Machine Learning with Python Cookbook 学习笔记 第8章
Chapter 8. Handling Images
前言
- 本笔记是针对人工智能典型算法的课程中Machine Learning with Python Cookbook的学习笔记
- 学习的实战代码都放在代码压缩包中
- 实战代码的运行环境是python3.9 numpy 1.23.1 **anaconda 4.12.0 **
- 上一章:(95条消息) Machine Learning with Python Cookbook 学习笔记 第7章_五舍橘橘的博客-CSDN博客
- 代码仓库
- Github:yy6768/Machine-Learning-with-Python-Cookbook-notebook: 人工智能典型算法笔记 (github.com)
- Gitee:[yyorange/机器学习笔记代码仓库 (gitee.com)](
8.0 Introduction
- 我们将机器学习应用于图像之前,我们通常首先需要将原始图像转换为我们的学习算法可用的特征。
- 要处理图像,我们将使用开源计算机视觉库 (OpenCV)。
conda install -c https://conda.anaconda.org/menpo opencv
import cv2
print(cv2.__version__)
4.5.2
8.1 Loading Images
-
加载一张图片
-
cv2.imread# Load library import cv2 import numpy as np from matplotlib import pyplot as plt # 加载图片 image = cv2.imread("image.jpg", cv2.IMREAD_GRAYSCALE) # 使用plt展示图片 plt.imshow(image, cmap="gray"), plt.axis("off") plt.show()结果:

Discussion
- 从根本上说,图像就是数据,当我们使用 imread 时,我们会将这些数据转换为我们非常熟悉的数据类型——NumPy 数组:
# 查看图像类型
print(type(image))
![]()
-
我们已将图像转换为一个矩阵,其元素对应于各个像素。 我们甚至可以看一下矩阵的实际值:
print(image)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M6L3qF9B-1658219977019)(C:\Users\12587\AppData\Roaming\Typora\typora-user-images\image-20220719095508114.png)]
- 可以查看图像矩阵的大小
print(image.shape)
![]()
-
加载有色彩的图片
-
初始时会加载成BGR格式(blue,green,red)
# 加载有颜色的图像 image_bgr = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR) # 展示像素 print(image_bgr[0, 0]) -
可以转换成RGB形式
-
可以绘制
# 转换成RGB格式 image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB) # 展示图片 plt.imshow(image_rgb), plt.axis("off") plt.show()
-

- (95条消息) 什么是RGB模式与BGR模式_SGchi的博客-CSDN博客_rgb和bgr
8.2 Saving Images
-
保存图片
-
opencv's imwiritesaving.py
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
# 加载 image as grayscale
image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# 保存
print(cv2.imwrite("images/plane_new.jpg", image))
![]()

保存成功
Discussion
- 图象格式根据文件名后缀确定(.jpg,.png etc.)
- imwrite 将覆盖现有文件而不输出错误或要求确认。
8.3 Resizing Images
- 更改图片大小
resize
# Load image
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# 更改大小
image_50x50 = cv2.resize(image, (50, 50))
# 查看新的图片
plt.imshow(image_50x50, cmap="gray"), plt.axis("off")
plt.show()

Discussion
-
调整图像大小是图像处理常见的任务
-
图像有各种形状和大小,要用作特征,图像必须具有相同的尺寸
-
机器学习可能需要数千或数十万张图像。 当这些图像非常大时,它们会占用大量内存,通过调整它们的大小,我们可以显着减少内存使用量。
-
机器学习的一些常见图像尺寸是 32 × 32、64 × 64、96 × 96 和 256 × 256。
8.4 Cropping Images
-
对图像进行裁剪
-
切片
croppingImage.py
# Load image
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image in grayscale
image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# Select first half of the columns and all rows
image_cropped = image[:,:128]
# Show image
plt.imshow(image_cropped, cmap="gray"), plt.axis("off")
plt.show()

