YOLO v1 原理深度讲解
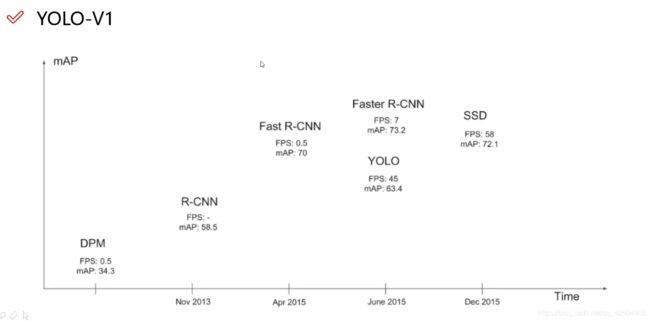
首先来看,yolo算法是一个one-stage的算法,即一步直达,所以速度非常快,适合做实时检测。缺点就是没有那么精确。
有一个概念MAP:这个指标是为了去衡量综合的检测效果。
这里牵扯到另一个概念就是召回率:

关于预测结果我们可以分为四类:
TP(真阳性) 预测为真的样本中确实为真的数量。
FP(假阳性) 预测为真的样本中确实为假的数量。
FN(假阴性) 预测为假的样本中确实为真的数量。
TN(真阴性) 预测为假的样本中确实为假的数量。
举个例子来说明
预测某些病人有没有得癌症。
假设有100个样本,真实情况是有10个得癌症的,通过预测函数遇到到了有12个得了癌症,其中有8个是真实得癌症的。
这种情况下:
TP=8
FP=12-8=4
FN=10-8=2
TN=(100-12)-2=86
所以准确率:
准确率 Accuracy
正确预测为1,正确预测为0的样本比率,公式为:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P7o943a7-1621343647831)(https://math.jianshu.com/math?formula=\frac%7BTP%2BTN%7D%7BALL%7D)]](http://img.e-com-net.com/image/info8/9d311757df9d44a9ac464ae79e2c0cdb.jpg)
上例中准确率为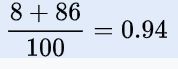
查准率 Precision
查准率是指在所有预测为1的样本中预测正确的比率,公式为:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eez59Otu-1621343647833)(https://math.jianshu.com/math?formula=\frac%7BTP%7D%7BTP%2BFP%7D)]{: id=](http://img.e-com-net.com/image/info8/379b41e80b6d4c47b4158df066c739b3.jpg)
上例中查准率为 ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7CGsfXRv-1621343647835)(https://math.jianshu.com/math?formula=\frac%7B8%7D%7B8%2B4%7D%3D0.667)]{: id=](http://img.e-com-net.com/image/info8/4096ddbd2ece4212ab80fb0d7f2803ad.jpg)
召回率 Recall
召回率是指在所有真正为1的样本中预测正确的比率,公式为:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YxBU5XEs-1621343647835)(https://math.jianshu.com/math?formula=\frac%7BTP%7D%7BTP%2BFN%7D)]{: id=](http://img.e-com-net.com/image/info8/26f752decf92449e88e944c77fe3d631.jpg)
上例中召回率为 ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kJsNJZUC-1621343647836)(https://math.jianshu.com/math?formula=\frac%7B8%7D%7B8%2B2%7D%3D0.8)]{: id=](http://img.e-com-net.com/image/info8/3d7711d6bd744b4ba37079a992a70db2.jpg)
查准率和召回率的关系

换句话说,召回率recall就是看每一个物体是不是都检测到了,查准率(也就是精度)就是说对于每一个我们需要检测的东西,检测的好不好
我们经常会看到一个叫做PR曲线图的概念
其实pr图就是精度Precision和召回率Recall之间关系变化的图像

