【三维目标检测】PointRCNN(二)
PointRCNN数据和源码配置过程请参考上一篇博文:【三维目标检测】PointRCNN(一)_Coding的叶子的博客-CSDN博客。本文主要详细介绍PointRCNN网络结构及其运行中间状态。
PointRCNN是用于点云三维目标检测模型算法,发表在CVPR2019《PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud》。论文网址为https://arxiv.org/abs/1812.04244。PointRCNN核心思想在于使用点云前景点生成候选框,充分利用了目标点与候选框的关联性。相比之下,之前的目标检测网络候选框基本上是基于二维特征图来批量生成的,前景点和背景点对候选的贡献是一样的。作者使用PointRCNN在KITTI数据集上进行了大量实验并在当时达到了最佳效果。目前,Point RCNN以KITTI三维目标检测平均精度AP为75.42%排在第20位,排名来源于paperwithcode网站,网址为:https://paperswithcode.com/sota/3d-object-detection-on-kitti-cars-moderate。
1 PointRCNN模型总体过程
PointRCNN模型分为两个阶段,第一阶段使用语义分割的方法分割出前景点并初步生成候选框;第二阶段对候选框进一步筛选并结合特征融合与坐标系变换等方法对筛选后的候选框进行特征提取、正负样本分类和特征回归。
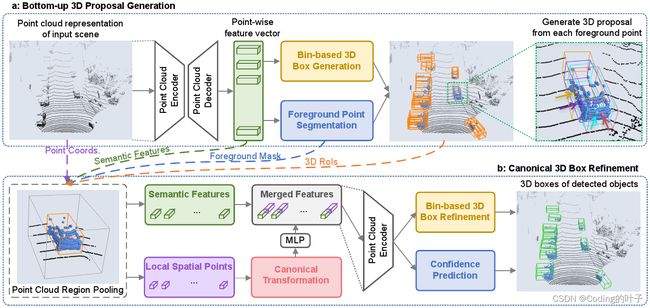
PointRCNN模型总体过程如下图所示,第一阶段主要包括特征提取、候选框生成、RPN损失计算;第二阶段主要包括候选框再筛选、正负样本选择、特征提取和ROI损失。

2 主要模块解析
2.1 点云特征提取
Point RCNN点云特征提取层包括backbone和neck两个网络,其中backbone网络主要用于提取多尺度高维度特征,neck网络将高维特征映射回待解决的问题空间,如分类或语义分割。
2.1.1 主干网络backbone
以KITTI数据为例,Point RCNN网络输入为Nx4(N=16384)维度的点云,4个维度分别是坐标x、y、z和反射强度r。Point RCNN主干网络采用多尺度PointNet++结构,即PointNet2SAMSG,详细介绍请参考博文:【三维深度学习】PointNet++(三):多尺度分组MSG详解_Coding的叶子的博客-CSDN博客_pointnet msg ssg。
PointNetSAMSG中采用四个级联的SAMSG结构依次进行特征提取。SA采样点数分别是4096、1024、256和64,因此,采样后点云坐标维度sa_xyz为[16384x3, 4096x3, 1024x3, 256x3, 64x3],特征维度sa_feature的维度为[1x16384, 96x4096, 256x1024, 512x256, 1024x64],同时返回各个采样点在原始点云中的索引sa_indices,其维度为[16384, 4096, 1024, 256, 64]。各个维度计算过程中默认忽略了Batch的维度,即BxNxM仅考虑NxM。B为batch size大小,可以根据需要自行设置。
PointRCNN主干网络的输出包括点云特征列表sa_feature [1x16384, 96x4096, 256x1024, 512x256, 1024x64]、采样后点云坐标列表sa_xyz [16384x3, 4096x3, 1024x3, 256x3, 64x3]和采样点索引列表sa_indices [16384, 4096, 1024, 256, 64]。关键函数调用及源码如下所示。
N =16384
# points B x N x 4 16384x4,
x = self.extract_feat(points)
Backbone PointNet2SAMSG
x = self.backbone(points)
#backbone返回值包括:sa_xyz、sa_feature、sa_indices
sa_xyz:[16384x3, 4096x3, 1024x3, 256x3, 64x3],SAMSG采样后的点云坐标
sa_feature:[1x16384, 96x4096, 256x1024, 512x256, 1024x64],SAMSG采样后的点云特征
sa_indices:[16384, 4096, 1024, 256, 64],SAMSG采样后的点云索引2.1.2 Neck网络
PointRCNN的Neck网络结构采用了PointNet++中的FP(Pointnet2_fp_neck feature propagation)特征上采样层。点云特征上采样原理和实现的详细介绍请参考博文:【点云上采样】三维点云特征上采样_Coding的叶子的博客-CSDN博客_点云上采样。
PointNet++的上采样是通过插值来实现的,并且插值依赖于前后两层特征。假设前一层的点数N=64,特征维度为D1;后一层点数S=16,特征维度为D2。那么插值的任务就是把后一层的点数插值成64,或者把前一层的特征维度由D1插值到D2。主要步骤如下:
