4.Pyramid Channel-based Feature...论文阅读
Pyramid Channel-based Feature Attention Network for image dehazing
译为:基于金字塔通道的图像去雾特征注意网络
CVIU’2020的论文
作者:Xiaoqin Zhang,Tao Wang,Jinxin Wang,Guiying Tang,Li Zhao
全为温州大学的教授和学生
Abstract
这篇文章先说了——传统的基于 DL 的图像去雾方法通常会使用高层的特征(因为高层包含了更多的语义信息)来去雾,这样会导致忽略底层的特征(然而底层会包括更多的细节信息)。这片文章提出了一种基于金字塔通道的特征注意网络——利用通道注意机制,以金字塔的方式利用不同层次特征之间的互补性,用于单幅图像的去雾。
然后在 Abstract 里面讲述了一下他的模块构造:三尺度特征提取模块、基于金字塔通道的特征注意模块和图像重建模块。
- 三尺度特征提取模块同时提取不同尺度下的底层空间结构特征和高层上下文特征。
- 特征注意模块 PCFA:利用特征金字塔和通道注意机制,有效地提取互相依赖的通道映射。以金字塔的方式选择性地聚集更重要的特征,用于图像去雾。
- 重建模块:用于重建特征来恢复清晰图像。
接着在 PCFAN 中采用了一种结合均方误差损失部分和边缘损失部分的损失函数可以保留图像细节。然后吹一下这个模型的效果。
Conclusion
本文提出一种新的端到端去雾网络,成为基于金字塔通道的特征注意网络,来解决单幅图像去雾问题。该网络命名为 PCFAN,组成部分在 Abstract 中有和下文讲详细介绍。然后提出一种新的边缘丢失算法来帮助网络学习更详细的信息,然后该网络更为轻便易于实施和效率更高更有效。
Introduce
就是比较经典的去雾问题。大多数方法都是依赖于大气散射模型。表达如下:
I ( x ) = t ( x ) J ( x ) + A ( x ) ( 1 − t ( x ) ) I(x)=t(x)J(x)+A(x)(1-t(x)) I(x)=t(x)J(x)+A(x)(1−t(x))
其中 x x x是指平面图像的像素坐标, I I I表示因为雾霾而退化的观测图像, J J J表示没有雾霾的场景图像。矩阵 A A A表示全球大气光,传输图 t t t是中等传输速率描述了到达相机传感器而不被散射的光的部分。
同时这个传输图t可以表达为 t ( x ) = e − β d ( x ) t(x)=e^{-\beta d(x)} t(x)=e−βd(x),其中的 β \beta β是大气是散射系数,同时 d ( x ) d(x) d(x)是相机到场景的距离。然而,透射图和大气光在实践中是未知的。因此,很多图像去雾方法是从模糊图像I中估计 t t t和 A A A,然后通过大气散射模型获得未知的清晰图像 J J J。
以前的图像去雾方法:
更多地集中于使用先验知识(如暗通道先验知识、对比色线先验知识和雾线先验知识)恢复清晰图像。比如 He 提出的暗通道先验方法来估计传输映射。
深度学习方法:
最近,深度学习在各种计算机视觉任务中表现出了有效性。人们提出了各种基于卷积神经网络(CNN)的方法来估计透射图和大气光。一旦对透射图和大气光进行了估计,就可以通过大气散射模型恢复去雾图像。一般来说,CNN 中的低级特征部分指的是细节信息,而高级特征包含更多的语义信息。这两种方法对于恢复清晰图像都很重要,但大多数基于 CNN 的方法通常使用高级特征来实现图像去噪。此外,这些方法基于大气散射模型。如果估计的透射图和大气光不准确,则去雾效果将是低质量的。
右下角的图片为该文章恢复的图像

Related work
在这一部分中,将介绍关于图像去雾和注意机制的相关工作,如下所示。
通常可以分为基于图像先验的去雾方法和基于深度学习的去雾方法。
基于图像先验的去雾方法
- He 等人(2010 年)提出了一种新的基于先验的方法,称为暗通道先验(DCP),以准确估计传输图。如果 RGB 颜色空间中至少有一个颜色通道在没有天空或明亮区域的 hazefree 图像中具有非常低的强度,则 DCP 适用。
