VOC数据集介绍及构建自己的VOC格式目标检测数据集
文章目录
- 1、安装标注工具
-
- 1.1 ubuntu linux 系统
- 1.2 windows系统
- 2、labelimg使用方法
- 3、标注结果文件说明
-
- 3.1 Pascal VOC数据集介绍
- 3.2 Pascal VOC格式
- 3.3 YOLO格式说明
- 4、标注图片和结果文件整理
-
- 4.1 Pascal VOC数据组织结构
- 4.2 自定义数据集整理为Pascal VOC格式
- 4.3 Pascal VOC 格式转YOLO
1、安装标注工具
数据格式是VOC格式,标注工具是labelimg,更多安装方法查看官网
1.1 ubuntu linux 系统
#克隆labeling
git clone https://github.com/tzutalin/labelImg
cd labelImg
#python3 和 pyqt5
sudo apt-get install pyqt5-dev-tools
python3 -m install pip install lxml pyqt5
python3 -m install pip install labelImg
labelImg [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
1.2 windows系统
下载地址,双击即可使用。data/predefined_classes.txt下的内容,可以修改自定义分类类别。
2、labelimg使用方法
本节将以windows系统的软件使用为例进行说明。图型界面如下:
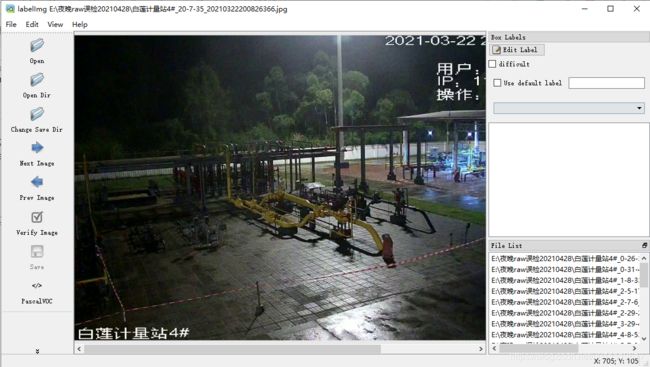
opendir用来打开图片所在文件夹
change save dir 用来选择结果保存文件夹,可以与图片文件夹是同一个
更多的快捷键如下:
| 快捷键 | 功能 |
|---|---|
| Ctrl+u | Load all of the images from a directory |
| Ctrl+r | Change the default annotation target dir |
| Ctrl+s | Save |
| Ctrl + d | Copy the current label and rect box |
| Ctrl + Shift + d | Delete the current image |
| Space | Flag the current image as verified |
| w | Create a rect box |
| d | Next image |
| a | Previous image |
| del | Delete the selected rect box |
| Ctrl++ | Zoom in |
| Ctrl– | Zoom out |
| ↑→↓← | Keyboard arrows to move selected rect box |
这些功能可以在标注图片过程中可以逐渐熟练使用,而且界面上有按钮可以来代替这些功能。要说明的是空格键来verfied图片,标注完成后,可以过一遍图片,来逐张验证,验证前后的区别是:
| 验证前 | 验证后 |
|---|---|
 |
 |
只是背景颜色的不现。
另外,VIew选项中,有几个按扭,可以提高标注效率: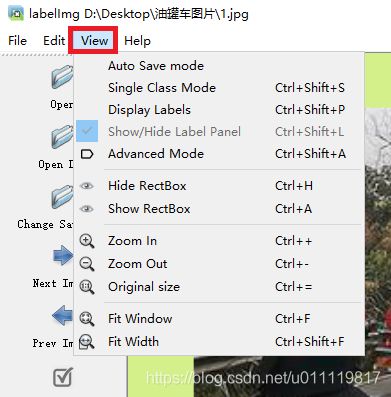
推荐使用xml格式进行保存结果,具本分析请看下文。
3、标注结果文件说明
标注工具上有两种格式可以选择,Pascal VOC和YOLO格式。
| Pascal VOC格式 | YOLO格式 |
|---|---|
 |
 |
对两种结果的文件分别进行保存然后查看:
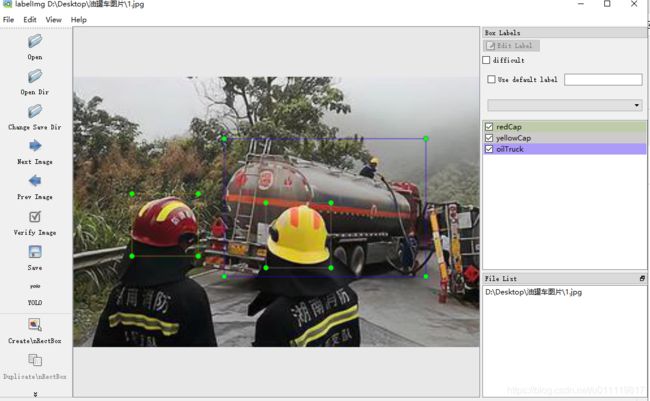
上图标注了三个类别,标注结果如下:
pascal voc格式保存结果为1.xml,yolo保存结果为1.txt和classes.txt。该软件对标注好的一张图片只能保存一次,所以对其中oilTruck这个分类的框微动一下后,再次保存的。不论那种结果保存格式,文件名与图片名一一对应,只有扩展名不同。下面看一下两种格式中的标注内容。
3.1 Pascal VOC数据集介绍
本段就贴个链接1,链接2吧,因为写的很好,在继续读下文前,一定要去认真看一看。
3.2 Pascal VOC格式
该种格式以xml文件进行保存,具体内容是:
<annotation>
<folder>油罐车图片</folder>
<filename>1.jpg</filename>
<path>D:\Desktop\油罐车图片\1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>312</width>
<height>208</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>redCap</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>43</xmin>