(1)以前一层的64个点为参考点,分别计算这64个点和待插值的16个点的距离,得到64x16的距离矩阵。
(2)分别在待插值的16个点中选择k=3个最接近各个参考点的点,然后将这k个点特征的加权平均值作为插值点的特征。每个参考点都会得到一个新的特征,新的特征来自于后一层点特征的加权平均。加权系数等于各个点的距离倒数除以3个点的距离倒数之和。距离越近,加权系数越大。
(3)通常插值后的特征维度会与原特征进行拼接,即维度为D1+D2。为了使特征维度保持为D2,通道为(D1+D2, D2)的卷积被用来将输出特征对齐到D2。
PointRCNN的Neck网络计算关键过程如下所示。
Neck
Pointnet2_fp_neck feature propagation,输入为backbone输出的特征列表,反向逐层上采样
FP4:输入:1024x64、512x256->特征上采样:1024x256->特征拼接:1536x256->特征对齐: (Conv2d(1536, 512, 1, 1)、Conv2d(512, 512)->输出:512x256
FP3:输入:512x256、256x1024->特征上采样:512x1024->特征拼接:768x512->特征对齐(Conv2d(768, 512, 1, 1)、Conv2d(512, 512)->输出:512x1024
FP2:输入:512x1024、96x4096->特征上采样:512x4096->特征拼接:608x4096->特征对齐:(Conv2d(608, 256, 1, 1)、Conv2d(256, 256)->输出:256x4096
FP1:输入:256x4096、1x16384->特征上采样:256x16384 ->特征拼接:257x16384->特征对齐:(Conv2d(257, 128, 1, 1)、Conv2d(128, 128)->输出:128x16384
特征提取网络最终输出:
fp_xyz:16384x3,FP上采样后的点云坐标
fp_features:128x16384,FP上采样后的点云特征
#---extract_feats endPointRCNN的特征提取网络的Backbone和Neck与PoinNet++完全一致,最终为点云中每个点提取到128维特征。特征提取网络最终输出由两部分组成,即各点坐标fp_xyz(16384x3)和特征(128x16384)。
2.2 候选框生成rpn网络
RPN网络的目的是产生可能存在目标的三维候选框(proposal)。这也是PointRCNN核心所在。在此之前,目标检测的候选框通常是由二维特征图直接产生。这种方法是以特征图上的点为中心,设置特定的尺寸和方向,进而产生候选框并提取其分类和回归特征。PointRCNN则是以前景点为中心来直接提取各点的分类和候选框回归特征。当某个点属于前景点(目标点)时,它对应的候选框才更有可能成为真实的候选框。而基于特征图的候选框是对所有位置进行候选框生成,不考虑对应位置是否包含目标信息。相比之下,PointRCNN生成候选框的方法更加高效,能够获得少量高质量(高召回率)的候选框。
RPN网络包括rpn head和rpn loss两部分,即候选框生成与损失函数计算。
rpn_head网络根据每个点的特征初步生成候选框的分类和位置信息。经过特征提取层,每个点具有128维特征,经过 Linear(128, 256)、Linear(256, 256)、 Linear(256, C)等3层全连接层后维度为C。这里C等于3,即预测3个不同的类别。类别的数量可根据实际情况和需求自行调整。因此,类别cls_preds预测结果的维度为16384x3,3表示类别的数量。后续这3个维度的预测结果通过sigmoid函数直接转为预测概率。
在PointRCNN原始论文中,候选框生成采用的时bin生成方法,即对原始空间尺寸重新按照bin的尺寸作为单位长度重新进行划分,然后生成候选框。候选框通过将128维特征降到76个维度后与候选框坐标、尺寸、角度等8个维度进行一一对应。作者发现采用这些方法,模型在训练过程中能够更快收敛。
Mmdetection3d源码中采用的方式比较常规,与大部分模型的候选框生成方式一样,而没有采用bin候选框生成方式。这也说明很多模型的大体思路和结构是一致的,功能相近的部分可以进行替换,这也是模型优化的思路之一。128维特征经过 Linear(128, 256)、Linear(256, 256)、 Linear(256, 8)等3层全连接层后维度为8,预测框bbox_preds预测结果的维度为16384x8。其中,0~2前三个维度表示预测框相对于真实框的中心偏差;3~5中间三个维度表示预测框相对于真实框的尺寸偏差;6~7最后两个维度表示预测框的角度方向,即分别为角度的余弦和正弦。假设这8个维度变量分别为xt、yt、zt、dxt、dyt、dzt、cost、sint,对应的真实框坐标为xa、ya、za、dxa、dya、dza,对应的预测框坐标和角度为xg、yg、zg、dxg、dyg、dzg、rg。xa、ya、za为各个点自身的坐标。它们之间的关系定义如下:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
rpn head网络结构相关代码如下:
bbox_preds, cls_preds = self.rpn_head(x)
