2019川大新生数据可视化(python wordcloud + echarts)
8月底和同学一起为川大新生制作了一个新生数据可视化的推送。这篇推送中插入的图片,主要使用了python的wordcloud制作词云,用echarts中的一些图表。这篇博客主要会记录一下我制作的部分。
目录
-
- 一、wordcloud制作姓名词云
-
- 1.Anaconda下安装wordcloud模块
- 2.导入模块
- 3. 处理数据
-
- 1) 处理名字
- 2)处理姓氏
- 4.生成词云
- 二、用Python处理数据
-
-
- 1) 处理日期
- 2)其他数据转换成json数组
-
- 三、echarts制作其他图表
-
- 1.矩形树图(Treemap)制作专业人数分布图
- 2.桑基图(Sankey)制作年龄流动图
- 3.柱状图制作男女比例图
- 四、设计与配色
- 五、总结
一、wordcloud制作姓名词云
1.Anaconda下安装wordcloud模块
如果没有安装wordcloud,可以在官网下载whl文件。下载好文件后,使用Anconda命令行,切到whl所在的文件目录,输入命令行:pip install wordcloud-1.5.0-cp36-cp36m-win_amd64.whl,然后安装成功后就可导入该模块了。

2.导入模块
要制作词云,主要需导入wordcloud,matplotlib这两个模块。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#导入wordcloud模块和matplotlib模块
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS
import matplotlib.pyplot as plt
from scipy.misc import imread
import chardet
3. 处理数据
由于当时得到的excel表格中,学生包括新疆、西藏等民族,姓名不是普通的姓+名的结构,给姓名的处理带来了一定困难。因此没有统计他们的姓氏。当时不了解python也可以处理excel,于是是将姓名按行存入一个txt文件,再通过python进行处理。
1) 处理名字
#读取原始的姓名txt文件
fileObj = open('name4.txt','r',encoding='UTF-8-sig')
ming=[]
#按行读取,姓名是三个字的同学的姓删除
line=fileObj.readline()
while line:
line=line.strip('\n')
if (len(line)<=4 and len(line)>0):
line=line.replace(line[0],"")
ming.append(line)
line=fileObj.readline()
m="".join(ming)
print(ming)
fileObj2 = open('ming.txt', 'w', encoding='utf-8')
fileObj2.write(m)
fileObj2.close()
# 姓名全部以单字形式排列,并存入新的文档
name=open('ming.txt','r',encoding='UTF-8').read()
name=name.replace('·','')
name=name.replace('\n','')
result=[]
for i in name:
result.append(i)
result.append(" ")
s = "".join(result) #列表转字符串
save = open('name7.txt', 'w', encoding='utf-8')
save.write(s)
save.close()
得到处理的结果:

2)处理姓氏
# 姓
fileObj = open('name4.txt','r',encoding='UTF-8-sig')
surname=[]
line=fileObj.readline()
while line:
line=line.strip('\n')
if (len(line)<=4 and len(line)>0):
surname.append(line[0])
surname.append(" ")
line=fileObj.readline()
sur="".join(surname)
print(surname)
fileObj2 = open('surname.txt', 'w', encoding='utf-8')
fileObj2.write(sur)
fileObj2.close()
得到处理的结果:

4.生成词云
