机器学习的R实现(mlr包)
目录
Machine Learning with MLR Package
1. 获取数据
2. 探索数据
3. 缺失值填补
4. 特征工程
5. 机器学习
1. 二次判别分析,Quadratic Discriminant Analysis (QDA).
2.逻辑回归 Logistic Regression
3. 决策树-Decision Tree
4. 随机森林,Random Forest
5. 支持向量机,SVM
6. 梯度提升机,Gradient Boosting Machine-GBM
7. Xgboost
8.特征选择
Machine Learning with MLR Package
直到现在,R还没有任何类似于Python的Scikit-Learn的包/库,在那里你可以得到做机器学习所需的所有功能。但是,从2016年2月开始,R用户有了mlr包,他们可以用它来执行大部分的ML任务。
现在让我们了解一下这个包如何工作的基本概念。如果你在这里得到它,理解整个包将是一个简单的小菜一碟。
这个包的整个结构依赖于这个前提。
创建一个任务。制造一个学习者。训练他们。
创建一个任务意味着在软件包中加载数据。制造一个学习者意味着选择一个算法(学习者),从任务(或数据)中学习。最后,训练它们。
MLR包在它的花束里有几种算法。这些算法被分为回归、分类、聚类、生存、多分类和成本敏感分类。让我们来看看一些可用的分类问题的算法。
listLearners("classif")[c("class","package")]
class package
1 classif.ada ada,rpart
2 classif.adaboostm1 RWeka
3 classif.bartMachine bartMachine
4 classif.binomial stats
5 classif.boosting adabag,rpart
6 classif.bst bst,rpart
7 classif.C50 C50
8 classif.cforest party
9 classif.clusterSVM SwarmSVM,LiblineaR
10 classif.ctree party
11 classif.cvglmnet glmnet
12 classif.dbnDNN deepnet
13 classif.dcSVM SwarmSVM,e1071
14 classif.earth earth,stats
15 classif.evtree evtree
16 classif.extraTrees extraTrees
17 classif.fdausc.glm fda.usc
18 classif.fdausc.kernel fda.usc
19 classif.fdausc.knn fda.usc
20 classif.fdausc.np fda.usc
21 classif.FDboost FDboost,mboost
22 classif.featureless mlr
23 classif.fgam refund
24 classif.fnn FNN
25 classif.gamboost mboost
26 classif.gaterSVM SwarmSVM
27 classif.gausspr kernlab
28 classif.gbm gbm
29 classif.geoDA DiscriMiner
30 classif.glmboost mboost
31 classif.glmnet glmnet
32 classif.h2o.deeplearning h2o
33 classif.h2o.gbm h2o
34 classif.h2o.glm h2o
35 classif.h2o.randomForest h2o
36 classif.IBk RWeka
37 classif.J48 RWeka
38 classif.JRip RWeka
39 classif.kknn kknn
40 classif.knn class
41 classif.ksvm kernlab
42 classif.lda MASS
43 classif.LiblineaRL1L2SVC LiblineaR
44 classif.LiblineaRL1LogReg LiblineaR
45 classif.LiblineaRL2L1SVC LiblineaR
46 classif.LiblineaRL2LogReg LiblineaR
47 classif.LiblineaRL2SVC LiblineaR
48 classif.LiblineaRMultiClassSVC LiblineaR
49 classif.linDA DiscriMiner
50 classif.logreg stats
51 classif.lssvm kernlab
52 classif.lvq1 class
53 classif.mda mda
54 classif.mlp RSNNS
55 classif.multinom nnet
56 classif.naiveBayes e1071
57 classif.neuralnet neuralnet
58 classif.nnet nnet
59 classif.nnTrain deepnet
60 classif.nodeHarvest nodeHarvest
61 classif.OneR RWeka
62 classif.pamr pamr
63 classif.PART RWeka
64 classif.penalized penalized
65 classif.plr stepPlr
66 classif.plsdaCaret caret,pls
67 classif.probit stats
68 classif.qda MASS
69 classif.quaDA DiscriMiner
70 classif.randomForest randomForest
71 classif.randomForestSRC randomForestSRC
72 classif.ranger ranger
73 classif.rda klaR
74 classif.rFerns rFerns
75 classif.rknn rknn
76 classif.rotationForest rotationForest
77 classif.rpart rpart
78 classif.RRF RRF
79 classif.rrlda rrlda
80 classif.saeDNN deepnet
81 classif.sda sda
82 classif.sparseLDA sparseLDA,MASS,elasticnet
83 classif.svm e1071
84 classif.xgboost xgboost1. 获取数据
在本教程中,我采用了DataHack中的一个流行的ML问题: Download Data.