- 在朱等人(2015)的工作中,证明了单幅图像去杂任务中颜色衰减先验的效率和有效性。该方法估计透过率并恢复场景辐射度,以去除单个图像中的薄雾
- Berman 等人(2016)提出了一种基于非局部先验的图像去雾算法,其计算复杂度与图像大小成线性关系。该算法假设无雾图像的颜色可以由聚集在 RGB 颜色空间中的典型颜色近似。
- 为了解决去雾图像中抑制伪影的问题,Chen 等人(2016)利用梯度残差最小化(GRM)来抑制去雾图像中输入图像中不存在的边缘。
总结:尽管上述方法在去除雾霾方面取得了成功,但由于它们所依赖的假设,它们的脱雾性能并不总是令人满意。
深度学习去雾方法
最近,数据驱动的深度学习方法在许多计算机视觉任务中展示了其在特征表示方面的优越能力
- 蔡等人(2016)介绍了一种称为 DehazeNet 的端到端系统。它首先估计一个介质传输图,然后通过经典大气散射模型恢复一个无雾图像。此外,作者还设计了用于特征提取的特殊最大输出单元层和用于恢复 DehazeNet 中高质量图像的双边校正线性单元——BReLU,这个有兴趣可以自己去看看。
- Ren 等人(2016)采用多尺度深度神经网络(MSCNN)来估计场景传输图。后面还有升级版的 MSCNN-HE 版本
- Li 等人(2017 年)提出了一种基于 CNN 的图像去雾模型,称为一体式去雾网络(AOD-Net)。他们的轻型网络直接生成无雾图像,而不是单独估计大气光和用于去除雾霾的传输矩阵。
- Zhang 和 Patel(2018)提出了用于端到端图像去雾的密集连接金字塔去雾网络(DCPDN)。该网络同时学习透射图、大气光和去雾图像,然后恢复 hazefree 图像。Chen 等人(2019)提出了一种端到端的门控上下文聚合网络(GCA),用于直接恢复最终的无雾图像。
注意机制
作为人类感知系统的一个重要属性(Itti 等人,1998 年),注意力机制可以被视为引导个体的视线集中在输入场景中最重要和信息最丰富的部分,而不是同时处理整个场景的指南。近年来,注意力机制得到了发展被引入深度学习方法来处理许多计算机视觉任务.
在将一些计算机视觉任务表示为顺序决策任务后,Mnih 等人(2014)提出了视觉注意的循环模型,并充分优化了不可微模型,以使用策略梯度算法学习特定于任务的策略。基于注意力的模型不是一次性处理整个输入图像,而是顺序地自适应地决定应该关注和处理哪些区域。Jaderberg 等人(2015)提出了空间变换网络,并引入了可微模块来缓解输入图像或多通道特征地图中的各种问题,包括对象旋转、比例变换、平移和杂波。为了在图像超分辨率中自适应提取信息丰富的高频通道注意特征,Zhang 等人(2018)采用通道注意机制来增强非常深的残余网络的表征能力。在通道注意模块中使用经典的全局平均池操作,考虑了有用的通道全局空间信息。Fu 等人(2019)提出了基于场景分割任务的自我注意机制的双注意网络(DANet)。提出的位置注意模块用于选择性地学习特征的空间相关性,而通道注意模块用于强调通道相关性。因此,使用这两个注意模块可以获得精确的分割结果。Liu 等人(2019)提出的用于图像去噪的 GridDehazeNet 是一种多尺度网络,带有通道式注意模块。基于通道的注意被用来重构不同尺度的特征,以及缓解一些多尺度网络中出现的瓶颈问题。
Pyramid channel-based feature attention network
1.Network architecture
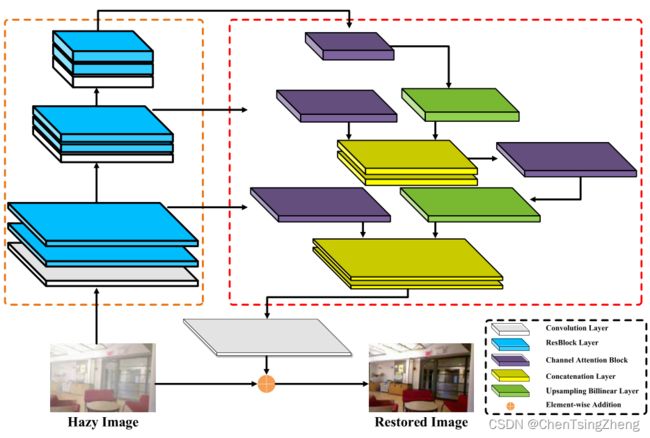
大 致 模 型 大致模型 大致模型