<ymin>92</ymin>
<xmax>96</xmax>
<ymax>144</ymax>
</bndbox>
</object>
<object>
<name>yellowCap</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>147</xmin>
<ymin>98</ymin>
<xmax>198</xmax>
<ymax>151</ymax>
</bndbox>
</object>
<object>
<name>oilTruck</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>111</xmin>
<ymin>46</ymin>
<xmax>266</xmax>
<ymax>157</ymax>
</bndbox>
</object>
</annotation>
从xml中可以看到每个分类的对应名称和位置xmin,ymin,xmax,ymax。labelimg标注坐标体系是左上角是(0,0),向右向下分别x,y的正方向。
3.3 YOLO格式说明
有两个文件,1.txt中存放结果,具体内容是:
0 0.222756 0.567308 0.169872 0.250000
1 0.552885 0.598558 0.163462 0.254808
2 0.600962 0.487981 0.496795 0.533654
classes.txt中具体内容是:
redCap
yellowCap
oilTruck
如果有多张图片时,会有与图片文件名相同的txt结果文件,但classes.txt文件只有一个,同时该文件的内容与labelimg下data/predefined_classes.txt内容相同。结果文件与classes.txt文件配合才可获得具体的结果。如果我们增加分类或修改predefined_classes.txt时,结果会发生改变,得出个结论就是使用YOLO格式保存结果不便于对标注做出改动,所以使用pascal voc格式比较好。
解释一下结果文件1.txt中内容的意义:
如第一行:0 0.222756 0.567308 0.169872 0.250000,0表示classes.txt 中第0行分类是redCap.剩下的四个数分别的标注框的(x,y,w,h),x,y是中心点,w是宽度,h是高度。与pascal voc xml文件中结果对应的具体计算公式如下:
#注释是xml的结果
w_img=312 # width
h_img=208 # height
x1 = 43 #xmin
x2 = 96 #xmax
y1 = 92 #ymin
y2 = 144 #ymax
x=(x1+x2)/2 = 69.5
y=(y1+y2)/2 = 118
w=x2-x1 = 53
h=y2-y1 = 52
x = x/w_img = 0.22275641 #四舍五入保留6位有效数字即为yolo文件中结果
y = y/h_img = 0.56730769
w = w/w_img = 0.16987179
h = h/h_img = 0.25
总的来说,不论是什么格式保存,结果无非是分类与位置共五个数
4、标注图片和结果文件整理
数据标注完以后,文件夹中是以.jpg结尾的图片和相同文件名以.xml结尾的标注结果,在训练前,要将这些文件整理成pascal voc格式。标注完成后的结果文件如下图:
4.1 Pascal VOC数据组织结构
Pascal VOC数据主要有2007和2012两年的数据,可以这里下载,也可以通过命令行下载:
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
2007有train,val,test,而2012只有train和val
下载后解压:
tar xf *.tar
解压后结果是:
#第一级
VOCdevkit
├── VOC2007
└── VOC2012
#第二级
VOCdevkit/VOC2007
├── Annotations
├── ImageSets
├── JPEGImages
├── SegmentationClass
└── SegmentationObject
VOCdevkit/VOC2012
├── Annotations
├── ImageSets
├── JPEGImages
├── SegmentationClass
└── SegmentationObject
#以VOC2007为例,第三级
## Annotations
VOCdevkit/VOC2007/Annotations/
├── 000001.xml
├── 000002.xml
├── 000003.xml
├── 000004.xml
├── 000005.xml
├── 000006.xml
├── 000007.xml
├── 000008.xml
├── 000009.xml
├── 000010.xml
...