Loan Prediction (analyticsvidhya.com)
path <- "~/Data/Playground/MLR_Package"
setwd(path)
#load libraries and data
install.packages("mlr")
library(mlr)
train <- read.csv("train_loan.csv", na.strings = c(""," ",NA))
test <- read.csv("test_Y3wMUE5.csv", na.strings = c(""," ",NA))2. 探索数据
summarizeColumns(train) name type na mean disp median mad min max nlevs
1 Loan_ID factor 0 NA 0.9983713 NA NA 1 1 614
2 Gender factor 13 NA NA NA NA 112 489 2
3 Married factor 3 NA NA NA NA 213 398 2
4 Dependents factor 15 NA NA NA NA 51 345 4
5 Education factor 0 NA 0.2182410 NA NA 134 480 2
6 Self_Employed factor 32 NA NA NA NA 82 500 2
7 ApplicantIncome integer 0 5403.4592834 6109.0416734 3812.5 1822.8567 150 81000 0
8 CoapplicantIncome numeric 0 1621.2457980 2926.2483692 1188.5 1762.0701 0 41667 0
9 LoanAmount integer 22 146.4121622 85.5873252 128.0 47.4432 9 700 0
10 Loan_Amount_Term integer 14 342.0000000 65.1204099 360.0 0.0000 12 480 0
11 Credit_History integer 50 0.8421986 0.3648783 1.0 0.0000 0 1 0
12 Property_Area factor 0 NA 0.6205212 NA NA 179 233 3
13 Loan_Status factor 0 NA 0.3127036 NA NA 192 422 2与基本的str()函数相比,这个函数给出了一个更全面的数据集视图。上面显示的是最后5行的结果。同样地,你也可以对测试数据进行处理。
summarizeColumns(test) name type na mean disp median mad min max nlevs
1 Loan_ID factor 0 NA 0.9972752 NA NA 1 1 367
2 Gender factor 11 NA NA NA NA 70 286 2
3 Married factor 0 NA 0.3651226 NA NA 134 233 2
4 Dependents factor 10 NA NA NA NA 40 200 4
5 Education factor 0 NA 0.2288828 NA NA 84 283 2
6 Self_Employed factor 23 NA NA NA NA 37 307 2
7 ApplicantIncome integer 0 4805.5994550 4910.6853990 3786 1598.2428 0 72529 0
8 CoapplicantIncome integer 0 1569.5776567 2334.2320987 1025 1519.6650 0 24000 0
9 LoanAmount integer 5 136.1325967 61.3666524 125 38.5476 28 550 0
10 Loan_Amount_Term integer 6 342.5373961 65.1566434 360 0.0000 6 480 0
11 Credit_History integer 29 0.8254438 0.3801498 1 0.0000 0 1 0
12 Property_Area factor 0 NA 0.6185286 NA NA 111 140 3从这些输出中,我们可以做出以下推断。
1.在数据中,我们有12个变量,其中Loan_Status是因变量,其余是自变量。
2.Train data有614个观测值。Test data有367个观测值。
3.在训练和测试数据中,有6个变量有缺失值(可以在na列中看到)。
4.ApplicantIncome和Coapplicant Income 是高度偏态的变量。我们怎么知道的?看看它们的最小、最大和中位数。我们必须对这些变量进行标准化处理。
5.LoanAmount、ApplicantIncome和CoapplicantIncome都有离群值,应该加以处理。
6.Credit_History是一个整数类型的变量。但是,由于是二进制性质,我们应该将其转换为因子。
另外,你可以用一个简单的直方图来检查上述变量中是否存在偏度。
hist(train$ApplicantIncome, breaks = 300, main = "Applicant Income Chart",xlab = "ApplicantIncome")
hist(train$CoapplicantIncome, breaks = 100,main = "Coapplicant Income Chart",xlab = "CoapplicantIncome")
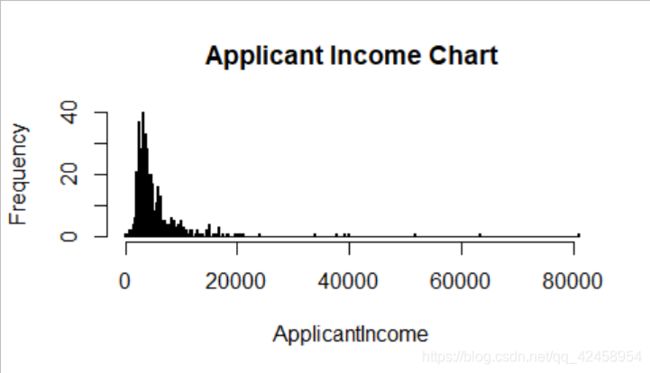

正如你在上面的图表中所看到的,偏斜度只不过是将大部分数据集中在图表的一侧。我们看到的是一个右偏的图表。为了使离群值可视化,我们可以使用boxplot。
boxplot(train$ApplicantIncome) 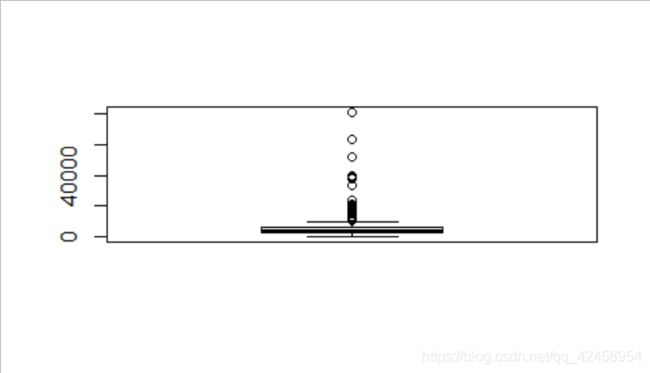
同样地,你也可以为CoapplicantIncome和LoanAmount创建一个boxplot。
让我们把Credit_History的类别改为因子。记住,因子类总是用于分类变量。
train$Credit_History <- as.factor(train$Credit_History)
test$Credit_History <- as.factor(test$Credit_History)
