吴恩达深度学习笔记——神经网络与深度学习(Neural Networks and Deep Learning)
文章目录
- 前言
- 传送门
- 神经网络与深度学习(Neural Networks and Deep Learning)
-
- 绪论
- 梯度下降法与二分逻辑回归(Gradient Descend and Logistics Regression)
-
- forward propagation
- backward propagation(with Chain Rule)
- vectorization
- 损失函数和成本函数推导(Loss Function | Cost Function)
- 多层神经网络入门
-
- 一些符号的规定
- 神经网络的向量化fp
- 神经网络的向量化bp
- 神经网络函数块
-
- fp块
- bp块
- 一轮迭代的处理流程
- 激活函数
-
- 可选项
- 导数计算(prime)
- 随机初始化
- 深层网络的合理性
前言
本系列文章是吴恩达深度学习攻城狮系列课程的笔记,分为五部分。
这一部分讲了深度学习和神经网络的最基础的概念,这一章尤为重要,尤其是要理解神经网络的合理性,建立直觉。
我的笔记不同于一般的笔记,我的笔记更加凝练,除了结论以及公式,更多的是对知识的理解,结合课程可以加速理解,省去很多时间,但是请注意,笔记不能替代课程,应该结合使用。
传送门
结构化机器学习项目,我建议放在最后看。
首先学这一节对你后面的学习没有影响,我就是跳过去学的。而且他更多的讲的是策略,尤其是举了很多后面的例子,你听了不仅不太好懂,而且没啥意思,所以我建议放在最后看。
神经网络与深度学习(Neural Networks and Deep Learning)
改善深层神经网络:超参数调整,正则化,最优化(Hyperparameter Tuning)
卷积神经网络(Convolutional Neural Networks)
序列模型与循环神经网络(Sequence Models)
结构化机器学习项目(Structuring Machine Learning Projects)
神经网络与深度学习(Neural Networks and Deep Learning)
绪论
梯度下降的公式为:
w = w − α d w w=w-\alpha dw w=w−αdw
这让我们想到牛顿法:
x = x − f ( x ) f ′ ( x ) x=x-\dfrac{f(x)}{f^\prime(x)} x=x−f′(x)f(x)
这两个有什么区别呢?思想都是迭代,但是实际完全不一样,最简单的场景:
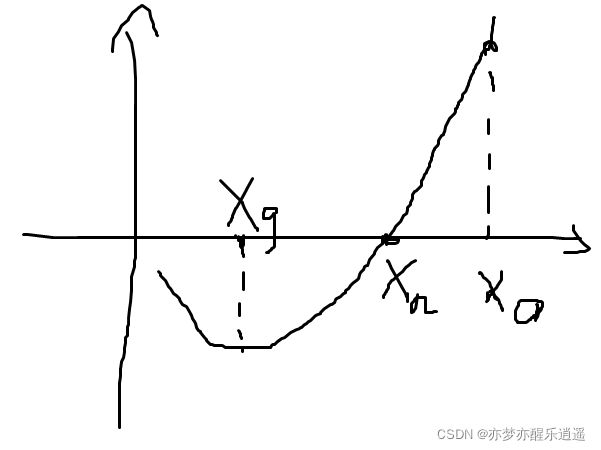
我们从 x 0 x_0 x0开始跑,就会发现,最后gradient-descent会收敛到 x g x_g xg但是牛顿法收敛到 x n x_n xn
虽然方向都是导数负方向,但是步长是这两个方法的本质区别“”
- gradient-descent的步长不由 α \alpha α决定,而是由导数决定,导数越大,下降越快,什么时候不动了呢?就是 f ′ ( x ) f^\prime(x) f′(x)为0的时候,也就是谷底。
- 牛顿法的步长由 f ( x ) f ′ ( x ) \dfrac{f(x)}{f^\prime(x)} f′(x)f(x)决定,如果假设导数仅仅决定方向,那么 f ( x ) f(x) f(x)越大,下降越快。什么时候不动了呢?就是 f ( x ) = 0 f(x)=0 f(x)=0,也就是零点。
梯度下降法与二分逻辑回归(Gradient Descend and Logistics Regression)
forward propagation
- 样本: X ( i ) X^{(i)} X(i)是一个n维向量,总共给定m个样本
- 样本矩阵: [ X ( 1 ) , ⋯ , X ( m ) ] n × m [X^{(1)},\cdots,X^{(m)}]_{n\times m} [X(1),⋯,X(m)]n×m
- 参数: w w w 是一个n维向量$ b b b是一个实数,我们的目标就是通过不断的迭代调整这两个参数