一般来说精度和召回率呈反相关关系。同时还会受置信度(阈值)的影响。而MAP就是在所有阈值条件下的一个平均情况。

v1的核心思想其实就是对于一个输入的图像,首先用s*s的小网格进行分割,然后对于每个小网格都生成两个候选框(先验框)(我们可以理解成经验值,即预先设置好两种分类的大体大小,生成两个形状的网格,当然对于很多物体的种类来说两个先验框肯定不够用,但yolo v1的论文思想就是先设置两个候选框)从中选择一种更符合真实物体形状的框,(如何选择?这里就分别计算每个框和真实物体框的IOU,取大者)然后再去对先验框的大小bx,by,bw,bh进行微调,所以这就是为什么作者说我们把检测的问题转换成了回归的问题。
对于每个被检测的物体,yolo v1的思想就是每个物体会产生一个中心点,然后中心点所落在的那个小格子就负责这个物体的预测。
在yolo v1中,我们每一个位置都要进行预测,所以会出现很多的候选框,这里yolo v1的改进就是他除了预测物体的bx by bh bw之外还会对每个候选框预测一个置信度(confidence),用来表示这个框内有没有我们需要检测的物体,如果有那么保留bx by bw bh,如果没有,那么bx by bw bh都失去了意义。
这里注意一点:x y w h不是具体的坐标值,都是经过归一化操作或经sigmoid函数之后限定在0-1里面的一个相对坐标值。当前候选框相对于整个图像的比例。
所以我们通过给置信度设置一个阈值来过滤掉一些置信度低的候选框,从而简化我们的计算。仅仅对高于我们设置的阈值的候选框进行二选一。
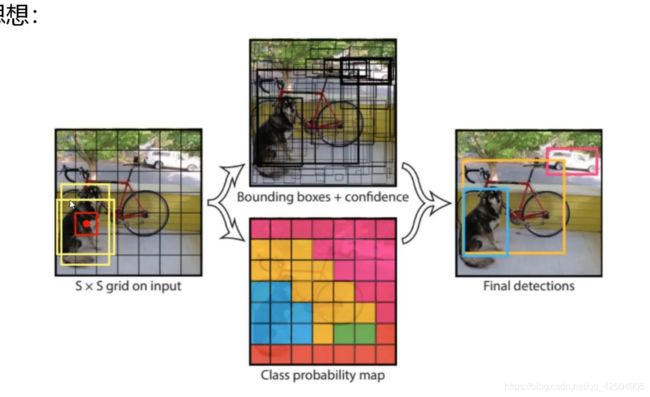
在v1版本中,输入图像大小被限定在了448x448,当然也可以输入其他尺寸的图片,但都要经reshape把它变成448x448在进行训练。
为什么图片尺寸是固定的呢:因为在v1版本中包含FC全连接层,全连接层需要w权重参数矩阵和b偏置参数矩阵,比如全连接层有1024个特征,前一层卷积层输出2048个特征,那么w就是一个[2048x1024]的矩阵,b就是1024个参数。而wb在训练的过程中参数是不能每次变化的,所以在v1版本中,只能输入固定的图片尺寸大小。
下图是yolov1的网络架构:
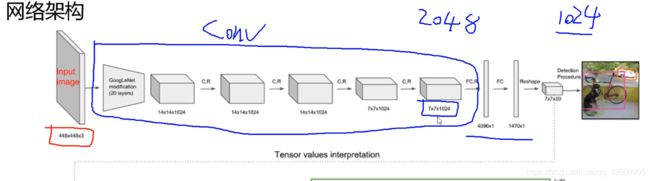
其实就是输入图像然后经一系列卷积和池化操作,最后得到了一个7x7x1024的特征图。在经两层池化,得到了一个7x7x30的输出。
关于7x7x30的输出:
代表我们最后的输出图像划分成了7x7的网格(grid cell)然后每个网格含有30个参数值。
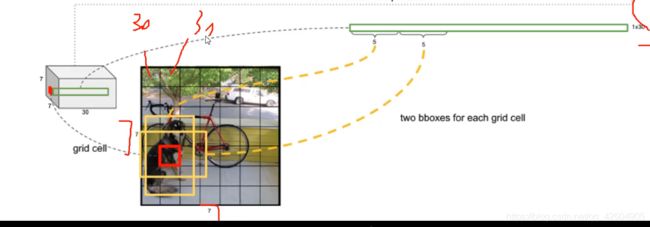
30个参数值分别都是什么呢,由于我们一个格子生成两个候选框,bounding box1:x1,y1,w1,h1,confidnece1,bounding box2:x2,y2,w2,h2,confidence2。再加上我们使用的数据集共可以进行20个类别的预测,所以5+5+20=30。
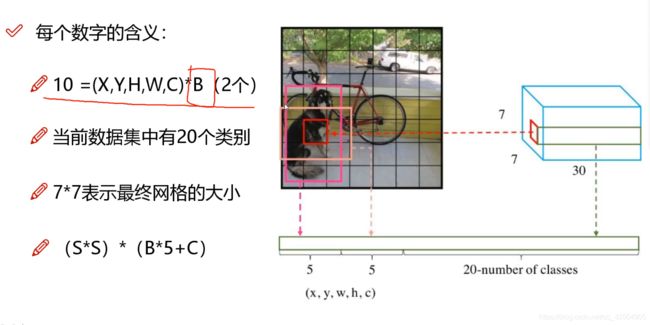
最终预测的结果数就是SxSx(Bx(4+1)+Class)
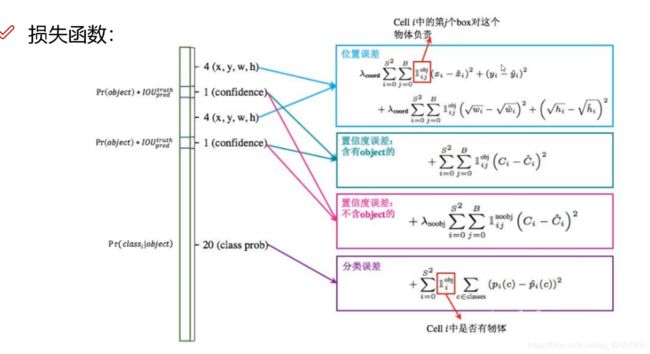
关于损失函数:
yolo v1的缺点:
1.每个网格(grid cell)只能检测一个物体,重合在一起的东西很难进行检测。
2.对于小物体的检测不是那么友好(因为先验框大小的缘故)