Discussion
- 裁剪对于只研究感兴趣的部分很有用
8.5 Blurring Images
- 使图像像素变得平滑,这样就可以模糊图像
- 求相邻像素的平均值
blurringImage.py
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# 模糊
image_blurry = cv2.blur(image, (5,5))
# 展示
plt.imshow(image_blurry, cmap="gray"), plt.axis("off")
plt.show()
# 以100*100为区域均值模糊图像
image_very_blurry = cv2.blur(image, (100,100))
# Show image
plt.imshow(image_very_blurry, cmap="gray"), plt.xticks([]), plt.yticks([])
plt.show()
 卷积核大小5*5求均值模糊图像
卷积核大小5*5求均值模糊图像
 卷积核大小为100*100求均值模糊图像
卷积核大小为100*100求均值模糊图像
Discussion
- 什么是卷积核?
This neighbor and the operation performed are mathematically represented as a kernel (don’t worry if you don’t know what a kernel is).
相邻像素以及对其在数学上的操作叫做kernel(中文翻译为卷积核)
(95条消息) 图像处理中的卷积核kernel_coder_by的博客-CSDN博客_卷积核
#我们在案例中使用的卷积核如下
# 创造 kernel
kernel = np.ones((5,5)) / 25.0
# 展示 kernel
print(kernel)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EPyw8m2k-1658219977025)(C:\Users\12587\AppData\Roaming\Typora\typora-user-images\image-20220719103837572.png)]
-
中心元素是被检验的元素,而它周围的元素是邻居。因为值都是一样的,所以每一个元素对结果都有相同的权重。
-
我们可以使用
filter2D手动实现卷积核应用于图像来达到类似的效果# 运用卷积核 image_kernel = cv2.filter2D(image, -1, kernel) # Show image plt.imshow(image_kernel, cmap="gray"), plt.xticks([]), plt.yticks([]) plt.show()
[(95条消息) Python-OpenCV中的filter2D()函数_Mr.Idleman的博客-CSDN博客](https://blog.csdn.net/qq_42059060/article/details/107660265?ops_request_misc=%7B%22request%5Fid%22%3A%22165820238616780366584409%22%2C%22scm%22%3A%2220140713.130102334…%22%7D&request_id=165820238616780366584409&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-107660265-null-null.142v32pc_rank_34,185v2control&utm_term=filter2d函数代码 python&spm=1018.2226.3001.4187)
8.6 Sharpening Images
-
锐化图像
-
filter2DsharpenImage.py
# Load libraries import cv2 import numpy as np from matplotlib import pyplot as plt # Load image as grayscale image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE) # 创建卷积核 kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]]) # 锐化 image_sharp = cv2.filter2D(image, -1, kernel) # 显示图片 plt.imshow(image_sharp, cmap="gray"), plt.axis("off") plt.show()