在这项工作中,我们结合了通道注意和金字塔操作的优点,提出了一种基于金字塔通道的特征注意网络(PCFAN)用于图像去模糊。PCFAN 的总体框架如图 2 所示。PCFAN 由三个模块组成,即三尺度特征提取模块、基于金字塔通道的特征注意模块和图像重建模块。三尺度特征模块包含三个阶段:第一个特征提取阶段由一个 3×3 卷积层和两个 RESBlock 组成(He 等人,2016)。在此阶段,特征图的深度(通道数)增加到 32。以下两个阶段均由 3×3 卷积和步幅 2 和两个重分组组成。它们将特征贴图的深度增加到 64 和 128,并将特征贴图的分辨率分别降低一半。与以往只使用第三阶段输出特征的工作不同,这三个阶段的所有输出都被输入到由多个通道注意块构成的基于金字塔通道的特征注意模块中。通道注意块用于在空间和通道维度上消除特征。最后,利用仅由一个卷积层组成的图像重建网络来重建清晰的图像。PCFAN 中的核心组件是通道注意块和基于金字塔通道的特征注意块,这将在以下部分详细介绍。
频道注意块:在这项工作中,为了确保网络捕捉到更多信息性特征,渠道注意机制(Zhang 等人,2018)被用于探索特征渠道之间的相互依赖关系。
通道详细结构信息如下图所示:
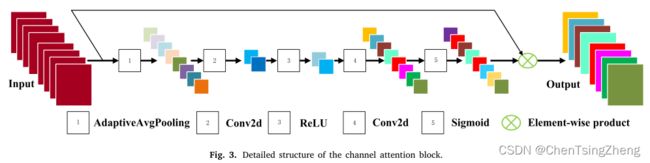
频 道 注 意 块 的 详 细 结 构 频道注意块的详细结构 频道注意块的详细结构
假设这些特征 f ∈ R C × W × H , f = [ f 1 , f 2 , . . . , f C ] f \in R^{C\times W\times H},f=[f_1,f_2,...,f_C] f∈RC×W×H,f=[f1,f2,...,fC]已给定,其中 f i ∈ R W × H f_i\in R^{W\times H} fi∈RW×H是 f f f的第 i i i个子特征,并且 C C C是 f 的通道数。首先,全局的 f 通道统计通过全局平均池化层来获得,下列公式所示:
v c = 1 W H ∑ i = 1 W ∑ j = 1 H f c ( i , j ) , μ = [ v 1 , v 2 , . . . , v c ] , v_c=\frac{1}{WH}\sum^W_{i=1}\sum^H_{j=1}f_c(i,j),\mu=[v_1,v_2,...,v_c], vc=WH1i=1∑Wj=1∑Hfc(i,j),μ=[v1,v2,...,vc],
其中 v c v_c vc表示通道特性,W 和 H 是各自特征的宽度和高度, f c ( i , j ) f_c(i,j) fc(i,j)指第 c 个特征的值在(i,j)点, [ . , . , . ] [.,.,.] [.,.,.]是串联操作,因此 μ \mu μ是 v k ( k = 1 , 2 , . . . C ) v_k(k=1,2,...C) vk(k=1,2,...C),然后,使用两个具有 ReLU 和 Sigmoid 激活函数的卷积来学习通道之间的线性和非线性相互作用。这些操作可以捕获聚合特征之间的通道依赖关系。其表述如下:
y ~ = σ ( ϕ 2 ( η ( ϕ 1 ( μ ) ) ) ) \widetilde{y}=\sigma(\phi_2(\eta(\phi_1(\mu)))) y =σ(ϕ2(η(ϕ1(μ))))
其中 ϕ , η \phi,\eta ϕ,η和 σ \sigma σ分别指卷积层,ReLU 和 Sigmoid 激活函数。 ϕ 1 \phi_1 ϕ1旨在减少输入功能的通道。 η \eta η被 ReLU 激活后,然后使用卷积层 ϕ 2 \phi_2 ϕ2将特征增加到原始通道数,最后通过以下方式获取该区块的输出特征 F o u t F_{out} Fout:
F o u t = f ~ ⨂ f F_{out}=\widetilde{f}\bigotimes f Fout=f ⨂f
其中,⊗ 是对应元素相乘, f f f是原始特征。
基于金字塔通道的特征注意模块:正如 Girshick(2015)和 He 等人(2015)所述,金字塔操作可以从 CNN 的多个层中提取特征,同时将它们融合以生成更有效的特征。然而,这些方法通常使用直观的融合策略,比如加法或级联。因此,我们提出了一种基于金字塔通道的特征注意模块(PCFA),它结合了特征金字塔和通道注意机制的优点。
2. Loss function
为了优化所提出的网络,使用两个损失函数。
-
MSE loss.
