论文阅读《P-MVSNet: Learning Patch-wise Matching Confidence Aggregation for Multi-View Stereo》
论文地址:P-MVSNet: Learning Patch-wise Matching Confidence Aggregation for Multi-View Stereo
一、摘要
Cost Volumes 应该是各向异性的,但是传统的方法使用各向同性的方式来处理它(基于方差计算,每个像素都以相同的贡献度参加代价聚合计算),文章使用了一个各向同性的3D卷积和各向异性的3D卷积相结合的代价聚合方式得到更加鲁棒的代价体。
二、网络结构

2.1 特征提取
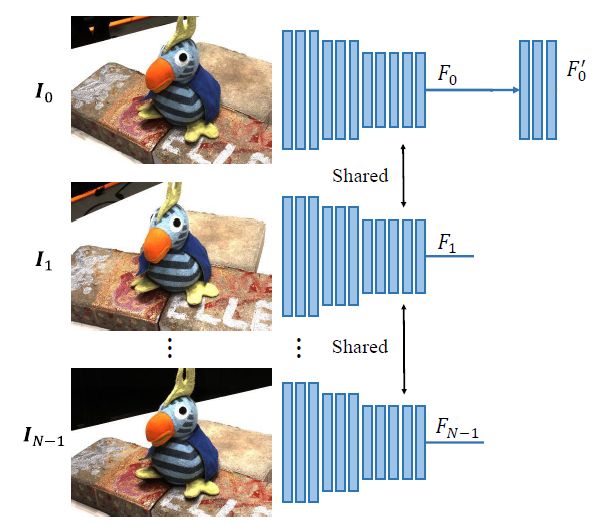
与MVSNet一样,经过卷积神经网络提取参考图像和N-1张源图像的特征 F i ∈ R H 4 × W 4 × C F_{i} \in \mathbb{R}^{\frac{H}{4}\times \frac{W}{4} \times C} Fi∈R4H×4W×C,其中 i ∈ ( 0 , N − 1 ) i\in(0, N-1) i∈(0,N−1),将参考视图经过Decoder得到参考视图的引导特征图 F 0 ′ ∈ R H 2 × W 2 × C F_{0}^{\prime} \in \mathbb{R}^{\frac{H}{2} \times \frac{W}{2} \times C} F0′∈R2H×2W×C,其中 { F i } 1 N − 1 \{F_{i}\}_{1}^{N-1} {Fi}1N−1用于后面构建Matching Confidence Volume(MCV),而 F 0 ′ F_{0}^{\prime} F0′用于引导生成更高分辨率的深度图。
2.2 基于patch的可学习匹配代价置信度计算
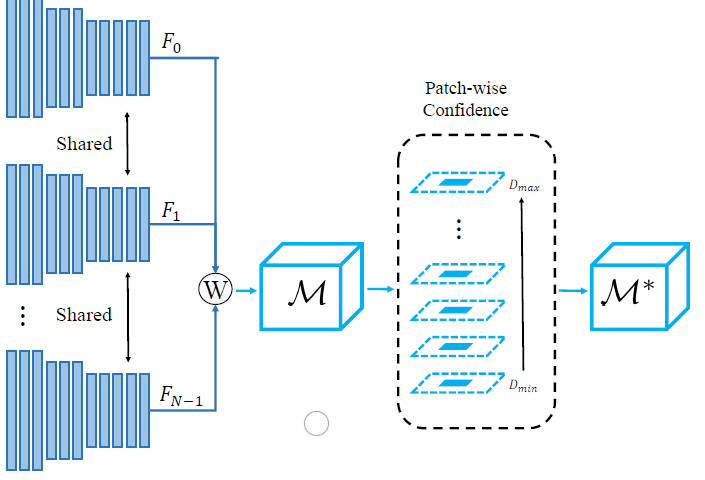
匹配代价体计算:将源视图的特征图经过相机的内外参数warp到参考视图,然后基于L2距离计算匹配代价体,如式1所示:
M ( d , p , c ) = exp ( − ∑ j = 1 N − 1 ( F j ( p ′ , c ) − F 0 ( p , c ) ) 2 N − 1 ) (1) \mathcal{M}(d, \boldsymbol{p}, c)=\exp \left(-\frac{\sum_{j=1}^{N-1}\left(F_{j}\left(\boldsymbol{p}^{\prime}, c\right)-F_{0}(\boldsymbol{p}, c)\right)^{2}}{N-1}\right)\tag{1} M(d,p,c)=exp(−N−1∑j=1N−1(Fj(p′,c)−F0(p,c))2)(1)
其中, j j j 代表不同视图, p p p 代表参考帧的像素点坐标, c c c 代表特征的维度, p ′ p^{\prime} p′ 表示邻域帧中 p p p 点对应的像素坐标点。
代价聚合:
M a ( d , p , c ) = ρ 1 ( M ( d , p , c ) ) + ρ 2 ( Ω 1 ( M ( d , p , c ) ) ) (2) \mathcal{M}^{a}(d, \boldsymbol{p}, c)=\rho_{1}(\mathcal{M}(d, \boldsymbol{p}, c))+\rho_{2}\left(\Omega_{1}(\mathcal{M}(d, \boldsymbol{p}, c))\right)\tag{2} Ma(d,p,c)=ρ1(M(d,p,c))+ρ2(Ω1(M(d,p,c)))(2)