point_cls_preds = self.cls_layers(feat_cls).reshape(batch_size, -1, self._get_cls_out_channels())
self.cls_layer: Linear(128, 256) -> Linear(256, 256) -> Linear(256, 3)
16384x128 -> 16384x3
point_box_preds = self.reg_layers(feat_reg).reshape(batch_size, -1, self._get_reg_out_channels())
self.reg_layer: Linear(128, 256) -> Linear(256, 256) -> Linear(256, 8)
16384x128 -> 16384x8rpn输出的损失包含bbox位置损失bbox_loss和语义损失semantic_loss两部分。其中,bbox的真实值bbox_targets的维度与bbox_preds保持一致,16384x8。实验测试可得到bbox_targets最后两维的平方和为1,映证了角度是用余弦和正弦来表征的。bbox_loss对应的损失函数为SmoothL1Loss,输入为bbox_preds、bbox_targets、box_loss_weights。box_loss_weights为每个点损失的权重,最终损失为各个点损失的加权求和。
语义损失semantic_loss的输入为cls_preds分类结果、真实类别semantic_points_label、权重semantic_loss_weight,采用FocalLoss损失函数,并将计算结果除以实际前景点数量来进行平均。
rpn 损失关键代码解析如下所示。
rpn_loss = self.rpn_head.loss(bbox_preds=bbox_preds, cls_preds=cls_preds, points=points, gt_bboxes_3d=gt_bboxes_3d, gt_labels_3d=gt_labels_3d, img_metas=img_metas)
#获取真实标签
targets = self.get_targets(points, gt_bboxes_3d, gt_labels_3d)
(bbox_targets, mask_targets, positive_mask, negative_mask, box_loss_weights, point_targets) = targets
# bbox loss SmoothL1Loss()
bbox_loss = self.bbox_loss(bbox_preds, bbox_targets, box_loss_weights.unsqueeze(-1))
# Semantic_loss FocalLoss()
semantic_points = cls_preds.reshape(-1, self.num_classes)
semantic_loss = self.cls_loss(semantic_points, semantic_points_label.reshape(-1), semantic_loss_weight.reshape(-1))
semantic_loss /= positive_mask.float().sum()
losses = dict(bbox_loss=bbox_loss, semantic_loss=semantic_loss)
return losses2.3 bbox候选框再筛选
上面PointRCNN第一阶段网络结构初步计算了rpn过程所有预测框的位置损失,而我们更加关心比较可能回归到真实框的候选框。因此,PointRCNN对候选框进行了进一步筛选,主要步骤如下:
(1)根据上述rpn_head网络部分公式将bbox偏差xt、yt、zt、dxt、dyt、dzt、cost、sint,转换为对应的预测框bbox3d坐标和角度xg、yg、zg、dxg、dyg、dzg、rg。预测框维度由8维变为7维,正弦和余弦由角度直接表征。
(2)分别统计各个候选框bbox3d中包含真实点的个数,筛选出含真实点的候选框。
(3)按照目标预测概率,选择出概率较大的前9000个候选框。
(4)利用NMS(非极大值抑制)从9000个候选框中最多选择出512个候选框。
(5)返回512个候选框坐标位置和方向bbox_selected(512x7),及其对应的目标概率 score_selected(512x1)、目标类别label(512x1)和 目标分类cls_preds(512x3)。
通过以上步骤,最终筛选出的bbox_list或proposal_list包含了第(5)步中的四个组成部分。关键代码解读如下所示。
bbox_list = self.rpn_head.get_bboxes(points_cat, bbox_preds, cls_preds, img_metas)
sem_scores = cls_preds.sigmoid()
#目标概率
obj_scores = sem_scores.max(-1)[0]
#目标类别
object_class = sem_scores.argmax(dim=-1)
