数据分析与业务(业务数据分析和hive的相关知识点)
数据分析与业务(业务数据分析和hive)
第一部分:数据来源
1、数据来源:

2、埋点方式比较:

- 注意:可以结合使用
- 全埋点:可以分析用户的行为,在哪一块停留时间的长短;
- 代码埋点:统计分析。
3、业务数据(也叫下单数据)埋点(不走系统有漏点)
(1)自埋点
(2)借助第三方平台(友盟,艾瑞和站酷做移动端分析的,注册后可埋点)
(3)收费标准:周期和埋点数量;打电话发送接口,技术植入接口,也就是一串连接(7600-9800)
第二部分:数据分析方法论
一、数据分析流程
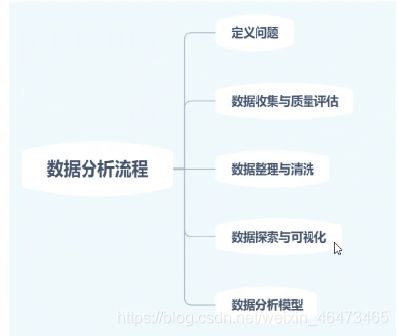

1、问题定位( 3W问题):
(1)What:确定核心指标(后续干嘛)
- 在excel中 :涉及统计,描述性统
- 三类人接触:
- 分析人员:搭档
- 需求:根据目的需求要干什么来确定
- 业务线:核心(跟他要求数据,与之搞好关系)
- 了解去干嘛,通过后续问题找出核心指标
- 比如:介绍人–>就业速度和就业薪资(考虑目的性是什么)
(2)Why:优化
- 下降问题:业务人员(别人找,别人着急)
- 日活
- 月活
- 收入
- 上升问题:自己走前面,主动去找,体现自己的价值
- 目的:监控指标
- 数据监控
- 数据大屏
- 下降问题怎么找:(会遇到偶然问题)
-
(1)查指标字典(指标算法是否一样)
-
(2)验证是否是正常波动范围(环比,同比):是正常问题就不用理会,不是正常问题就查找问题下降原因
数据分析最基础:对比分析——>与自己,与他人 -
(3)以上没问题之后再找数据下降原因
-
问题拆解(逻辑树+假设)——>按公式拆解
毛利润=销量*(价格-成本) 销量下降——>用户下降是否正常 价格下降——>价格 成本上升——>增加渠道
-
-
(3)How:机器学习
2、量化问题(可执行性)
- What:96%——>98%,提高了2%,这样制定方案的依据(为什么这样制定方案)
- 例子:
| 自习时间 | 就业率 |
|---|---|
| 6h | 99% |
| 4h | 96% |
| 2h | 94% |
可以预估增加自习时间,可以提高就业率大概2%,不能盲目拍脑袋决定
3、目标预估:实验(由点到面)
产品不同时期的追求不同
二、流量分析
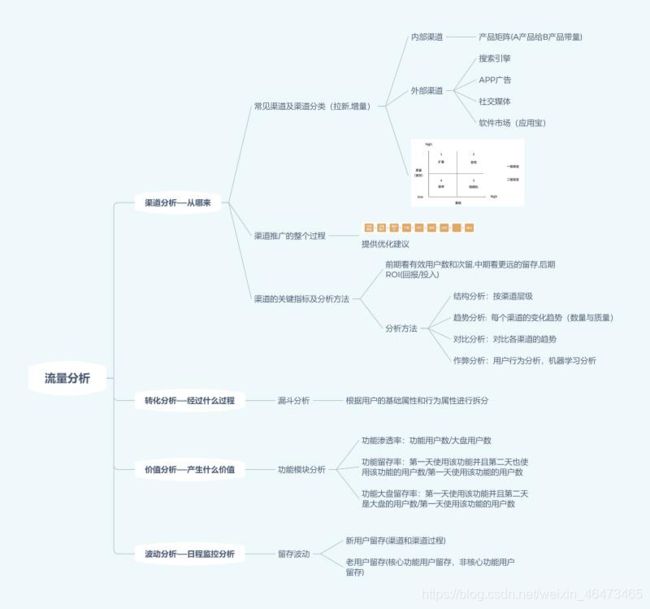
1、用户增长
- AARRR(3R是裂变/自传播)–>全新领域(可替代产品少的)最好使,只需要扩大知名度,有了替代品之后就不适用了

