ViT学习笔记
ViT与Vitae笔记
文章目录
- ViT与Vitae笔记
- 前言
- 一、ViT模型与详解
-
- 1.图像分块处理
- 2.位置信息编码
- 3.Norm&Mutil-Head Attention
- 4.Resnet
- 5.MLP
- 6.最终分类输出
- 二、GELU激活函数和SiLu激活函数
- 总结
前言
传统的Transformer模型在NLP领域研究中显示出主导趋势,这是因为他们有很强
的能力通过自我注意机制来模拟长期依赖,Transformer的这种成功和良好的特性
启发了许多将其应用于各种计算机视觉任务的作品。
Vitae即vision transformer advanced取得相当不错的成效,这篇文章主要介
绍传统Transformer到Vitae所做的改进,并且作为笔记记录一下。
一、ViT模型与详解

1.图像分块处理
最初始应用于NLP领域的Transformer处理的为序列数据,即数据格式为
[batch,sentence_len],而最常用的图像数据格式为[Height,Width,Channel],
因此,要将Transformer应用于计算机视觉领域,首先得进行数据转换,即将图像数据转换为序列数据。
假设一个图像数据大小为[224×224×3],可以采用尺寸大小为14×14,步长为14,无零填充层的卷积核,数量为369,从而输出得到[16×16×369],然后将Height和Width两个维度展平可以得到[256×369]的二维数据,就得到Transformer能够处理的数据格式。更形象一点的说法是将图像的一小块类比为一个单词,整副图像就相当于一句话。
2.位置信息编码
要在刚刚的patch向量中加入class token和每个patch所在的位置信息,也就是position embedding。class token就是每个sequence开头的一个数字。
一张图片的一串patch是一个sequence, 所以class token就加在它们前面,因此变为[257,369],传统Transformer中的位置编码是采用公式添加固定的信息,而ViT模型采用了可训练的位置信息参数
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
nn.Parameter() 可将生成的参数添加到整个模型优化过程中,从而更好表示位置信息。
3.Norm&Mutil-Head Attention
层标准化与多头自注意力机制在上篇文章已经提过,可以参考深度学习之Transformer
4.Resnet


残差对应这两部分,会多次调用,因此我们直接写出函数
class Residual(nn.Module):
def __init__(self, f):
super().__init__()
self.fn = f
def forward(self, x, **kwargs):
residual = x
x = self.fn(x, **kwargs)
x += residual
return x
Resnet网络可参考Resnet
5.MLP
MLP即为多层感知机,实际上就是多层全连接,即

class FeedForward(nn.Sequential):
def __init__(self, emb_size, expansion, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
)
6.最终分类输出

在分类部分,ViT所做的工作是利用提取到的特征进行分类。
在进行特征提取的时候,我们第一步在图片序列中添加的Class Token,该Token会作为一个单位的序列信息一起进行特征提取,在提取的过程中,该Class Token会与其它的特征进行特征交互,融合其它图片序列的特征,
最终,我们利用Multi-head Self-attention结构提取特征后的Class Token进行全连接分类,输出最终分类得分。
x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0]
可以看到,如果池化类型为‘mean’,则会对全部Token进行平均池化,默认不是,因此只会取第一步加进来的那个融合其他图片序列各种特征的Class Token输入到MLP,最终输出结果。
二、GELU激活函数和SiLu激活函数
GELU(gaussian error linear units)就是我们常说的高斯误差线性单元,它是一种高性能的神经网络激活函数。
不同于进行阈值硬判决的ReLu函数,GELU函数根据输入的大小赋予其应有的权重,而实现是通过最常用的高斯分布累积函数,即

而GELU函数的表达式如下:
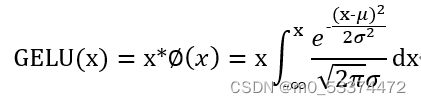
SiLu激活函数表达式如下:

这两个激活函数常出现在ViTAE架构中,在ViT中也有所使用。
总结
总结了Vision Transformer对比传统Transformer改进的地方,为学习ViTAE打下基础,会更注意细节问题。