pooled_point_feats = self.point_roi_extractor(features, points, batch_size, rois)
#将预测结果差值坐标转换为实际坐标,由8个维度变为7个维度,转换公式见rpn_head网络部分。
bbox3d = self.bbox_coder.decode(bbox_preds[b], points[b, ..., :3], object_class[b])
bbox_selected, score_selected, labels, cls_preds_selected = self.class_agnostic_nms(obj_scores[b], sem_scores[b], bbox3d, points[b, ..., :3], input_metas[b])
#每个点所在候选框的序号,-1表示点不在任何预测框中,即被预测为背景点
box_idx = bbox.points_in_boxes(points)
box_indices = box_idx.new_zeros([num_bbox + 1])
#背景点标签由-1变为num_box,16384
box_idx[box_idx == -1] = num_bbox
#每个位置表示第N个bbox之中包含的真实点个数
box_indices.scatter_add_(0, box_idx.long(), box_idx.new_ones(box_idx.shape))
box_indices = box_indices[:-1]
#包含真实点的预测框的mask,应修改成box_indices > 0
nonempty_box_mask = box_indices >= 0
bbox = bbox[nonempty_box_mask]
#按照目标概率,选出前topk个索引,topk=9000
obj_scores_nms, indices = torch.topk(obj_scores, k=topk)
#对选择的9000个候选框,经过NMS非极大值抑制后,并提取前nms_cfg.nms_post=512个候选框。
keep = nms_func(bbox_for_nms, obj_scores_nms, nms_cfg.iou_thr)
keep = keep[:nms_cfg.nms_post]
bbox_selected = bbox.tensor[indices][keep]
score_selected = obj_scores_nms[keep]
cls_preds = sem_scores_nms[keep]
labels = torch.argmax(cls_preds, -1)
#bbox_selected 512x7, score_selected 512x1, labels 512x1, cls_preds 512x3
return bbox_selected, score_selected, labels, cls_preds2.4 roi损失
roi的意义是感兴趣区域,也就是上面筛选出的候选框。Roi损失roi_losses将根据筛选候选框特征来进行计算。由于目标在检测场景中占据的比例有限,大部分被背景占据,所以在目标检测过程中大部分候选框都是负样本,框住的是背景。和二维目标检测损失相似,计算roi损失需要选择一定数量的正负样本,并控制正负样本的比例。针对选中的正负样本,模型通常采用交叉熵损失来计算分类损失,但仅对正样本进行位置回归。
PointRCNN在计算roi损失的过程中主要包含下面三个步骤:
(1)选择正负样本。正负样本总数为128。正样本最多占50%,即正样本数量最多为64。
(2)特征提取。选择出的128个候选框区域作为roi再次进行特征提取。RPN阶段提取的分类分数、特征(128)、目标深度(归一化深度坐标)拼接成16384x130维度新特征,然后根据roi pool从roi区域选择512个点,将点的坐标进一步拼接到特征。这样每个选择的roi样本对应512个点,每个点维度为133,即总维度为128x133x512。针对新特征,通过PointNet SA结构和卷积,模型输出了每个样本的分类分数(128)和预测位置(128x7)。
(3)计算损失。Roi损失包含分类损失和回归损失,其中回归损失用位置损失和角点损失,即loss_cls、loss_bbox、loss_corner。
Roi损失计算函数如下所示。
roi_losses = self.roi_head.forward_train(rcnn_feats, img_metas, proposal_list, gt_bboxes_3d, gt_labels_3d)2.4.1 正负样本选择
正负样本总体数量为128,即从上文筛选的512个候选框中进一步筛选出128个。正样本最多占50%,即正样本数量最多为64。如果不足正样本不超过64个,以实际数量为主;如果数量超过64个,则随机选出64个作为正样本。总样本数量128减去正样本数量就是负样本数量,可以看到负样本数量至少占50%。预测框与真实框的IOU大于0.55时属于正样本,否则为负样本。
正负样本选择的详细代码解析如下。正负样本选择函数返回结果为返回sample_results,主要包含采样后的128个bboxes、正负样本索引、正负样本对应的bbox。