- 实际值和预测值:
实际值为 y y y,仅有0,1两种
预测值是一个概率,写作 a = y ^ = σ ( z ( i ) ) a=\hat{y}=\sigma(z^{(i)}) a=y^=σ(z(i))
z ( i ) = w T X ( i ) + b z^{(i)}=w^TX^{(i)}+b z(i)=wTX(i)+b,z只是一个最初的预测,是在R范围上的,要进行转化
σ ( x ) = 1 1 + e − x \sigma(x)=\dfrac{1}{1+e^{-x}} σ(x)=1+e−x1,这个激活函数将R上的z变为0-1之间的数,可以理解为概率。 - 损失函数: L ( a , y ) = − ( y log ( a ) + ( 1 − y ) log ( 1 − a ) ) L(a,y)=-(y\log(a)+(1-y)\log(1-a)) L(a,y)=−(ylog(a)+(1−y)log(1−a)),代表单个样本的差距
- 成本函数: J ( w , b ) = 1 m ∑ L ( a ( i ) , y ( i ) ) J(w,b)=\dfrac{1}{m}\sum L(a^{(i)},y^{(i)}) J(w,b)=m1∑L(a(i),y(i)),代表样本总体的平均差距
backward propagation(with Chain Rule)
使用计算图+链式法则求导,省略部分步骤,直接到关键步
- d z ( i ) = a ( i ) − y ( i ) dz^{(i)}=a^{(i)}-y^{(i)} dz(i)=a(i)−y(i),对每一个 x ( i ) x^{(i)} x(i),都有一个 d z ( i ) dz^{(i)} dz(i)
- d w i = 1 m ∑ x i ( i ) d z ( i ) dw_i=\dfrac{1}{m}\sum x_i^{(i)}dz^{(i)} dwi=m1∑xi(i)dz(i),对每一个 w w w,都是由m个 X ( i ) X^{(i)} X(i)生成,其中 w w w的每一个元,都是有m个 X ( i ) X^{(i)} X(i)的对应元生成
- d b = d z db=dz db=dz ,db由所有 d z ( i ) dz^{(i)} dz(i)生成
vectorization
避免使用显式的for loop,而是改用numpy的向量和矩阵运算函数,其中内置了大量的加速算法,以及调用多线程,充分利用CPU以及GPU的计算资源,可以将性能提高百倍以上。
总体流程为fp: w , b , X − > Z , σ − > A w,b,X->Z,\sigma->A w,b,X−>Z,σ−>A,bp: A , Y − > d Z , X − > d w , d b A,Y->dZ,X->dw,db A,Y−>dZ,X−>dw,db, 将 w 和 b 将w和b 将w和b迭代然后不断循环,直至足够准确。
- 将 m 个 X 样本写成一个矩阵为 X ,然后分块 将m个X样本写成一个矩阵为X,然后分块 将m个X样本写成一个矩阵为X,然后分块 [ X ( 1 ) , ⋯ , X ( m ) ] [X^{(1)},\cdots,X^{(m)}] [X(1),⋯,X(m)]
- 将 m 个 y 样本写成一个矩阵为 将m个y样本写成一个矩阵为 将m个y样本写成一个矩阵为 Y = [ y ( 1 ) , ⋯ , y ( m ) ] Y=[y^{(1)},\cdots, y^{(m)}] Y=[y(1),⋯,y(m)]
- 将 z ( i ) 写成矩阵,为 将z^{(i)}写成矩阵,为 将z(i)写成矩阵,为 Z = [ z ( 1 ) , ⋯ , z ( m ) ] Z=[z^{(1)},\cdots, z^{(m)}] Z=[z(1),⋯,z(m)]
- 则有 则有 则有 Z = w T X + B = w T [ X ( 1 ) , ⋯ , X ( m ) ] Z=w^TX+B=w^T[X^{(1)},\cdots, X^{(m)}] Z=wTX+B=wT[X(1),⋯,X(m)]
= [ w T X ( 1 ) , ⋯ , w T X ( m ) ] =[w^TX^{(1)},\cdots,w^TX^{(m)}] =[wTX(1),⋯,wTX(m)],