2、渠道分析
- 引流:优化自身,增加用户体验,减少用户流失
- 漏斗分析
- 跟上个月比,跟上上个月比,跟同行业比
- 渠道质量:找好的渠道,渠道多,数量多,流量多
- 用户质量:目标人群的转化率:注册
-
以平均值分隔,平均数不容易受极值点的影响
-
中位数也可以,不过中位数容易受极值点的影响
注意:要把指标带入指标字典才有对比性
-
3、电商的用户精细化营销(RFM)
- 目的:提高用户粘度,忠诚度
- 短期:DAU,MAU
- 长期:提高了多少用户
- RFM:线性关系的别放在一起
- 航空公司:找核心指标
- 某人经常往返两地——>留住就好
4、渠道推广过程

5、渠道的关键指标和分析方法
- 关键指标
- 前期:有效用户数和次日留存
- 中期;更长时间的留存
- 后期:ROI(回报/投入)
- 分析方法:
- 结构分析:按渠道层级
- 趋势分析:每个渠道的变化趋势(数量与质量)
- 对比分析:对比各渠道趋势
- 作弊分析:用户行为分析,机器学习分析
三、路径分析:最主要的是找到各功能模块的切入点
1、定义:
- 随着APP功能模块,坑位越来越多,用户行为越来越分散。
- 路径分析是基于用户所有行为,挖掘若干条重要的用户路径,通过优化界面交互让产品用起来体验更好,产生更多价值。
- 路径分析:先有数据再进行验证
- 漏斗分析:先有假设再数据验证
- 只有一条路径
- 路径多——>多个漏斗分析(要找好的路径,大工程,看用户日志)——>发现问题——>改进优化——>用户转化
- APP梳理埋点,确定路径(先有行为,后有路径)
2、各功能模块和坑位的渗透率