Discussion
-
什么是图像锐化?
图像锐化与图像平滑是相反的操作,锐化是通过增强高频分量来减少图像中的模糊,增强图像细节边缘和轮廓,增强灰度反差,便于后期对目标的识别和处理。锐化处理在增强图像边缘的同时也增加了图像的噪声。方法通常有微分法和高通滤波法。
-
(95条消息) 图像增强—图像锐化_白水baishui的博客-CSDN博客_图像锐化
-
本例子用的是高通滤波的一种算子
[[0, -1, 0], [-1, 5, -1], [0, -1, 0]]
8.7 Enhancing Contrast
-
增强图像之间像素的对比度
-
直方图均衡化是一种图像处理工具
-
我们有灰度图像时,我们可以直接在图像上应用 OpenCV 的
equalizeHist:enhanceContrast.py
# Load libraries import cv2 import numpy as np from matplotlib import pyplot as plt # Load image image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE) # 增强图像 image_enhanced = cv2.equalizeHist(image) # 显示 plt.imshow(image_enhanced, cmap="gray"), plt.axis("off") plt.show() # 有色图像 image_bgr = cv2.imread("images/plane.jpg") # 转换成 YUV 形式 image_yuv = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2YUV) # 直方图均衡化 image_yuv[:, :, 0] = cv2.equalizeHist(image_yuv[:, :, 0]) # 转换成RGB image_rgb = cv2.cvtColor(image_yuv, cv2.COLOR_YUV2RGB) # 展示图像 plt.imshow(image_rgb), plt.axis("off") plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VBfUpFTP-1658219977028)(C:\Users\12587\AppData\Roaming\Typora\typora-user-images\image-20220719135115090.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-94YCEXyb-1658219977029)(C:\Users\12587\AppData\Roaming\Typora\typora-user-images\image-20220719135644640.png)]
Discussion
-
在处理有色图像时,需要先将图像转换成YUV的格式:Y 是亮度或亮度,U 和 V 表示颜色。 转换后,我们可以将 equalizeHist 应用于图像,然后将其转换回 BGR 或 RGB:
-
直方图均衡如何工作的详细解释超出了本书的范围,但简短的解释是它会转换图像,以便使用更广泛的像素强度。
-
虽然生成的图像通常看起来并不“真实”,但我们需要记住,图像只是底层数据的视觉表示。 如果直方图均衡能够使感兴趣的对象更容易与其他对象或背景区分开来(并非总是如此),那么它可以成为我们图像预处理管道的有价值的补充
直方图均衡化 - 知乎 (zhihu.com)
学习了一下,直方图均衡化的核心问题是推导出映射函数f和CDF
最简单的处理就是把理想中的函数想成均匀的,CDF认为是256

当然有许多复杂的形式,可以让f更加符合局部的图片特征,在文章里有介绍
8.8 Isolating Colors
- 分离出图像颜色
- Define a range of colors and then apply a mask to the image
isolateColor.py
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image
image_bgr = cv2.imread('images/plane.jpg')
# 转化 BGR to HSV
image_hsv = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2HSV)
# 定义两种蓝色 in HSV被隔离
lower_blue = np.array([50,100,50])
upper_blue = np.array([130,255,255])
# 生成蒙板
mask = cv2.inRange(image_hsv, lower_blue, upper_blue)
# 进行蒙板
image_bgr_masked = cv2.bitwise_and(image_bgr, image_bgr, mask=mask)
# 转换 BGR to RGB
image_rgb = cv2.cvtColor(image_bgr_masked, cv2.COLOR_BGR2RGB)
# 显示 image
plt.imshow(image_rgb), plt.axis("off")
plt.show()

Discussion
- HSV:色调、饱和度和值
- mask在图像领域被翻译成蒙板
- 定义了一系列我们想要隔离的值,这可能是最困难和最耗时的部分。(在案例中是两种blue)
- 最后生成蒙板,蒙板也是二进制表示,可以进行按位与bitwise_and(src1, src2, dst=None, mask=None)
8.9 Binarizing Images
- 将图像黑白化(2值化)
Thresholding,adaptive thresholding
threholding.py
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image_grey = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# 运用 adaptive thresholding
# 设置极值和邻居大小、均值操作值
max_output_value = 255
neighborhood_size = 99
subtract_from_mean = 10
image_binarized = cv2.adaptiveThreshold(image_grey,
max_output_value,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY,
neighborhood_size,
subtract_from_mean)
# 显示
plt.imshow(image_binarized, cmap="gray"), plt.axis("off")
plt.show()