这就是一个简单的分块矩阵然后 w T 左乘 这就是一个简单的分块矩阵然后w^T左乘 这就是一个简单的分块矩阵然后wT左乘 就是相当于对分块矩阵行进行作用 就是相当于对分块矩阵行进行作用 就是相当于对分块矩阵行进行作用 - 对 Z 矩阵进行 σ 作用,转换成 A 矩阵 对Z矩阵进行\sigma作用,转换成A矩阵 对Z矩阵进行σ作用,转换成A矩阵
- d Z = A − Y ,很明显,两个行向量直接相减即可得出 d Z dZ=A-Y,很明显,两个行向量直接相减即可得出dZ dZ=A−Y,很明显,两个行向量直接相减即可得出dZ
- d w = 1 m X d Z T dw=\dfrac{1}{m}XdZ^T dw=m1XdZT,这一步看着有点迷惑,但是确实有效,从效果上,可以理解为用每一个 z ( i ) 作用到一列 X ( i ) z^{(i)}作用到一列X^{(i)} z(i)作用到一列X(i)上,然后通过矩阵积的性质实现累加,最后外面挂个求均值得出结果
- d b = 对 d Z 向量求均值 db=对dZ向量求均值 db=对dZ向量求均值
损失函数和成本函数推导(Loss Function | Cost Function)
损失函数 L ( a , y ) = − [ y log ( a ) + ( 1 − y ) log ( 1 − a ) ] L(a,y)=-[y\log(a)+(1-y)\log(1-a)] L(a,y)=−[ylog(a)+(1−y)log(1−a)]
成本函数
- 损失函数
定义 a = P ( y = 1 ∣ X ) a=P(y=1|X) a=P(y=1∣X),即给定样本下得出y=1的概率。那么,反过来。 P ( y = 0 ∣ X ) = 1 − a P(y=0|X)=1-a P(y=0∣X)=1−a,即,给定X得出y=0的概率为1-a
对于单个样本,即 X X X,他的真实结果不是0,就是1,也就是说,是两点分布。那么我们可以写出 P ( y ∣ X ) = a y ( 1 − a ) 1 − y P(y|X)=a^y(1-a)^{1-y} P(y∣X)=ay(1−a)1−y,这是个很经典的两点分布写法,分别取y=1和0,可以得出我们最开始的两种情况。
然后左右两边同取log(实际上是ln),得 log ( P ) = y a + ( 1 − y ) ( 1 − a ) \log(P)=ya+(1-y)(1-a) log(P)=ya+(1−y)(1−a),因为我们用梯度下降,是要最小化,所以为了最大化概率P,我们要在损失函数前加负号,这样,当我们把损失函数最小化,那么里面的非负部分就是最大化的了,即P最大。
- 成本函数
成本函数使用极大似然估计推导。
首先,假设m个样本都是独立同分布的,这个应该在找样本的时候就确保好,然后我们就可以用最大似然估计了。
P ( X ∣ θ ) = ∏ P ( y i ∣ X i ) P(X|\theta)=\prod P(y^i|X^i) P(X∣θ)=∏P(yi∣Xi),然后用最大似然估计的套路,左右取ln,得出 log P ( X ∣ θ ) = − ∑ L ( a i , y i ) \log P(X|\theta)=-\sum L(a^i,y^i) logP(X∣θ)=−∑L(ai,yi),为了使P最大,需要令 ∑ L ( a i , y i ) \sum L(a^i,y^i) ∑L(ai,yi)最小,出于某种原因,我们给他前面加了一个常数来进行一个缩放,最后就是 J ( w , b ) = 1 m ∑ L ( a i , y i ) J(w,b)=\dfrac{1}{m}\sum L(a^i,y^i) J(w,b)=m1∑L(ai,yi)
其实这个也可以直观理解。
让所有样本的平均损失最小,不就整体最优了嘛。
多层神经网络入门
一些符号的规定
- 神经网络分层,用[] 作为上标来表明层数,输入层为0层,所以通常观念中,输入层不算做神经网络层中的一层。L为总层数。
- n x = n [ 0 ] n_x=n^{[0]} nx=n[0],为输入特征数, , n [ i ] ,n^{[i]} ,n[i]为每层的神经元个数,理论上这两个其实是一类东西,因为每一层经过神经元作用后,输到下一层的特征数就会变成n