class(train$Credit_History)
[1] "factor"你可以用以下方法进一步检查数据。
summary(train)
summary(test)Loan_ID Gender Married Dependents Education Self_Employed
LP001002: 1 Female:112 No :213 0 :345 Graduate :480 No :500
LP001003: 1 Male :489 Yes :398 1 :102 Not Graduate:134 Yes : 82
LP001005: 1 NA's : 13 NA's: 3 2 :101 NA's: 32
LP001006: 1 3+ : 51
LP001008: 1 NA's: 15
LP001011: 1
(Other) :608
ApplicantIncome CoapplicantIncome LoanAmount Loan_Amount_Term Credit_History
Min. : 150 Min. : 0 Min. : 9.0 Min. : 12 Min. :0.0000
1st Qu.: 2878 1st Qu.: 0 1st Qu.:100.0 1st Qu.:360 1st Qu.:1.0000
Median : 3812 Median : 1188 Median :128.0 Median :360 Median :1.0000
Mean : 5403 Mean : 1621 Mean :146.4 Mean :342 Mean :0.8422
3rd Qu.: 5795 3rd Qu.: 2297 3rd Qu.:168.0 3rd Qu.:360 3rd Qu.:1.0000
Max. :81000 Max. :41667 Max. :700.0 Max. :480 Max. :1.0000
NA's :22 NA's :14 NA's :50
Property_Area Loan_Status
Rural :179 N:192
Semiurban:233 Y:422
Urban :202 我们发现,变量Dependents有一个3+级别,也应被处理。修改因子变量中的名称级别是很简单的。它可以这样做。
#rename level of Dependents
levels(train$Dependents)[4] <- "3"
levels(test$Dependents)[4] <- "3"3. 缺失值填补
不仅仅是初学者,即使是优秀的R分析员也会为缺失值的归纳而奋斗。MLR包提供了一个很好很方便的方法,可以使用多种方法来计算缺失值。 在我们完成了对数据的必要修改之后,让我们来归纳缺失值。
在我们的例子中,我们将使用基本的平均数和模式归纳法来归纳数据。你也可以使用任何ML算法来计算这些值,但这是以计算为代价的。
#impute missing values by mean and mode
imp <- impute(train, classes = list(factor = imputeMode(), integer = imputeMean()), dummy.classes = c("integer","factor"), dummy.type = "numeric")
imp1 <- impute(test, classes = list(factor = imputeMode(), integer = imputeMean()), dummy.classes = c("integer","factor"), dummy.type = "numeric")这个函数很方便,因为你不需要指定每个变量的名称来归纳。它根据变量的类别来选择变量。它还为缺失值创建新的虚拟变量。有时,这些(虚拟)特征包含一个趋势,可以用这个函数来捕捉。 dummy.class说我应该为哪些类创建一个虚拟变量。
imp函数的$data属性包含填补的数据。
imp_train <- imp$data
imp_test <- imp1$data现在,我们有了完整的数据。你可以用以下方法检查新的变量。
summarizeColumns(imp_train)
summarizeColumns(imp_test) name type na mean disp median mad min max nlevs
1 Loan_ID factor 0 NA 9.983713e-01 NA NA 1 1 614
2 Gender factor 0 NA 1.824104e-01 NA NA 112 502 2
3 Married factor 0 NA 3.469055e-01 NA NA 213 401 2
4 Dependents factor 0 NA 4.136808e-01 NA NA 51 360 4
5 Education factor 0 NA 2.182410e-01 NA NA 134 480 2
6 Self_Employed factor 0 NA 1.335505e-01 NA NA 82 532 2
7 ApplicantIncome numeric 0 5.403459e+03 6.109042e+03 3812.5 1822.8567 150 81000 0
8 CoapplicantIncome numeric 0 1.621246e+03 2.926248e+03 1188.5 1762.0701 0 41667 0
9 LoanAmount numeric 0 1.464122e+02 8.403747e+01 129.0 45.2193 9 700 0
10 Loan_Amount_Term numeric 0 3.420000e+02 6.437249e+01 360.0 0.0000 12 480 0
11 Credit_History numeric 0 8.421986e-01 3.496810e-01 1.0 0.0000 0 1 0
12 Property_Area factor 0 NA 6.205212e-01 NA NA 179 233 3
13 Loan_Status factor 0 NA 3.127036e-01 NA NA 192 422 2
14 Gender.dummy numeric 0 2.117264e-02 1.440769e-01 0.0 0.0000 0 1 0
15 Married.dummy numeric 0 4.885993e-03 6.978576e-02 0.0 0.0000 0 1 0