Discussion
-
max_output_value 只是确定输出像素强度的最大强度。
-
cv2.ADAPTIVE_THRESH_GAUSSIAN_C 将像素的阈值设置为相邻像素强度的加权和。
-
权重由Gaussian window.
-
我们可以使用 cv2.ADAPTIVE_THRESH_MEAN_C 将阈值简单地设置为相邻像素的平均值
# Apply cv2.ADAPTIVE_THRESH_MEAN_C image_mean_threshold = cv2.adaptiveThreshold(image_grey, max_output_value, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, neighborhood_size, subtract_from_mean) # 展示 plt.imshow(image_mean_threshold, cmap="gray"), plt.axis("off") plt.show()
-
最后两个参数是块大小(用于确定像素阈值的邻域大小)和从计算的阈值中减去的常数(用于手动微调阈值)。
-
阈值化的一个主要好处是对图像进行去噪——只保留最重要的元素。
8.10 Removing Backgrounds
- 除去背景
GrabCut算法
# Load library
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image and convert to RGB
image_bgr = cv2.imread('images/background.jpg')
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
# Rectangle values: start x, start y, width, height
rectangle = (0, 56, 256, 150)
# 创建起始遮罩
mask = np.zeros(image_rgb.shape[:2], np.uint8)
# 为grabCut算法使用的临时空间
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
# 应用 grabCut
cv2.grabCut(image_rgb, # 原图片
mask, # 初始遮罩
rectangle, # 定义的长方形区域
bgdModel, # 背景
fgdModel, # 背景
5, # Number of iterations
cv2.GC_INIT_WITH_RECT) # Initiative using our rectangle
# 将确定为背景的地方标记为0,否则标记为1
mask_2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
# 把mask2减去
image_rgb_nobg = image_rgb * mask_2[:, :, np.newaxis]
# 显示
plt.imshow(image_rgb_nobg), plt.axis("off")
plt.show()


效果有点……差
Disscussion
-
首先作者承认
GrabCut无法去除所有背景 -
在我们的解决方案中,我们首先在包含前景的区域周围标记一个矩形。 GrabCut 假设这个矩形之外的所有东西都是背景,并使用该信息来确定正方形内可能是什么背景(要了解算法如何做到这一点,请查看此解决方案末尾的外部资源)。 然后创建一个掩码,表示不同的确定/可能的背景/前景区域。
# Show mask plt.imshow(mask_2, cmap='gray'), plt.axis("off") plt.show()

-
黑色区域是我们的矩形之外的区域,它被假定为绝对背景。灰色区域是 GrabCut 认为可能的背景,而白色区域可能是前景。 然后使用此蒙版创建合并黑色和灰色区域的第二个蒙版:
# Show mask plt.imshow(mask_2, cmap='gray'), plt.axis("off") plt.show()

包含关于Grab Cut算法的介绍(95条消息) 图像分割经典算法–《图割》(Graph Cut、Grab Cut-----python实现)_我的她像朵花的博客-CSDN博客_图割算法
8.11 Detecting Edges
-
查找图片中的边界
-
Canny edge detector
detectEdges.py
# Load library
import cv2
import numpy as np
from matplotlib import pyplot as plt
image_gray = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# 计算中值强度
median_intensity = np.median(image_gray)
# 设置阈值
lower_threshold = int(max(0, (1.0 - 0.33) * median_intensity))
upper_threshold = int(min(255, (1.0 + 0.33) * median_intensity))
# 运用 canny edge detector
image_canny = cv2.Canny(image_gray, lower_threshold, upper_threshold)
# 显示
plt.imshow(image_canny, cmap="gray"), plt.axis("off")
plt.show()

