什么是人工智能?什么是机器学习?什么是深度学习?三连问
人工智能
- 人工智能
- 机器学习
-
- 有监督学习
- 无监督学习
- 半监督学习
- 强化学习
- 深度学习
-
- 神经网络
- 三者之间的关系
最近机器学习,深度学习频繁出现人工智能领域,成为高频词汇,但是好多同学对这些同学一知半解,一会儿这个学习,一会儿又那个学习的,所以这篇文章,主要是来给同学们介绍这三者之间的关系以及概念性的一些理解,我觉得对于入门这个领域很有帮助。
人工智能
其实我们通过一些科幻电影,比如《我,机器人》,《终结者》系列吗,我们大致可以明白,所谓的人工智能的理想状态就是机器有人的思维,可以理解问题,判断问题,解决问题。从这句话我希望告诉同学们。人工智能是指能力,而不是设备,机器只是一种明显的表现方式。
那么随着时代的发展,人工智能的研究领域也在不断扩大,细分出了很多智能化的领域,比如说自然语言处理,计算机视觉,进化计算,推荐系统等等很多,下图展示了人工智能研究的各个分支。
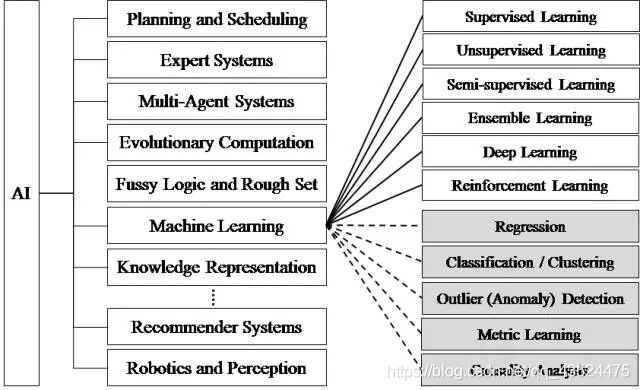
但是就目前AI的发展(人工智能根据能力等级划分,分别是弱智能,强智能,超智能)来说,大部分来说都是弱智能,让机器具备观察和感知的能力,可以做到一定程度的理解和推理,比如现在邮箱自动过滤,自动拦截骚扰电话等。而电影里的人工智能多半都是在描绘强人工智能,而这部分在目前的现实世界里难以真正实现,而强人工智能让机器获得自适应能力,解决一些之前没有遇到过的问题。对比弱智能和强智能,弱智能的学习能力是有人们介入的,比如机器需要学习什么东西,那有关于这个东西的一系列特征,属性…都是人类给予的,而强智能能够有自己的思考方式,能够进行推理然后制作计划,最后进行执行,并且拥有一定的学习能力,能够在实践当中不断进步。那超智能,那基本上其思考能力超越人类了,也许超智能可以比人类提前进入某种未知的领域,且还能自己进行研究。
机器学习
弱人工智能有希望取得突破,是如何实现的,“智能”又从何而来呢?这主要归功于一种实现人工智能的方法——机器学习。
在开始学习之前,我们来感受一下,什么是机器学习
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能核心,是使计算机具有智能的根本途径。
通过定义 ,我们突然感受到 机器学习不好学,又要懂得多科数学运算,还要知道代码如何编写,甚至还要研究人类的学习学习。其实不然,我们先感受一个机器学习的例子
我们想要完成做出一个效果,就是可以让机器能辨别出面前的酒是个什么酒,然后我们来到一个酒吧里,酒吧老板也很愿意帮助我们,于是拿拿出了十个酒杯,告诉我们:你眼前的这十杯红酒,每杯略不相同,前五杯属于「赤霞珠」后五杯属于「黑皮诺」。现在,我重新倒一杯酒,你只需要正确地告诉我它属于哪一类。

那我们是如何解决这个问题的呢?
