论文笔记:RelationPrompt :Zero-Shot Relation Triplet Extraction

论文来源: ACL Findings 2022
论文链接:https://arxiv.org/pdf/2203.09101.pdf
论文代码:http://github.com/declare-lab/RelationPrompt
本篇论文是由阿里达摩院自然语言智能实验室于2022年发表的关于零样本关系抽取的顶会论文,本篇博客将记录我在阅读过程中的一些笔记!
Abstract
关系抽取在知识构建和知识表示方面具有重要意义,但是将其推广到不可见的关系类型方面的研究较少,本文引入零样本关系三元组抽取任务。即给定一个输入句子,每个提取的三元组包括头实体、关系和尾实体,其中关系标签在训练阶段是不存在的。针对此问题,本文通过提示语言模型生成结构化文本来合成关系样本。
具体而言,RelationPrompt方法是将语言模型的提示和结构化文本方法相结合,设计了一个结构化提示模板,用于在关系标签提示条件下生成该关系的样本。为了克服句子中存在多个三元组的情况,还设计了一种新的三元组搜索解码方法。
Introduction
关系抽取旨在预测非结构化文本中实体之间的关系,其应用包括知识图谱构建、问答等。
问题背景:现有方法通常需要大规模的标注样本数据集,标注成本高,并且关系标签固定,模型无法扩展到没有见过的关系类别。零样本关系分类任务不需要提取完整的关系三元组,而是根据根据给定的头、尾实体进行关系分类或根据头实体和关系预测尾实体。
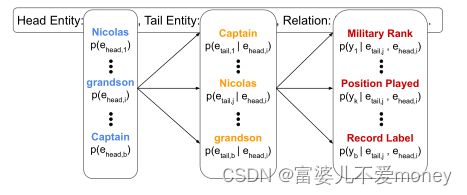
基于上述背景,本文提出一种新的具有挑战性的任务设置,零样本关系三元组抽取ZeroRTE,目标是从给定输入句子中抽取(头实体,尾实体,关系)三元组,其中,此关系标签在训练数据中从没有出现过。关系抽取相关的任务设置如下图所示。其中,ZeroRTE任务的输入是一个句子,输出是实体关系三元组。

贡献:
本文提出RelationPrompt,将零样本问题重新定义为合成数据生成,核心概念是利用关系标签的语义,提示语言模型生成能够表达所需关系的合成训练样本,然后可以使用合成数据训练另一个模型来执行零样本任务。
同时,提出一种名为三元组搜索解码的方法,在预测时间提取多个三元组,而不必对每个都包含单个三元组数据的合成样本进行训练,从而打破了一个句子包含多个不同关系三元组的局限。
Methodology
RelationPrompt框架需要两个模型:① 用于合成关系样本的关系生成器 Relation Generator;② 根据合成数据进行训练并用于预测未知关系的三元组的关系提取器 Relation Extractor。
ZeroRTE任务:目标是从训练集中学习,并推广测试集中,且两个数据集中的关系标签是不交叉的。RelationPrompt算法步骤如下:

Relation Generator
关系生成器![]() 如下图所示,以“Relation: y”形式的结构化提示作为输入,并以“Context: s. Head Entity:
如下图所示,以“Relation: y”形式的结构化提示作为输入,并以“Context: s. Head Entity: ![]() , tail Entity:
, tail Entity: ![]() ”的形式结构化输出。
”的形式结构化输出。

如下图所示,![]() 是通过语言模型的next-word prediction进行训练的。通过对特殊术语“上下文:”、“头实体:”和“尾实体:”进行拆分,输出序列被解码为关系三元组。如果解码错误,在生成的上下文中找不到实体,我们将丢弃该样本并继续生成,直到达到固定数量的有效样本。
是通过语言模型的next-word prediction进行训练的。通过对特殊术语“上下文:”、“头实体:”和“尾实体:”进行拆分,输出序列被解码为关系三元组。如果解码错误,在生成的上下文中找不到实体,我们将丢弃该样本并继续生成,直到达到固定数量的有效样本。

