2021_WSDM_Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation
[论文阅读笔记]2021_WSDM_Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation
论文下载地址: https://doi.org/10.1145/3437963.3441738
发表期刊:WSDM
Publish time: 2021
作者及单位:
- Bowen Hao Renmin University of China [email protected]
- Jing Zhang∗ Renmin University of China [email protected]
- Hongzhi Yin The University of Queensland [email protected]
- Cuiping Li Renmin University of China [email protected]
- Hong Chen Renmin University of China [email protected]
数据集:
- MovieLens-1M(Ml-1M) https://grouplens.org/datasets/movielens/ (作者在论文中公开的)
- MOOCs http://moocdata.cn/data/course-recommendation (作者在论文中公开的)
- Last.fm http://www.last.fm (作者在论文中公开的)
代码:
- https://github.com/jerryhao66/Pretrain-Recsys (作者在论文中公开的)
其他人写的文章
简要概括创新点: 这篇论文,理论的针对点。冷启动用户的embedding是inaccurate。训练时用的有丰富交互的数据,ground-truth和cold-start user/item是author随机采样模拟得到的;训练好了,再用到冷启动的数据上
- (1)However, the basic pre-training GNN model doesn’t specially address the cold-start neighbors. During the original graph convolution process, the inaccurate embeddings of the cold-start neighbors and the embeddings of other neighbors are equally treated and aggregated to represent the target user/item. (然而,基本的预训练GNN模型并没有专门针对冷启动邻居。在原始的图卷积过程中,冷启动邻域的不准确嵌入和其他邻域的嵌入被平等地处理和聚合,以表示目标用户/项。) 这篇论文,理论的针对点。冷启动用户的embedding是inaccurate
- (2)This paper proposes to pretrain a GNN model before applying it for recommendation. (本文建议在应用GNN模型进行推荐之前对其进行预训练。)
- (3)To further reduce the impact from the cold-start neighbors,
- we incorporate a self-attention-based meta aggregator to enhance the aggregation ability of each graph convolution step, (为了进一步减少冷启动邻居的影响,我们加入了一个基于自注意的元聚合器来增强每个图卷积步骤的聚合能力)
- and an adaptive neighbor sampler to select the effective neighbors according to the feedbacks from the pre-training GNN model.(以及一个自适应邻居采样器来根据预训练GNN模型的反馈 选择有效邻居。)
- (4)Since we also need ground truth embeddings of the cold-start users/items to learn f f f , we simulate those users/items from the target users/items with abundant interactions. (由于我们还需要冷启动用户/项目的真实值嵌入来学习 f f f,因此我们模拟了目标用户/项目中具有丰富交互的用户/项目。)
ABSTRACT
- (1) Cold-start problem is a fundamental challenge for recommendation tasks. Despite the recent advances on Graph Neural Networks (GNNs) incorporate the high-order collaborative signal to alleviate the problem, the embeddings of the cold-start users and items aren’t explicitly optimized, and the cold-start neighbors are not dealt with during the graph convolution in GNNs. (冷启动问题是推荐任务面临的一个基本挑战。,尽管最近在图形神经网络(GNN)方面取得了一些进展,但在GNN中,冷启动用户和项目的嵌入没有得到明确的优化,并且在图形卷积过程中也没有处理冷启动邻居。)
- (2)This paper proposes to pretrain a GNN model before applying it for recommendation. (本文建议在应用GNN模型进行推荐之前对其进行预训练。)
- Unlike the goal of recommendation, the pre-training GNN simulates the cold-start scenarios from the users/items with sufficient interactions and takes the embedding reconstruction as the pretext task, such that it can directly improve the embedding quality and can be easily adapted to the new cold-start users/items. (与推荐的目标不同,预训练GNN模拟用户/项目的冷启动场景,具有充分的交互,并以嵌入重构为借口任务,这样可以直接提高嵌入质量,并且可以很容易地适应新的冷启动用户/项目。)
- (3)To further reduce the impact from the cold-start neighbors,
- we incorporate a self-attention-based meta aggregator to enhance the aggregation ability of each graph convolution step, (为了进一步减少冷启动邻居的影响,我们加入了一个基于自注意的元聚合器来增强每个图卷积步骤的聚合能力)
- and an adaptive neighbor sampler to select the effective neighbors according to the feedbacks from the pre-training GNN model.(以及一个自适应邻居采样器来根据预训练GNN模型的反馈 选择有效邻居。)
- (4)Experiments on three public recommendation datasets show the superiority of our pre-training GNN model against the original GNN models on user/item embedding inference and the recommendation task.
CCS CONCEPTS
• Information systems → Social recommendation;
KEYWORDS
Pre-training, graph neural networks, cold-start, recommendation
1 INTRODUCTION
-
(1)Recommendation systems [14, 21] have been extensively deployed to alleviate information overload in various web services, such as social media, E-commerce websites and news portals. To predict the likelihood of a user adopting an item, collaborative filtering (CF) is the most widely adopted principle. The most common paradigm for CF, such as matrix factorization [21] and neural collaborative filtering [14], is to learn embeddings, i.e. the preferences for users and items and then perform the prediction based on the embeddings [13]. However, these models fail to learn high-quality embeddings for the cold-start users/items with sparse interactions. (推荐系统[14,21]已被广泛部署,以缓解各种网络服务(如社交媒体、电子商务网站和新闻门户)中的信息过载。为了预测用户采用某个项目的可能性,协同过滤(CF)是最广泛采用的原则。CF最常见的范例,如矩阵分解[21]和神经协同过滤[14],是学习嵌入,即用户和项目的偏好,然后根据嵌入进行预测[13]。然而,这些模型无法为交互稀少的冷启动用户/项目学习高质量的嵌入。)
-
(2)To address the cold-start problem, traditional recommender systems incorporate the side information such as content features of users and items [40,44] or external knowledge graphs (KGs) [35,37] to compensate the low-quality embeddings caused by sparse interactions. However, the content features are not always available, and it is not easy to link the items to the entities in KGs due to the incompleteness and ambiguation of the entities. (为了解决冷启动问题,传统的推荐系统结合了用户和项目的内容特征[40,44]或外部知识图(KG)[35,37]等辅助信息,以补偿稀疏交互导致的低质量嵌入。然而,内容功能并不总是可用的,而且由于实体的不完整性和模糊性,将项目链接到KGs中的实体并不容易。)
-
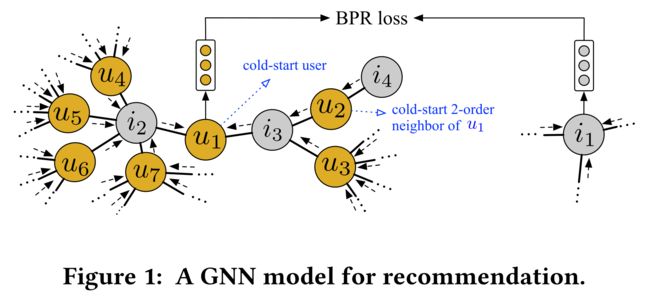
(3) On another line, inspired by the recent development of graph neural networks (GNNs) [2, 11, 19], NGCF [38] and LightGCN [13] encode the high-order collaborative signal in the user-item interaction graph by a GNN model, based on which they perform the recommendation task. As shown in Fig. 1, a typical recommendation-oriented GNN conducts graph convolution on the local neighborhood’s embeddings of u 1 u_1 u1 and i 1 i_1 i1. Through iteratively repeating the convolution by multiple steps, the embeddings of the high-order neighbors are propagated to u 1 u1 u1 and i 1 i1 i1. Based on the aggregated embeddings of u 1 u_1 u1 and i 1 i_1 i1, the likelihood of u 1 u_1 u1 adopting i 1 i_1 i1 is estimated, and cross-entropy loss [3] or BPR loss [13, 38] is usually adopted to compare the likelihood and the true observations. (另一方面,受图形神经网络(GNN)[2,11,19]的最新发展启发,NGCF[38]和LightGCN[13]通过GNN模型对用户项交互图中的高阶协作信号进行编码,并在此基础上执行推荐任务。如图1所示,典型的面向推荐的GNN对 u 1 u_1 u1和 i 1 i_1 i1的局部邻域嵌入进行图卷积通过多次迭代重复卷积,高阶邻域的嵌入被传播到 u 1 u_1 u1和 i 1 i_1 i1。基于 u 1 u_1 u1和 i 1 i_1 i1的聚合嵌入, u 1 u_1 u1采纳 i 1 i_1 i1的可能性被评估,通常采用 交叉熵损失[3]或 BPR损失[13,38]来比较可能性和真实观测值。)