16 Dependents.dummy numeric 0 2.442997e-02 1.545057e-01 0.0 0.0000 0 1 0
17 Self_Employed.dummy numeric 0 5.211726e-02 2.224447e-01 0.0 0.0000 0 1 0
18 LoanAmount.dummy numeric 0 3.583062e-02 1.860192e-01 0.0 0.0000 0 1 0
19 Loan_Amount_Term.dummy numeric 0 2.280130e-02 1.493913e-01 0.0 0.0000 0 1 0
20 Credit_History.dummy numeric 0 8.143322e-02 2.737223e-01 0.0 0.0000 0 1 0你是否注意到两组数据之间的差异?没有吗?再看看。答案是Married.dummy变量只存在于imp_train,而不存在于imp_test。因此,我们必须在建模阶段将其删除。
可选:你可能对使用ML算法进行缺失值估算感到兴奋或好奇。 事实上,有一些算法不需要你去估算缺失值。你可以简单地提供给他们缺失的数据。它们会自行处理缺失值。让我们来看看这些算法是什么。
listLearners("classif", check.packages = TRUE, properties = "missings")[c("class","package")]
class package
1 classif.featureless mlr
2 classif.gbm gbm
3 classif.naiveBayes e1071
4 classif.rpart rpart
5 classif.xgboost xgboost然而,最好是单独处理缺失值。让我们看看如何使用rpart来处理缺失值。
rpart_imp <- impute(train, target = "Loan_Status",
classes = list(numeric = imputeLearner(makeLearner("regr.rpart")),
factor = imputeLearner(makeLearner("classif.rpart"))),
dummy.classes = c("numeric","factor"),
dummy.type = "numeric")4. 特征工程
特征工程是预测性建模中最有趣的部分。因此,特征工程有两个方面。特征转换和特征创建。在这里,我们将尝试在这两个方面开展工作。
首先,让我们从ApplicantIncome、CoapplicantIncome、LoanAmount等变量中移除异常值。有很多技术可以去除异常值。在这里,我们将对这些变量中的所有大值进行捕捉,并将其设置为一个阈值,如下图所示。
#for train data set
cd <- capLargeValues(imp_train, target = "Loan_Status",cols = c("ApplicantIncome"),threshold = 40000)
cd <- capLargeValues(cd, target = "Loan_Status",cols = c("CoapplicantIncome"),threshold = 21000)
cd <- capLargeValues(cd, target = "Loan_Status",cols = c("LoanAmount"),threshold = 520)
#rename the train data as cd_train
cd_train <- cd
#add a dummy Loan_Status column in test data
imp_test$Loan_Status <- sample(0:1,size = 367,replace = T)
cde <- capLargeValues(imp_test, target = "Loan_Status",cols = c("ApplicantIncome"),threshold = 33000)
cde <- capLargeValues(cde, target = "Loan_Status",cols = c("CoapplicantIncome"),threshold = 16000)
cde <- capLargeValues(cde, target = "Loan_Status",cols = c("LoanAmount"),threshold = 470)
#renaming test data
cd_test <- cde我在分析了变量分布后,酌情选择了阈值。为了检查效果,你可以做summary(cd_train$ApplicantIncome),看到最大值被限定在33000。
在这两个数据集中,我们看到所有的虚拟变量都是数字性的。作为二进制的形式,它们应该是分类的。让我们把它们的类别转换为因子。这一次,我们将使用简单的for和if循环。
#convert numeric to factor - train
for (f in names(cd_train[, c(14:20)])) {
if( class(cd_train[, c(14:20)] [[f]]) == "numeric"){
levels <- unique(cd_train[, c(14:20)][[f]])
cd_train[, c(14:20)][[f]] <- as.factor(factor(cd_train[, c(14:20)][[f]], levels = levels))
}
}
#convert numeric to factor - test
for (f in names(cd_test[, c(13:18)])) {
if( class(cd_test[, c(13:18)] [[f]]) == "numeric"){
levels <- unique(cd_test[, c(13:18)][[f]])
cd_test[, c(13:18)][[f]] <- as.factor(factor(cd_test[, c(13:18)][[f]], levels = levels))
}
}这些循环说--"对于cd_train/cd_test数据框架的第14至20列的每一个列名,如果这些变量的类别是数字,就从这些列中取出唯一的值作为水平,并将它们转换成因子(分类)变量。
现在我们来创建一些新的特征。
#Total_Income
cd_train$Total_Income <- cd_train$ApplicantIncome + cd_train$CoapplicantIncome