其中: ρ 1 ρ_{1} ρ1 就是将 p p p 点的特征值乘以一个1x1x1的卷积核(一个尺度因子), Ω 1 Ω_{1} Ω1 表示1x3x3的卷积+BN+RELU,表示将 p p p 点邻域的像素聚合,但只在同一个深度层聚合,因为卷积核的第一维为1,该卷积核的参数为ρ1。
M ⋆ ( d , p , c ) = tanh ( ρ 3 ( Ω 2 ( M a ( d , p , c ) ) ) ) (3) \mathcal{M}^{\star}(d, \boldsymbol{p}, c)=\tanh \left(\rho_{3}\left(\Omega_{2}\left(\mathcal{M}^{a}(d, \boldsymbol{p}, c)\right)\right)\right) \tag{3} M⋆(d,p,c)=tanh(ρ3(Ω2(Ma(d,p,c))))(3)
其中:逐深度进行代价聚合之后,沿着深度方向也进行聚合, Ω 2 Ω_{2} Ω2 代表3x3x3的卷积核,在 p p p 点的深度再考虑上下两个深度的3x3的邻域内做代价聚合。卷积核的参数为 ρ 3 ρ_{3} ρ3,最后乘以一个非线性因子tanh得到代价聚合后的 M ⋆ ( d , p , c ) \mathcal{M}^{\star}(d, \boldsymbol{p}, c) M⋆(d,p,c).
2.3 hybrid 3D U-Net

将 M ⋆ ( d , p , c ) \mathcal{M}^{\star}(d, \boldsymbol{p}, c) M⋆(d,p,c)送入到hybrid 3D U-Net得到latent probability volume(LPV)记为 V 2 = V 2 ( d , p ) ∈ ( Z × H 4 × W 4 ) V_{2}=V_{2}(d,p)\in(Z\times \frac{H}{4}\times \frac{W}{4}) V2=V2(d,p)∈(Z×4H×4W),表示表示 F 0 F_{0} F0 每个像素在深度方向上的潜在概率分布。网络由多个各向异性的3D卷积核各向同性的3D卷积组成。浅层使用各向异性的卷积核融合代价体,深层使用各向同性的卷积核来融合更多的信息(各向异性的卷积指的是三个维度不相等的卷积核,各向同性的卷积核指的是三个维度相同的卷积核,感觉有点强行凑观点的嫌疑哈哈哈)。
2.4 深度图计算
先将 V 2 V_{2} V2经过在深度维度上做softmax得到一个概率体 P 2 P_{2} P2,基于期望计算深度图:
D ℓ 2 ( p ) = ∑ d = D min D max d ⋅ P 2 ( d , p ) (4) D_{\ell_{2}}(\boldsymbol{p})=\sum_{d=D_{\min }}^{D_{\max }} d \cdot \mathcal{P}_{2}(d, \boldsymbol{p})\tag{4} Dℓ2(p)=d=Dmin∑Dmaxd⋅P2(d,p)(4)

D ℓ 2 D_{\ell_{2}} Dℓ2是分辨率较低的深度图,使用参考图像的特征图 F 0 ′ F_{0}^{\prime} F0′ 来引导生成高分辨率的深度图。首先将 F 0 ′ F_{0}^{\prime} F0′ 与 上采样后的 V 2 V_{2} V2 concat成通道为 C + Z C+Z C+Z的输入,再经过一个CNN+BN+RELU和一个softmax和期望回归层,输入高分辨率的深度图 D ℓ 1 D_{\ell_{1}} Dℓ1;
三、损失函数
损失函数如下:
Loss = α ∣ Φ 2 ∣ ∑ p ∈ Φ 2 ∥ D ℓ 2 ( p ) − D ℓ 2 ⋆ ( p ) ∥ 1 + 1 − α ∣ Φ 1 ∣ ∑ p ∈ Φ 1 ∥ D ℓ 1 ( p ) − D ℓ 1 ⋆ ( p ) ∥ 1 (5) \begin{aligned} \text { Loss }=& \frac{\alpha}{\left|\Phi_{2}\right|} \sum_{p \in \Phi_{2}}\left\|D_{\ell_{2}}(p)-D_{\ell_{2}}^{\star}(p)\right\|_{1} +\frac{1-\alpha}{\left|\Phi_{1}\right|} \sum_{\boldsymbol{p} \in \Phi_{1}}\left\|D_{\ell_{1}}(\boldsymbol{p})-D_{\ell_{1}}^{\star}(\boldsymbol{p})\right\|_{1} \end{aligned}\tag{5} Loss =∣Φ2∣αp∈Φ2∑∥∥Dℓ2(p)−Dℓ2⋆(p)∥∥1+∣Φ1∣1−αp∈Φ1∑∥∥Dℓ1(p)−Dℓ1⋆(p)∥∥1(5)
其中, Φ 2 \Phi_{2} Φ2和 Φ 1 \Phi_{1} Φ1表示有标签的像素点, D ℓ 1 ⋆ D_{\ell_{1}}^{\star} Dℓ1⋆和 D ℓ 2 ⋆ D_{\ell_{2}}^{\star} Dℓ2⋆表示对应的Ground truth深度图; α \alpha α是一个可调节的权重超参数;
四、深度图滤波
4.1 基于深度估计置信度
当聚合代价体的深度方向上是单峰时的置信度是最高的。因此,使用初始深度图前的概率体求深度图 D ℓ 2 D_{\ell_{2}} Dℓ2的置信度图 C 2 ( p ) C_{2}(p) C2(p):
C 2 ( p ) = max { P 2 ( d , p ) ∣ d ∈ [ D min , D max ] } (6) C_{2}(\boldsymbol{p})=\max \left\{\mathcal{P}_{2}(d, \boldsymbol{p}) \mid d \in\left[D_{\min }, D_{\max }\right]\right\}\tag{6} C2(p)=max{P2(d,p)∣d∈[Dmin,Dmax]}(6)
将 C 2 ( p ) C_{2}(\boldsymbol{p}) C2(p)上采样后为 U 1 U_{1} U1,计算深度图 D ℓ 1 D_{\ell_{1}} Dℓ1的置信度图如式7所示:
C 1 ( p ) = U 1 ( p ) + max { P 1 ( d , p ) ∣ d ∈ [ D min , D max ] } (7) C_{1}(\boldsymbol{p})=U_{1}(\boldsymbol{p})+\max \left\{\mathcal{P}_{1}(d, \boldsymbol{p}) \mid d \in\left[D_{\min }, D_{\max }\right]\right\}\tag{7} C1(p)=U1(p)+max{P1(d,p)∣d∈[Dmin,Dmax]}(7)
使用深度估计置信度图来进行滤波,去除置信度低的像素点。
基于深度一致性
利用了传统方法中的左右一致性检查;
∣ q ′ − p ∣ < ϵ ∣ d ^ ( q ′ ) − d ^ ( p ) ∣ d ^ ( p ) < η (8) \left|\boldsymbol{q}^{\prime}-\boldsymbol{p}\right|<\epsilon \\ \\ \frac{\left|\hat{d}\left(\boldsymbol{q}^{\prime}\right)-\hat{d}(\boldsymbol{p})\right| }{ \hat{d}(\boldsymbol{p})}<\eta\tag{8} ∣q′−p∣<ϵd^(p)∣∣∣d^(q′)−d^(p)∣∣∣<η(8)
五、实验结果