- 每一层的每一个节点都是神经元,每一个节点分为两部分,第一部分是使用 w 作用 w作用 w作用,第二部分是激活函数作用。一个神经元就相当于我们前面的logistic 回归,一层就是若干个logistic回归堆叠而成。
- W m × n [ i ] = W n [ i ] × n [ i − 1 ] [ i ] 代表第 i 层的神经网络参数,是 w 的推广 W^{[i]}_{m\times n}=W^{[i]}_{n^{[i]}\times n^{[i-1]}}代表第i层的神经网络参数,是w的推广 Wm×n[i]=Wn[i]×n[i−1][i]代表第i层的神经网络参数,是w的推广, 可以看做是当前层所有节点的 w T 垂直 堆叠而成 可以看做是当前层所有节点的w^T \textbf{垂直} 堆叠而成 可以看做是当前层所有节点的wT垂直堆叠而成, 所以 W [ i ] = [ [ w 1 [ i ] T ] , [ w 2 [ i ] T ] , ⋯ , [ w m [ i ] T ] ] 所以W^{[i]}=[[w^{[i]T}_1],[w^{[i]T}_2],\cdots,[w^{[i]T}_m]] 所以W[i]=[[w1[i]T],[w2[i]T],⋯,[wm[i]T]]总共堆m行,m是本层神经元个数 = n [ i ] =n^{[i]} =n[i],每一行都是n维向量,n是上一层传过来特征的数量 = n [ i − 1 ] =n^{[i-1]} =n[i−1]。
所以可以看出来,水平遍历可以将单个神经元接收的所有特征遍历,垂直遍历可以将单个特征导向的所有神经元遍历。 - B [ i ] 代表第 i 层的神经网络参数,是 b 的推广, B^{[i]}代表第i层的神经网络参数,是b的推广, B[i]代表第i层的神经网络参数,是b的推广, 可以看做是当前层所有节点的 b 堆叠而成,同样是 垂直 堆叠 可以看做是当前层所有节点的b堆叠而成,同样是\textbf{垂直}堆叠 可以看做是当前层所有节点的b堆叠而成,同样是垂直堆叠
- Z [ i ] 是 z T 的水平堆叠 Z^{[i]}是z^T的水平堆叠 Z[i]是zT的水平堆叠
- A [ i ] 是 a T 的水平堆叠,是 Z [ i ] 被 g 作用后的矩阵 A^{[i]}是a^T的水平堆叠,是Z^{[i]}被g作用后的矩阵 A[i]是aT的水平堆叠,是Z[i]被g作用后的矩阵, A n x × m [ 0 ] = X A^{[0]}_{n_x\times m}=X Anx×m[0]=X, A [ L ] = Y ^ 1 × m A^{[L]}=\hat{Y}_{1\times m} A[L]=Y^1×m
- g [ i ] g^{[i]} g[i]代表当前层的激活函数
神经网络的向量化fp
设X=A{[0]},\hat{Y}=A{[L]},则逐层计算,这个for loop现在没有办法避免:
for i = 1 to L:
Z [ i ] = W [ i ] A [ i − 1 ] + B [ i ] Z^{[i]}=W^{[i]}A^{[i-1]}+B^{[i]} Z[i]=W[i]A[i−1]+B[i]
A [ i ] = g ( Z [ i ] ) A^{[i]}=g(Z^{[i]}) A[i]=g(Z[i])
这个式子可以分块理解,还原他们堆叠之前的状态,然后这个分块列向量乘以分块行向量再加B向量(广播后实际为矩阵),出来一个矩阵,这个矩阵每行对应于单节点的logistic regression,然后垂直堆叠起来一层的结果。
我们换个角度理解这个产生的矩阵,经过sigmoid函数作用后生成的A矩阵,如果从列来看,实际上每一列都相当于一个样本 X ( i ) X^{(i)} X(i)经过一层神经网络后产生的新样本,只不过该样本的维数(长度)变成了当前层神经元的个数,但是很明显,样本数量没有变化。
也就是说:
节点数 n [ i ] n^{[i]} n[i]=参数矩阵 W [ i ] W^{[i]} W[i]的高度=样本矩阵 A [ i ] A^{[i]} A[i]的高度.