cd_test$Total_Income <- cd_test$ApplicantIncome + cd_test$CoapplicantIncome
#Income by loan
> cd_train$Income_by_loan <- cd_train$Total_Income/cd_train$LoanAmount
> cd_test$Income_by_loan <- cd_test$Total_Income/cd_test$LoanAmount
#change variable class
> cd_train$Loan_Amount_Term <- as.numeric(cd_train$Loan_Amount_Term)
> cd_test$Loan_Amount_Term <- as.numeric(cd_test$Loan_Amount_Term)
#Loan amount by term
> cd_train$Loan_amount_by_term <- cd_train$LoanAmount/cd_train$Loan_Amount_Term
> cd_test$Loan_amount_by_term <- cd_test$LoanAmount/cd_test$Loan_Amount_Term在创建新的特征时(如果它们是数字的),我们必须检查它们与现有变量的相关性。
#splitting the data based on class
> az <- split(names(cd_train), sapply(cd_train, function(x){ class(x)}))
#creating a data frame of numeric variables
> xs <- cd_train[az$numeric]
#check correlation
> cor(xs)正如我们所看到的,总收入与申请人收入存在着非常高的相关性。这意味着这个新变量没有提供任何新的信息。因此,这个变量对建模数据没有帮助。
现在我们可以删除这个变量。
cd_train$Total_Income <- NULL
cd_test$Total_Income <- NULL仍然有足够的潜力来创建新的变量。在继续进行之前,我希望你能深入思考这个问题,并尝试创建更多新的变量。 在对数据做了这么多修改之后,让我们再次检查数据。
summarizeColumns(cd_train)
summarizeColumns(cd_test)5. 机器学习
到这里为止,我们已经执行了所有重要的转换步骤,除了对偏态的变量进行归一化。这将在我们创建任务后完成。
正如开头所解释的,对于mlr来说,任务只不过是学习者学习的数据集。由于这是一个分类问题,我们将创建一个分类任务。所以,任务类型完全取决于手头问题的类型。
#create a task
> trainTask <- makeClassifTask(data = cd_train,target = "Loan_Status")
> testTask <- makeClassifTask(data = cd_test, target = "Loan_Status")
> trainTask
Supervised task: cd_train
Type: classif
Target: Loan_Status
Observations: 614
Features:
numerics factors ordered
13 8 0
Missings: FALSE
Has weights: FALSE
Has blocking: FALSE
Classes: 2
N Y
192 422
Positive class: N正如你所看到的,它提供了一个cd_train数据的描述。然而,一个明显的问题是,它将正类视为N,而它应该是Y,让我们修改一下。
trainTask <- makeClassifTask(data = cd_train,target = "Loan_Status", positive = "Y")为了更深入的了解,你可以使用str(getTaskData(trainTask))检查你的任务数据。
现在,我们将对数据进行标准化处理。对于这一步,我们将使用mlr包中的normalizeFeatures函数。默认情况下,这个包会对数据中的所有数字特征进行标准化处理。值得庆幸的是,只有3个我们必须归一化的变量是数字,其余的变量都是数字以外的类别。
#normalize the variables
trainTask <- normalizeFeatures(trainTask,method = "standardize")
testTask <- normalizeFeatures(testTask,method = "standardize")在我们开始应用算法之前,我们应该删除那些不需要的变量。
trainTask <- dropFeatures(task = trainTask,features = c("Loan_ID","Married.dummy"))MLR包有一个内置函数,可以从数据中返回重要变量。让我们看看哪些变量是重要的。稍后,我们可以利用这些知识对输入的预测因子进行子集,以改进模型。在运行这段代码时,R可能会提示你安装 "FSelector "包,你应该这么做。
#Feature importance
im_feat <- generateFilterValuesData(trainTask, method = c("information.gain","chi.squared"))
plotFilterValues(im_feat,n.show = 20)#to launch its shiny application
plotFilterValuesGGVIS(im_feat)如果你仍然想知道信息.增益,让我提供一个简单的解释。信息增益一般是在决策树的背景下使用的。决策树中的每个节点分割都是基于信息增益的。一般来说,它试图找出携带最大信息的变量,使用这些变量可以更容易地预测目标类别。
让我们现在开始建模。我不会详细解释这些算法,但我提供了一些有用资源的链接。我们将首先学习较简单的算法,然后以复杂的算法结束本教程。
通过MLR,我们可以使用makeLearner选择和设置算法。这个学习者将在trainTask上进行训练,并尝试对testTask进行预测。
1. 二次判别分析,Quadratic Discriminant Analysis (QDA).
一般来说,qda是一种参数化的算法。参数化意味着它对数据做了某些假设。如果实际发现数据遵循假设,这样的算法有时会胜过一些非参数化算法。 Read More.