-
(4)Despite the success of capturing the high-order collaborative signal in GNNs [13, 38], the cold-start problem is not thoroughly solved by them. (尽管成功地捕获了GNNs中的高阶协同信号[13,38],但冷启动问题并没有被它们彻底解决。
- First, the GNNs for recommendation address thecold-start user/item embeddings through optimizing the likelihood of a user adopting an item, which isn’t a direct improvement of the embedding quality; (首先,推荐的GNN通过优化用户采用项目的可能性来解决冷启动用户/项目嵌入问题,这不是嵌入质量的直接提高;)
- second, the GNN model does not specially deal with the cold-start neighbors among all the neighbors when performing the graph convolution. For example in Fig. 1, to represent u 1 u_1 u1, the 2-order neighbor u 2 u_2 u2 is also a cold-start user who only interacts with i 3 i_3 i3 and i 4 i_4 i4. The result of graph convolution on the inaccurate embedding of u 2 u_2 u2 and the embedding of u 3 u_3 u3 together will be propagated to u 1 u_1 u1 and hurt its embedding. (其次,在进行图卷积时,GNN模型没有专门处理所有邻居中的冷启动邻居。例如,在图1中,为了表示 u 1 u_1 u1, 二阶近邻 u 2 u_2 u2是只与 i 3 i_3 i3和 i 4 i_4 i4交互的冷启动用户. 关于 u 2 u_2 u2的不精确嵌入的图卷积结果 以及 u 3 u_3 u3的嵌入将一起传播到 u 1 u_1 u1并且 伤害了它的嵌入。)
- Existing GNNs ignore the cold-start characteristics of neighbors during the graph convolution process. Although some GNN models such as GrageSAGE [11] or FastGCN [4] filter neighbors before aggregating them, they usually follow a random or an importance sampling strategy, which also ignore the cold-start characteristics of the neighbors. This leads us to the following research problem: how can we learn more accurate embeddings for cold-start users or items by GNNs? (现有的GNN在图卷积过程中忽略了邻居的冷启动特性。尽管一些GNN模型,如GrageSAGE[11]或FastGCN[4]在聚合邻居之前会过滤它们,但它们通常遵循随机或重要抽样策略,这也会忽略邻居的冷启动特性。这就引出了以下研究问题:我们如何通过GNNs为冷启动用户或项目学习更准确的嵌入?)
-
(5) Present work. To tackle the above challenges, before performing the GNN model for recommendation,
- we propose to pre-train the GNN model to enhance the embeddings of the cold-start users or items. (我们建议对GNN模型进行预训练,以增强冷启动用户或项目的嵌入。)
- Unlike the goal of recommendation, the pre-training task directly reconstructs the cold-start user/item embeddings by mimicking the meta-learning setting via episode based training, as proposed in [34]. (与推荐的目标不同,预培训任务通过基于事件的培训 模拟元学习设置,直接重建冷启动用户/项目嵌入,如[34]所述。)
- Specifically, we pick the users/items with sufficient interactions as the target users/items and learn their ground truth embeddings on the observed abundant interactions. To simulate the real cold-start scenarios, in each training episode, we randomly sample K neighbors for each target user/item, based on which we perform the graph convolution multiple steps to predict the target embedding. (具体来说,我们选择具有足够交互的用户/项目作为目标用户/项目,并在观察到的大量交互上了解它们的基本真相嵌入。为了模拟真实的冷启动场景,在每个训练集中,我们对每个目标用户/项目随机抽样K个邻居,在此基础上,我们执行图卷积多个步骤来预测目标嵌入。)
- The reconstruction loss between the predicted embedding and the ground truth embedding is optimized to directly improve the embedding capacity, making the model easily and rapidly being adapted to new cold-start users/items. (对预测嵌入和地面真值嵌入之间的重建损失进行了优化,以直接提高嵌入容量,使模型易于快速适应新的冷启动用户/项目。)
-
(6) However, the above pre-training strategy still can not explicitly deal with the high-order cold-start neighbors when performing graph convolution. Besides, previous GNN sampling strategies such as random or importance sampling strategies may fail to sample high-order relevant cold-start neighbors due to their sparse interactions. (然而,在执行图卷积时,上述预训练策略仍然不能明确地处理高阶冷启动邻居。此外,以往的GNN抽样策略,如随机抽样或重要抽样策略,由于其稀疏的交互作用,可能无法对高阶相关冷启动邻居进行抽样。)
- To overcome these challenges, we incorporate a meta aggregator and an adaptive neighbor sampler into the pre-training GNN model (为了克服这些挑战,我们在预训练GNN模型中加入了元聚合器和自适应邻居采样器。).
- Specifically, the meta aggregator learns cold-start users/items’ embeddings on the first-order neighbors by self-attention mechanism under the same meta-learning setting, which is then incorporated into each graph convolution step to enhance the aggregation ability. (在相同的元学习设置下,元聚合器通过自我注意机制学习冷启动用户/项目在一阶邻居上的嵌入,然后将其纳入每个图卷积步骤,以增强聚合能力。)
- While the adaptive neighbor sampler is formalized as a hierarchical Markov Sequential Decision Process, which sequentially samples from the low-order neighbors to the high-order neighbors according to the feedbacks provided by the pre-training GNN model. (自适应邻域采样器被形式化为一个层次马尔可夫序列决策过程,该过程根据预训练GNN模型提供的反馈,从低阶邻域到高阶邻域’
- 依次采样。)
- The two components are jointly trained. Since the GNN model can be instantiated by different choices such as the original GCN [19], GAT [31] or FastGCN [4], the proposed pre-training GNN model is model-agnostic. (这两个部分是联合培训的。由于GNN模型可以通过不同的选择进行实例化,如原始GCN[19]、GAT[31]或FastGCN[4],因此提出的预训练GNN模型是模型不可知的。)
- To overcome these challenges, we incorporate a meta aggregator and an adaptive neighbor sampler into the pre-training GNN model (为了克服这些挑战,我们在预训练GNN模型中加入了元聚合器和自适应邻居采样器。).
-
(7)The contributions of this work are as follows:
- We propose a pre-training GNN model to learn high-quality embeddings for cold-start users/items. The model is learned under the meta-learning setting to reconstruct the user/item embeddings, which has the powerful generalization capacity. (我们提出了一个预训练GNN模型,用于为冷启动用户/项目学习高质量的嵌入。该模型在元学习环境下学习,重构用户/项目嵌入,具有较强的泛化能力。)
- To deal with the cold-start neighbors during the graph convolution process, we further propose a meta aggregator to enhance the aggregation ability of each graph convolution step, and a neighbor sampler to select the effective neighbors adaptively according to the feedbacks of the pre-training GNN model. (为了处理图卷积过程中的冷启动邻居,我们进一步提出了一个元聚合器来增强每个图卷积步骤的聚合能力,以及一个邻居采样器来根据预训练GNN模型的反馈自适应地选择有效邻居。)
-
(8) Experiments on both intrinsic embedding evaluation task and extrinsic downstream recommendation task demonstrate the superiority of our proposed pre-training GNN model against the state-of-the-art GNN models. (通过对内在嵌入评估任务和外在下游推荐任务的实验,证明了我们提出的训练前GNN模型相对于最先进的GNN模型的优越性。)
2 PRELIMINARIES
-
(1)In this section, we first define the problem and then introduce the graph neural networks that can be used to solve the problem.
-
(2) We formalize the user-item interaction data for recommendation as a bipartite graph denoted as G = ( U , I , E ) G = (U,I,E) G=(U,I,E),
- where U = { u 1 , ⋅ ⋅ ⋅ , u ∣ U ∣ } U = \{u_1,· · · ,u_{|U|}\} U={u1,⋅⋅⋅,u∣U∣} is the set of users and I = { i 1 , ⋅ ⋅ ⋅ , i ∣ I ∣ } I = \{i_1,· · · ,i_{|I|}\} I={i1,⋅⋅⋅,i∣I∣} is the set of items.
- U U U and I I I comprise two types of the nodes in G G G.