3、功能模块内的路径

第三部分:异动分析



第四部分:Hive进阶
1、Hive数据模型

2、Hive数据类型

3、Hive特殊分隔

(1) 创建数据表实例

(2) 创建数据表解释如下所示:
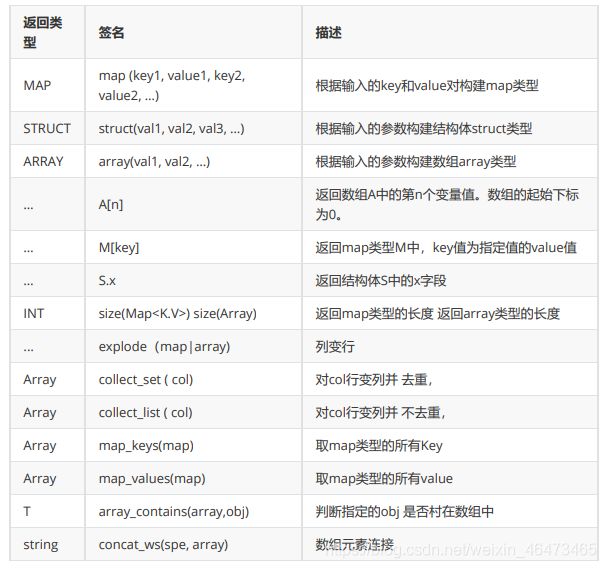
4、复合类型构建访问函数
5、Hive和Mysql的对比:并行存在
| 离线数据库(Hive) | 普通数据库(Mysql ) |
|---|---|
| 入仓不变(历史数据和日志数据) | 业务数据,经常变 |
| 添加和提取 | 增、删、改、查 |
| 只有元数据,表映射的是HDFS里的文件数据 | 存数据,锁和事物 |
| 数据格式由用户定义 | 数据格式由系统决定 |
| 不支持数据更新 | 支持数据更新 |
| 无索引 | 有索引 |
| 执行的是MapRedcue | 执行的是Executor |
| 执行延时高 | 执行延时低 |
| 可扩展性高 | 可扩展性低 |
| 数据规模大 | 数据规模小 |
hive 的区别:
(1)存储——>映射
(2)复杂类型
(3)分隔符
(4)分区
(5)排序:四种
6、Hive的数据存储
- 1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
- 2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
- 3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
- (1):db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
- (2):table:在hdfs中表现所属db目录下一个文件夹
- (3):external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了 - (4): partition:在hdfs中表现为table目录下的子目录
- (5):bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
7、Hive的启动:
- 这是建立在二次启动的时候:
- (1)jps:查看集群状态
- (2)start-all.sh:启动集群
- (3)service mysqld ststus:查看mysqld状态
- (4)service mysqld start:启动mysqld
8、Hive的基本语句
1、建表语法如下所示:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] ----指定表的名称和表的具体列信息。
[COMMENT table_comment] ---表的描述信息。
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] ---表的分区信息。
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] ---表的桶信息。
[ROW FORMAT row_format] ---表的数据分割信息,格式化信息。
[STORED AS file_format] ---表数据的存储序列化信息。
[LOCATION hdfs_path] ---数据存储的文件夹地址信息。
2、 CLUSTERED BY(分桶)
- 对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
3、把表(或者分区)组织成桶(Bucket)有两个理由:
- (1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
-(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
9、Hive的使用过程
1、建普通表(table):
-(1)查看表的转态(个数,有哪些表?)
-
show
show tables;
-(2)本地写入txt文档,建立一个描述学生的文件student.txt
-
新建 student.txt;
echo student.txt; -
编辑student.txt的内容(两种方式)
vim student.txtvim是编辑 -
一般不用,因为你在本地文件追加了也传不到表里面
echo 1232 >> student.txt>>是追加;>是覆盖; -
查看 student.txt的内容
cat student.txt -
查看 student.txt的内容
cat student.txt -
(3)建表
CREATE TABLE students(name STRING,age INT,stature INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
- 第一行声明一个students表,包含三列name,age,stature。还必须指明每一列的数据类型,这里我们指定了姓名为字符串类型,年龄和身高都是整型。
- 第二行的ROW FORMAT DELIMITED是HiveQL所特有的,声明的是数据文件的每一行是由制表符分隔的文本。Hive按照这一格式读取数据:每行3个字段,分别对应表中的3列,以换行符分隔。
- 第三行FIELDS TERMINATED BY '\t’表示字段间以制表符分隔。
-
(4)导入本地数据(student.txt)——>在hive里面导入
LOAD DATA LOCAL INPATH '/student.txt' INTO TABLE students; LOAD DATA LOCAL INPATH '/student.txt' OVERWRITE INTO TABLE students; -
(5)查询表中内容
select * from students;
2、托管表(内部表)和外部表
- 在Hive中创建表时,默认情况下Hive负责管理数据,这意味着Hive把数据移到它的仓库目录中,我们称为“托管表”。
- 另一种选择是创建一个“外部表”,这会让Hive到仓库目录以外的位置访问数据。
- 这两种表的区别表现在LOAD和DROP命令的语义上。
(1)托管表(内部表)
-
加载数据到托管表时,Hive把数据移到仓库目录。