以上随着神经网络的层而变化。
但是:
A [ i ] 矩阵的宽度 ≡ 初始样本数 A^{[i]}矩阵的宽度\equiv 初始样本数 A[i]矩阵的宽度≡初始样本数
以上不随层而变化。
我们从更高层的角度去理解W和Z,B的形状:
B和W是按照神经元垂直堆叠的,所以这两个的 高度 ≡ 当前层神经元个数 高度\equiv 当前层神经元个数 高度≡当前层神经元个数
然后因为激活函数不改变形状,所以实际上结果 A ∼ Z ∼ W W W ⋯ X A\sim Z\sim WWW\cdots X A∼Z∼WWW⋯X,因为最右矩阵是X,所以A,Z矩阵的宽度恒定为m
至于W的宽度,这个根据上一层的n定。
最后,不管你有多少层,最终还是输出了一个 A m × 1 A_{m\times 1} Am×1,因此,Lost和Cost的计算方法完全相同。
神经网络的向量化bp
d Z n [ i ] × m [ i ] = { A [ i ] − Y , i = L d A [ i ] ∗ g [ i ] ′ ( Z [ i ] ) , i ≠ L , ∗ 为 e l e m e n t − w i s e 逐元素相乘 dZ^{[i]}_{n^{[i]}\times m}= \begin{cases} A^{[i]}-Y, & i=L \\ dA^{[i]}*g^{[i]\prime}(Z^{[i]}), & i\neq L,*为element-wise逐元素相乘 \end{cases} dZn[i]×m[i]={A[i]−Y,dA[i]∗g[i]′(Z[i]),i=Li=L,∗为element−wise逐元素相乘
其中,dA的计算是反向递归的,要给一个递归初始值
d A [ i − 1 ] = { [ − y ( 1 ) a ( 1 ) + 1 − y ( 1 ) 1 − a ( 1 ) , ⋯ , − y ( m ) a ( m ) + 1 − y ( m ) 1 − a ( m ) ] 1 × m , i = L W [ i ] T d Z [ i ] , i ≠ L dA^{[i-1]}= \begin{cases} [-\dfrac{y^{(1)}}{a^{(1)}}+\dfrac{1-y^{(1)}}{1-a^{(1)}},\cdots,-\dfrac{y^{(m)}}{a^{(m)}}+\dfrac{1-y^{(m)}}{1-a^{(m)}}]_{1\times m},& i=L \\ W^{[i]T}dZ^{[i]},& i\neq L \\ \end{cases} dA[i−1]=⎩ ⎨ ⎧[−a(1)y(1)+1−a(1)1−y(1),⋯,−a(m)y(m)+1−a(m)1−y(m)]1×m,W[i]TdZ[i],i=Li=L
第一个式子可以迁移,第二个式子直观理解只能通过维数来理解他的合理性。
-
d W n [ i ] × n [ i − 1 ] [ i ] = 1 m d Z [ i ] A [ i − 1 ] T dW^{[i]}_{n^{[i]}\times n^{[i-1]}}=\dfrac{1}{m} dZ^{[i]}A^{[i-1]T} dWn[i]×n[i−1][i]=m1dZ[i]A[i−1]T
这个可以迁移理解,在Logistic Regression里, d w = 1 m X d Z T dw=\dfrac{1}{m}XdZ^T dw=m1XdZT,而我们这里的W矩阵是若干个 w T w^T wT纵向堆叠而成,所以我们要做一个转置。 -
d B n [ i ] × 1 [ i ] = 1 m n p . s u m ( d Z [ i ] , a x i s = 1 , k e e p d i m s = T r u e ) . r e s h a p e ( n [ i ] , 1 ) dB^{[i]}_{n^{[i]}\times 1}=\dfrac{1}{m} np.sum(dZ^{[i]},axis=1,keepdims=True).reshape(n^{[i]},1) dBn[i]×1[i]=m1np.sum(dZ[i],axis=1,keepdims=True).reshape(n[i],1)
