NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
目录
5.5 实践:基于ResNet18网络完成图像分类任务
5.5.1 数据处理
5.5.2 模型构建
什么是“预训练模型”?什么是“迁移学习”?(必做)
5.5.3 比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
5.5.4 模型评价
5.5.5 模型预测
思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
心得体会
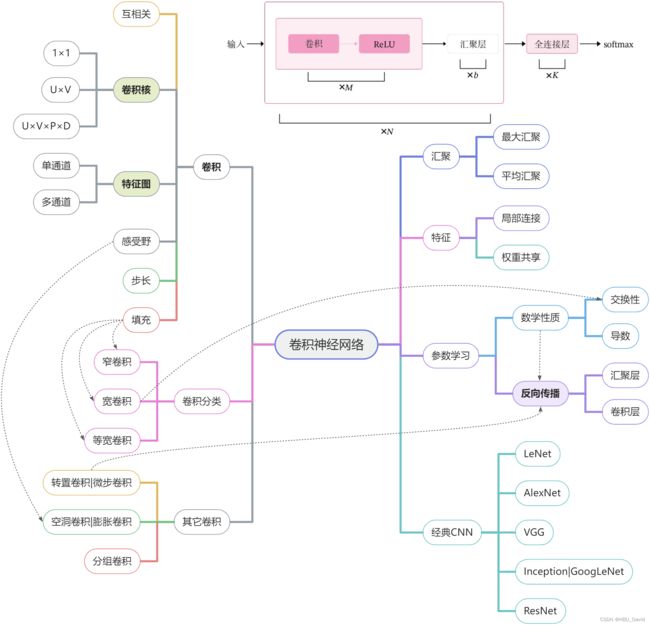
5.5 实践:基于ResNet18网络完成图像分类任务
图像分类(Image Classification)
计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。
很多任务可以转换为图像分类任务。
比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
- 数据集:CIFAR-10数据集,
- 网络:ResNet18模型,
- 损失函数:交叉熵损失,
- 优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
- 评价指标:准确率。
5.5.1 数据处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
5.5.2 模型构建
使用pyotorch高层API中的resnet18进行图像分类实验。
torchvision.models.resnet18()
什么是“预训练模型”?什么是“迁移学习”?(必做)
参考:预训练的简单概括就是使用尽可能多的训练数据,从中提取出尽可能多的共性特征,从而让模型对特定任务的学习负担变轻。 预训练方式表现在模型参数上,就是我之前已经拿到一个任务,这个任务和其他任务有很多相同之处,于是提前训练好了所有的模型参数(预训练)。因此我们不再需要从0开始训练所有参数了,但是针对我们目前这个任务,有些参数可能不合适,我们只需要在当前参数的基础上稍加修改(微调)就可以得到比较好的效果,这样学习时间必然会大大减小。而且,由于预训练过程和我们当前的任务不是同时进行的,所以可以提前花很长时间把几千亿乃至万万亿参数(现在应该还没)提前预训练好,以求和更多的具体任务都有重合,从而只需要我们微调就可以在各项任务达到不错的效果。
迁移学习,顾名思义,就是要进行迁移。放到人工智能和机器学习的学科里,迁移学习是一种学习的思想和模式。
首先机器学习是人工智能的一大类重要方法,也是目前发展最迅速、效果最显著的方法。机器学习解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可顺利地实现知识的迁移。
5.5.3 比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。
使用训练集和验证集进行模型训练,共训练30个epoch。
在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
import torch.nn.functional as F
import torch.optim as opt
from nndl import RunnerV3, Accuracy
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
lr = 0.001
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
model = resnet18_model
model.to(device)
optimizer = opt.SGD(model.parameters(), lr=lr, momentum=0.9)
loss_fn = F.cross_entropy
metric = Accuracy()
runner = RunnerV3(model, optimizer, loss_fn, metric)
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps, eval_steps=eval_steps, save_path="best_model.pdparams")运行结果:
cpu
[Train] epoch: 0/30, step: 0/18750, loss: 6.97701
[Train] epoch: 4/30, step: 3000/18750, loss: 0.85450
[Evaluate] dev score: 0.60330, dev loss: 1.16656
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.60330
[Train] epoch: 9/30, step: 6000/18750, loss: 0.29281
[Evaluate] dev score: 0.62940, dev loss: 1.44578
[Evaluate] best accuracy performence has been updated: 0.60330 --> 0.62940
[Train] epoch: 14/30, step: 9000/18750, loss: 0.17818
[Evaluate] dev score: 0.63910, dev loss: 1.70278
[Evaluate] best accuracy performence has been updated: 0.62940 --> 0.63910
[Train] epoch: 19/30, step: 12000/18750, loss: 0.02657
[Evaluate] dev score: 0.64540, dev loss: 1.80198
[Evaluate] best accuracy performence has been updated: 0.63910 --> 0.64540
[Train] epoch: 24/30, step: 15000/18750, loss: 0.04895
[Evaluate] dev score: 0.63760, dev loss: 2.00975
[Train] epoch: 28/30, step: 18000/18750, loss: 0.02457
[Evaluate] dev score: 0.64760, dev loss: 2.08300
[Evaluate] best accuracy performence has been updated: 0.64540 --> 0.64760
[Evaluate] dev score: 0.63870, dev loss: 2.08529
[Train] Training done!可视化观察训练集与验证集的准确率及损失变化情况。