- Notation E ⊆ U × I E \subseteq U \times I E⊆U×I denotes the set of edges that connect the users and items.
-
(3) We use N ( u ) l N^l_{(u)} N(u)l to represent the l l l-order neighbors of user u u u. When ignoring the superscript, N ( u ) N (u) N(u) indicates the first-order neighbors of u u u. Similarly, N ( i ) l N^l_{(i)} N(i)l and N ( i ) N (i) N(i) are defined for items.
-
(4) Let f : U ∪ V → R b d f : U \cup V \to R^bd f:U∪V→Rbd be the encoding function that maps the users/items to d d d-dimension real-valued vectors. We use h u h_u hu and h i h_i hi to denote the embedding of user u u u and item i i i respectively. Given a bipartite graph G G G, we aim to pre-train the encoding function f f f that is able to be applied on the downstream recommendation task to improve its performance. In the following sections, we mainly take user embedding as an example to explain the proposed model. Item embedding can be explained in the same way. (是将用户/项目映射到 d d d维实值向量的编码函数。我们用 h u h_u hu还有 h i h_i hi分别表示用户 u u u和项目 i i i的嵌入。在给定二部图 G G G的情况下,我们的目标是对编码函数 f f f进行预训练,使其能够应用于下游推荐任务,以提高其性能。在接下来的部分中,我们主要以用户嵌入为例来解释所提出的模型。项目嵌入可以用同样的方式解释。)
2.1 GNN for Recommendation
- (1) The encoding function f f f can be instantiated by various GNNs. Take GraphSAGE as an example, we first sample neighbors for each user u u u randomly and then perform the graph convolution

to obtain the embedding of u u u, where l l l denotes the current convolution step and h u l h^l_u hul denotes user u u u’s embedding at this step. - (2)Similarly, we can obtain the item embedding h i l h^l_i hilat the l l l-th convolution step. Once the embeddings of the last step L L L for all the users and items are obtained, we calculate the relevance score y ( u , i ) = h u L T h i L y(u,i) = {h^L_u}^T h^L_i y(u,i)=huLThiL between user u u u and item i i i and adopt the BPR loss [13, 38], i.e.,
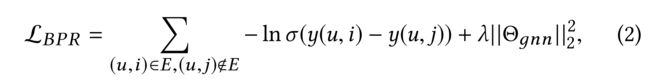
to optimize the user preferences over items. - (3)The above presented GNNs are end-to-end models that can learn user/item embeddings and then recommend items to users simultaneously. For addressing the cold-start users/items, the GNNs can incorporate the high-order collaborative signal through iteratively repeating the sampling and the convolution processes. However, the goal of recommendation shown in Eq.(2) can not explicitly improve the embedding quality of the cold-start users/items. (上述GNN是端到端模型,可以学习用户/项目嵌入,然后同时向用户推荐项目。为了解决冷启动用户/项目的问题,GNN可以通过迭代重复采样和卷积过程来合并高阶协作信号。然而,等式(2)中所示的推荐目标不能明确提高冷启动用户/项目的嵌入质量。)
3 THE PRE-TRAINING GNN MODEL
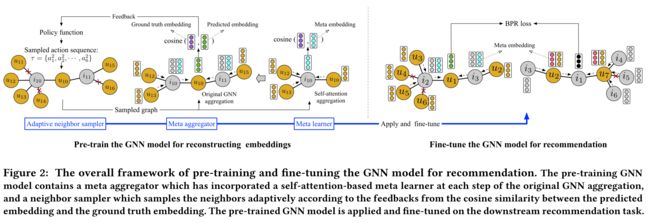
This section introduces the proposed pre-training GNN model to learn the embeddings for the cold-start users and items. (本节介绍了拟议的培训前GNN模型,以了解冷启动用户和项目的嵌入。)
- We first describe a basic pre-training GNN model, (我们首先描述一个基本的训练前GNN模型,)
- and then explain a meta aggregator
- and an adaptive neighbor sampler that are incorporated in the model to further improve the embedding performance. (模型中加入了自适应邻域采样器,进一步提高了嵌入性能。)
- Finally we explain how the model is fine-tuned on the downstream recommendation task. (模型中加入了自适应邻域采样器,进一步提高了嵌入性能。)
- The overview framework is shown in Fig. 2.
3.1 The Basic Pre-training GNN Model
- (1)We propose a basic pre-training GNN model to reconstruct the cold-start user/item embeddings in the meta-learning setting. (我们提出了一个基本的预训练GNN模型来重建元学习环境中的冷启动用户/项目嵌入。)
- To achieve the goal, we need abundant cold-start users/items as the training instances. (我们需要大量的冷启动用户/项目作为训练实例。)
- (2)Since we also need ground truth embeddings of the cold-start users/items to learn f f f , we simulate those users/items from the target users/items with abundant interactions. (由于我们还需要冷启动用户/项目的真实值嵌入来学习 f f f,因此我们模拟了目标用户/项目中具有丰富交互的用户/项目。)
- The ground truth embedding for each user u u u, i.e., h u h_u hu, is learned upon the observed abundant interactions by NCF[14]. (每个用户 u u u的基本真相嵌入,即 h u h_u hu, 通过NCF观察到的大量相互作用学习[14])
- To mimic the cold-start users/items, in each training episode, we randomly sample K K K neighbors for each target user/item. We repeat the sampling process L − 1 L-1 L−1 steps from the target user to the L L L-1-order neighbors, which results in at most K l K^l Kl(1 ≤ l ≤ L) l l l-order neighbors for each target user/item. (为了模拟冷启动用户/项目,在每一次训练中,我们随机抽取每个目标用户/项目的K邻居。.从目标用户到 L − 1 L-1 L−1阶邻居的取样过程我们重复 L − 1 L-1 L−1步,每个目标用户/物品最多产生 K l K^l Kl(1 ≤ l ≤ L) l l l-order 邻居。)
- Similar to GraphSAGE [11], we sample high-order neighbors to improve the computational efficiency. Upon the sampled first/high-order neighbors for the target user u u u, the graph convolution described in Eq. (1) is applied L L L-1 steps to obtain the embeddings { h 1 L − 1 , ⋅ ⋅ ⋅ , h K L − 1 } \{h^{L−1}_1 ,· · · , h^{L−1}_K \} {h1L−1,⋅⋅⋅,hKL−1} for the K K K first-order neighbors of u u u. (与GraphSAGE[11]类似,我们对高阶邻域进行采样以提高计算效率。在目标用户 u u u的采样的一阶/高阶邻居之后,应用等式(1)中描述的图卷积被应用 L L L-1来步获得u的K个 一阶邻居的嵌入)
- Then we aggregate them together to obtain the embedding of the target user u u u. Unlike the previous L L L-1 steps that concatenates h u l − 1 h^{l−1}_u hul−1 and h N ( u ) l h^l_{N(u)} hN(u)l to obtain h u l h^l_u hul for each neighbor (Cf. Eq. (1)), we only use h N ( u ) L h^L_{N(u)} hN(u)L to represent the target embedding h u L h^L_u huL, as we aim to predict the target embedding by the neighbors’ embeddings: (然后我们将它们聚合在一起,以获得目标用户uu的嵌入。与之前的LL-1步骤不同)
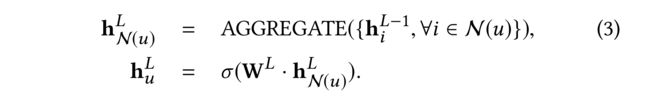
- Finally, we use cosine similarity to measure the difference between the predicted target embedding h u L h^L_u huL and the ground-truth embedding h u hu hu, as proposed by [16], due to its popularity as an indicator for the semantic similarity between embeddings:
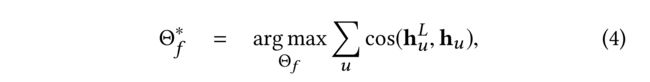
- where Θ f = W L , Θ g n n \Theta_f= {W^L, \Theta_{gnn}} Θf=WL,Θgnn is the set of the parameters in f f f .
