Pointnet与Pointnet++论文笔记
Pointnet与Pointnet++论文笔记
近期由于课题需要,研读了Pointnet系列文章,在此总结个人心得,并结合了部分博客进行阐述,不足之处希望各位批评指正,也欢迎各位同学来进行学习交流。
论文地址:https://arxiv.org/abs/1612.00593(pointnet)
论文地址:https://arxiv.org/abs/1706.02413 (pointnet++)
1. 前言
图像数据在计算机中的表示通常编码了像素点之间的空间关系,与此不同的是,点云数据是由一组无序的点所构成一个集合。因此,在使用图像识别任务的深度学习模型处理点云数据之前,需要对点云数据进行一些处理。目前采用的方式主要有两种:
- 将点云数据渲染到二维平面
将点云投射到不同方向的二维图像上,并应用标准的二维CNN来提取特征。将从不同图像中学习到的特征通过视图池化层聚合到一个全局特征,然后利用该全局特征对对象进行分类。虽然基于视图的方法在分类任务中可以获得较高的精度,但该方法应用于点云分割存在难度,即点云很难将每个点分类到特定的类别。比较典型的算法有MV3D和AVOD。 - 将点云数据转换到voxel grid
通过分割三维空间,引入空间依赖关系到点云数据中,再使用3D卷积等方式来进行处理。然而,点云是稀疏的,并且使用三维网格来表示点云是很浪费的。此外,考虑到体积数据的高内存和计算成本,三维网格的分辨率通常很低,这可能会导致量化伪影。因此,利用体积方法来处理大规模的点云是有问题的。
不同于以上两种方法对点云数据先预处理再使用的方式,PointNet系列论文提出了直接在点云数据上应用深度学习模型的方法。
2. 初识点云
2.1 3D数据的4种表现形式

三维数据的表述形式一般分为四种:
- 点云:由N个D维的点组成,当这个D=3的时候一般代表着(x,y,z)的坐标,当然也可以包括一些法向量、强度等别的特征。
- Mesh:由三角面片和正方形面片组成。
- 体素:由三维栅格将物体用0和1表征。
- 多角度的RGB图像或者RGB-D图像
2.2 为什么使用点云
点云有很多优势,也越来越受到雷达、自动驾驶等的青睐。
-
点云更接近于设备的原始表征(即雷达扫描物体直接产生点云)
-
点云的表达方式更加简单,一个物体仅用一个N × D的矩阵表示(其中N表示目标点云的个数,D表示维度,一般D=3)
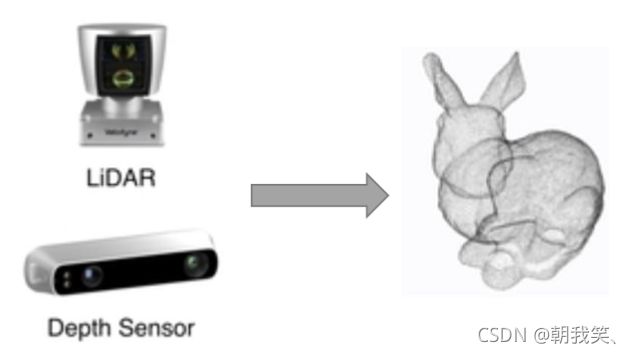
3. Pointnet设计思想
设计网络之前,我们需要了解Pointnet的相关特性,点云主要有无序性以及仿射不变性等。
3.1 无序性
由对称函数到PointNet(vanilla)
点云实际上拥有无序性的特点,简单地说就是点的排序不影响物体的性质,如下图所示:
即当一个N × D 在N的维度上随意的打乱之后,其表述的其实是同一个物体。因此针对点云的无序性,作者提出的解决办法是利用一个对称函数来解决。常见的对称函数有Sum、Max以及求平均等。该论文使用的是MAX Pooling。
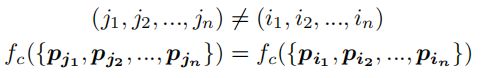
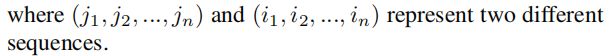
我们可利用max函数设计一个简单的点云网络

这样做的话会导致每个点损失的特征太多了,输出的全局特征仅仅继承了三个坐标轴上最大的那个特征,因此需要先将点云上的每一个点映射到一个高维的冗余空间(例如1024维),在一个高维空间提取全局特征之后,再映射到低维。(我们可以将MLP(多层感知机)简单的理解为一个全连接网络)
3.2 基于点云的旋转不变性
点云的旋转不变性指的是,给予一个点云一个旋转,所有的x , y , z 坐标都变了,但是代表的还是同一个物体。因此对于普通的PointNet(vanilla),如果先后输入同一个但是经过不同旋转角度的物体,它可能不能很好地将其识别出来。在论文中的方法是新引入了一个T-Net网络(由transformer引进,该网络在Pointnet++中去除了,实验证明去除变换网络后,该网络仍然具有令人满意的性能)去学习点云的旋转,将物体校准,剩下来的PointNet(vanilla)只需要对校准后的物体进行分类或者分割即可。

由图可以看出,由于点云的旋转非常的简单,只需要对一个N × D的点云矩阵乘以一个D × D的旋转矩阵即可,因此对输入点云学习一个3 × 3 的矩阵,即可将其矫正;同样的将点云映射到K维的冗余空间后,再对K维的点云特征做一次校对,只不过这次校对需要引入一个正则化惩罚项,希望其尽可能接近于一个正交矩阵(主要作用是便于计算机的计算)。
3.3 网络总体结构
满足了以上两个点云的特性之后,就可以设计出PointNet的网络结构