均方误差(MSE)损失用于测量清晰图像和输出去模糊图像之间像素方向的差异。MSE 的定义如下:
L M S E = 1 C W H ∑ c = 1 C ∑ i = 1 W ∑ j = 1 H ( I c , i , j c l e a r − I ~ c , i , j d e h a z e ) 2 ℒ_{MSE}=\frac{1}{CWH}\sum^C_{c=1}\sum^W_{i=1}\sum^H_{j=1}(I^{clear}_{c,i,j}-\widetilde{I}^{dehaze}_{c,i,j})^2 LMSE=CWH1c=1∑Ci=1∑Wj=1∑H(Ic,i,jclear−I c,i,jdehaze)2其中,C,W,H 分别代表一张图片的通道数,宽度和高度。 I c , i , j c l e a r I^{clear}_{c,i,j} Ic,i,jclear是地面在通道 c 上(i,j)的真实值, I ~ c , i , j d e h a z e \widetilde{I}^{dehaze}_{c,i,j} I c,i,jdehaze是对应于 PCFAN 生成的去雾图像的值。
-
Edge loss.
为了更详细地恢复清晰的图像,我们在网络中引入了边缘损失函数。首先是卷积运算 Conv 使用拉普拉斯算子(Trudinger,1983)获得清晰图像和去模糊图像的边缘图像。然后使用 Tanh 激活函数将边缘图像的值映射到 [ 0 , 1 ] [0,1] [0,1].
最后是像素距离 ( L 1 N o r m ) (L_1 Norm) (L1Norm)用于测量清晰边缘图像和去模糊边缘图像之间的差异。边缘损失函数由下式给出:
L e d g e = ∥ T a n h ( C o n v ( I c l e a r , k l a p l a c e ) ) − T a n h ( C o n v ( I ~ d e h a z e d , k l a p l a c e ) ) ∥ 1 ℒ_{edge}=\parallel Tanh(Conv(I^{clear},k_{laplace}))-Tanh(Conv(\widetilde{I}^{dehazed},k_{laplace}))\parallel_1 Ledge=∥Tanh(Conv(Iclear,klaplace))−Tanh(Conv(I dehazed,klaplace))∥1 -
Total loss.
总体损失:在训练阶段,通过组合这两个损失函数来定义总损失,并由下式给出:
L = L m s e + α ⋅ L e d g e ℒ=ℒ_{mse}+\alpha \cdot ℒ_{edge} L=Lmse+α⋅Ledge
其中 α \alpha α是用于产生最终损失的超参数 ℒ. 在这项工作中, α \alpha α设置为 0.01。
Experiments
在本节中,我们在一个合成数据集和一个真实数据集上进行了大量实验,以证明所提出的网络的有效性。将所提出的网络与最先进的基于图像先验的方法和基于学习的方法进行比较,包括 DCP(He et al.CVPR’09)、DehazeNet(Cai et al.TIP’16)、MSCNN(Ren et al.ECCV’16)、AOD Net(Li et al.ICCV’17)、GFN(Ren et al.CVPR’18)、DCPDN(Zhang et al.CVPR’18)、EPDN(Qu et al.CVPR’19)和 FAMEDNet(Zhang TIP’20)。此外,还进行了消蚀研究,以验证边缘损失函数和基于金字塔通道的特征注意模块的有效性。
Experimental settings
数据集:很难收集大量真实世界的朦胧图像及其无霾图像。因此,数据 驱动的方法通常依赖于合成的模糊图像,这些模糊图像是使用适当的散射系数从基于大气散射模型的清晰图像生成的 β \beta β和大气光 α \alpha α.在这项工作中,一个名为 RESIDE(Li 等人,2018a)的大规模合成数据集被用来训练和测试提议的 PCFAN。它分为五种不同的类型子集:室内训练集(ITS)、室外训练集(OTS)、综合客观测试集(SOTS)、现实世界任务驱动测试集(RTTS)和混合主观测试集(HSTS)。ITS、OTS 和 SOT 是合成数据集,RTT 中的图像来自真实场景,HST 包含合成图像和真实图像。ITS 包含 1399 个清晰图像生成的 13990 个模糊图像,SOTS 包含 500 个室内模糊图像和 500 个室外模糊图像。在这项工作中,ITS 和 SOTS 分别用作训练集和测试集。设置与之前方法中使用的设置相同(Qu 等人,2019 年)。此外,在 RTTS 上进行了一些实验,证明了该网络的泛化能力。