- (3) Training GNNs in the meta-learning setting can explicitly reconstruct the user/item embeddings, making GNNs easily and rapidly being adapted to new cold-start users/items. (在元学习环境中训练GNN可以显式地重构用户/项目嵌入,使GNN轻松快速地适应新的冷启动用户/项目。)
- After the model is trained, for a new arriving cold-start user or item, based on the few first-order neighbors and the high-order neighbors, we can predict an accurate embedding for it. (该模型经过训练后,对于新到达的冷启动用户或项目,基于少量的一阶邻域和高阶邻域,我们可以预测它的准确嵌入。)
- However, the basic pre-training GNN model doesn’t specially address the cold-start neighbors. During the original graph convolution process, the inaccurate embeddings of the cold-start neighbors and the embeddings of other neighbors are equally treated and aggregated to represent the target user/item. (然而,基本的预训练GNN模型并没有专门针对冷启动邻居。在原始的图卷积过程中,冷启动邻域的不准确嵌入和其他邻域的嵌入被平等地处理和聚合,以表示目标用户/项。) 这篇论文,理论的针对点。冷启动用户的embedding是inaccurate
- Although some GNN models such as GrageSAGE or FastGCN filter neighbors before aggregating them, they usually follow the random or importance sampling strategies, which ignore the cold-start characteristics of the neighbors. Out of this consideration, we incorporate a meta aggregator and an adaptive neighbor sampler into the above basic pre-training GNN model. (尽管一些GNN模型(如GrageSAGE或FastGCN)在聚合邻居之前会对其进行过滤,但它们通常遵循随机或重要抽样策略,忽略了邻居的冷启动特性。出于这一考虑,我们将元聚合器和自适应邻居采样器合并到上述基本的预训练GNN模型中。)
3.2 Meta Aggregator
-
(1)We propose the Meta Aggregator to deal with the cold-start neighbors.
-
(2)Suppose the target node is u u u and one of its neighbor is i i i, if i i i is interacted with sparse nodes, its embedding, which is inaccurate, will affect the embedding of u u u when performing graph convolution by the GNN f f f . Although the cold-start issue of i i i is dealt with when i i i acts as another target node, embedding i i i, which is parallel to embedding u u u, results in a delayed effect on u’ embedding. Thus, before training the GNN f f f , we train another function g g g under the similar meta-learning setting as f f f . The meta learner g g g learns an additional embedding for each node only based on its first-order neighbors, thus it can quickly adapt to new cold-start nodes and produce more accurate embeddings for them. The embedding produced by g g g is combined with the original embedding at each convolution in f f f . Although both f f f and g g g are trained under the same meta-learning setting, ** f f f is to tackle the cold-start target ndoes, but g g g is to enhance the cold-start neighbors’ embeddings. ** (假设目标节点是 u u u,其一个邻居是 i i i,如果 i i i与稀疏节点交互,其嵌入不准确,将影响GNN f f f执行图卷积时 u u u的嵌入。虽然当 i i i作为另一个目标节点时, i i i的冷启动问题会得到解决,但嵌入 i i i(与嵌入 u u u平行)会导致 u u u’嵌入的延迟效应。因此,在训练GNN f f f之前,我们在与 f f f类似的元学习设置下训练另一个函数 g g g。元学习器 g g g仅基于每个节点的一阶邻居学习一个额外的嵌入,因此它可以快速适应新的冷启动节点,并为它们生成更精确的嵌入。 g g g生成的嵌入与 f f f中每个卷积处的原始嵌入相结合。虽然 f f f和 g g g都是在相同的元学习环境下训练的,但 f f f是为了解决冷启动目标ndoes,而 g g g是为了增强冷启动邻居的嵌入。)
-
(3)Specifically, we instantiate g g g as a self-attention encoder [30]. (具体来说,我们将 g g g实例化为一个自我关注编码器[30])
- For each user u u u, g g g accepts the initial embeddings { h 1 0 , ⋅ ⋅ ⋅ , h K 0 } \{h^0_1,· · · ,h^0_K\} {h10,⋅⋅⋅,hK0} of the K K K first-order neighbors for u u u as input, (对于每个用户 u u u, g g g接受 u u u的 K K K个一阶邻居初始嵌入作为输入)
- calculates the attention scores of all the neighbors to each neighbor i i i of u u u, (计算所有邻居对 u u u每个邻居 i i i的注意力得分)
- aggregates all the neighbors’ embeddings according to the attention scores to produce the embedding h i h_i hi for each i i i, (根据注意力得分聚合所有邻居的嵌入,对每个 i i i生成嵌入 h i h_i hi)
- and finally averages the embeddings of all the neighbors to get the embedding h ~ u \tilde{h}u h~u, named as the meta embedding of user u u u. (最后平均所有邻居的嵌入,得到嵌入 h ~ u \tilde{h}_u h~u, 称为 u u u的元嵌入)
- The process is formulated as:
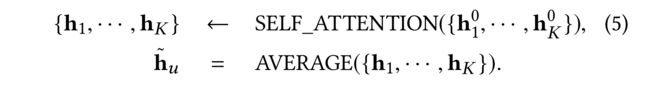
-
(4)The self-attention technique, which pushes the dissimilar neighbors further apart and pulls the similar neighbors closer together, can capture the major preference of the nodes from its neighbors. The same cosine similarity described in Eq.(4) is used as the loss function to measure the difference between the predicted meta embedding h ~ u \tilde{h}u h~u and the ground truth embeding h u h_u hu. Once g g g is learned, we add the meta embedding h ~ u \tilde{h}u h~u into each graph convolution step of the GNN f f f in Eq. (1): (自我注意技术将不同的邻居进一步分开,将相似的邻居拉近,可以从邻居那里捕获节点的主要偏好。使用等式(4)中描述的相同余弦相似性作为损失函数,以测量预测的元嵌入 h ~ u \tilde{h}u h~u 和基础真值嵌入 h u h_u hu之间的差异 .一旦学习了 g g g,我们将元嵌入 h ~ u \tilde{h}u h~u添加到等式(1)中GNN f f f的每个图卷积步骤中)

- where the target embedding h u l − 1 h^{l−1}_u hul−1 of the former step, the aggregated neighbor embedding h N ( u ) l h^l_{N(u)} hN(u)lof this step are learned following the basic pre-training GNN model.
-
(5)For a target user u u u, Eq.(6) is repeated L L L-1 steps to obtain the embeddings { h 1 L − 1 , ⋅ ⋅ ⋅ , h K L − 1 } \{h^{L−1}_1 ,· · · ,h^{L−1}_K\} {h1L−1,⋅⋅⋅,hKL−1} for its K K K first-order neighbors,
- Eq. (3) is also applied on them to get the final embedding h u L h^L_u huL,
- and finally the same cosine similarity in Eq. (4) is used to optimize the parameters of the meta aggregator, which includes the parameters Θ f \Theta_f Θf of the basic pre-training GNN and Θ g \Theta_g Θg of the meta-learner.
- The meta aggregator extends the original GNN graph convolution through emphasizing the representations of the cold-start neighbors in each convolution step, which can improve the final embeddings of the target users/items. (元聚合器通过在每个卷积步骤中强调冷启动邻居的表示来扩展原始GNN图卷积,这可以改进目标用户/项的最终嵌入。)
3.3 The Adaptive Neighbor Sampler
-
(1)The proposed sampler does not make any assumption about what kind of neighbors are useful for the target users/items. Instead, it learns an adaptive sampling strategy according to the feedbacks from the pre-training GNN model. (提出的采样器没有假设什么样的邻居对目标用户/项目有用。相反,它根据预训练GNN模型的反馈学习自适应采样策略。)
-
(2)To achieve this goal, we cast the task of neighbor sampler as a hierarchical Markov Decision Process (MDP) [28, 47].