#load qda
> qda.learner <- makeLearner("classif.qda", predict.type = "response")
#train model
> qmodel <- train(qda.learner, trainTask)
#predict on test data
> qpredict <- predict(qmodel, testTask)
#create submission file
> submit <- data.frame(Loan_ID = test$Loan_ID, Loan_Status = qpredict$data$response)
> write.csv(submit, "submit1.csv",row.names = F)Upload 上传这个提交文件,并检查你的排行榜排名(不会是好事)。我们的准确率是~71.5%。我明白,这个提交文件可能不会让你在排行榜上名列前茅,但还有很长的路要走。所以,让我们继续吧。
2.逻辑回归 Logistic Regression
这一次,我们也来检查交叉验证 cross validation 的准确性。较高的交叉验证准确率决定了我们的模型不会受到高方差的影响,并且在未见过的数据上有很好的概括性。
#logistic regression
> logistic.learner <- makeLearner("classif.logreg",predict.type = "response")
#cross validation (cv) accuracy
> cv.logistic <- crossval(learner = logistic.learner,task = trainTask,iters = 3,stratify = TRUE,measures = acc,show.info = F)同样,你可以为任何学习者进行交叉验证。这不是非常容易吗?所以,我使用了分层抽样和3折CV。我一直建议你在分类问题上使用分层抽样,因为它能保持目标类在n个折中的比例。我们可以通过以下方式检查CV的准确性。
#cross validation accuracy
cv.logistic$aggr
acc.test.mean
0.7947553这是在5次折叠中计算出的平均精确度。要查看每个折页各自的准确性,我们可以这样做。
cv.logistic$measures.test
iter acc
1 1 0.8439024
2 2 0.7707317
3 3 0.7598039现在,我们将训练模型,并在测试数据上检查预测的准确性。
#train model
fmodel <- train(logistic.learner,trainTask)
getLearnerModel(fmodel)
#predict on test data
fpmodel <- predict(fmodel, testTask)
#create submission file
submit <- data.frame(Loan_ID = test$Loan_ID, Loan_Status = fpmodel$data$response)
write.csv(submit, "submit2.csv",row.names = F)Woah! 这个算法让我们的准确率有了明显的提升。此外,这是一个稳定的模型,因为我们的CV分数和排行榜上的分数密切匹配。这次提交的结果,准确率为79.16%。很好,我们现在正在改进。让我们前进到下一个算法。
3. 决策树-Decision Tree
据说决策树比逻辑回归模型能更好地捕捉非线性关系。让我们看看我们是否可以进一步改进我们的模型。这次我们将对树的参数进行超调,以达到最佳效果。要获得任何算法的参数列表,只需写下(本例中为rpart)。
getParamSet("classif.rpart")这将返回一长串可调整和不可调整的参数。 现在让我们建立一棵决策树。在创建树学习者之前,请确保你已经安装了rpart包。
#make tree learner
makeatree <- makeLearner("classif.rpart", predict.type = "response")#set 3 fold cross validation
set_cv <- makeResampleDesc("CV",iters = 3L)3折交叉验证
#Search for hyperparameters
> gs <- makeParamSet(
makeIntegerParam("minsplit",lower = 10, upper = 50),
makeIntegerParam("minbucket", lower = 5, upper = 50),
makeNumericParam("cp", lower = 0.001, upper = 0.2)
)正如你所看到的,我设置了3个参数。minsplit表示一个节点中发生分裂的最小观察数。minbucket表示我应该保留在终端节点中的最小观察数。cp是复杂性参数。它越小,树就会在数据中学习更多的具体关系,这可能会导致过度拟合。
#do a grid search
> gscontrol <- makeTuneControlGrid()
#hypertune the parameters
> stune <- tuneParams(learner = makeatree, resampling = set_cv, task = trainTask, par.set = gs, control = gscontrol, measures = acc)你可以去走走,直到参数调整完成。也许,你可以去抓一些小妖怪! 在我的机器上运行需要15分钟。我的机器是8GB的英特尔i5处理器的Windows机器。
#check best parameter
stune$x
# $minsplit
# [1] 37
#
# $minbucket
# [1] 15
#
# $cp
# [1] 0.001它返回一个最佳参数的列表。你可以用以下方法检查CV的准确性。
#cross validation result
stune$y
# 0.8127132使用setHyperPars函数,我们可以直接设置最佳参数作为算法中的建模参数。
#using hyperparameters for modeling
t.tree <- setHyperPars(makeatree, par.vals = stune$x)
#train the model
t.rpart <- train(t.tree, trainTask)
getLearnerModel(t.rpart)
#make predictions
tpmodel <- predict(t.rpart, testTask)
#create a submission file
submit <- data.frame(Loan_ID = test$Loan_ID, Loan_Status = tpmodel$data$response)
write.csv(submit, "submit3.csv",row.names = F)决策树的表现并不比逻辑回归好。该算法的准确率与逻辑回归相同,为79.14%。所以,一棵树是不够的。现在让我们建立一个森林。
4. 随机森林,Random Forest