这个如此理解,对每一个节点,我们都要对所有样本进行均值,所以进行横向求均值,形成若干个b堆叠而成的向量,最后一层的B就是一个实数。
写到这里,我不由得感叹矩阵的强大,真tm哪个小天才能想出这种玩意,能让公式随着维数的增加而保持形式稳定,太离谱了!
神经网络函数块
其实可以看出来,除了最后一层有点特殊以外,每一层的处理方式都是相同的,那可不可以编写一个函数去一次性处理一层的任务呢?
可以,以下是流程图:

fp块
Input: A [ i − 1 ] A^{[i-1]} A[i−1]
Process:
Z [ i ] = n p . d o t ( W [ i ] , A [ i − 1 ] ) + B [ i ] Z^{[i]}=np.dot(W^{[i]},A^{[i-1]})+B^{[i]} Z[i]=np.dot(W[i],A[i−1])+B[i]
A [ i ] = g [ i ] ( Z [ i ] ) A^{[i]}=g^{[i]}(Z^{[i]}) A[i]=g[i](Z[i])
Cache: Z [ i ] Z^{[i]} Z[i]
Output: A [ i ] A^{[i]} A[i]
bp块
Input: d A [ i ] dA^{[i]} dA[i]
Process:
d Z [ i ] = d A [ i ] ∗ g [ i ] ′ ( Z [ i ] ) dZ^{[i]}=dA^{[i]}*g^{[i]\prime }(Z^{[i]}) dZ[i]=dA[i]∗g[i]′(Z[i])
d W [ i ] = 1 m n p . d o t ( d Z [ i ] , A [ i − 1 ] T ) dW^{[i]}=\dfrac{1}{m}np.dot(dZ^{[i]},A^{[i-1]T}) dW[i]=m1np.dot(dZ[i],A[i−1]T)
d B [ i ] = 1 m n p . s u m ( d Z [ i ] , a x i s = 1 , k e e p d i m s = T r u e ) dB^{[i]}=\dfrac{1}{m}np.sum(dZ^{[i]},axis=1,keepdims=True) dB[i]=m1np.sum(dZ[i],axis=1,keepdims=True)
d A [ i − 1 ] = n p . d o t ( W [ i ] T , d Z [ i ] ) dA^{[i-1]}=np.dot(W^{[i]T},dZ^{[i]}) dA[i−1]=np.dot(W[i]T,dZ[i])
Output: d A [ i − 1 ] , d W [ i ] , d B [ i ] dA^{[i-1]} , dW^{[i]} , dB^{[i]} dA[i−1],dW[i],dB[i]
一轮迭代的处理流程
-
赋值 A [ 0 ] = X A^{[0]}=X A[0]=X
-
不断调用fp函数,生成A和Z
-
赋值 d A [ L ] = [ − y ( 1 ) a ( 1 ) + 1 − y ( 1 ) 1 − a ( 1 ) , ⋯ , − y ( m ) a ( m ) + 1 − y ( m ) 1 − a ( m ) ] 1 × m dA^{[L]}=[-\dfrac{y^{(1)}}{a^{(1)}}+\dfrac{1-y^{(1)}}{1-a^{(1)}},\cdots,-\dfrac{y^{(m)}}{a^{(m)}}+\dfrac{1-y^{(m)}}{1-a^{(m)}}]_{1\times m} dA[L]=[−a(1)y(1)+1−a(1)1−y(1),⋯,−a(m)y(m)+1−a(m)1−y(m)]1×m
