吴恩达深度神经网络笔记—搭建卷积神经网络模型(TensorFlow)
利用框架搭建卷积神经网络模型
导包
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
import tensorflow as tf
from tensorflow.python.framework import ops
from cnn_utils import *
%matplotlib inline
np.random.seed(1)
加载数据集
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
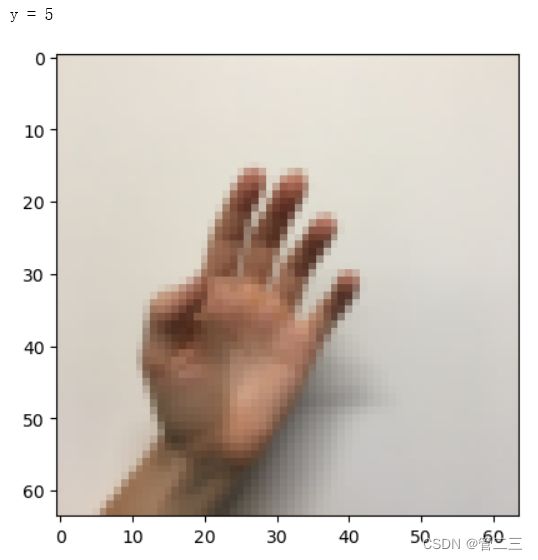
数据集是6个符号的集合,表示从0到5的数字。

查看数据集中一条数据
index = 15
plt.imshow(X_train_orig[index])
print ("y = " + str(np.squeeze(Y_train_orig[:, index])))
结果:
数据集处理
X_train = X_train_orig/255.
X_test = X_test_orig/255.
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
conv_layers = {}
结果:
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
创建占位符
def create_placeholders(n_H0, n_W0, n_C0, n_y):
X = tf.compat.v1.placeholder(tf.float32,[None, n_H0, n_W0, n_C0])
Y = tf.compat.v1.placeholder(tf.float32,[None, n_y])
return X, Y
为什么要使用tf.placeholder?
因为每一个tensor在graph上都是一个op。当我们将train数据分成一个个minibatch然后传入网络进行训练时,每一个minibatch都将是一个op,这样的话,一副graph上的op未免太多,也会产生巨大的开销;于是就有了tf.placeholder,我们每次可以将 一个minibatch传入到x = tf.placeholder(tf.float32,[None,32])上,下一次传入的x都替换掉上一次传入的x,这样就对于所有传入的minibatch x就只会产生一个op,不会产生其他多余的op,进而减少了graph的开销。
测试:
X, Y = create_placeholders(64, 64, 3, 6)
print ("X = " + str(X))
print ("Y = " + str(Y))
结果:
X = Tensor("Placeholder:0", shape=(None, 64, 64, 3), dtype=float32)
Y = Tensor("Placeholder_1:0", shape=(None, 6), dtype=float32)
初始化参数
def initialize_parameters():
tf.compat.v1.set_random_seed(1)
W1 = tf.compat.v1.get_variable("W1",[4, 4, 3, 8],initializer = tf.keras.initializers.glorot_normal(seed = 0))
W2 = tf.compat.v1.get_variable("W2",[2, 2, 8, 16],initializer = tf.keras.initializers.glorot_normal(seed = 0))
parameters = {"W1": W1,
"W2": W2}
return parameters
测试:
tf.compat.v1.reset_default_graph()
with tf.compat.v1.Session() as sess_test:
parameters = initialize_parameters()
init = tf.compat.v1.global_variables_initializer()
sess_test.run(init)
print("W1 = " + str(parameters["W1"].eval()[1,1,1]))
print("W2 = " + str(parameters["W2"].eval()[1,1,1]))
结果:
W1 = [ 0.03393849 -0.16554174 -0.006313 0.01852748 -0.03301779 -0.03344928
-0.14225453 0.13832784]
W2 = [ 0.18496291 -0.17294659 -0.22462192 -0.00193902 -0.12594481 0.02987488
-0.23320328 -0.23961914 0.14771584 0.09277791 0.01622899 0.24536026
-0.12588692 -0.32413897 -0.21403536 -0.17823085]
前向传播
tf.nn.conv2d(X,W1,strides=[1,s,s,1],padding=‘SAME’)
给定输入X和一组过滤器 W1,这个函数将会自动使用W1来对X进行卷积,第三个输入参数是**[1,s,s,1]**是指对于输入 (m, n_H_prev, n_W_prev, n_C_prev)而言,每次滑动的步伐。
tf.nn.max_pool(A, ksize = [1,f,f,1], strides = [1,s,s,1], padding = ‘SAME’)
给定输入X,该函数将会使用大小为(f,f)以及步伐为(s,s)的窗口对其进行滑动取最大值。
tf.nn.relu(Z1)
计算Z1的ReLU激活。
tf.contrib.layers.flatten(P)
给定一个输入P,此函数将会把每个样本转化成一维的向量,然后返回一个tensor变量,其维度为(batch_size,k)
tf.contrib.layers.fully_connected(F, num_outputs)
给定一个已经一维化了的输入F,此函数将会返回一个由全连接层计算过后的输出。使用该函数后全连接层会自动初始化权值且在你训练模型的时候它也会一直参与,所以当我们初始化参数的时候我们不需要专门去初始化它的权值。
def forward_propagation(X, parameters):
W1 = parameters['W1']
W2 = parameters['W2']
A1 = tf.nn.conv2d(X,W1,strides = [1,1,1,1], padding = 'SAME')