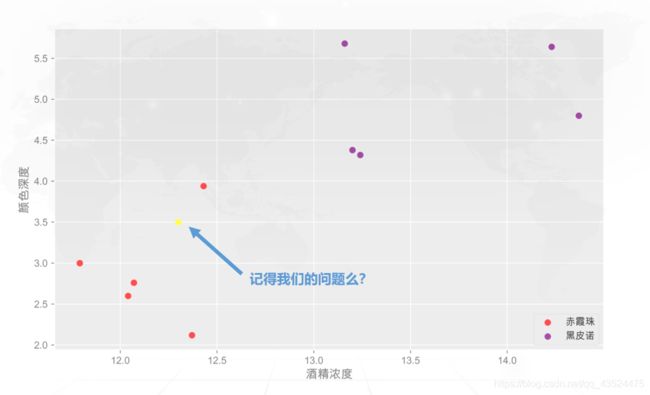
我们将老板提供的信息:酒精浓度,颜色深度搜集起来,作为一个数据集,并且制作出一个模型,如上图(散点图),我们通过模型,我们就可以发现,两种酒的酒精浓度和颜色深度在散点图中,分布在一定的区域内 ,我们根据新倒的一杯酒然后去匹配,那么匹配在哪一个区域,那么就是哪种酒的可能性就大。
这里我们所处理的问题叫做「分类问题」机器学习的方法是基于数据产生的 “模型”(model)的算法,也称 “学习算法”(learning algorithm), 所以说机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
- 有监督学习(supervised learning)
- 无监督学习(unsupervised learning)
- 半监督学习(semi-supervised learning)
- 强化学习(reinforcement learning)
以上四种就是机器学习常用算法的体系吧~
有监督学习
指对数据的若干特征与**若干标签(类型)**之间的关联性进行建模的过程;只要模型被确定,就可以应用到新的未知数据上。这类学习过程可以进一步分为
- 「分类」(classification)任务
- 「回归」(regression)任务
在分类任务中,标签都是离散值;而在回归任务中,标签都是连续值。
在上面的场景中,每一杯酒称作一个样本,十杯酒组成一个样本集。酒精浓度、颜色深度等信息称作特征。这十杯酒分布在一个多维特征空间中。进入当前程序的“学习系统”的所有样本称作输入,并组成输入空间。在学习过程中,所产生的随机变量的取值,称作输出,并组成输出空间。
- 在有监督学习过程中,当输出变量均为连续变量时,预测问题称为回归问题;
- 当输出变量为有限个离散变量时,预测问题称为分类问题。
其实我们是不是可以理解为就是说,有监督学习,就是我们知道了一个题的答案,我们把这些答案组成一个整体的样本集,然后统计发给机器去学习,当样本集达到了一定量之后,机器就跟人一样,这个东西我见多了,我见的习惯,下次再见,我就知道这个东西是什么的概率比较大了。
无监督学习
指对不带任何标签的数据特征进行建模,通常被看成是一种 “让数据自己介绍自己” 的过程。这类模型包括
- 「聚类」(clustering)任务
- 「降维」(dimensionality reduction)任务
聚类算法可以讲数据分成不同的组别,而降维算法追求用更简洁的方式表现数据。
与有监督学习相比,好像我们并不告诉机器我们给的数据是什么,答案是什么,我们让机器去尝试,一个类型的答案看多了,也就自然而然的构成了一种人类的“惯性思维
半监督学习
另外,还有一种半监督学习(semi-supervised learning)方法, 介于有监督学习和无监督学习之间。通常可以在数据不完整时使用。
强化学习
强化学习不同于监督学习,它将学习看作是试探评价过程,以 “试错” 的方式进行学习,并与环境进行交互已获得奖惩指导行为,以其作为评价。此时系统靠自身的状态和动作进行学习,从而改进行动方案以适应环境。
这个过程就很像我们训练宠物一样,比如训练狗狗做一下,让狗狗坐下,狗狗坐下来了,我们奖励它一根烤肠吃,没坐下,我们就拍一下它的脑袋,时间长了,是不是狗狗就知道我们坐下才有东西吃。
深度学习
那机器学习是如何能够做到通过各种算法从数据中学习完成任务的呢,此时,深度学习就出现了,深度学习:一种实现机器学习的技术。
深度学习本来并不是一种独立的学习方法,其本身也会用到有监督和无监督的学习方法来训练深度神经网络。但由于近几年该领域发展迅猛,一些特有的学习手段相继被提出(如残差网络),因此越来越多的人将其单独看作一种学习的方法。