#选择一定比例的正样本和负样本
sample_results = self._assign_and_sample(proposal_list, gt_bboxes_3d, gt_labels_3d)
#按照类别逐一选择正负样本
gt_per_cls = (cur_gt_labels == i)
pred_per_cls = (cur_labels_3d == i)
#返回AssignResult(num_gts, assigned_gt_inds, max_overlaps, labels=assigned_labels)
cur_assign_res = assigner.assign(cur_boxes.tensor[pred_per_cls], cur_gt_bboxes.tensor[gt_per_cls], gt_labels=cur_gt_labels[gt_per_cls])
#计算真实框和各个预测框的重叠比例 k x n
overlaps = self.iou_calculator(gt_bboxes, bboxes)
#gt_inds:每个bbox对应的真实框序号,负样本为0,正样本为对应真实框序号(从1开始),-1为非正非负样本,max_overlaps为最大重叠IOU
assign_result = self.assign_wrt_overlaps(overlaps, gt_labels)
# for each anchor, the max iou of all gts, n
max_overlaps, argmax_overlaps = overlaps.max(dim=0)
# for each gt, the max iou of all proposals, k
gt_max_overlaps, gt_argmax_overlaps = overlaps.max(dim=1)
#与真实框重叠比例在0~0.55之间的属于负样本,标记为0
assigned_gt_inds[(max_overlaps >= 0) & (max_overlaps < self.neg_iou_thr)] = 0
# 3. assign positive: above positive IoU threshold
pos_inds = max_overlaps >= self.pos_iou_thr 0.55
#正样本为对应真实框序号(从1开始)
assigned_gt_inds[pos_inds] = argmax_overlaps[pos_inds] + 1
#正样本对应的目标类别,类别默认为-1,表示背景点
assigned_labels[pos_inds] = gt_labels[assigned_gt_inds[pos_inds] - 1]
#返回真实框个数k、正负样本判别结果n、最大重叠比例n、正样本标签
return AssignResult(num_gts, assigned_gt_inds, max_overlaps, labels=assigned_labels)
# gt inds (1-based),当前类别在所有真实框中的序号,从1开始,即第几个真实框属于当前label
gt_inds_arange_pad = gt_per_cls.nonzero(as_tuple=False).view(-1) + 1
# convert to 0~gt_num+2 for indices
gt_inds_arange_pad += 1
# now 0 is bg, >1 is fg in batch_gt_indis,每个预测框匹配的真实框序号,从1开始,即第几个真实框匹配当前预测框l,0表示负样本,-1表示背景
batch_gt_indis[pred_per_cls] = gt_inds_arange_pad[cur_assign_res.gt_inds + 1] - 1
#预测框与真实框重叠的最大比例
batch_gt_labels[pred_per_cls] = cur_assign_res.labels
sampling_result = self.bbox_sampler.sample(assign_result, cur_boxes.tensor, cur_gt_bboxes.tensor, cur_gt_labels)
#正样本最多保留128*0.5,即从上述的gt_inds选择出大于0的部分;如果数量不超过64,则保留全部正样本;如果数量超过64,则随机选择出64个正样本。
num_expected_pos = int(self.num * self.pos_fraction)
#总样本数保持为128,减去正样本数量即为负样本数量
num_expected_neg = self.num - num_sampled_pos
#负样本从两部分选择,80%来源于IOU在0.1~0.55之间,剩余的从IOU在0~0.1中随机选择。
piece_neg_inds = torch.nonzero( (max_overlaps >= min_iou_thr)& (max_overlaps < max_iou_thr), as_tuple=False).view(-1)