LOAD DATA LOCAL INPATH '/student.txt' INTO TABLE students; -
要丢弃一个表,可以使用一下语句:
DROP TABLE students;
这个表,包括它的元数据和数据,都会被一起删除。在这里要重复强调,因为最初的LOAD是一个移动操作,而DROP是一个删除操作,所以数据会彻底消失。这就是Hive所谓的“托管数据”的含义。
(2)外部表
-
对于外部表而言,这两个操作的结果就不一样了:由你自己来控制数据的创建和删除。外部数据的位置需要在创建表的时候指明:
CREATE EXTERNAL TABLE external_table(dummy STRING) LOCATION '/user/tom/external_table'; LOAD DATA INPATH '/data.txt' INTO TABLE external_table;
使用EXTERNAL关键字后,Hive知道数据并不由自己管理,因此不会把数据移到自己的仓库目录。事实上,在定义时,它甚至不会检查这一外部位置是否存在。这是一个非常有用的特性,因为这意味着你可以把创建数据推迟到创建表之后才进行。
丢弃外部表时,Hive不会碰数据,而是只会删除元数据。
(3)如何选择内部表和外部表
- 作为一个经验法则,如果所有处理都是由Hive来完成,应该使用托管表。但如果要用Hive和其他工具来处理同一个数据集,应该使用外部表。
- 普遍的用法是把存放在HDFS的初始数据集用作外部表进行使用,然后用Hive的变换功能把数据移到托管的Hive表中,这一方法反之也成立——外部表可以用于从Hive导出数据供其他应用程序使用。
3、表的修改:
(1)可以使用 ALTER TABLE语句来重命名表:
ALTER TABLE source RENAME TO target;
- 这个结果是 /user/hive/warehouse/source 被重命名为/user/hive/warehouse/target。对于外部表,这个操作只更新元数据,而不会移动目录。
(2)添加或修改一个新列:
-
Hive允许修改列的定义,添加新的列,甚至用一组新的列替换表内已有的列。
ALTER TABLE target ADD COLUMNS (col3 STRING) -
新的col3被添加在已有列的后面。数据文件并没有更新,因此原来的查询会为col3的所有值返回空值null(当然,除非文件中原来就已经有额外的字段)。
-
更常用的做法是创建一个定义了新列的新表,然后使用SELECT语句把数据填充进去。
4、表的删除:
-
DROP TABLE语句用于删除表的数据和元数据。如果是外部表,就只删除元数据——数据不会受到影响。
-
如果要删除表内的所有数据,但要保留表的定义,删除数据文件即可,例如:
dfs -rmr /user/hive/warehouse/my_table; -
Hive把缺少文件(或根本没有表对应的目录)的表认为是空表。
-
另外一种达到类似目的的方法是使用LIKE关键字创建一个与第一个表模式相同的新表。如:
CREATE TABLE new_table LIKE existing_table;
10、自己系统验证过的
1、hive——>新建表
# comment是注释
create table info(
id int comment 'id',
name string comment '名称',
id_array array comment '相关id列表',
map_info map comment '状态信息',
more_info struct )
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':';
也可以丢弃coment
# 创建表
create table info(
id int,
name string,
id_array array,
map_info map,
more_info struct )
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':';
2、本地——>创建文件
(1)本地创建文件(cd /)
echo info.txt;
(2)编辑文件
vim info.txt;
(3)数据
123|华为|1235,345|id:1111,token:1122,user_name:zhangsan1|a,10
456|华为|89,635|id:1111,token:1122,user_name:zhangsan3|b,20
789|小米5|452,63|id:2211,token:1122,user_name:zhangsan2|c,30
1235|小米5|785,36|id:1115,token:2222,user_name:zhangsan5|d,50
4562|OPPO Findx|7875,3563|id:1111,token:2222,user_name:zhangsan6|d,50
(4)查看文件内容
cat info.txt
3、hive——>导入虚拟机本地数据
LOAD DATA LOCAL INPATH '/info.txt' INTO TABLE info;
4、hive——>查询语句
(1)查找全部
select * from info;
(2)查找数组元素(数字做索引);
select id_array[0] from info;
- 查找id_array里的元素,[0]里的数字可换
(3)查找字典元素(键(key)做索引)
select map_info['user_name'] from info;
- 查找map_info里的元素[‘user_name’]里的键(key)可换
(4)查找结构体元素(.)
select more_info.p_type from info;
- 结构体后面的p_type可换
5、hive——>追加一条记录
(1)追加一条map里面没有user_name的数据(自定义)
vim info.txt;
数据:
123|华为|1235,345|id:1111,token:1122|z,10
- 这样追加会把info.txt现有的数据都追加到info表里面
(2)应该这样追加
(1)新建一个txt文件:
echo info1.txt;
(2)编辑txt文件;
