节点。

训练样本:
训练时并不是用SS算法输出的所有候选区域,SS算法得到大约2000个候选区域,训练时只用其中的一小部分。而且还分成正样本和负样本。正样本就是候选框中确实存在目标的样本,负样本就是框中是背景。如果正负样本不平衡有可能会使训练结果产生偏移。原论文中从2000个候选框选出64个作为样本,一部分时正样本,一部分时负样本。与真实的位置IOU>0.5,视为正样本。与所有的真实目标的IOU的最大值(可能有很多目标)在[0.1,0.5)之间是为负样本。
Fast RCNN的损失:分类损失,回归损失

Fast RCNN较之前的RCNN相比,有三个方面得到了提升:
1. 卷积不再是对每个Region Proposal进行,而是直接对整张图像,速度得到了提升。 RCNN算法与图像内的大量候选框重叠,导致提取特征操作中的大量冗余。 而Fast RCNN很好的解决了这一问题。
2. 用SoftMax代替原来的SVM分类器。
3. 用Roi Pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把Region Proposal作为输入。
4.将特征提取,分类,边界框回归揉合在一个网络中完成。

Fast RCNN仍存在的不足:
1.由于使用的Selective Search选择性搜索,这一过程十分耗费时间。
2.由于使用Selective Search来预先提取候选区域,Fast RCNN并未实现真正意义上端到端的训练模式。
三、Faster RCNN
对于Faster RCNN来讲,与RCNN和Fast RCNN最大的区别就是,目标检测所需要的四个步骤,即候选区域生成,特征提取,分类器分类,回归器回归,这四步全都交给深度神经网络来做,并且全部运行在 GPU上,这大大提高了操作的效率。
Faster RCNN可以说是由两个模块组成的:区域生成网络RPN候选框提取模块+Fast RCNN检测模块。
Faster RCNN的工作流程:

Faster RCNN与Fast RCNN的区别就在于采用RPN网络来生成候选框
RPN网络介绍:

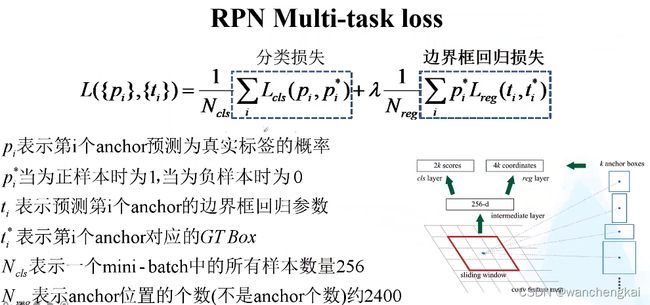
特征图上每个窗口中心点,映射到原图位置,生成长度256的向量(长度由特征图的通道数决定),再通过两个FC,分别计算出2k个目标概率参数(分别为背景和前景的概率,只是前景,没有分类)和4k个边界框位置参数。其中k是anchor box的个数。
每个位置在原图上分别有三种比例和三种尺度(面积)共9个anchor
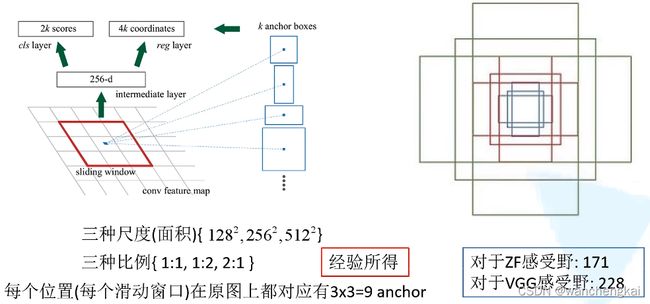
通过一个小的感受野去预测一个大的目标也是可能的,有时看到物体的一部分也能大概知道物体所在区域的位置。
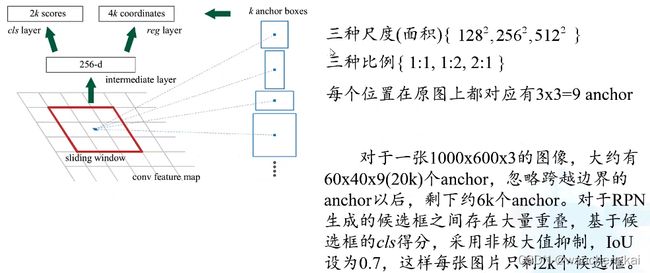
Anchor和proposal是不同的,proposal是anchor经过回归参数修正后的。
RPN的实现:采用3*3conv,stride=1,padding = 1,深度和原来相同。所以,运算后特征矩阵的shape和原来特征图是一样的(相当于每个位置是一个256-d的向量)。再在后面并联两个1*1的卷积层来实现类别预测和位置回归预测。
类别预测卷积核1*1*2k,位置回归预测卷积核1*1*4k
RPN的损失函数:


本文参考了视频:https://www.bilibili.com/video/BV1af4y1m7iL?p=1