具体来说,对于每一个N × 3 N的点云输入,网络先通过一个T-Net将其在空间上对齐,再通过MLP将其映射到64维的空间上,再进行对齐,最后映射到1024维的空间上。这时对于每一个点,都有一个1024维的向量表征,此时引入最大池化操作,将1024维所有通道上都只保留最大的那一个,这样得到的1 × 1024的向量就是N个点云的全局特征。
对于分类问题,直接将这个全局特征经过MLP,由softmax函数输出每一类的分数(即概率);如果是分割问题,由于需要输出的是逐点的类别,需要对全局特征与局部特征进行融合,最后通过MLP,输出逐点的分类概率。
4.Pointnet++
4.1 pointnet的缺陷
PointNet的缺点——Pointnet设计只考虑了全局特性,而缺失局部特征。从很多实验结果都可以看出,PointNet对于场景的分割效果十分一般,由于其网络直接暴力地将所有的点最大池化为了一个全局特征,因此局部点与点之间的联系并没有被网络学习到。在分类和物体的Part Segmentation中,这样的问题还可以通过中心化物体的坐标轴部分地解决,但在场景分割中,这就导致效果十分一般了。在此基础上,原论文作者的团队对于Pointnet进行了改进,Pointnet++由此诞生。
4.2 Multi-Scale PointNet
作者在第二代PointNet中主要借鉴了CNN的多层感受野的思想。CNN通过分层不断地使用卷积核扫描图像上的像素并做内积,使得越到后面的特征图感受野越大,同时每个像素包含的信息也越多。而PointNet++就是仿照了这样的结构,具体如下:
其先通过在整个点云的局部采样并划一个范围,将里面的点作为局部的特征,用PointNet进行一次特征的提取。因此,通过了多次这样的操作以后,原本的点的个数变得越来越少,而每个点都是有上一层更多的点通过PointNet提取出来的局部特征,也就是每个点包含的信息变多了。文章将这样的一个层成为Set Abstraction。

4.3 Set Abstraction的实现细节
一个Set Abstraction主要由三部分组成:
- Sampling:利用FPS(最远点采样)随机采样点
- Grouping:利用Ball Query划一个R为半径的圈,将每个圈里面的点云作为一簇
- PointNet: 对Sampling+Grouping以后的点云进行局部的全局特征提取
4.4 方法缺陷与改进
通过上述方法实现的PointNet++虽然在点云上的分类和分割效果有了一定的提升,但是作者发现,其在点云的缺失鲁邦性上似乎变得更差了。其原因是因为激光收集点云的时候总是在近的地方密集,在远的地方稀疏,因此当Sampling和Grouping的操作在稀疏的地方进行的时候,一个点可能代表了很多很多的局部特征,因此一旦缺失,网络的性能就会极大的受影响,如下图所示


当点云的个数缺失到20%的时候,PointNet++的性能甚至还不如PointNet。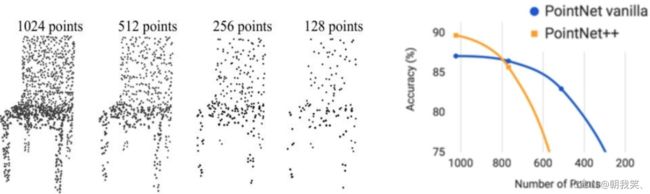
作者通过引入不同分辨率/尺度的Grouping去对局部做PointNet,求局部的全局特征来进行改进,最后再将不同尺度的特征拼接起来;同时也通过在训练的时候随机删除一部分的点来增加模型的缺失鲁棒性。

4.5 Pointnet++的总体架构与改进结果
4.5.1 Pointnet++总体架构
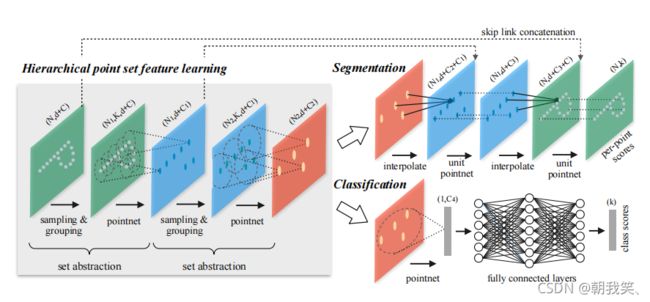
4.5.2 Pointnet++改进结果
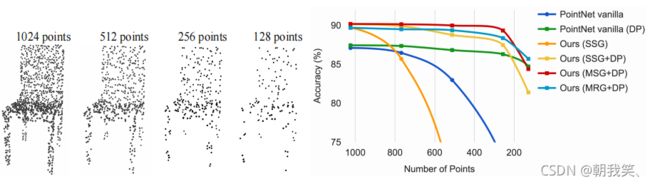
最终结果显示,PointNet++在点缺失到80%左右仍然具有良好的表现。
5.总结
Pointnet是直接利用3D数据进行深度学习处理的开山之作,而Pointnet++在Pointnet的缺乏局部特征基础上所作出的改进。然而,PointNet++仍然单独处理局部点集中的每个点,并且不提取点与其邻居点之间的关系,如距离和边缘向量。因此,目前有很多论文在提取点以及其邻近点之间做了改进,感兴趣的同学可以阅读相关文献,在此不细说。
下一阶段准备对于Pointnet++进行复现,等具体实现后再考虑要不要发文章。
参考:
[1]https://blog.csdn.net/weixin_39373480/article/details/88878629
[2]https://blog.csdn.net/sinat_17456165/article/details/106596332