Python爬虫—【最强兵王】音频爬取
单位的同事喜欢听电子书,抽空写了个脚本,爬取了所有的电子书音频,这样听书比较方便。
电子书网址:最强兵王 福海版
通过 F12 开发者工具,可以清晰地看到网页的结构,先查看 title 所在的位置:

接下来查找音频 audio 所在的位置:

学习 Python 爬虫,常用的库需要了解一下,如requests,BeautifulSoup,selenium等,用起来很方便。
使用这些库,我们很容易就获得 audio 对应的 title 和 src:
base_url = "https://www.ting22.com/ting/659-2.html"
browser = webdriver.Chrome()
browser.get(base_url)
soup = BeautifulSoup(browser.page_source, 'html.parser')
audio_name = soup.find(name='div', attrs={'class': 'title'}).h1.string
audio_url = soup.find(name='source', attrs={'id': 'mySource'}).get('src')
print(audio_name + " + " + audio_url)以下是程序运行结果:

获取到 audio 的 title 和 src,接下来就是保存文件:
audio_dir = "D:/AudioBook/Test/"
try:
urllib.request.urlretrieve(audio_url, audio_dir + audio_name + ".mp3")
except Exception as e:
print(e)
print("Get Audio " + audio_name + " Failed!")
else:
print("Get Audio " + audio_name + "Success!")看运行结果
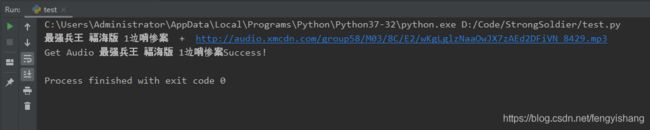
最后,音频已经保存在本地。

整个流程就清晰了,然后爬取全部的音频,考虑放在一个 for 循环中。
大批量的爬取,网站会有一些反爬虫的限制,所以浏览器 header 标识需要随时切换,对于捕获的一些异常要能够处理。
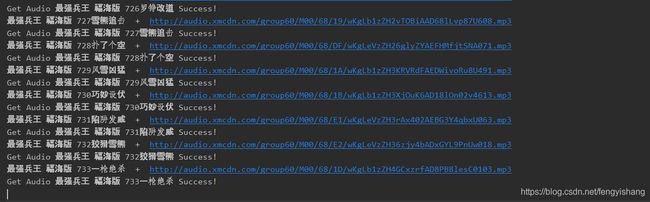
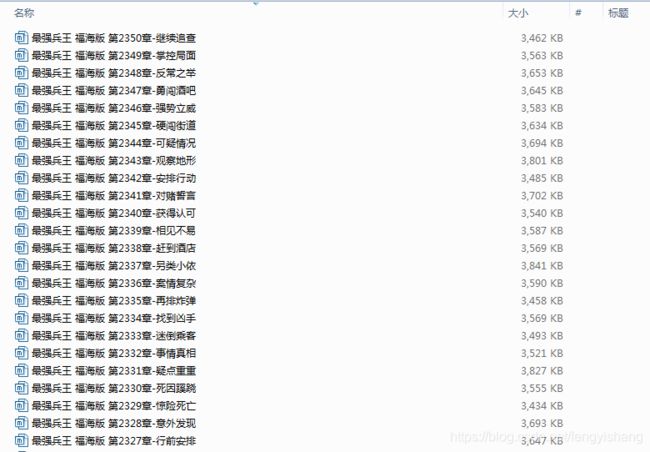
以下是源码,供大家参考。
import time
import socket
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from fake_useragent import UserAgent
def download_audio(audio_name, audio_url):
socket.setdefaulttimeout(60)
try:
audio_dir = "D:/AudioBook/StrongSoldier/"
user_agent = UserAgent(verify_ssl=False)
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', user_agent.random)]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(audio_url, audio_dir + audio_name + ".mp3")
except socket.timeout:
print("Download " + audio_name + " Time Out...")
download_audio(audio_name, audio_url)
except urllib.error.ContentTooShortError:
print("Download " + audio_name + " Failed,Reloading...")
download_audio(audio_name, audio_url)
else:
print("Get Audio " + audio_name + " Success!")
time.sleep(2)
def main():
base_url = "https://www.ting22.com/ting/659-"
option = webdriver.ChromeOptions()
option.add_argument('headless')
page_start = 1
page_end = 1775
for num in range(page_start, page_end):
page_num = str(num)
webpage = base_url + page_num + ".html"
browser = webdriver.Chrome(options=option)
browser.get(webpage)
time.sleep(1)
soup = BeautifulSoup(browser.page_source, 'html.parser')
audio_name = soup.find(name='div', attrs={'class': 'title'}).h1.string
audio_url = soup.find(name='source', attrs={'id': 'mySource'}).get('src')
print(audio_name + " + " + audio_url)
download_audio(audio_name, audio_url)
browser.quit()
if __name__ == "__main__":
main()