- Specifically, we formulate the neighbor sampler as L L L−1 MDP subtasks where the l l l-th subtask indicates sampling the l l l-order neighors. The subtasks are performed sequentially by sampling from the second-order to L-order neighbors. When the l l l-th subtask deletes all the neighbors or the L L L-th subtask is finished, the overall task is finished. We will introduce how to design the state, action and the reward for these subtasks as below. (具体来说,我们将邻域采样器表示为L−1个MDP子任务,其中第 l l l个子任务表示对 l l l阶邻居进行采样。子任务通过从二阶到L阶邻域采样顺序执行。当第 l l l个子任务删除所有邻居或第 L L L个子任务完成时,整个任务完成。下面我们将介绍如何为这些子任务设计状态、操作和奖励。)
-
(3)State. The l l l-th subtask takes an action at the t t t-th l l l-order neighbor to determine whether to sample it or not according to the state of the target user u u u, the formerly selected neighbors, and the t t t-th l l l-order neighbor to be determined. We define the state features s t l s^l_t stl for the t-th l-order neighbor as the cosine similarity and the element-wise product between its initial embedding and the target user u u u’s initial embedding, the initial embedding of each formerly selected neighbor by the l l l-1-th subtask and the average embedding of all the formerly selected neighbors respectively. (状态. l l l-th子任务在t-th-l-order邻居处执行操作,以根据目标用户 u u u、先前选择的邻居和要确定的t-th-l-order邻居的状态来确定是否对其进行采样。我们定义了状态特征 s t l s^l_t stl对于作为余弦相似度的第 t t t个 l l l阶邻居,以及其初始嵌入和目标用户u的初始嵌入之间的元素乘积,分别通过 l l l-1子任务对每个先前选择的邻居的初始嵌入和所有先前选择的邻居的平均嵌入。)
-
(4)Action and Policy. We define the action a t l ∈ { 0 , 1 } a^l_t \in \{0,1\} atl∈{0,1} for the t t t-th l l l-order neighbor as a binary value to represent whether to sample the neighbor or not. We perform a t l a^l_t atl by the policy function P P P: (第 t t t个 l l l阶邻居为二进制值,以表示是否对邻居进行采样)
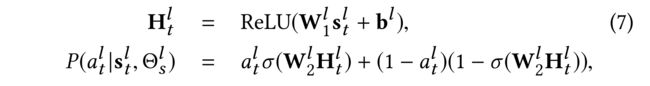
- where W 1 l ∈ R d s × d W^l_1 \in R^{ds\times d} W1l∈Rds×d , W 2 l ∈ R d × 1 W^l_2 \in R^{d×1} W2l∈Rd×1 and b l ∈ R d s b^l \in R^{d_s} bl∈Rds are the parameters to be learned,
- d s d_s ds is the number of the state features
- and d d d is the embedding size.
- Notation H t l H^l_t Htl represents the embedding of the input state
- and Θ s l = { W 1 l , W 2 l , b l } \Theta^l_s= \{W^l_1,W^l_2,b^l\} Θsl={W1l,W2l,bl}.
- Sigmoid function σ \sigma σ is used to transform the input state into a probability.
-
(5) Reward. The reward is a signal to indicate whether the performed actions are reasonable or not. Suppose the sampling task is finished at the l l l′-th subtask, each action of the formerly performed l l l′subtasks accepts a delayed reward after the last action of the l l l′-level subtask. In another word, the immediate reward for an action is zero except the last action. The reward is formulated as: (奖励是一个信号,表明所采取的行动是否合理。假设采样任务在l′th子任务完成,之前执行的l′子任务的每个动作在l′level子任务的最后一个动作之后接受延迟奖励。换句话说,除了最后一个动作外,一个动作的即时奖励为零。奖励的形式如下:)
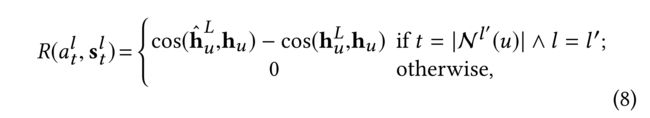
- where h u L h^L_u huL is the predicted embedding of the target user u u u after the L L L-step convolution by Eq. (6) and Eq. (3), while h ~ u L \tilde{h}^L_u h~uL is predicted in the same way but on the sampled neighbors following the policy function in Eq. (7). The cosine similarity between the predicted embedding and the ground truth embedding indicates the performance of the pre-training GNN Model. The difference between the performance caused by h ~ u L \tilde{h}^L_u h~uL and h u L h^L_u huL reflects the sampling effect.
-
(6)Objective Function. We find the optimal parameters of the policy function defined in Eq. (7) by maximizing the expected reward ∑ τ P ( τ ; Θ s ) R ( τ ) \sum_{\tau} P(τ;\Theta_s)R(\tau) ∑τP(τ;Θs)R(τ),
- where τ = s 1 1 , a 1 1 , s 2 1 , ⋅ ⋅ ⋅ , s t l ′ , a t l ′ , s t + 1 l ′ , ⋅ ⋅ ⋅ \tau = {s^1_1,a^1_1,s^1_2,· · · ,s^{l′}_t,a^{l′}_t,s^{l′}_{t+1},· · · } τ=s11,a11,s21,⋅⋅⋅,stl′,atl′,st+1l′,⋅⋅⋅ is a sequence of the sampled actions and the transited states,
- P ( τ ; Θ s ) P(\tau; \Theta_s) P(τ;Θs) denotes the corresponding sampling probability,
- R ( τ ) R(\tau) R(τ) is the reward for the sampled sequence τ \tau τ,
- and Θ s = { Θ s 1 , ⋅ ⋅ ⋅ , Θ s L } \Theta_s= \{\Theta^1_s,· · · ,\Theta^L_s\} Θs={Θs1,⋅⋅⋅,ΘsL}.
-
(7)Since there are too many possible action-state trajectories for the entire sequence, we adopt the monto-carlo policy gradient [39] to sample M M M action-state trajectories and calculate the gradients: (由于整个序列有太多可能的动作状态轨迹,我们采用monto carlo策略梯度[39]对M动作状态轨迹进行采样并计算梯度:)
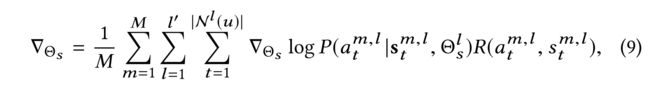
- where s t m , l s^{m,l}_t stm,l represents the state of the t t t-th l l l-order neighbor in the m m m-th action-state trajectory,
- and a t m , l a^{m,l}_t atm,l denotes the corresponding action.
- N l ( u ) N^l(u) Nl(u) indicates the set of all the l-order neighbors.
-
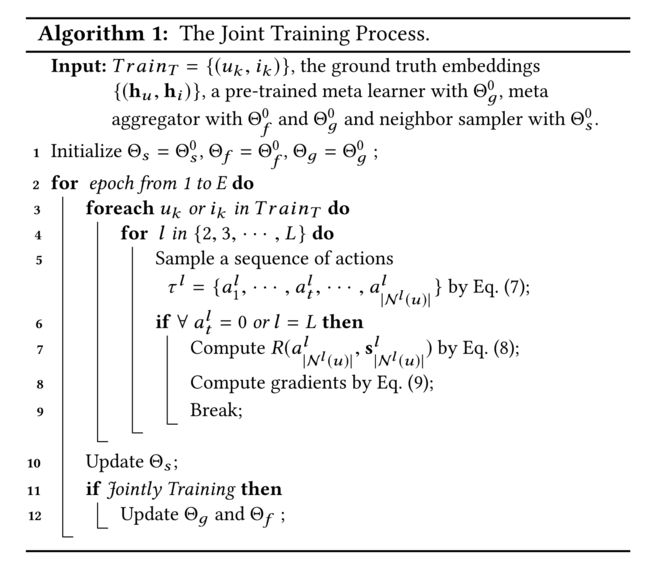
(8) Algorithm 1 shows the training process of the adaptive neighbor sampler. At each step l l l, we sample a sequence of actions A l A^l Al(Line 5). If all the actions at the l l l-th step equal to zero or the last L L L-th step is performed (Line 6), the whole task is finished, then we compute the reward (Line 7) and the gradients (Line 8). After an epoch of sampling, we update the parameters of the sampler (Line 10). If it is jointly trained with the meta learner and the meta aggregator, we also update their parameters (Line 12). (算法1显示了自适应邻居采样器的训练过程。在每个步骤 l l l中,我们对一系列动作 a l a^l al(第5行)进行采样。如果第11步的所有动作都等于零,或者最后一个第11步的动作都完成了(第6行),整个任务就完成了,那么我们计算奖励(第7行)和梯度(第8行)。采样一段时间后,我们更新采样器的参数(第10行)。如果它与元学习者和元聚合器联合训练,我们也会更新它们的参数(第12行)。)
3.4 Model Training

- The whole process of the pre-training GNN model is shown in Algorithm 2,
- where we first pre-train the meta learner g g g only based on first-order neighbors (Line 1), (我们首先只基于一阶邻域对元学习者g进行预训练(第1行),)
- and then incorporate g g g into each graph convolution step to pre-train the meta aggregator (Line 2), (然后将g合并到每个图卷积步骤中,以预训练元聚合器(第2行),)
- next we pre-train the neighbor sampler with feedbacks from the pre-trained meta aggregator (Line 3), (接下来,我们使用预先训练的元聚合器(第3行)的反馈对邻居采样器进行预训练,)
- and finally we jointly train the meta learner, the meta aggregator and the neighbor sampler together (Line 4). (最后,我们共同训练元学习者、元聚合器和邻居取样器(第4行)。)
- Same as the settings of [8, 47], to have a stable update during joint training, each parameter Θ ∈ { Θ f , Θ g , Θ s } \Theta \in \{\Theta_f, \Theta_g, \Theta_s\} Θ∈{Θf,Θg,Θs} is updated by a linear combination of its old version and the new old version, i.e., Θ n e w = λ Θ n e w + ( 1 − λ ) Θ o l d \Theta_{new} = \lambda \Theta_{new} + (1 − \lambda)\Theta_{old} Θnew=λΘnew+(1−λ)Θold, where λ ≪ 1 \lambda \ll 1 λ≪1.