Relation Extractor
关系提取器![]() 如下图所示 ,将包含“Context:s”形式的句子作为结构化提示输入,然后生成一个"Head Entity:
如下图所示 ,将包含“Context:s”形式的句子作为结构化提示输入,然后生成一个"Head Entity: ![]() , Tail Entity:
, Tail Entity: ![]() , Relation: y" 结构化输出序列。
, Relation: y" 结构化输出序列。

如下图所示,本文使用标准的sequence-to-sequence进行训练和解码,为了预测给定句子中的单个关系三元组,我们可以在没有任何初始解码器输入的情况下生成模型输出。

另外,通过提供的实体对信息作为初始解码器输入生成关系类别,对ZeroRC任务做预测,即以“Context:s,Head Entity:![]() ,Tail Entity:
,Tail Entity:![]() ,Relation:”作为解码器输入,生成“y”作为输出。因此,本文所提方法支持ZeroRTE和ZeroRC任务,因为这种变化影响模型预测而不是训练。
,Relation:”作为解码器输入,生成“y”作为输出。因此,本文所提方法支持ZeroRTE和ZeroRC任务,因为这种变化影响模型预测而不是训练。
Extracting Multiple triplets using Triplet Search Decoding
核心概念是通过分别考虑头、尾实体和关系标签的多个候选,在生成过程中枚举多个输出序列。如下图所示,每个可能路径代表了一个候选三元组,通过分数阈值筛选出最合适的候选三元组,当总体概率高于设置的阈值时被预测为最终的关系三元组。

Experiments
零样本关系三元组抽取任务实验
由于ZeroRTE是一个新的任务,本文提供了两种基线方法用于与RelationPrompt进行比较,首先本文的关系提取器可以在不微调合成样本的情况下执行ZeroRTE,因此被训练为在可见关系集的句子上提取三元组,但是,由于训练数据和测试数据之间领域不相关,无法实现最佳性能,基线NoGen:在不使用生成的合成数据的情况下抽取陌生关系类别的三元组,基线TableSequence 是一种传统的关系三元组抽取模型。

如上图所示,m是测试集中关系类别的数量,RelationPrompt方法在 FewRel和Wiki-ZSL数据集的总体结果均高于基线模型。没有用生成的样本进行训练的抽取模型(NoGen)性能比较低,表明使用关系生成器中的合成样本对于零样本泛化至关重要。TableSequence需要假设在训练数据中存在具有多个关系三元组的句子,才能在测试句子上抽取多个关系三元组。然而,我们生成的数据仅限于每一个句子只包含一个关系三元组。因此,TableSequence 对于多三元组 ZeroRTE 不能很好地执行
零样本关系分类任务实验
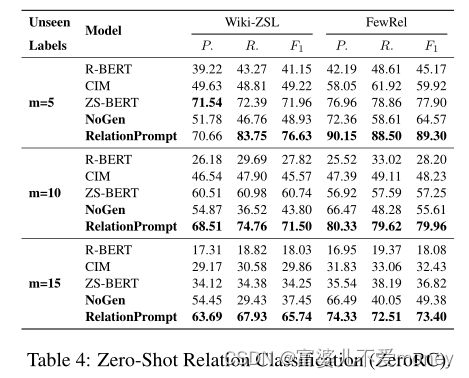
当未知标签m增大时,ZS-BERT的性能下降幅度更大,表明RelationPrompt能够更好的扩展到更大的未知标签集。
积累
① To overcome the limitation for ... , we design a novel ..., method. Experiments on FewRel and Wiki-ZSL datasets show the efficacy of (our model) for XXX task.
为了克服。。。的局限性,我们设计了一种新颖的。。。方法。在FewRel和Wiki-ZSL数据集上的实验表明,我们的模型对XXX任务的有效性。
② To our knowledge, this is the first work to extend the task of Relation Triplet Extraction to the zero-shot setting.
据我们所知,这是第一项将关系三元组抽取任务扩展到零样本设置的工作。