实现:在训练所提出的网络时,所有图像都在 RGB 空间中处理。为了优化提议的网络,采用了批量为 1 的 Adam(Kingma and Ba,2014)优化器,其中 β 1 \beta_1 β1和 β 2 \beta_2 β2的值分别为 0.5 和 0.999。学习率设置为 0.0001.提出的网络是用 PyTorch 框架实现的。此外,培训和测试也在配备 Intel Xeon Silver 4114 CPU、32 GB RAM 和 NVIDIA Tesla P100 GPU 的 PC 上进行。为了进行公平比较,本文中的峰值信噪比定量结果是在去噪结果的基础上使用 PYTHON 代码计算的。 P S N R = 10 × l o g 10 ( M A X ) 2 M S E PSNR=10 \times log_{10}\frac{(MAX)^2}{MSE} PSNR=10×log10MSE(MAX)2,(我找到的这一篇论文在这里出现错误,不知道是不是论文中打错了还是谷歌学术下载过来显示错误)其中 MAX 是每张图像的最大像素值。MSE 用来评估一张真实场景和去雾后的图像的误差。
质量措施:为了评估该网络的性能,本工作考虑了两个方面:一个是客观测量,另一个是主观评估。对于前者,研究了两个评估标准:峰值信噪比(PSNR)和结构相似性指数(SSIM)(Wang 等人,2004)。对于后者,在 SOTS 和 RTTS 数据集上,将所提出的网络与六种最先进的方法进行可视化比较。
Ablation study
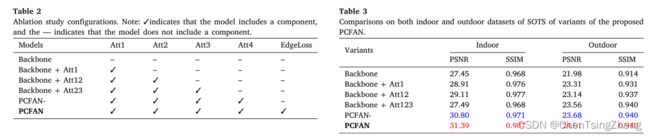
为了进一步证明建议的 PCFAN 的有效性,进行了消融实验,以验证建议的 PCFAN 的所有部分是否有效。该 PCFAN 的核心组件是基于金字塔通道的特征注意模块(PCFA)、通道注意块和边缘丢失函数。因此,通过考虑 PCFA 模块中不同的通道注意块和边缘损失函数,进行了消融实验。如第 3 节所述,有四个重要的通道注意块对 PCFAN 的性能有很大影响。
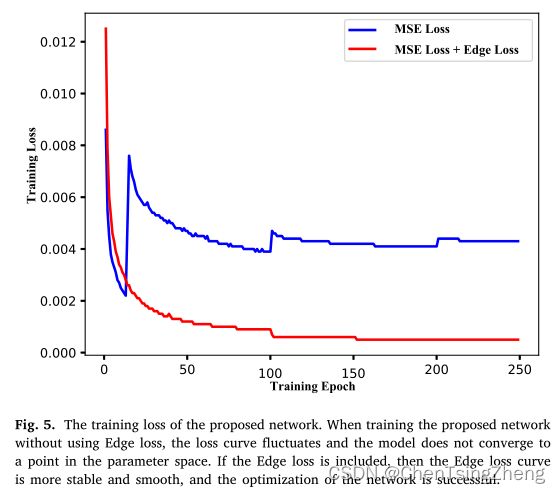
我只取其中的Edge的图像来讲一下:
翻译下来就是:当在不使用边缘损耗的情况下训练所提出的网络时,损耗曲线会波动,并且模型不会收敛到参数空间中的某一点。如果考虑了边缘损耗,则边缘损耗曲线更稳定、更平滑,网络的优化是成功的。
下面就是消融实验的对比的表:
Comparisons with state-of-theart methods
将所提出的网络在合成数据集上的结果与最先进的方法进行了比较。一些方法,如DCP、DehazeNet和GRM,首先估计透射图和大气光,然后借助大气散射模型来恢复dehazed图像。其他方法,如DCPDN和EPDN,直接学习模糊图像和去模糊图像之间的映射,并使用该映射恢复去模糊图像。图6。显示了SOTS室内和室外数据集视觉效果的定性比较。基于先前的方法,如DCP和GRM,往往会产生比地面真相更暗的图像,因为这些方法往往无法准确估计图像的模糊厚度。此外,图像的颜色失真会降低图像的质量。(例如,图6中的建筑、天空、地板和椅子(DCP、GRM))。对于基于学习的方法,DehazNet和GCA的结果中有更多的模糊性。这会导致颜色失真问题。虽然AOD网络可以减少颜色失真,但它会受到光环效应的影响。(例如,参见图6(AOD)中椅子和建筑物的边界)。虽然EPDN取得了更好的效果,但仍存在一些混浊和颜色失真。与这些方法相比,该方法在去除雾霾方面取得了最佳的视觉效果。定量比较结果如表1所示,其中数字值是SOTS数据库中平均PSNR和SSIM的结果。结果表明,PCFAN在图像去杂方面的性能最好。具体来说,在SOTS的室内数据集上,PCFAN在比较的方法中排名第一。