随机森林是一种强大的算法,以产生惊人的结果而闻名。实际上,它的预测来自于一个树的集合。它对每棵树给出的预测进行平均,并产生一个概括性的结果。从这里开始,大部分的步骤都与上面类似,但这次我用随机搜索代替网格搜索来调整参数,因为它更快。
getParamSet("classif.randomForest")
#create a learner
rf <- makeLearner("classif.randomForest", predict.type = "response", par.vals = list(ntree = 200, mtry = 3))
rf$par.vals <- list(
importance = TRUE
)
#set tunable parameters
#grid search to find hyperparameters
rf_param <- makeParamSet(
makeIntegerParam("ntree",lower = 50, upper = 500),
makeIntegerParam("mtry", lower = 3, upper = 10),
makeIntegerParam("nodesize", lower = 10, upper = 50)
)
#let's do random search for 50 iterations
rancontrol <- makeTuneControlRandom(maxit = 50L)虽然,随机搜索比网格搜索快,但有时它的效率较低。在网格搜索中,算法对所提供的每个可能的参数组合进行调整。在随机搜索中,我们指定迭代的次数,它随机地通过参数组合。在这个过程中,它可能会错过一些重要的参数组合,而这些参数组合可能会产生最大的精确度,谁知道呢。
#set 3 fold cross validation
set_cv <- makeResampleDesc("CV",iters = 3L)
#hypertuning
rf_tune <- tuneParams(learner = rf, resampling = set_cv, task = trainTask, par.set = rf_param, control = rancontrol, measures = acc)现在,我们有了最后的参数。让我们检查一下参数列表和简历的准确性。
#cv accuracy
rf_tune$y
acc.test.mean
0.8192571
#best parameters
rf_tune$x
$ntree
[1] 168
$mtry
[1] 6
$nodesize
[1] 29现在让我们建立随机森林模型并检查其准确性。
#using hyperparameters for modeling
> rf.tree <- setHyperPars(rf, par.vals = rf_tune$x)
#train a model
> rforest <- train(rf.tree, trainTask)
> getLearnerModel(t.rpart)
#make predictions
> rfmodel <- predict(rforest, testTask)
#submission file
> submit <- data.frame(Loan_ID = test$Loan_ID, Loan_Status = rfmodel$data$response)
> write.csv(submit, "submit4.csv",row.names = F)没有新的故事可以欢呼。这个模型也返回了79.14%的准确性。因此,请尝试使用网格搜索而不是随机搜索,并在评论中告诉我你的模型是否有所改进。
5. 支持向量机,SVM
支持向量机(SVM)也是一种用于回归和分类问题的监督学习算法。一般来说,它在n维空间创建一个超平面,根据目标类别对数据进行分类。让我们暂时远离树形算法,看看这种算法是否能给我们带来一些改进。
因为,大部分的步骤都与上面执行的类似,我认为对你来说,理解这些代码不再是一个挑战。
#load svm
getParamSet("classif.ksvm") #do install kernlab package
ksvm <- makeLearner("classif.ksvm", predict.type = "response")
#Set parameters
pssvm <- makeParamSet(
makeDiscreteParam("C", values = 2^c(-8,-4,-2,0)), #cost parameters
makeDiscreteParam("sigma", values = 2^c(-8,-4,0,4)) #RBF Kernel Parameter
)
#specify search function
ctrl <- makeTuneControlGrid()
#tune model
res <- tuneParams(ksvm, task = trainTask, resampling = set_cv, par.set = pssvm, control = ctrl,measures = acc)
#CV accuracy
res$y
acc.test.mean
0.8062092
#set the model with best params
t.svm <- setHyperPars(ksvm, par.vals = res$x)
#train
par.svm <- train(ksvm, trainTask)
#test
predict.svm <- predict(par.svm, testTask)
#submission file
submit <- data.frame(Loan_ID = test$Loan_ID, Loan_Status = predict.svm$data$response)
write.csv(submit, "submit5.csv",row.names = F)这个模型的准确率为77.08%。不错,但比我们的最高分要低。在这里,不要感到无望。这就是核心的机器学习。除非得到一些好的变量,否则ML是不工作的。也许,你应该在特征工程方面考虑得更多,并创造更多有用的变量。现在让我们来做提升。
6. 梯度提升机,Gradient Boosting Machine-GBM
现在你正在进入提升算法的领域。GBM执行顺序建模,即在一轮预测后,它检查不正确的预测,给它们分配相对更多的权重,并再次预测,直到它们被正确预测。
#load GBM
getParamSet("classif.gbm")
g.gbm <- makeLearner("classif.gbm", predict.type = "response")
#specify tuning method
rancontrol <- makeTuneControlRandom(maxit = 50L)
#3 fold cross validation
set_cv <- makeResampleDesc("CV",iters = 3L)
#parameters
gbm_par<- makeParamSet(
makeDiscreteParam("distribution", values = "bernoulli"),
makeIntegerParam("n.trees", lower = 100, upper = 1000), #number of trees