-
反向调用bp函数,生成dA,dW,dB,更新W,B矩阵
激活函数
可选项
- sigmoid/tanh
tanh ( x ) = e x − e − x e x + e − x \tanh(x) =\dfrac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=ex+e−xex−e−x,隐藏层常用,因为有期望为0的特征,往往表现比sigmoid函数好,而sigmoid常用于输出层的激活。同时,tanh也有缺陷,就是在|z|很大的时候,梯度几乎为0,会拖慢迭代速度。 - ReLU/Leaky ReLU (Rectified Linear Unit)
a = m a x ( 0 , z ) a=max(0,z) a=max(0,z),线性修正单元出现了,这个是隐藏层激活函数的默认选项。 因为其梯度的稳定性,用其实现的神经网络迭代速度很快。
a = m a x ( 0.01 z , z ) , a=max(0.01z,z), a=max(0.01z,z),Leaky ReLU的出现是用来修正ReLU在负数情况下梯度为0的情况的。但是实际上因为神经元多以及初始样本的输入,出现z小于0的情况很少 - 为什么要使用非线性激活函数
如果全都是线性的,那么最后的计算结果也不过是一种线性组合,化简后就会发现,无论多少层网络,最终效果就和一层网络相同。
如果要用,就是输出层或者是用于特殊用途的隐藏层。
导数计算(prime)
- sigmoid
g ′ ( z ) = a ( 1 − a ) g^\prime (z)=a(1-a) g′(z)=a(1−a) - tanh
g ′ ( z ) = 1 − a 2 g^\prime (z)=1-a^2 g′(z)=1−a2
直观理解,如果|z|足够大, ( t a n h ( z ) ) 2 (tanh(z))^2 (tanh(z))2趋近1,也就是导数趋近0 - ReLU
g ′ ( z ) = { 0 , z ≤ 0 1 , z > 0 g^\prime (z)= \begin{cases} 0 ,& z \leq 0 \\ 1 ,& z > 0 \end{cases} g′(z)={0,1,z≤0z>0 - Leaky ReLU
g ′ ( z ) = { 0.01 , z ≤ 0 1 , z > 0 g^\prime(z)= \begin{cases} 0.01, & z \leq 0 \\ 1, & z>0 \end{cases} g′(z)={0.01,1,z≤0z>0
随机初始化
- W = n p . r a n d o m . r a n d n ( ( n [ i ] , n [ i − 1 ] ) ) ∗ 0.01 W=np.random.randn((n^{[i]},n^{[i-1]}))*0.01 W=np.random.randn((n[i],n[i−1]))∗0.01
首先,W不能对称,即W的行不能相同。如果有相同,那这两个神经元就造成了浪费,如果完全对称,那么每层神经元就相当于一个神经元
然后,乘一个系数调整使得权重足够小,防止Z矩阵元素过大导致sigmoid或者tanh函数饱和,从而拖慢学习速度。
- B = n p . z e r o ( ( n [ i ] , 1 ) ) B=np.zero((n^{[i]},1)) B=np.zero((n[i],1))
B其实随便,因为W已经随机了
深层网络的合理性
首先,从图像识别来看,神经网络就相当于从细微的特征入手,然后逐层组装,最后合成一个目标特征。
然后,深层神经网络可以在计算复杂问题的时候有效降低神经元规模,用深度换取空间复杂度。这个起源于电路理论。
emm,我其实也不太理解,看了几个小文章,大概理解了:逐层抽象提取分类,可以让简单的特征被下一层复用,有一种类似于通过动态规划来降低递归的重复计算的作用。暂时这么理解吧。