## JPEGImages
VOCdevkit/VOC2007/JPEGImages/
├── 000001.jpg
├── 000002.jpg
├── 000003.jpg
├── 000004.jpg
├── 000005.jpg
├── 000006.jpg
├── 000007.jpg
├── 000008.jpg
├── 000009.jpg
├── 000010.jpg
├── 000011.jpg
├── 000012.jpg
├── 000013.jpg
##ImageSets
VOCdevkit/VOC2007/ImageSets/
├── Layout
├── Main
└── Segmentation
#ImageSets第四级
VOCdevkit/VOC2007/ImageSets/
├── Layout
│ ├── test.txt
│ ├── train.txt
│ ├── trainval.txt
│ └── val.txt
├── Main
│ ├── aeroplane_test.txt
│ ├── aeroplane_train.txt
│ ├── aeroplane_trainval.txt
│ ├── aeroplane_val.txt
│ ├── bicycle_test.txt
│ ├── bicycle_train.txt
│ ├── bicycle_trainval.txt
│ ├── bicycle_val.txt
│ ├── bird_test.txt
│ ├── bird_train.txt
│ ├── bird_trainval.txt
│ ├── bird_val.txt
│ ├── boat_test.txt
│ ├── boat_train.txt
│ ├── boat_trainval.txt
│ ├── boat_val.txt
│ ├── bottle_test.txt
│ ├── bottle_train.txt
│ ├── bottle_trainval.txt
│ ├── bottle_val.txt
│ ├── bus_test.txt
│ ├── bus_train.txt
│ ├── bus_trainval.txt
│ ├── bus_val.txt
│ ├── car_test.txt
│ ├── car_train.txt
│ ├── car_trainval.txt
│ ├── car_val.txt
│ ├── cat_test.txt
│ ├── cat_train.txt
│ ├── cat_trainval.txt
│ ├── cat_val.txt
│ ├── chair_test.txt
│ ├── chair_train.txt
│ ├── chair_trainval.txt
│ ├── chair_val.txt
│ ├── cow_test.txt
│ ├── cow_train.txt
│ ├── cow_trainval.txt
│ ├── cow_val.txt
│ ├── diningtable_test.txt
│ ├── diningtable_train.txt
│ ├── diningtable_trainval.tx
│ ├── diningtable_val.txt
│ ├── dog_test.txt
│ ├── dog_train.txt
│ ├── dog_trainval.txt
│ ├── dog_val.txt
│ ├── horse_test.txt
│ ├── horse_train.txt
│ ├── horse_trainval.txt
│ ├── horse_val.txt
│ ├── motorbike_test.txt
│ ├── motorbike_train.txt
│ ├── motorbike_trainval.txt
│ ├── motorbike_val.txt
│ ├── person_test.txt
│ ├── person_train.txt
│ ├── person_trainval.txt
│ ├── person_val.txt
│ ├── pottedplant_test.txt
│ ├── pottedplant_train.txt
│ ├── pottedplant_trainval.tx
│ ├── pottedplant_val.txt
│ ├── sheep_test.txt
│ ├── sheep_train.txt
│ ├── sheep_trainval.txt
│ ├── sheep_val.txt
│ ├── sofa_test.txt
│ ├── sofa_train.txt
│ ├── sofa_trainval.txt
│ ├── sofa_val.txt
│ ├── test.txt
│ ├── train_test.txt
│ ├── train_train.txt
│ ├── train_trainval.txt
│ ├── train.txt
│ ├── train_val.txt
│ ├── trainval.txt
│ ├── tvmonitor_test.txt
│ ├── tvmonitor_train.txt
│ ├── tvmonitor_trainval.txt
│ ├── tvmonitor_val.txt
│ └── val.txt
└── Segmentation
├── test.txt
├── train.txt
├── trainval.txt
└── val.txt
可以看到文件结构是相同的。
目标检测只用到Annotations、ImageSets和JPEGImages,而ImageSets下只用Main
对于2007,Main下各个txt文件的说明为:
*_train.txt是各个分类的训练图片,来自2007 trainval数据集
*_val.txt是各个分类的验证图片,来自2007 trainval数据集
*_trainval.txt 是各个分类的训练和验证图片,来自2007 trainval数据集
*_test.txt是各个分类的测试图片,来自2007 test数据集
#因为有20个分类,所以上述文件共20*4=80个,还有另外四个文件
train.txt
val.txt
trainval.txt
test.txt
以上各个分类的文件与总文件行数是完全对应的,不同的是各个分类在图片名后会有1或-1来表示该图片是正样本还是负样本,以car这个分类为例:

可以看到文件名一样,行数也一样。同理,对于val.txt,trainval.txt,test.txt都是相同的。
我们再看一下数量:

可以看到,数据上的一致性。另外注意,有四个文件是train_train.txt,train_val.txt,train_trainval.txt,train_test.txt,这个是火车分类,不要误理解为训练文件。
以上,我们就可以对pascal voc的结构有一个整体的认识。
4.2 自定义数据集整理为Pascal VOC格式
因为目标检测只用到Annotations、ImageSets和JPEGImages,而ImageSets下只用Main,所以我们可以照着创建一个这样的格式。如下:
VOCdevkit/VOC2021 #不同的数据集可以用不同的年份名称来命名,自己的数据集这个可以自定义
├── Annotations #存放所有*.xml的标注文件
├── ImageSets #其下边只有Main这一个文件夹
│ └── Main #用来存放train.txt,val.txt(训练中只有train.txt和val.txt,如果要测试还会有test.txt
└── JPGImages #用来存放所有图片
我们可以执行如下命令来实现这个功能:
mv *.jpg VOCdevkit/VOC2021/JPEGImages
mv *.xml VOCdevkit/VOC2021/Annotations
要强调的一点是每一张图片并不是都会有对应的标注文件,对于一个要标注目都没有的图片是不会进行标注,也就不会有标注文件;也就是说xml文件数量会小于等于jpg的图片文件,对于没有标记文件的图片会被当做背景来处理,下文中也会有说明具体的处理方法。
将图片和标注文件放入对应的文件后的,还需要对ImageSets/Main下的train.txt和val.txt进行生成,使用如下代码:
#create_train_val.txt 该脚本放到与VOCdevkit同级位置
import os
years=[('2021',1.0)] #指定训练集百分比0~1,其余是验证
#years=[('2021',1.0),('2022',0.8)] #多次收集形成多个文件夹时,也可以同时处理
wd = os.getcwd()
for year,percent in years:
img_files = os.listdir('%s/VOCdevkit/VOC%s/JPEGImages' %(wd,year))
split = int(len(img_files) * percent)
train_img_files,val_img_files = img_files[:split],img_files[split:]
with open('%s/VOCdevkit/VOC%s/ImageSets/Main/train.txt' %(wd,year),'w') as f1:
for img_file in train_img_files:
f1.write(img_file.split('.')[0]+'\n')
print('train.txt done')
with open('%s/VOCdevkit/VOC%s/ImageSets/Main/val.txt' %(wd,year),'w') as f2:
for img_file in val_img_files:
f2.write(img_file.split('.')[0]+'\n')
print('val.txt done')
到此,其本上完成数据的整理工作。
4.3 Pascal VOC 格式转YOLO
这个转换过程主要是对于标签格式的转换,本文3.2节已经对YOLO的标签格式进行过介绍。转换代码如下:
#voc_label.py 这个文件yolov4官方文档中有,与VOCdevkit同级,但略有不同,具体如下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = [('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'),
('2021', 'train'), ('2021', 'val')] #有train,val,test的选择主要依赖与ImageSets/Main下有那些文件夹
classes = ["aeroplane","bicycle","bird","boat","bottle","bus","car","cat","chair","cow", \
"diningtable","dog","horse","motorbike","person","pottedplant","sheep","sofa","train","tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
try:
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
# print image_id
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
except:
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
out_file.close()
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
#以上部分会生成对应的 年份_train.txt,年份_val.txt多个文件,我们做算法开法,通常有训练和验证就可以了
strs_train = 'cat '+ ' '.join([a+'_'+b+'.txt' for a,b in sets if b=='train']) +'> train.txt'
strs_val = 'cat '+ ' '.join([a+'_'+b+'.txt' for a,b in sets if b=='val']) +'> val.txt'
os.system(strs_train)
os.system(strs_val)
print("all Done!")
#以上部分为了后期训练做准备生成了train.txt和val.txt,要注意的是每次有更新的文件夹后,不只要处理新的文件夹,要全部处理,因为要生成train.txt时是按照年份的。
以上代码可以可以将多个年份文件夹整合成一份train.txt和val.txt,也就是说可以将多次收集的不同文件汇合到一起来做训练,适合多次收集的数据。