makeIntegerParam("interaction.depth", lower = 2, upper = 10), #depth of tree
makeIntegerParam("n.minobsinnode", lower = 10, upper = 80),
makeNumericParam("shrinkage",lower = 0.01, upper = 1)
)
n.minobsinnode指的是树节点中的最小观测值数量。 shrinkage是调节参数,决定了算法的移动速度/速度。
#tune parameters
tune_gbm <- tuneParams(learner = g.gbm, task = trainTask,resampling = set_cv,measures = acc,par.set = gbm_par,control = rancontrol)
#check CV accuracy
tune_gbm$y
#set parameters
final_gbm <- setHyperPars(learner = g.gbm, par.vals = tune_gbm$x)
#train
to.gbm <- train(final_gbm, traintask)
#test
pr.gbm <- predict(to.gbm, testTask)
#submission file
submit <- data.frame(Loan_ID = test$Loan_ID, Loan_Status = pr.gbm$data$response)
write.csv(submit, "submit6.csv",row.names = F)该模型的准确率为78.47%。GBM的表现比SVM好,但不能超过随机森林的准确性。最后,我们也来测试一下XGboost。
7. Xgboost
Xgboost被认为比GBM更好,因为它的内在属性包括一阶和二阶梯度、并行处理和修剪树的能力。Xgboost的一般实现需要你将数据转换为矩阵。有了mlr,这就不需要了。
正如我在一开始所说的,使用这个(MLR)包的一个好处是,你可以按照同一套命令来实现不同的算法。
#load xgboost
set.seed(1001)
getParamSet("classif.xgboost")
#make learner with inital parameters
xg_set <- makeLearner("classif.xgboost", predict.type = "response")
xg_set$par.vals <- list(
objective = "binary:logistic",
eval_metric = "error",
nrounds = 250
)
#define parameters for tuning
xg_ps <- makeParamSet(
makeIntegerParam("nrounds",lower=200,upper=600),
makeIntegerParam("max_depth",lower=3,upper=20),
makeNumericParam("lambda",lower=0.55,upper=0.60),
makeNumericParam("eta", lower = 0.001, upper = 0.5),
makeNumericParam("subsample", lower = 0.10, upper = 0.80),
makeNumericParam("min_child_weight",lower=1,upper=5),
makeNumericParam("colsample_bytree",lower = 0.2,upper = 0.8)
)
#define search function
rancontrol <- makeTuneControlRandom(maxit = 100L) #do 100 iterations
#3 fold cross validation
set_cv <- makeResampleDesc("CV",iters = 3L)
#tune parameters
xg_tune <- tuneParams(learner = xg_set, task = trainTask, resampling = set_cv,measures = acc,par.set = xg_ps, control = rancontrol)
#set parameters
xg_new <- setHyperPars(learner = xg_set, par.vals = xg_tune$x)
#train model
xgmodel <- train(xg_new, trainTask)
#test model
predict.xg <- predict(xgmodel, testTask)
#submission file
submit <- data.frame(Loan_ID = test$Loan_ID, Loan_Status = predict.xg$data$response)
write.csv(submit, "submit7.csv",row.names = F)糟糕的XGBoost。这个模型返回的准确率为68.5%,甚至比qda还低。可能发生什么?过度拟合。所以,这个模型返回的CV准确率约为80%,但排行榜上的分数却急剧下降,因为这个模型无法对未见过的数据进行正确预测。
8.特征选择
为了改进,让我们这样做。直到这里,我们一直使用trainTask来建立模型。让我们使用重要变量的知识。首先取6个重要的变量,然后在这些变量上训练模型。你可以期待一些改进。要创建一个选择重要变量的任务,请这样做。
#selecting top 6 important features
top_task <- filterFeatures(trainTask, method = "rf.importance", abs = 6)所以,我要求这个函数使用随机森林的重要性特征来获得前6个重要特征。现在,在上面的模型中用trainTask替换top_task,并在评论中告诉我你是否有任何改进。
另外,试着创造更多的特征。目前排行榜上的冠军准确率为~81%。如果你一直跟着我到这里,现在不要放弃。
结束语
这篇文章的动机是让你开始学习机器学习技术。这些技术在今天的工业中普遍使用。因此,请确保你能很好地理解它们。不要把这些算法当作黑箱方法来使用,要充分理解它们。我已经提供了资源的链接。
上面发生的事情在现实生活中经常发生。你会尝试很多算法,但在准确性方面不会得到改善。但是,你不应该放弃。作为一个初学者,你应该尝试探索其他方法来实现准确性。记住,无论你做了多少次错误的尝试,你只需要做对一次。
在加载这些模型时,你可能要安装软件包,但那只是一次。如果你完全遵循这篇文章,你已经准备好建立模型了。你所要做的就是,学习它们背后的理论。
你觉得这篇文章有帮助吗?你尝试过我上面列出的改进方法吗?哪种算法给了你最大的准确性?在下面的评论中分享你的观察/经验。
https://www.analyticsvidhya.com/blog/2016/08/practicing-machine-learning-techniques-in-r-with-mlr-package/