def plot(runner, fig_name):
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
train_items = runner.train_step_losses[::30]
train_steps = [x[0] for x in train_items]
train_losses = [x[1] for x in train_items]
plt.plot(train_steps, train_losses, color='#8E004D', label="Train loss")
if runner.dev_losses[0][0] != -1:
dev_steps = [x[0] for x in runner.dev_losses]
dev_losses = [x[1] for x in runner.dev_losses]
plt.plot(dev_steps, dev_losses, color='#E20079', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='x-large')
plt.xlabel("step", fontsize='x-large')
plt.legend(loc='upper right', fontsize='x-large')
plt.subplot(1, 2, 2)
# 绘制评价准确率变化曲线
if runner.dev_losses[0][0] != -1:
plt.plot(dev_steps, runner.dev_scores,
color='#E20079', linestyle="--", label="Dev accuracy")
else:
plt.plot(list(range(len(runner.dev_scores))), runner.dev_scores,
color='#E20079', linestyle="--", label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize='x-large')
plt.xlabel("step", fontsize='x-large')
plt.legend(loc='lower right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()
plot(runner, fig_name='cnn-loss4.pdf')运行结果:

结果图像如上图所示,我们发现使用预训练模型后,模型训练的时间短,速度快,但是准确率和误差相比于未使用预训练模型基本一致。
5.5.4 模型评价
correct=0
total=0
with torch.no_grad():
for data in testloader:
images,labels=data
outputs=net(images)
_,predicted=torch.max(outputs.data,1)
total+=labels.size(0)
correct+=(predicted==labels).sum().item()#.item()用于取出tensor中的值。
print("Accuracy of the network on the 10000 test images: %d %%"%(100*correct/total))
运行结果:
[Test] accuracy/loss: 0.7270/1.82125.5.5 模型预测
同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:
#获取测试集中的一个batch的数据
X, label = next(iter(test_loader))
X = X.cpu()
logits = runner.predict(X)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
#获取概率最大的类别
pred_class = torch.argmax(pred[2]).numpy()
print(label[2].numpy())
label = label[2].numpy()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
#可视化图片
plt.figure(figsize=(2, 2))
imgs, labels = load_cifar10_batch(folder_path='C:\\Users\\0310\\PycharmProjects\\pythonProject\\cifar-10-batches-py', mode='test')
plt.imshow(imgs[2].transpose(1,2,0))
plt.savefig('cnn-test-vis.pdf')运行结果:
The true category is 8 and the predicted category is 8思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
本文章提出了残差学习网络ResNet,很好地解决了在线性的卷积神经网络中仅仅增加网络的深度,会出现的网络退化问题,使得网络的学习能力能够随着网络深度的增加而增加。其大幅度提高了深度卷积网络提取特征的能力,并使得计算机的在视觉方面的识别能力达到并超过了人类的水平。
本文通过引入残差学习(residual learning)来解决退化问题,即⊕ ⊕⊕上方学习的为 H ( x ) − x H(x)-xH(x)−x,这也正是要学习的残差F ( x ) = H ( x ) − x F(x)=H(x)-xF(x)=H(x)−x,希望通过H ( x ) = F ( x ) ⊕ x H(x)=F(x)⊕xH(x)=F(x)⊕x拟合x,这里引入了x,把恒等映射作为网络H(x)的一部分。而原本是H(x)拟合x。

2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
LeNet:深度CNN网络的基石。
AlexNet:改良加深版的LeNet,包含8层变换,效果出众,掀起深度学习热潮。
VGG:从图像中提取CNN特征的首选算法,迁移学习优于LeNet。
GoogLeNet:LeNet 2.0版本,引入了Inception结构,通过更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
ResNet:主要解决了深度网络中的退化的问题,在VGG基础上提升了长度,加入了res-block结构,是当下主流网络。
心得体会
本次实验对预训练模型和迁移学习,cifar10有关内容有了更加深刻的理解,并且和其他同学有很大差距,继续努力。
NNDL 实验5(下) - HBU_DAVID - 博客园 (cnblogs.com)
6. 卷积神经网络 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)