Discussion
- 边缘检测是计算机视觉中的一个主要话题。边缘很重要,因为它们是高信息区域。
- 有许多边缘检测技术(Sobel 滤波器、拉普拉斯边缘检测器等)。但是,我们的解决方案使用常用的 Canny 边缘检测器。
- Canny 检测器需要两个参数来表示低梯度阈值和高梯度阈值。低阈值和高阈值之间的潜在边缘像素被认为是弱边缘像素,而高于高阈值的那些被认为是强边缘像素。
(95条消息) Canny边缘检测_saltriver的博客-CSDN博客_canny
8.12 Detecting Corners
- 检测出图像中的corner
cornerHarris
detectCorners.py
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image_bgr = cv2.imread("images/plane.jpg")
image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
image_gray = np.float32(image_gray)
# 设置 corner detector 参数
block_size = 2
aperture = 29
free_parameter = 0.04
# 搜索corner
detector_responses = cv2.cornerHarris(image_gray, # 原图
block_size, # 每个像素周围的邻居大小
aperture, # 使用的Sobel核大小
free_parameter) # 自由参数,越大可以识别越软的corner
# 将探测后的结果存储
detector_responses = cv2.dilate(detector_responses, None)
# 只要探测到的值大于阈值(这里是0.02的比例),设置成黑色
threshold = 0.02
image_bgr[detector_responses >
threshold *
detector_responses.max()] = [255, 255, 255]
# 转换成灰度图像
image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
# 显示
plt.imshow(image_gray, cmap="gray"), plt.axis("off")
plt.show()
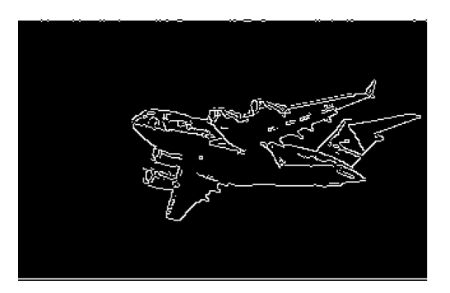
Discussion
-
Harris角点检测器是检测两条边相交的常用方法。
-
我们对检测角点的兴趣与删除边缘的原因相同:角点是高信息点。哈里斯角检测器的完整解释可以在本节末尾的外部资源中找到,但一个简化的解释是它会寻找窗口(也称为邻域或补丁),其中窗口有小的移动(想象摇动窗口)在窗口内的像素内容中产生很大的变化。
-
cornerHarris 包含三个重要的参数,我们可以使用它们来控制检测到的边缘。首先,block_size 是用于角点检测的每个像素周围的邻居的大小。其次,孔径是使用的 Sobel 核的大小(如果您不知道那是什么,请不要担心),最后还有一个自由参数,其中较大的值对应于识别较软的角。
# 显示可能的 corners plt.imshow(detector_responses, cmap='gray'), plt.axis("off") plt.show()