vim info1.txt;
(3)写入数据
txt文件 只有这一条数据:
123|华为|1235,345|id:1111,token:1122|z,10
(4)再导入info1.txt里的数据
LOAD DATA LOCAL INPATH '/info1.txt' INTO TABLE info;
- 这样就追加了一条info1里面的数据;主要看你追加文件的里的数据
6、hive——>再次进行查询
(1)查找字典里不含user_name的数据
select * from info
where not array_contains(map_keys(map_info),'user_name');
(2)把数组id_array里的元素连接在一起
# concat_ws相当于mysql里的group_concat
select *,
concat_ws('',id_array) from info;
(3)把字典map_info里的值连接在一起(合成一个大字符串)
select *,
concat_ws('',map_values(map_info)) from info;
(4)查找包含1的字典map的数据
(1)%1%:放%%的
(2)rlike:放正则表达式的
# 第一种方法:
select *,
concat_ws('',map_values(map_info)) from info
where concat_ws('',map_values(map_info)) like '%5%';
# 第二种方法:
# 跟上面的效果一样
select *,
concat_ws('',map_values(map_info)) from info
where concat_ws('',map_values(map_info)) rlike '1';
(5)虚拟表 列变行(炸裂函数)(变成行数看map_info里的键值对个数)
select *,map_key,map_value from info
lateral view explode(map_info) xuni as map_key,map_value;
(6)返回map类型的长度;map_info的大小
select *,map_key,map_value,size(map_info) as b from info
lateral view explode(map_info) xuni as map_key,map_value;
select * from
(select *,map_key,map_value,size(map_info) as b from info
lateral view explode(map_info) xuni as map_key,map_value) a;
select *,map_key,map_value,size(map_info) as b from test
lateral view explode(map_info) xuni as map_key,map_value
where concat_ws('',map_values(map_info)) like '%5%';
(7)所有map_value带5的数据
select * from
(select *,map_key,map_value,size(map_info) as b from info
lateral view explode(map_info) xuni as map_key,map_value) a
where map_value like '%5%';
(8)查询字典map里面符合条件的数据
# 没出结果是正常的,因为没报错
select id,max(b),count(*) from
(select *,size(map_info) as b from info
lateral view explode(map_info) xuni as map_key,map_value)as a
where map_value like '%1%'
group by id
having max(b)=count(*);
(10)查询数组id_array里面符合条件的数据
select id,max(b),count(*) from
(select *,size(id_array) b from info
lateral view explode(id_array) info1 as ids)as a
where ids like '%3%'
group by id
having max(b)=count(*);
(11)行变列(collect):
collect_set:去重
collect_lis:不去重
select id,collect_set(name),collect_list(name) from
(select *,size(id_array) b from info
lateral view explode(map_info) info1 as map_key,map_value)as a
group by id;
(12)数据导出
insert overwrite local directory '/home/hadoop/test_output'
row format delimited fields terminated by '\t'
select * from info;
(13)分区表装载数据
show create table info;
(14)创建分区表
CREATE TABLE `info2`(
`id` int COMMENT 'id',
`id_array` array COMMENT '??id??',
`map_info` map COMMENT '????',
`more_info` struct)
partitioned by (name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':';
(14)打开动态分区
set hive.exec.dynamic.partition.mode=nonstrict
(15)插入分区表
insert into table `info2` partition(name)
select id,id_array,map_info,more_info,name from info;