神经网络
可以说人工智能的核心的核心就是神经网络,因为直到人工神经网络技术的出现,才让机器拥有了“真智能”。因为在神经网络之前,我们人类能清清楚楚地知道机器内部的分析过程,它们只是一个大型的复杂的程序而已;它是由规律可寻找的,而人工神经网络则不同,它的内部是一个黑盒子,就像我们人类的大脑一样,我们不知道它内部的分析过程,我们不知道它是如何识别出人脸的,也不知道它是如何打败围棋世界冠军的。我们只是为它构造了一个躯壳而已,就像人类一样,我们只是生出了一个小孩而已,他脑子里是如何想的我们并不知道!这就是人工智能的可怕之处。
听名词我们就可以了解到:所谓的人工神经网络就是在模拟人类大脑结构,在人类的大脑中,有数十亿个称为神经元的细胞,它们连接成了一个神经网络。在初中的生物学当中,我们知道人类大脑神经元细胞的树突接收来自外部的多个强度不同的刺激,并在神经元细胞体内进行处理,然后将其转化为一个输出结果。
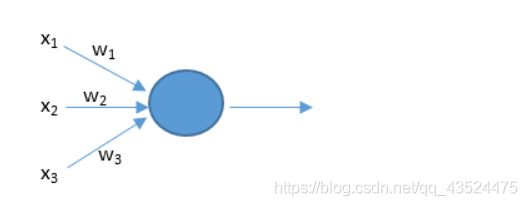
那么我们在神经网络中,x是神经元的输入,相当于树突接收的多个外部刺激。w是每个输入对应的权重,它影响着每个输入x的刺激强度。如下图
大脑的结构越简单,那么智商就越低。单细胞生物是智商最低的了。人工神经网络也是一样的,网络越复杂它就越强大,所以我们需要深度神经网络。这里的深度是指层数多,层数越多那么构造的神经网络就越复杂。
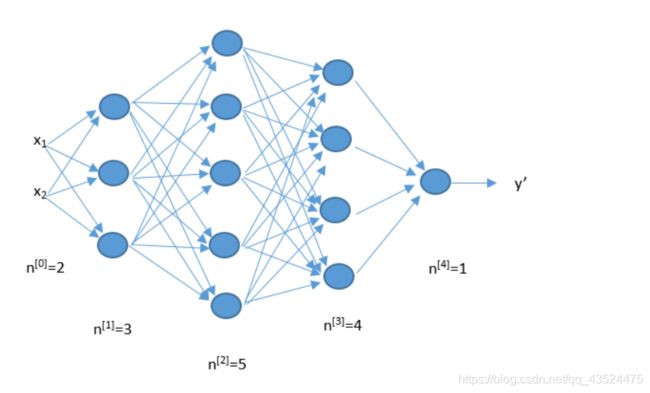
训练深度神经网络的过程就叫做深度学习,网络构建好了后,我们只需要负责不停地将训练数据输入到神经网络中,它内部就会自己不停地发生变化不停地学习。打比方说我们想要训练一个深度神经网络来识别猫。我们只需要不停地将猫的图片输入到神经网络中去。训练成功后,我们任意拿来一张新的图片,它都能判断出里面是否有猫。但我们并不知道他的分析过程是怎样的,它是如何判断里面是否有猫的。但是机器的分析过程是怎么样的?我们无从知道~~
最初的深度学习是利用深度神经网络来解决特征表达的一种学习过程。深度神经网络本身并不是一个全新的概念,可大致理解为包含多个隐含层的神经网络结构。为了提高深层神经网络的训练效果,人们对神经元的连接方法和激活函数等方面做出相应的调整。其实有不少想法早年间也曾有过,但由于当时训练数据量不足、计算能力落后,因此最终的效果不尽如人意。
深度学习摧枯拉朽般地实现了各种任务,使得似乎所有的机器辅助功能都变为可能。无人驾驶汽车,预防性医疗保健,甚至是更好的电影推荐,都近在眼前,或者即将实现。
三者之间的关系
不过有几点,还是要声明一下的
目前,业界有一种错误的较为普遍的意识,即“深度学习最终可能会淘汰掉其他所有机器学习算法”。这种意识的产生主要是因为,当下深度学习在计算机视觉、自然语言处理领域的应用远超过传统的机器学习方法,并且媒体对深度学习进行了大肆夸大的报道。深度学习,作为目前最热的机器学习方法,但并不意味着是机器学习的终点。
起码目前存在以下问题:
- 深度学习模型需要大量的训练数据,才能展现出神奇的效果,但现实生活中往往会遇到小样本问题,此时深度学习方法无法入手,传统的机器学习方法就可以处理;
- 有些领域,采用传统的简单的机器学习方法,可以很好地解决了,没必要非得用复杂的深度学习方法;
- 深度学习的思想,来源于人脑的启发,但绝不是人脑的模拟,举个例子,给一个三四岁的小孩看一辆自行车之后,再见到哪怕外观完全不同的自行车,小孩也十有八九能做出那是一辆自行车的判断,也就是说,人类的学习过程往往不需要大规模的训练数据,而现在的深度学习方法显然不是对人脑的模拟。