-
然后,我们应用阈值处理以仅保留最可能的角点。或者,我们可以使用类似的检测器 Shi-Tomasi 角检测器,它的工作方式与 Harris 检测器 (goodFeaturesToTrack) 类似,可以识别固定数量的强角。
# 使用goodFeaturesToTrack # Load images image_bgr = cv2.imread('images/plane.jpg') image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY) # Number of corners to detect corners_to_detect = 10 minimum_quality_score = 0.05 minimum_distance = 25 # 检测 corners = cv2.goodFeaturesToTrack(image_gray, corners_to_detect, # 角点个数 minimum_quality_score, # 最低阈值 minimum_distance) # 最短的距离 corners = np.float32(corners) # 圈出每个角点 for corner in corners: x, y = corner[0] cv2.circle(image_bgr, (int(x), int(y)), 10, (255, 255, 255)) # Convert to grayscale image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY) # Show image plt.imshow(image_rgb, cmap='gray'), plt.axis("off") plt.show()
8.13 Creating Features for Machine Learning
- 创建可以用于机器学习的特征
flatten
features.py
# Load image
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load image as grayscale
image = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# Resize image to 10 pixels by 10 pixels
image_10x10 = cv2.resize(image, (10, 10))
# Convert image data to one-dimensional vector
print(image_10x10.flatten())
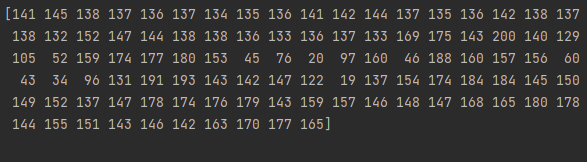
Discussion
-
如果是灰度图像一个像素一个value
plt.imshow(image_10x10, cmap="gray"), plt.axis("off") plt.show()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BkV6RtbB-1658219977036)(C:\Users\12587\AppData\Roaming\Typora\typora-user-images\image-20220719161328275.png)]
-
如果图像是彩色的,则不是每个像素都由一个值表示,而是由多个值(通常是三个)表示,这些值表示混合以形成最终颜色的通道(红色、绿色、蓝色等) 像素。
# Load image in color
image_color = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR)
# Resize image to 10 pixels by 10 pixels
image_color_10x10 = cv2.resize(image_color, (10, 10))
# Convert image data to one-dimensional vector, show dimensions
print(image_color_10x10.flatten().shape)
![]()
- 计算机视觉的一大挑战就是如何处理彩色图片增大,因为它每个像素都是一组特征,随之而来的特征数激增的问题
# Load image in grayscale
image_256x256_gray = cv2.imread("images/plane.jpg", cv2.IMREAD_GRAYSCALE)
# Convert image data to one-dimensional vector, show dimensions
print(image_256x256_gray.flatten().shape)
# Load image in color
image_256x256_color = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR)
# Convert image data to one-dimensional vector, show dimensions
print(image_256x256_color.flatten().shape)
![]()
如输出所示,即使是一张小的彩色图像也有近 200,000 个特征,这在我们训练模型时可能会出现问题,因为特征的数量可能远远超过观察的数量。这个问题将激发后面章节中讨论的维度策略,它试图减少特征的数量,同时不丢失数据中包含的过多信息。
8.14 Encoding Mean Color as a Feature
-
求出平均颜色
meancolor.py
# Load libraries import cv2 import numpy as np from matplotlib import pyplot as plt # 加载 image_bgr = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR) # 计算每个channel的平均值 channels = cv2.mean(image_bgr) # 交换blue和red的值 (making it RGB, not BGR) observation = np.array([(channels[2], channels[1], channels[0])]) # 展示 mean channel values print(observation) # 显示 plt.imshow(observation), plt.axis("off") plt.show()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JVeebO2J-1658219977038)(C:\Users\12587\AppData\Roaming\Typora\typora-user-images\image-20220719162303067.png)]

Discussion
这三个颜色是每个channel的平均值,这可以作为图片的一个特征
8.15 Encoding Color Histograms as Features
-
生成一组代表颜色的特征值
-
计算每一种颜色的直方图
histograms.py
# Load libraries
import cv2
import numpy as np
from matplotlib import pyplot as plt
# 加载
image_bgr = cv2.imread("images/plane.jpg", cv2.IMREAD_COLOR)
# 转换成 RGB
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
# 特征
features = []
# 计算每一个channel
colors = ("r", "g", "b")
# 生成直方图
for i, channel in enumerate(colors):
histogram = cv2.calcHist([image_rgb], # 原图
[i], # 索引
None, # 遮罩
[256], # 直方图大小
[0, 256]) # 范围
features.extend(histogram)
# 创建一个用于表示特征的向量
observation = np.array(features).flatten()
# 展示前五项
print(observation[0:5])
![]()
Discussion
-
RGB每个有三个通道
# Show RGB channel values print(image_rgb[0,0])
-
可以绘制直方图(pandas)
# 绘制直方图 # Import pandas import pandas as pd # Create some data data = pd.Series([1, 1, 2, 2, 3, 3, 3, 4, 5]) # 显示 data.hist(grid=False) plt.show()
# 计算每一个channel
colors = ("r", "g", "b")
# 生成直方图
for i, channel in enumerate(colors):
histogram = cv2.calcHist([image_rgb], # 原图
[i], # 索引
None, # 遮罩
[256], # 直方图大小
[0, 256]) # 范围
features.extend(histogram)
# 绘制
plt.plot(histogram, color=channel)
plt.xlim([0, 256])
# Show plot
plt.show()

下一章:(97条消息) Machine Learning with Python Cookbook 学习笔记 第9章_五舍橘橘的博客-CSDN博客