数据结构(二)——单向有头链表的原理以及简单应用
本章主要叙述数据结构中单向有头链表的原理,在将原理说明白之后,后边会给出增删改查的实例代码和代码讲解。
文章目录
- 一、单向有头链表的原理
- 二、基本功能
-
- 1、创建和摧毁链表
- 2、按位置插入元素
- 3、按元素大小插入元素
- 4、删除元素
- 5、一些小功能(判断是否为空,可视化)
- 三、主函数和`.h`文件
一、单向有头链表的原理
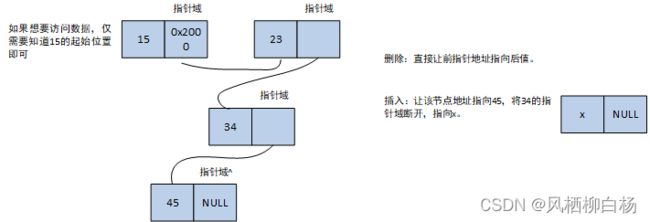
链式存储的数据结构的精髓就是结构体嵌套。链表的一个节点通常由一个数据和一个地址组成,而前边节点的地址往往指向后边的数据节点。
它的形状就是这样,如图所示:
有头链表和无头链表的区别就是,有头链表并不是直接从第一个节点开始的。我们取得的地址往往是指向链表的头结点,之后做的所有操作都是通过这个头结点进行的。下面给出有头链表和无头链表的区别:
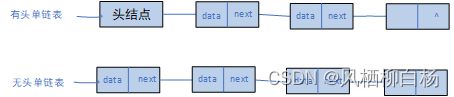
他们的区别就是,有头结点的首地址不会改变。无头单链表插入的时候首地址需要改变。
常见面试问题:请在带头节点的单链表中实现某功能,请在无头结点的单链表中实现某功能。
我们在C语言中定义一个有头单链表是这样的:
typedef struct node_st
{
datatype data;
struct node_st *next;
}list;
下面来看一下,如何在C语言代码中利用无头单链表实现增删改查。
二、基本功能
1、创建和摧毁链表
(1)创建链表其实只需要创建一个头结点即可,只有一个节点的链表也叫链表;
list *list_create()
{
list *me;
me = malloc(sizeof(*me));
if (NULL == me)
return NULL;
me->next = NULL;
return me;
}
(2)但是摧毁单链表的时候,我们需要把链表的每一个节点都摧毁,不然的话会造成内存泄漏。
void list_destroy(list *me)
{
list *node, *next;
for (node = me->next; node != NULL; node=next)
{
next = node->next
free(node);
}
free(me);
return ;
}
2、按位置插入元素
一般情况下,我们不会按位置向链表中插入元素,这样的情况仅可以被当做练手。
这里我自己定义的API为:int list_insert_at(list *me, int i, datatype *data)
i是我想要插入元素的位置,data是想要插入元素的地址,me就是传入链表的头结点地址。
整个函数这样实现:
int list_insert_at(list *me, int i, datatype *data)
{
int j = 0;
list *node = me, *newnode;
if(i <0)
return -1; //return -EINVAL;
while (j < i && node != NULL)
{
node = node->next;
j++;
}
if (node != NULL)
{
newnode = malloc(sizeof(*newnode));
if (NULL == newnode)
return -2;
newnode->data = *data;
newnode->next = node->next; // 先把node原有指向给newnode
node->next = newnode; // 再把node的指向变成newnode
return 0;
}
else
return -3;
}
需要新建两个链表,一个链表(node)用来记录插入元素位置的前驱,另一个链表(newnode)就是我们想要插入的新节点。node的地址应当从原来的指向变为指向newnode,而在此之前应当把node原来的指向给newnode->next。
3、按元素大小插入元素
按元素大小插入元素的原理就是比大小;
int list_order_insert(list *me, datatype *data) // 比较常见
{
list *p = me, *q;
while (p->next && p->next->data < *data)
p = p->next;
q = malloc(sizeof(*q))
if (q == NULL)
return -1;
q->data = *data;
q->next = p->next;
p->next = q;
return 0;
}
这里一定要注意一点,while语句中的判断顺序不能改变,只能先判断p->next不为空,后判断数据。不然容易报错。
4、删除元素
删除元素与插入元素的思路一样,首先要找到想要删除元素的位置的前一位,因为我们需要找到这个位置的前一个的地址。并把这个地址指向下下一位。代码是这样的:
int list_delete(list *me, datatype *data)
{
list *p = me, *q;
while (p->next && p->next->data != data)
p = p->next;
if (p->next == NULL)
return -1;
else
{
q = p->next;
p->next = q->next;
free(q);
q = NULL;
}
}
找到后边的位置之后,直接把这个节点释放掉,在把这个节点删除掉之后,切记一定要把这个节点的前驱和后继一一对应。
5、一些小功能(判断是否为空,可视化)
(1)判断链表是否为空思路:如果一个带头单链表为空,那么这个链表的头结点指向的位置应当为空。
int list_isempty(list *me)
{
if (me->next == NULL)
return 0;
return 1;
}
(2)链表可视化 思路:可视化应当从头结点的下一个节点开始,直到空节点为止。那么我们可以这样进行处理:
void list_display(list *me)
{
list *node = me->next;
if (list_isempty(me) == 0)
return ;
while (node != NULL)
{
printf(“%d ”, node->data);
node = node->next;
}
printf(“\n”);
return ;
}
三、主函数和.h文件
所有的函数都已经写完了,那么主函数的调用就很简单了。
#include "head.h"
#include .h文件中一般包含函数的声明和链表的定义,那么我们可以在其中这样写(.h文件中函数声明的形参可以包含变量名,也可以不包含):
#ifdef LIST_H__
#define LIST_H__
typedef int datatype;
typedef Struct node_st
{
datatype data;
struct node_st *next;
}list;
list *List_create(); // 创造链表
Int List_insert_at(list *, int I, datatype *); // 按位置插入,不太具有实际生产作用,仅做练习使用
int List_order_insert(list *, datatype *); // 按顺序插入,不需要指定位置
int List_delete_at(list *, int I, datatype *); // 根据位置删除,并带回删除的值
int List_delete(list *, datatype *); // 根据当前某个值进行删除
int List_isempty(list *); // 是否为空
void list_destroy(list *);
#endif