处理完名和姓的结果后,就可以使用wordcloud函数来绘制词云。当时遇到了一个问题就是词云只能生成两个字及以上的词云,对于单个字会认为这不是一个词。解决办法是修改参数中的regexp(正则表达式)有regexp=r"\w[\w']*",这样wordcloud就会将单字也认为是词,从而生成字云。
除此之外还使用到了以下几个参数:
mask:设置为pic是为了让生成的词云具有图片的形状。#FFFFFF是不会显示字的,因此如果画面背景不是纯白也会显示字。
prefer_horizontal: 这个属性是让竖直的字的出现概率为1,因此词云的所有字都是竖直排列的,可读性会更强。
background_color=None和mode=‘RGBA’ :这两个一起设置,能够让图片的背景是透明的。(这里主要是需要和美工交接,让她帮忙上一个底色)
stopwords:停止词,因为处理数据是先生成了姓,因此当时考虑将姓作为停止词(也就是不会出现在词云上),但鉴于有些姓同样会出现在名字中,会影响准确性,因此并没有这样做。
#读入处理过的姓名文件
text2= open('name7.txt','r',encoding='UTF-8').read()
#读入背景图片
pic = imread('panda16.png')
#生成词云
cloud = WordCloud(mask=pic,prefer_horizontal=1,#width=800,height=800,
font_path='C:\\Windows\\Fonts\\Nk728iWCZ.TTF',
background_color=None,scale=5,regexp=r"\w[\w']*",
max_font_size = 100,mode='RGBA') #,stopwords=stop)
cloud.generate(text2)
image_colors = ImageColorGenerator(pic)
cloud.recolor(color_func=image_colors)
#显示词云图片
plt.imshow(cloud)
plt.axis('off')
plt.show()
#保存图片
cloud.to_file('test26.png')
最后生成的词云如下:
二、用Python处理数据
除了用python处理词云之外,python还用于处理一些数据,比如将数据从excel格式调成json格式(便于echarts使用)。当然,当时我python处理excel文件还不太熟,因此整个处理数据(包括年龄、星座等制作后面的表格时使用到的数据)的步骤可以归纳为以下的几点:
1.在excel中用数据透视表进行统计,然后将得到的结果以txt文本保存。
2.在notepad进行简单的查找替换,将文件编码设置为utf-8。
3.转化为json数组时通过python读取txt文件,然后对其进行相应的处理,得到符合要求的json数组。
(当然后续知道可以直接在excel中转json,不过写数据处理的代码也算是让我更熟悉了python)
这里放部分的代码:
1) 处理日期
因为生日的日期有多种格式(斜杠、全数值、横杠),为了让他们格式相同,所以进行了处理。
while line:
if(line.find('/')>=0):
print(line)
line=line.replace('/','-')
fileObj2.write(line)
elif(line.find('-')<0):
line_list=[]
line_list=list(line)
line_list.insert(4,'-')
print(line_list)
line_list.insert(7,'-')
print(line_list)
newline="".join(line_list)
print(newline)
fileObj2.write(newline)
else:
fileObj2.write(line)
line=fileObj.readline()
fileObj2.close()
2)其他数据转换成json数组
这是用来生成桑基图中的links中的数组。
while line:
index=line.find('\n')
blank=line.find(' ')
line_list = list(line)
line_list.insert(index+1,"},")
line_list.insert(0,"{ 'name':'")
line_list.insert(blank+2,"',\n")
line_list.insert(blank+3,"value:")
print(line_list)
#转回字符串
newline=''.join(line_list)
print(newline)
fileObj2.write(newline)
line=fileObj.readline()
fileObj2.close()
三、echarts制作其他图表