sampling_result = SamplingResult(pos_inds, neg_inds, bboxes, gt_bboxes, assign_result, gt_flags)
return sampling_result2.4.2 特征提取
特征提取目的是为了对选择的roi候选框进行更加精细的特征提取。RPN阶段提取的分类分数、特征(128)、目标深度(归一化深度坐标)拼接成16384x130维度新特征,然后根据roi pool从roi区域选择512个点,将点的坐标进一步拼接到特征。这样每个选择的roi样本对应512个点,每个点维度为133,即总维度为128x133x512。Roi pool的目的可以看作是对每个候选框选择出固定数量的点,并且标记候选框是包含原始点云中的点。
利用坐标Canonical变换,roi的中心点坐标作为原点,并且将其倾斜角度旋转到零。模型用3个PointNet SA模块PointSAModule对roi的512个点进行特征提取,得到l_features = [128x128x512, 128x128x128, 128x256x32, 128x512x1],l_xyz = [128x512x3, 128x128x3, 128x32x3],对应的采样点数分别为128、32、1。最后用一个点的特征来作为512个点的宏观全局特征,即最终特征维度为128x512x1。对这128x512x1特征进行卷积操作,模型输出了每个样本的分类分数cls_score(128)和bbox_pred预测位置(128x7)。
关键过程代码解析如下所示。
# concat the depth, semantic features and backbone features
features = features.transpose(1, 2).contiguous()
point_depths = points.norm(dim=2) / self.depth_normalizer - 0.5
features_list = [point_scores.unsqueeze(2), point_depths.unsqueeze(2), features]
#拼接后的特征维度为1+1+128 = 130,即16384 x 130
features = torch.cat(features_list, dim=2)
bbox_results = self._bbox_forward_train(features, points, sample_results)
#rois为筛选的128个bbox,128x7
box_results = self._bbox_forward(features, points, batch_size, rois)
pooled_point_feats = self.point_roi_extractor(features, points, batch_size, rois)
#将坐标与现有特征拼接,特征维度由130改为133,然后从每个rois候选框选择512个点,同时返回rois候选框是否空,即不包含前景点。因此,pooled_roi_feat维度为128x512x133,pooled_empty_flag维度为128,其中0表示不为空,1表示为空。
pooled_roi_feat, pooled_empty_flag = self.roi_layer(coordinate, feats, rois)
# canonical transformation 正交变换
roi_center = rois[:, :, 0:3]
#中心坐标作为原点
pooled_roi_feat[:, :, :, 0:3] -= roi_center.unsqueeze(dim=2)
#对坐标进行旋转,相当于让bbox预测框的倾角旋转到零。
pooled_roi_feat[:, :, 0:3] = rotation_3d_in_axis(pooled_roi_feat[:, :, 0:3], -(rois.view(-1, rois.shape[-1])[:, 6]), axis=2)
#将为空的预测框特征置为零。
pooled_roi_feat[pooled_empty_flag.view(-1) > 0] = 0
#128x133x512
return pooled_roi_feat
特征提取
cls_score, bbox_pred = self.bbox_head(pooled_point_feats)
#将特征133个维度的前5个单独提取出来,再次提一遍特征。这5个维度的意义分别是3个坐标、目标概率和归一化深度,128x5x512
xyz_input = input_data[..., 0:self.in_channels].transpose( 1, 2).unsqueeze(dim=3).contiguous().clone().detach()
#卷积Conv2d(5, 128)、Conv2d(128, 128),128x128x512
xyz_features = self.xyz_up_layer(xyz_input)
#rpn阶段提取的128维特征,128x128x512
rpn_features = input_data[..., self.in_channels:].transpose(1, 2).unsqueeze(dim=3)