3.5 Downstream Recommendation Task
- After the pre-training GNN model is learned, we can fine-tune it in the recommendation downstream task.
- Specifically, for each target user u u u and his neighbors { N 1 ( u ) , ⋅ ⋅ ⋅ , N L ( u ) } \{N^1(u),· · · ,N^L(u)\} {N1(u),⋅⋅⋅,NL(u)} of different order, we first use the pre-trained neighbor sampler to sample proper high-order neighbors { N 1 ( u ) , N ^ 2 ( u ) ⋅ ⋅ ⋅ , N ^ L ( u ) } \{N1(u),\hat{N}^2(u) · · · ,\hat{N}^L(u)\} {N1(u),N^2(u)⋅⋅⋅,N^L(u)}, and then use the pre-trained meta aggregator to produce the user embedding h u L h^L_u huL. The item embeddings are generated in the same way. Then we transform the embeddings and make a product between a user and an item to obtain the relevance score y ( u , i ) = σ ( W ⋅ h u L ) T σ ( W ⋅ h i L ) y(u,i) = \sigma {(W · h^L_u)}^T\sigma(W·h^L_i) y(u,i)=σ(W⋅huL)Tσ(W⋅hiL) with parameters Θ r = { W } \Theta_r= \{W\} Θr={W}. The BPR loss defined in Eq. (2) is used to optimize Θ r \Theta_r Θr and fine-tune Θ g \Theta_g Θg, Θ f \Theta_f Θf and Θ s \Theta_s Θs.
4 EXPERIMENT
- In this section, we present two types of experiments to evaluate the performance of the proposed pre-training GNN model. (在本节中,我们将介绍两种类型的实验来评估所提出的训练前GNN模型的性能)
- One is an intrinsic evaluation which aims to directly evaluate the quality of the user/item embedding predicted by the pre-training model. (一种是内在评估,旨在直接评估预训练模型预测的用户/项目嵌入质量。)
- The other one is an extrinsic evaluation which applies the proposed pre-training model into the downstream recommendation task and indirectly evaluate the recommendation performance. (另一种是外部评估,它将所提出的预训练模型应用于下游推荐任务,并间接评估推荐性能。)
4.1 Experimental Setup
4.1.1 Dataset.
We evaluate on three public datasets including MovieLens-1M (Ml-1M)3[12], MOOCs4[47] and Last.fm5. Table 1 illustrates the statistics of these datasets. The code is available now.

4.1.2 Baselines.
-
(1)We select three types of baselines including the state-of-the-art neural matrix factorization model, the general GNN models and the special GNN models for recommendation: (我们选择了三种类型的基线,包括最先进的神经矩阵分解模型、通用GNN模型和特殊GNN模型,以供推荐:)
- NCF [14]: is a neural matrix factorization model which combines Multi-layer Perceptron and matrix factorization to learn the embeddings of users and items. (NCF[14]:是一种神经矩阵分解模型,它结合多层感知器和矩阵分解来学习用户和项目的嵌入。)
- GraphSAGE [11]: is a general GNN model which samples neighbors randomly and aggregates them by the AVERAGE function. (GraphSAGE[11]:是一个通用的GNN模型,它随机对相邻的数据进行采样,并通过平均函数进行聚合。)
- GAT [31]: is a general GNN model which aggregates neighbors by the attention mechanism without sampling. (GAT[31]:是一个通用的GNN模型,它通过注意机制聚集邻居,无需采样。)
- FastGCN [4]: is also a general GNN model which samples the neighbors by the important sampling strategy and aggregates neighbors by the same aggregator as GCN [19]. (FastGCN[4]:也是一种通用的GNN模型,它通过重要的采样策略对邻居进行采样,并通过与GCN相同的聚合器对邻居进行聚合[19]。)
- FBNE [3]: is a special GNN model for recommendation, which samples the neighbors by the importance sampling strategy and aggregates them by the AVERAGE function based on the explicit user-item and the implicit user-user/item-item interactions. (FBNE[3]:是一种特殊的推荐GNN模型,它基于显式用户项和隐式用户/项交互,通过重要性抽样策略对邻居进行抽样,并通过平均函数进行聚合。)
- LightGCN [13]: is a special GNN model for recommendation, which discards the feature transformation and the nonlinear activation functions in the GCN aggregator. (LightGCN[13]:是一个用于推荐的特殊GNN模型,它抛弃了GCN聚合器中的特征转换和非线性激活函数。)
-
(2)For each GNN model, we evaluate the corresponding pre-training model.
- For example, for the GAT model,
- Basic-GAT means we apply GAT into the basic pre-training GNN model proposed in Section 3.1,
- Meta-GAT indicates we incorporate the meta aggregator proposed in Section 3.2 into Basic-GAT,
- NSampler-GAT represents that we incorporate the adaptive neighbor sampler proposed in Section 3.3 into Basic-GAT,
- and GAT* is the final poposed pre-training GNN model that incorporates both the meta aggregator and the adaptive neighbor sampler into Basic-GAT.
- For example, for the GAT model,
-
(3)The original GAT and LightGCN models use the whole adjacency matrix, i.e., all the neighbors, in the aggregation function. To train them more efficiently, we implement them in the same sampling way as GraphSAGE, where we randomly sample at most 10 neighbors for each user/item. Then the proposed pre-training GNN model is performed under the sampled graph. (原始的GAT和LightGCN模型在聚合函数中使用整个邻接矩阵,即所有邻居。为了更有效地训练它们,我们采用与GraphSAGE相同的采样方式实现它们,在GraphSAGE中,我们为每个用户/项目随机采样最多10个邻居。然后,在采样图下执行所提出的预训练GNN模型。)
4.1.3 Intrinsic and Extrinsic Settings.
- We divide each dataset into the meta-training set D T D_T DT and the meta-test set D N D_N DN. (我们将每个数据集划分为元训练集 D T D_T DT元测试集 D N D_N DN)
- We train and evaluate the pre-training GNN model in the intrinsic user/item embedding inference task on D T D_T DT. (我们在 D T D_T DT上的内在用户/项目嵌入推理任务中训练和评估预训练GNN模型)
- Once the model is trained, we fine-tune it in the extrinsic downstream recommendation task and evaluate it on D N D_N DN. (一旦模型经过训练,我们将在外部下游推荐任务中对其进行微调,并在 D N D_N DN上对其进行评估)
- We select the ==users/items= from each dataset with sufficient interactions as the target users/items in D T D_T DT, as the intrinsic evaluation needs the true embeddings of users/items inferred from the sufficient interactions. (我们从每个具有足够交互的数据集中选择users/items作为 D T D_T DT中的目标用户/项 , 因为内在评估需要从充分的交互中推断出用户/项目的真正嵌入。)
- Take the scenario of cold-start users as an example, we divide the users with the number of the direct interacted items more than n i n_i ni into D T D_T DT and leave the rest users into D N D_N DN. We select n i n_i ni as 60 and 20 for the dataset Ml-1M and MOOCs respectively. Since the users in Last.fm interact with too many items, we randomly sample 200 users, put 100 users into D T D_T DT and leave the rest 100 users into D N D_N DN. For each user in D N D_N DN, we only keep its K K K-shot items to simulate the cold-start users. (以冷启动用户场景为例,我们将用户划分为直接交互项的数量大于 n i n_i ni的用户进入 D T D_T DT,让其余的用户进入 D N D_N DN. 我们选择数据集Ml-1M和MOOC的 n i n_i ni分别为60和20。因为Last.fm中的用户与太多项目交互,我们随机抽取200个用户,将100个用户放入 D T D_T DT,其余的100个用户分进 D N D_N DN. 对于 D N D_N DN中的每个用户, 我们只保留其K-shot项目,以模拟冷启动用户。)
- Similarly, for the cold-start item scenario, we divide the items with the number of the direct interacted users more than n u n_u nu into D T D_T DT and leave the rest items into D N D_N DN, where n u n_u nu is set as 60, 20 and 15 for MovieLens-1M, MOOCs and Last.fm respectively. In the intrinsic task, K K K is set as 3 and 8, while in the extrinsic task, K K K is set as 8. The embedding size d is set as 256. The number of the state features d s d_s ds is set as 2819.