1.矩形树图(Treemap)制作专业人数分布图
在这张图中,主要通过矩形的大小来映射专业的人数多少。图片的尺寸考虑到看推送的清晰度问题,因此设置得较长。

在做的时候,遇到的问题主要是字体不能够换行以及调整字体大小的问题。
解决办法是用:series->upperLable->normal加入formatter: '{b}',,然后通过data中的name进行换行处理(由于矩形树图的特殊性,为了让排版更好看,手动对每一个需要换行的name进行了换行)。
series->levels中的两个元素分别表示的是学院层和学院下的专业层的不同设置。
var myChart = echarts.init(document.getElementById('treemap'));
option = {
series: [{
type: 'treemap',
data: [
{
name: '材料科学与工程学院',
value: xxx,
children: [{
name: '材料类',
value: xx,
}, {
name: '生物医学工程',
value: xx
}]
//每一个学院下的专业
},
],
upperLabel:{
normal:{
ellipsis:false,
color: '#555',
show:true,
fontSize:10,
fontWeight:'bold',
formatter: '{b}',
backgroundColor:'#e6eae3'
}
},
levels:[
{
color:['#5bbdc8','#83ccd2','#7ebea5','#ffefa1'],
itemStyle: {
normal: {
borderColor:'#e6eae3',
borderWidth: 6,
gapWidth: 5
}
}
},
{
itemStyle: {
normal: {
borderColor:'#e6eae3',
borderWidth: 4,
gapWidth: 1
}
}
},
],
label:{
position:'insideLeft',
ellipsis:false,
color: '#555',
fontWeight:'bold',
fontSize:13,
formatter:'{b}',
}
}]
};
myChart.setOption(option);
2.桑基图(Sankey)制作年龄流动图
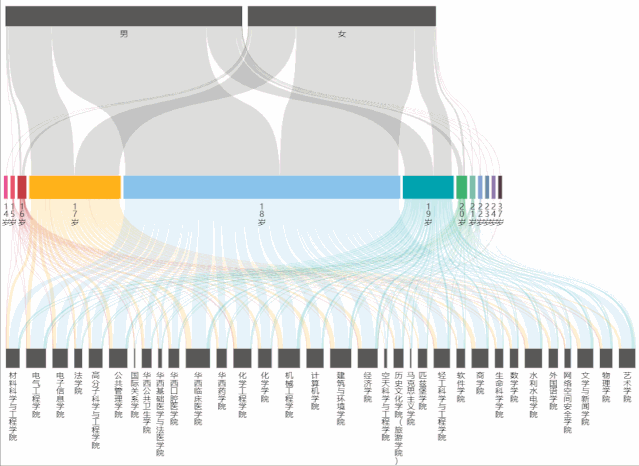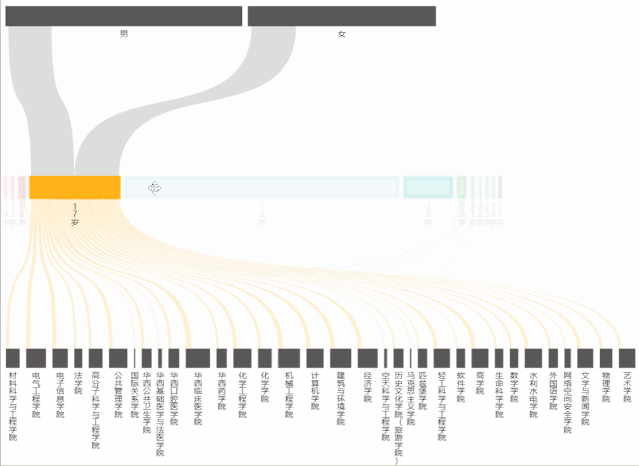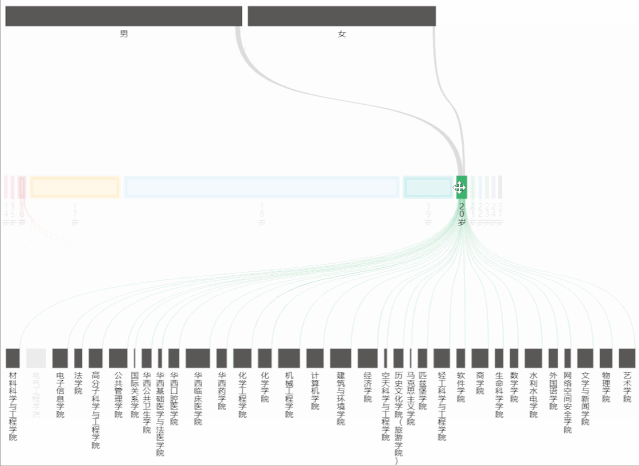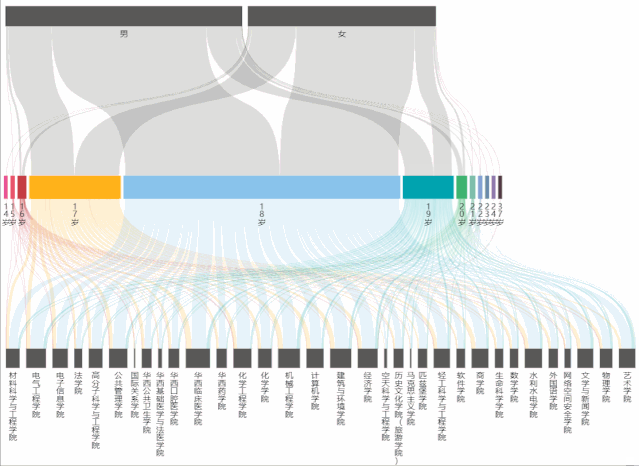
从桑基图中,能够看到不同年龄占男女生总人数的比例,以及占学院总人数的比例。
在制作桑基图时,主要遇到的问题是:年龄最小/大的人数过少,表现在echarts的图表中就会发现根本无法选中和显示出来,为了解决这个问题,将series->data->itemStyle->borderWidth中的数值改大(即增大边框宽度),这样就能够正常显示和交互了。
option = {
series: {
type: 'sankey',
layout: 'none',
layoutIterations: 0,
nodeWidth: 30,
nodeGap: 10,
height: 300,
focusNodeAdjacency: 'allEdges',
orient: 'vertical',
label: {
show: true,
position: 'bottom',
//[-10,60],
formatter: function(val) {
//x轴的文字改为竖版显示
var str = val.name.split("");
return str.join("\n");
},
},
data: [{
name: '14岁',
itemStyle: {
color: '#e95295',
borderWidth: 6,
borderColor: '#e95295',
opacity: 1,
},
},
//其余每一个年龄除了color的设置之外,其他都是相同的
{
name: '材料科学与工程学院',
itemStyle: {
color: '#595857',
borderWidth: 0,
},
},
//其他所有学院的格式都如上所示
{
name: '男',
itemStyle: {
color: '#595857',
},
},
{
name: '女',
itemStyle: {
color: '#595857',
},
}],
links: [{
source: '男',
target: '15岁',
value: 7,
},
/*...