#特征拼接融合,也可以改为加减乘除的融合方式,128x256x512
merged_features = torch.cat((xyz_features, rpn_features), dim=1)
#卷积Conv2d(256, 128)降维,128x128x512
merged_features = self.merge_down_layer(merged_features)
#相当于有512点,坐标三个维度,特征为128个维度
l_xyz, l_features = [input_data[..., 0:3].contiguous()], [merged_features.squeeze(dim=3)]
#用3个SA模块PointSAModule对这512个点进行特征提取,l_features = [128x128x512, 128x128x128, 128x256x32, 128x512x1],l_xyz = [128x512x3, 128x128x3, 128x32x3]
li_xyz, li_features, cur_indices = self.SA_modules[i](l_xyz[i], l_features[i])
#最后用一个点的特征来作为512个点的宏观全局特征。
#128x512x1
shared_features = l_features[-1]
x_cls = shared_features
x_reg = shared_features
#Conv1d(512, 256)、Conv2d(256, 256),128x256x1
x_cls = self.cls_convs(x_cls)
#Conv1d(256, 1),128x1x1
rcnn_cls = self.conv_cls(x_cls)
#Conv1d(512, 256)、Conv2d(256, 256),128x256x1
x_reg = self.reg_convs(x_reg)
#Conv1d(256, 7),128x256x1
rcnn_reg = self.conv_reg(x_reg)
rcnn_cls = rcnn_cls.transpose(1, 2).contiguous().squeeze(dim=1)
rcnn_reg = rcnn_reg.transpose(1, 2).contiguous().squeeze(dim=1)
#bbox_results:cls_score, bbox_pred,128,128x7
return rcnn_cls, rcnn_reg2.4.3 roi loss
roi损失包含分类损失和回归损失,其中回归损失用位置损失和角点损失,即loss_cls、loss_bbox、loss_corner。在计算分类损失loss时,roi的真实标签label根据iou重叠比列大大小转换为0~1之间的数值,0表示iou小于0.25的负样本,1表示iou大于0.7的正样本。Roi分类损失loss_cls的损失函数为CrossEntropyLoss,bbox位置损失loss_bbox损失函数为SmoothL1Loss,焦点损失loss_corner函数为 HuberLoss。
#分类正样本iou>0.7
cls_pos_mask = ious > cfg.cls_pos_thr
#分类负样本iou<0.25
cls_neg_mask = ious < cfg.cls_neg_thr
#iou在0.25~0.7之间的样本mask,困难样本,hard sample
interval_mask = (cls_pos_mask == 0) & (cls_neg_mask == 0)
# iou regression target,正样本label为1,否则label为0
label = (cls_pos_mask > 0).float()
#对困难样本label归一化至0~1,相当于中间标签,那么正样本为1,负样本为0,也可以理解为分类概率。
label[interval_mask] = (ious[interval_mask] - cfg.cls_neg_thr) / (cfg.cls_pos_thr - cfg.cls_neg_thr)
# label weights,每个标签赋予了相同的权重,128个
label_weights = (label >= 0).float()
# box regression target,仅对bbox正样本进行回归
reg_mask = pos_bboxes.new_zeros(ious.size(0)).long()
reg_mask[0:pos_gt_bboxes.size(0)] = 1
#仅对bbox正样本进行回归
bbox_weights = (reg_mask > 0).float()
#label 128 0~1,bbox_targets m,pos_gt_bboxes m,reg_mask 128, label_weights 128, bbox_weights 128
(label, bbox_targets, pos_gt_bboxes, reg_mask, label_weights, bbox_weights) = targets