4.2 Intrinsic Evaluations: Embedding Inference
In this section, we conduct the intrinsic evaluation of inferring the embeddings of cold-start users/items by the proposed pre-training GNN model. Both the evaluations on the user embedding inference and the item embedding inference are performed. (在本节中,我们通过提出的预训练GNN模型对推断冷启动用户/项目的嵌入进行内在评估。对用户嵌入推理和项目嵌入推理进行评估。)
4.2.1 Training and Test Settings.
-
(1) We use the meta-training set D T D_T DT to perform the intrinsic evaluation. (我们使用元训练集 D T D_T DT进行内在评估)
- Specifically, we randomly split D T D_T DT into the training set T r a i n T Train_T TrainT and the test set T e s t T Test_T TestT with a ratio of 7:3.
- We train NCF [14] to get the ground-truth embeddings for the target users/items in both T r a i n T Train_T TrainT and T e s t T Test_T TestT. (我们培训NCF[14]为目标用户/项目在这两个领域获得ground-truth嵌入)
- To mimic the cold-start users/items on T e s t T Test_T TestT, we randomly keep K K K neighbors for each user/item, which results in at most K l K^l Kl neighbors (1 ≤ l l l ≤ 3) for each target user/item. Thus T e s t T Test_T TestT is changed into T e s t T ′ Test^′_T TestT′
-
(2)The original GNN models are trained by BPR loss in Eq. (2) on T r a i n T Train_T TrainT. The proposed pre-training GNN models are trained by the cosine similarity in Eq. (4) on T r a i n T Train_T TrainT. The NCF model is trained transductively to obtain the user/item embeddings on the merge dataset of T r a i n T Train_T TrainT and T e s t T ′ Test^′_T TestT′. The embeddings in both the proposed models and the GNN models are initialized by the NCF embedding results. We use Spearman correlation [16] to measure the agreement between the ground truth embedding and the predicted embedding. (所提出的模型和GNN模型中的嵌入均由NCF嵌入结果初始化。我们使用斯皮尔曼相关性[16]来衡量地面真值嵌入和预测嵌入之间的一致性。)
4.2.2 Overall Performance.
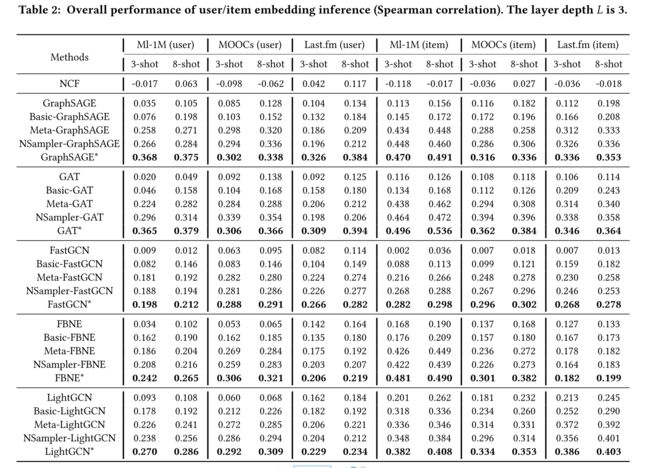
- Table 2 shows the overall performance of the proposed pre-training GNN model and all the baselines using 3-order neighbors. The results show that compared with the baselines, our proposed pre-training GNN model significantly improves the quality of the user/item embeddings (+33.9%-58.4% in terms of Spearman correlation). Besides, we have the following findings: (表2显示了建议的训练前GNN模型的总体性能,以及使用三阶邻域的所有基线。结果表明,与基线相比,我们提出的训练前GNN模型显著提高了用户/项目嵌入的质量(在Spearman相关性方面为33.9%-58.4%)。此外,我们有以下发现:)
- Through incorporating the high-order neighbors, the GNN models can improve the embedding quality of the cold-start users/items compared with the NCF model (+2.6%-24.9% in terms of Spearman correlation). (通过引入高阶邻域,GNN模型可以提高冷启动用户/项目的嵌入质量,与NCF模型相比(+2.6%-24.9%的Spearman相关性)。)
- All the basic pre-training GNN models beat the corresponding GNN models by improving 1.79-15.20% Spearman correlation, which indicates the basic pre-training GNN model is capable of reconstructing the cold-start user/item embeddings. (所有基本预训练GNN模型均优于相应的GNN模型,其Spearman相关性提高了1.79-15.20%,表明基本预训练GNN模型能够重构冷启动用户/项目嵌入。)
- Compared with the basic pre-training GNN model, both the meta aggregator and the adaptive neighbor sampler can improve the embedding quality by 1.09%-18.20% in terms of the Spearman correlation, which indicates that the meta aggregator can indeed strengthen each layer’s aggregation ability and the neighbor sampler can filter out the noisy neighbors. (与基本的预训练GNN模型相比,元聚合器和自适应邻居采样器在Spearman相关性方面都能将嵌入质量提高1.09%-18.20%,这表明元聚合器确实可以增强每一层的聚合能力,而邻居采样器可以过滤掉有噪声的邻居。)
- When the neighbor size K decreases from 8 to 3, the Spearman correlation of all the baselines significantly decrease 0.08%-6.10%, while the proposed models still keep a competitive performance. (当邻域大小K从8减小到3时,所有基线的Spearman相关性显著降低0.08%-6.10%,而所提出的模型仍保持有竞争力的性能。)
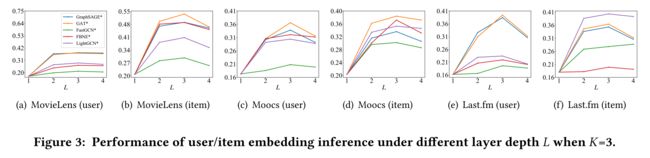
- We also investigate the effect of the propagation layer depth L on the model performance. In particular, we set the layer depth L as 1,2,3 and 4, and report the performance in Fig. 3. The results show when L is 3, most algorithms can achieve the best performance, while only using the first-order neighbors performs the worst8, which implies incorporating proper number of layers can alleviate the cold-start issue. (我们还研究了传播层深度L对模型性能的影响。特别是,我们将层深度L设置为1、2、3和4,并在图3中报告性能。结果表明,当L为3时,大多数算法可以获得最佳性能,而仅使用一阶邻域执行最差的8,这意味着加入适当数量的层可以缓解冷启动问题。)
4.3 Extrinsic Evaluation:
Recommendation In this section, we apply the pre-training GNN model into the downstream recommendation task and evaluate the performance. (建议在本节中,我们将训练前GNN模型应用到下游推荐任务中,并评估其性能。)
4.3.1 Training and Testing Settings.
-
(1)We consider the scenario of the cold-start users and use the meta-test set DNto perform recommendation. For each user in DN, we select top 10% of his interacted items in chronological order into the training setT rainN, and leave the rest items into the test setT estN. We pre-train our model on DTand fine-tune it onT rainNaccording to Section 3.5.
-
(2)The original GNN and the NCF models are trained by the BPR loss function in Eq. (2) on DTandT rainN. For each user inT estN, we calculate the user’s relevance score to each of the rest 90% items. We adopt Recall@K and NDCG@K as the metrics to evaluate the items ranked by the relevance scores. By default, we set K as 20 for Ml-1m and Moocs. For Last.fm, since there are too many items, we set K as 200.