男和女两种性别和到每一个年龄的所有link
此处不公开数据*/
{
source: '15岁',
target: '材料科学与工程学院',
value: 1
},
/*...
每一个年龄流动到每一个学院的所有link
此处不公开数据*/
],
lineStyle: {
normal: {
color: 'source',
curveness: 0.75
}
}
},
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
3.柱状图制作男女比例图

柱状图制作的比较顺利。右侧的数值可以通过设置两个y轴来解决。另外,圆角的柱状图可以在series->itemStyle->barBorderRadius中设置圆角的半径。
var myChart = echarts.init(document.getElementById('gendermap'));
option = {
backgroundColor: '#fff',
tooltip: {
trigger: 'axis',
axisPointer: {// 坐标轴指示器,坐标轴触发有效
type: 'shadow'
// 默认为直线,可选为:'line'或'shadow'
}
},
legend: {
data: ['男生', '女生'],
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
yAxis: [
{
type: 'category',
data: ['外国语学院',
'文学与新闻学院',
...],
/*这里存储的是图中左侧显示的每一个学院
为了减少篇幅就不写完了*/
splitLine: {
show: true,
ineStyle:{type:'dashed'}
},
axisLine: {
lineStyle: {
color: '#000',
}
},
axisLabel: {
color: '#000',
fontSize:15
}
},
{
type: 'category',
data: ['0.24:1',...],
/*这里存储的是图中右边显示的所有的比例(用字符串存储)
为了减少篇幅就不写完了*/
text:'男女比',
splitLine: {
show: false
},
axisLine: {
lineStyle: {
color: '#000',
}
},
axisLabel: {
color: '#000',
fontSize:15
}
}
],
xAxis: [
{
show: false,
type: 'value',
}
],
series : [
{
name:'女生',
type:'bar',
stack: '总量',
data:[],
/*这里的data包括每一个学院的女生的数量
此处就不公开该数据了*/
itemStyle: {
barBorderRadius: 20,
//设置柱形的圆角,可以设置该半径
color: new echarts.graphic.LinearGradient(0, 0, 0, 1, [{
offset: 0.4,
color: "#ffefa1"
},
])
},
},
{
name:'男生',
type:'bar',
stack: '总量',
data:[],
/*这里的data包括每一个学院的男生的数量
需要将数量取成负数
这样能够让男女数量分布在坐标轴的两边(中轴对齐)*/
itemStyle: {
barBorderRadius: 20,
color: new echarts.graphic.LinearGradient(0, 0, 0, 1, [{
offset: 0.4,
color: "#5bbdc8"
},
])
},
}
]
};
if (option && typeof option === "object") {
myChart.setOption(option, true);
}
四、设计与配色
使用了echarts和python,可视化看上去的确没有什么难度,但如果说要做出来能够放在推送上的视觉美观的作品,就不得不考虑设计和配色了。
首先是两个姓氏和名字的词云,大川的美工小姐姐基于原图,帮我们画了底色,让整个图案变得更鲜明。
其次,最初我们制作的图表的风格不统一,配色也非常混乱。在讨论后我们选择用了蓝色和黄色作为两种主色调。在这个基础上做好的图都要重新换一身衣服。当看到统一的配色的时候,风格自然地就融入在一起了。
关于配色当时我们参考了一些网站,包括 配色方案,还有其他的一些网上常见的有RGB值的色卡,最后定下来颜色。
五、总结
这个可视化推送我们断断续续做了一周左右。因为我python其实不算熟,做词云、数据处理的时候是边学边做,绕了不少弯路,配色那里也是反复修改,每张图都是十几稿,词云生成了差不多三十张(笑哭)。不过总算也将一个相对成熟的可视化作品完成了,3万点击量和很多令人感动的留言真的是让人成就感满满呐。
还有一点我很惊讶,我司空见惯,甚至觉得有点难看的echarts,在不是计算机专业的美工看来非常稀奇,希望更多不是计算机的人也能使用这些可视化工具,如果这篇文章能有些帮助的话,那就太好了。