#loss_cls、loss_bbox、loss_corner
loss_bbox = self.bbox_head.loss(bbox_results['cls_score'], bbox_results['bbox_pred'], rois, *bbox_targets)
# calculate class loss CrossEntropyLoss(avg_non_ignore=False)
cls_flat = cls_score.view(-1)
loss_cls = self.loss_cls(cls_flat, labels, label_weights)
#SmoothL1Loss()
loss_bbox = self.loss_bbox(pos_bbox_pred.unsqueeze(dim=0), bbox_targets.unsqueeze(dim=0).detach(), bbox_weights_flat.unsqueeze(dim=0))
# calculate corner loss huber loss
loss_corner = self.get_corner_loss_lidar(pred_boxes3d, pos_gt_bboxes)2.5 总体损失函数
总体损失包括rpn损失和roi损失。rpn位置损失函数bbox_loss对应的损失函数为SmoothL1Loss。rpn语义损失semantic_loss采用FocalLoss损失函数,并将计算结果除以实际前景点数量来进行平均。roi分类损失loss_cls的损失函数为CrossEntropyLoss,bbox位置损失loss_bbox损失函数为SmoothL1Loss,焦点损失loss_corner函数为 HuberLoss。
总体损失类型如下所示。
bbox_loss:SmoothL1Loss
semantic_loss:FocalLoss
loss_cls:CrossEntropyLoss
loss_bbox:SmoothL1Loss
loss_corner:HuberLoss2.6 顶层结构
顶层结构主要包含以下三部分:
(1)特征提取:self.extract_feat,得到128x16384特征,见2.5节。
(2)检测头:见2.6节。
(3)损失函数:见2.7节。
def forward_train(self, points, img_metas, gt_bboxes_3d, gt_labels_3d):
losses = dict()
points_cat = torch.stack(points)
x = self.extract_feat(points_cat)
# features for rcnn
backbone_feats = x['fp_features'].clone()
backbone_xyz = x['fp_xyz'].clone()
rcnn_feats = {'features': backbone_feats, 'points': backbone_xyz}
bbox_preds, cls_preds = self.rpn_head(x)
rpn_loss = self.rpn_head.loss(bbox_preds=bbox_preds,cls_preds=cls_preds,points=points,gt_bboxes_3d=gt_bboxes_3d,gt_labels_3d=gt_labels_3d,img_metas=img_metas)
losses.update(rpn_loss)
bbox_list = self.rpn_head.get_bboxes(points_cat, bbox_preds, cls_preds,img_metas)
proposal_list = [dict(boxes_3d=bboxes,scores_3d=scores,labels_3d=labels,cls_preds=preds_cls)
for bboxes, scores, labels, preds_cls in bbox_list]
rcnn_feats.update({'points_cls_preds': cls_preds})
roi_losses = self.roi_head.forward_train(rcnn_feats, img_metas,proposal_list, gt_bboxes_3d,gt_labels_3d)
losses.update(roi_losses)
return losses
#extract_feat模块
def extract_feat(self, points):
x = self.backbone(points)
if self.with_neck:
x = self.neck(x)3 训练命令
python tools/train.py configs/point_rcnn/point_rcnn_2x8_kitti-3d-3classes.py4 运行结果

5 【python三维深度学习】python三维点云从基础到深度学习_Coding的叶子的博客-CSDN博客_python点云分割
更多三维、二维感知算法和金融量化分析算法请关注“乐乐感知学堂”微信公众号,并将持续进行更新。