4.3.2 Overall Performance.
-
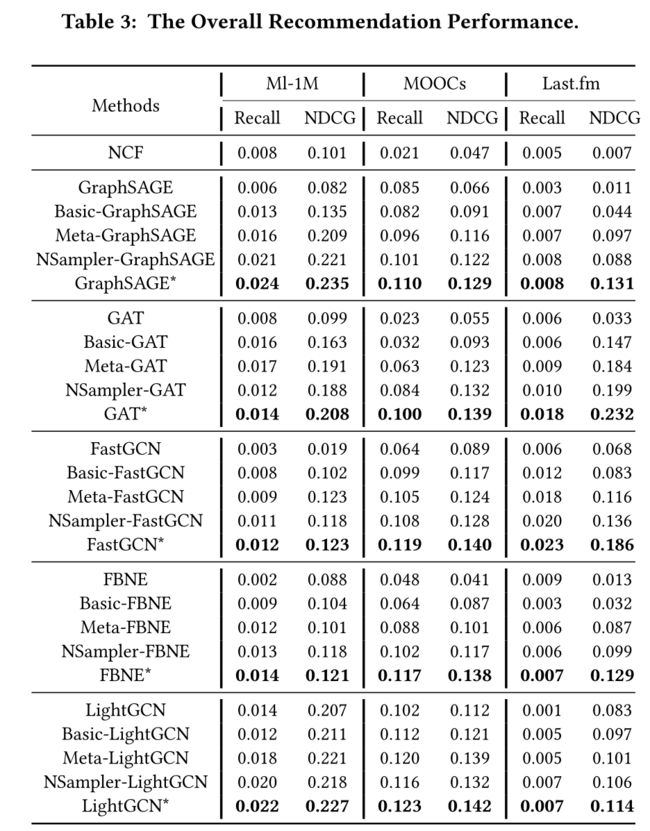
Table 3 shows the overall recommendation performance. The results indicate that the proposed basic pre-training GNN models outperform the corresponding original GNN models by 0.40%-3.50% in terms of NDCG, which demonstrates the effectiveness of the basic pre-training GNN model on the cold-start recommendation performance. Upon the basic pre-training model, adding the meta aggregator and the adaptive neighbor sampler can further improve 0.30%-6.50% NDCG respectively, which indicates the two components can indeed alleviate the impact caused by the cold-start neighbors when embedding the target users/items, thus they can improve the downstream recommendation performance. (表3显示了总体推荐性能。结果表明,所提出的基本预训练GNN模型在NDCG方面比相应的原始GNN模型的性能提高了0.40%-3.50%,这表明了基本预训练GNN模型对冷启动推荐性能的有效性。在基本预训练模型的基础上,添加元聚合器和自适应邻居采样器,可以分别进一步提高0.30%-6.50%的NDCG,这表明这两个组件确实可以缓解嵌入目标用户/项目时冷启动邻居造成的影响,因此,它们可以提高下游推荐的性能。)
-
Case Study. We attempt to understand how the proposed pre-training model samples the high-order neighbors of the cold-start users/items by the MOOCs dataset. Fig. 4 illustrates two sampling cases, where notation * indicates the users/items are cold-start.
- The cold-start item i∗ 1099 is “Corporate Finance", which only interacts with three users. Our proposed neighbor sampler samples a second-order item i∗ 676, “Financial Statement". Although i∗ 676 only interacts with two users, it is relevant to the target item i∗ 1099.
- Similarly, the cold-start user u∗ 80467, who likes computer science, only selects three computer science related courses. The proposed neighbor sampler samples a second-order user u∗ 76517. Although it only interacts with two courses, they are “Python" and “VC++" which are relevant to computer science.
- However, the importance-based sampling strategies in FastGCN and FBNE cannot sample these neighbors, as they are cold-start with few interactions.

5 RELATED WORK
5.1 Cold-start Recommendation.
- Cold-start issue is a fundamental challenge in recommender systems.
- On one hand, existing recommender systems incorporate the side information such as spatial information [40, 44], social trust path [10, 36, 41, 42] and knowledge graphs [35,37] to enhance the representations of the cold-start users/items. However, the side information is not always available, making it intractable to improve the cold-start embedding’s quality. (一方面,现有的推荐系统结合了诸如空间信息[40,44]、社会信任路径[10,36,41,42]和知识图[35,37]等辅助信息,以增强冷启动用户/项目的表示。然而,旁侧信息并不总是可用的,因此难以提高冷启动嵌入的质量。)
- On the other hand, researchers solve the cold-start issue by only mining the underlying patterns behind the user-item interactions. (另一方面,研究人员仅通过挖掘用户项交互背后的潜在模式来解决冷启动问题。)
- One kind of the methods is meta-learning [9, 23, 26, 34], which consists of metric-based recommendation [29] and model-based recommendation [7, 20, 22, 24]. However, few of them capture the high-order interactions. (其中一种方法是元学习[9,23,26,34],它包括基于度量的推荐[29]和基于模型的推荐[7,20,22,24]。然而,它们很少捕捉到高阶相互作用)
- Another kind of method is GNNs, which leverage user-item bipartite graph to capture high-order collaborative signals for recommendation. The representative models include Pinsage [45], NGCF [38], LightGCN [13], FBNE [3] and CAGR [42]. (另一种方法是GNNs,它利用用户项二部图捕捉高阶协作信号进行推荐。代表性模型包括Pinsage[45]、NGCF[38]、LightGCN[13]、FBNE[3]和CAGR[42]。)
- Generally, the recommendation-oriented GNNs optimize the likeli-hood of a user adopting an item, which isn’t a direct improvement of the embedding quality of the cold-start users or items. (一般来说,面向推荐的GNN优化了用户采用某个项目的可能性,这并不能直接提高冷启动用户或项目的嵌入质量。)
5.2 Pre-training GNNs.
- Recent advances on pre-training GNNs aim to empower GNNs to capture the structural and semantic properties of an input graph, so that it can easily generalize to any downstream tasks with a few fine-tuning steps on the graphs [17]. (关于预训练GNN的最新进展旨在使GNN能够捕获输入图的结构和语义属性,这样,只需对图进行一些微调,它就可以轻松地推广到任何下游任务[17]。)
- The basic idea is to design a domain specific pretext task to provide additional supervision for exploiting the graph structures and semantic properties. Examples include (其基本思想是设计一个特定于领域的借口任务,为利用图形结构和语义属性提供额外的监督。例子包括)
- (1) graph-level pretext task, which either distinguishes subgraphs of a certain node from those of other vertices [25] or maximize the mutual information between the local node representation and the global graph representations[27, 32]. (图级借口任务,它要么将某个节点的子图与其他顶点的子图区分开来[25],要么最大化局部节点表示和全局图表示之间的互信息[27,32]。)
- (2) Node-level task, which perform node feature and edge generation [17] pretext tasks. (节点级任务,执行节点特征和边缘生成[17]借口任务。)
- (3) Hybrid-level task, which considers both node and graph-level tasks [15, 46]. However, none of these models explore pre-training GNNs for recommendation, and we are the first to study the problem and define the reconstruction of the cold-start user/item embeddings as the pretext task. (混合级任务,同时考虑节点级和图级任务[15,46]。然而,这些模型都没有探索用于推荐的预训练GNN,我们是第一个研究这个问题并将冷启动用户/项目嵌入的重建定义为借口任务的人)
6 CONCLUSION
- This work explores pre-training a GNN model for addressing the cold-start recommendation problem.
- We propose a pretext task as reconstructing cold-start user/item embeddings to explicitly improve their embedding quality. (我们提出了一个前置任务,重建冷启动用户/项目嵌入,以明确提高其嵌入质量。)
- We further incorporate a self-attention-based meta aggregator to improve the aggregation ability of each graph convolution step, (我们还加入了一个基于自我注意的元聚合器,以提高每个图卷积步骤的聚合能力,)
- and propose a sampling strategy to adaptively sample neighbors according to the GNN performance. (提出了一种根据GNN性能自适应采样邻居的策略。)
- Experiments on three datasets demonstrate the effectiveness of our proposed pre-training GNN against the original GNN models. We will explore multiple pretext tasks in the future work.