吴恩达深度学习C4W1(Pytorch)实现
问题描述
此次作业需要处理的任务在之前的任务中出现过:完成一个多分类器,识别图像中手势代表的数字:

与之前作业不同的是,需要在神经网络中加入卷积层(CONV)和池化层(POOL),神经网络的大致结构为:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLCONNECTED
import torch
import h5py
import numpy as np
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
1 - 数据预处理
读取数据并创建数据接口。
Hint:TensorDataset 可以用来对 tensor 进行打包,就好像 python 中的 zip 功能。该类通过每一个 tensor 的第一个维度进行索引。因此,该类中的 tensor 第一维度必须相等。
def load_dataset():
# 读取数据
train_dataset = h5py.File('datasets/train_signs.h5', 'r')
train_set_x_orig = torch.tensor(train_dataset['train_set_x'][:])
train_set_y_orig = torch.tensor(train_dataset['train_set_y'][:])
test_dataset = h5py.File('datasets/test_signs.h5', 'r')
test_set_x_orig = torch.tensor(test_dataset['test_set_x'][:])
test_set_y_orig = torch.tensor(test_dataset['test_set_y'][:])
# 数据归一化
train_set_x = train_set_x_orig.permute(0, 3, 1, 2) / 255
test_set_x = test_set_x_orig.permute(0, 3, 1, 2) / 255
return train_set_x, train_set_y_orig, test_set_x, test_set_y_orig
def data_loader(X, Y, batch_size=64):
# 创建数据接口
dataset = TensorDataset(X, Y)
return DataLoader(dataset, batch_size, shuffle=True)
train_x, train_y, test_x, test_y = load_dataset()
print(f'train_x.shape = {train_x.shape}')
print(f'train_y.shape = {train_y.shape}')
print(f'test_x.shape = {test_x.shape}')
print(f'test_y.shape = {test_y.shape}')
可以看到对应的数据形状。
注意:数据归一化时进行了维度变换,因为Conv2d的输入数据格式为 ( N , C i n , H i n , W i n ) (N, C_{in}, H_{in}, W_{in}) (N,Cin,Hin,Win)
2 - 模型封装
将整个神经网络封装成类CNN,包含两个卷积层和一个全连接层,卷积层的操作包括:卷积,非线性激活和最大池化。
前向传播函数forward中,依次计算各层的输出,需要注意的是第二层卷积层的输出送到全连接层之前需要进行维度变化,将单个样本转换成一维向量。
注意:前向传播时不需要经过softmax层,因为损失函数包含softmax的功能。
由于Pytorch的padding没有SAME模式,因此模型构建根据自己的设计进行更改,使用到的数学公式如下:
H o u t × W o u t = ⌊ H i n + 2 p − f 2 + 1 ⌋ × ⌊ W i n + 2 p − f 2 + 1 ⌋ H_{out} \times W_{out} = \left\lfloor\frac{H_{in}+2p-f}{2}+1\right\rfloor \times \left\lfloor\frac{W_{in}+2p-f}{2}+1\right\rfloor Hout×Wout=⌊2Hin+2p−f+1⌋×⌊2Win+2p−f+1⌋
具体的CNN网络框架如下图所示:
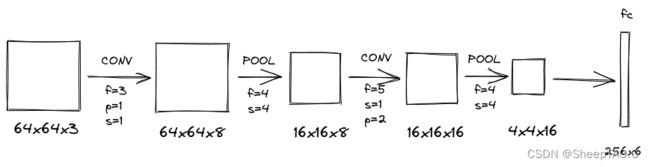
class CNN(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = nn.Sequential( # Layer 1, input: (3, 64, 64)
nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=4, stride=4, padding=0)
)
self.conv2 = nn.Sequential( # Layer 2
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=4, stride=4, padding=0)
)
self.fc = nn.Linear(16 * 4 * 4, 6)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# 展平
x = x.reshape(x.shape[0], -1)
x = self.fc(x)
return x
def predict(self, x):
output = self.forward(x)
pred = self.softmax(output)
return torch.max(pred, dim=1)[1]
3 - 构建训练模型
def model(train_x, train_y, lr = 0.0009, epochs = 100, batch_size = 64, pc = True):
cnn = CNN()
# 加载数据
train_loader = data_loader(train_x, train_y)
# 使用交叉熵损失函数,包含softmax
loss_fn = nn.CrossEntropyLoss()
# 使用Adam优化算法
optimizer = torch.optim.Adam(cnn.parameters(), lr=lr)
# 迭代更新
for e in range(epochs):
epoch_cost = 0
for step, (batch_x, batch_y) in enumerate(train_loader):
# 前向传播
y_pred = cnn.forward(batch_x)
# 损失函数
loss = loss_fn(y_pred, batch_y)
epoch_cost += loss
# 梯度归零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
epoch_cost /= step + 1
if e % 5 == 0:
writer.add_scalar(tag=f'CNN-lr={lr},epochs={epochs}', scalar_value=epoch_cost, global_step=e)
if pc:
print(f'epoch={e},loss={epoch_cost}')
# 评估准确度
y_pred = cnn.predict(train_x)
print(f'Train Accuracy: {torch.sum(y_pred == train_y) / y_pred.shape[0] * 100:.2f}%')
# 保存学习后的参数
torch.save(cnn.state_dict(), 'cnn_params.pkl')
print('参数已保存到本地pkl文件')
return cnn
cnn = model(train_x, train_y, epochs=200)
损失函数图像如下

对模型进行评估
train_pred = cnn.predict(train_x)
test_pred = cnn.predict(test_x)
print(f'Test Accuracy: {torch.sum(train_pred == train_y) / train_pred.shape[0] * 100:.2f}%')
print(f'Test Accuracy: {torch.sum(test_pred == test_y) / test_pred.shape[0] * 100:.2f}%')

参考:实现卷积神经网络:吴恩达Course 4-卷积神经网络-week1作业 pytorch版