Z1 = tf.nn.relu(A1)
M1 = tf.nn.max_pool(Z1, ksize = [1,8,8,1], strides = [1,8,8,1], padding = 'SAME')
A2 = tf.nn.conv2d(M1,W2,strides = [1,1,1,1], padding = 'SAME')
Z2 = tf.nn.relu(A2)
M2 = tf.nn.max_pool(Z2, ksize = [1,4,4,1], strides = [1,4,4,1], padding = 'SAME')
F = tf.keras.layers.Flatten()(M2)
NET = tf.keras.layers.Dense(6)
Z3 = NET(F)
return Z3
测试:
tf.compat.v1.reset_default_graph()
with tf.compat.v1.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
init = tf.compat.v1.global_variables_initializer()
sess.run(init)
a = sess.run(Z3, {X: np.random.randn(2,64,64,3), Y: np.random.randn(2,6)})
print("Z3 = " + str(a))
结果:
Z3 = [[-0.28834903 -1.8021204 0.87139827 -0.85399485 2.0558307 2.991231 ]
[-0.4699881 -1.3789502 0.8473368 -1.0291927 1.9558324 2.790418 ]]
计算损失函数
tf.nn.softmax_cross_entropy_with_logits(logits = Z3 , lables = Y)
计算softmax的损失函数。这个函数既计算softmax的激活,也计算其损失.
tf.reduce_mean
计算的是平均值,使用它来计算所有样本的损失来得到总成本。
def compute_cost(Z3, Y):
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels = Y))
return cost
测试:
tf.compat.v1.reset_default_graph()
with tf.compat.v1.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
init = tf.compat.v1.global_variables_initializer()
sess.run(init)
a = sess.run(cost, {X: np.random.randn(4,64,64,3), Y: np.random.randn(4,6)})
print("cost = " + str(a))
结果:
cost = -2.91034
完成模型
random_mini_batches()
返回的是一个mini-batches的列表。
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.009,
num_epochs = 100, minibatch_size = 64, print_cost = True):
ops.reset_default_graph()
tf.compat.v1.set_random_seed(1)
seed = 3
(m, n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = []
X, Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m / minibatch_size)
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch
_ , temp_cost = sess.run([optimizer,cost],feed_dict={X:minibatch_X, Y:minibatch_Y})
minibatch_cost += temp_cost / num_minibatches
if print_cost == True and epoch % 5 == 0:
print ("Cost after epoch %i: %f" % (epoch, minibatch_cost))
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
predict_op = tf.argmax(Z3, 1)
correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(accuracy)
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
print("Train Accuracy:", train_accuracy)
print("Test Accuracy:", test_accuracy)
return train_accuracy, test_accuracy, parameters
测试:
_, _, parameters = model(X_train, Y_train, X_test, Y_test)
结果:
Cost after epoch 0: 1.903382
Cost after epoch 5: 1.190022
Cost after epoch 10: 0.758482
Cost after epoch 15: 0.601357
Cost after epoch 20: 0.453344
Cost after epoch 25: 0.423432
Cost after epoch 30: 0.301320
Cost after epoch 35: 0.292329
Cost after epoch 40: 0.249041
Cost after epoch 45: 0.212705
Cost after epoch 50: 0.169256
Cost after epoch 55: 0.168881
Cost after epoch 60: 0.160701
Cost after epoch 65: 0.113217
Cost after epoch 70: 0.105539
Cost after epoch 75: 0.134959
Cost after epoch 80: 0.122584
Cost after epoch 85: 0.073460
Cost after epoch 90: 0.067096
Cost after epoch 95: 0.075297
