Parameter Server论文阅读笔记《Scaling Distributed Machine Learning with the Parameter Server》
工作一直在使用分布式的机器学习框架,有必要了解一些基本的原理,就先从李沐大佬的文章入手,写个笔记作为记录。
主要贡献
第三代开源的Parameter Server架构,具有以下特性
1)高效的通信
2)灵活的一致性模型
3)弹性可拓展能力
4)系统容错能力
5)易用性
工程挑战
通信:访问巨量的参数,需要大量的网络带宽支持。
容错:分布式计算需要较好的容错能力,failover机制。
相关工作
第一代的参数服务器架构
VLDB 2010,灵活性和性能都比较欠缺,使用memcached存储作为同步机制。
YahooLDA实现了一些基本原语的定义,包括update、set,get等
第二代的参数服务器架构
Distbelief(Google,2012)只针对特殊应用,不够通用
第三代的参数服务器架构
Petuum、PS server更加通用
本问提出的架构结合各家所长,解决当前限制
Spark Mlib,包含中间状态的存储,有很好拓展性,但是受限于BSP的一致性。
GraphLab,异步通信,但是有结构限制,拓展性不太好。
Piccolo,有完善的参数aggregate,但缺少消息压缩、备份、一致性。
目的
风险最小化,风险就是预测误差的衡量,预测误差即模型对未来的样本的预测误差。
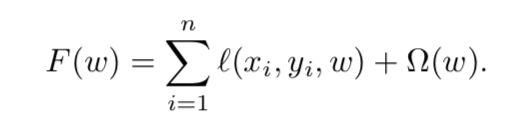
一部分是在训练数据上的误差,一部分是模型复杂度的惩罚(正则项)。
模型的复杂度和训练的数据量之间有明显的关系,当模型复杂度高训练数据少时容易出现过拟合的情况,结果可能出现记忆每个样本的结果,对未来样本的预测能力是不好的;当模型复杂度低数据量多的时候模型就无法捕捉感兴趣的相关信息。
架构
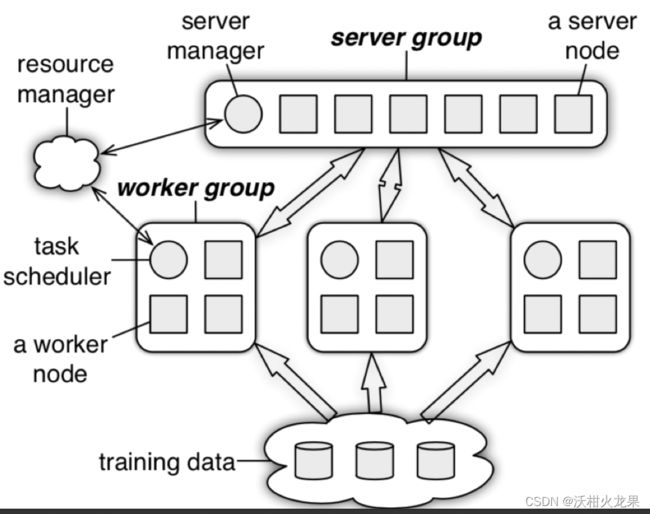
主要分为server group和worker group
1)在server group中一个server node维护一个模型参数的分片,它会跟group中的其他node进行通信,作数据转移或备份提供可靠性。server manager维护meta信息,包括参数分片的分配以及node的存活信息。
2)worker group中的worker节点负责保存部分训练样本数据并计算梯度等统计信息,worker节点之间是独立的,不会相互通信,只会和sever进行通信,更新及来取参数。
参数通过(key, value)的vector进行存储
KV Vector
机器学习将模型作为(稀疏的)线性代数的对象。key需要是有顺序的,将参数作为 kv的pair,不存在的key默认就是0,最终作为向量或者矩阵的语义。这样的好处是实现优化算法的时候有一些现成的库可以使用。
Range Push and Pull
基本操作是一次拉取或更新一个范围内的key的参数,可以试全部,也可以是单个key。也可以将本地的梯度共享出来。
Server UDF
server除了对worker传过来的数据进行常规的aggregate,还可以进行用户自定义的操作,以实现更负责的优化算法。
Asynchronous Tasks and Dependency
Tasks通过RPC来进行远程调用,可以是一个push或者pull的操作,也可以是一个操作的结合。当被调用方返回一个结果,调用方才会标记一个task完成,task是并行异步执行的,也可以设置执行task的依赖。
灵活的一致性
为了权衡收敛效果和系统性能(耗时),提供了灵活的一致性机制
1)Sequential,依次执行,BSP
2)Eventual,同时执行
3)Bounded delay,设置一个时间t,在t时间之前的所有任务都完成了,新的任务才会启动。
Bounded delay具有比较好的灵活性,当t=0的时候就是Sequential,当t为无穷时就是Eventtual
User-Defined Filter
系统提供细粒度的通信同步控制,对于某些算法,可以判断某些参数是否对模型起到重要作用,通过一些阈值判断进行非必要的通信过滤。发送很小的梯度值是低效的。
Vector Clock
为了跟踪向量合并的过程以及防止重复消息的发送,需要给向量打上时间标记即Vector Clock。传统的方法需要o(n * m),即节点和参数,但是同一个range的参数时间戳是相同的,这样可以节省空间。
Massage
消息包含在key range中对应的kv pair,以及对应的Vector Clock。消息不仅使用在模型参数的传递中,还可以使用在task的消息传递,格式为(task id, 参数或者返回的结果)。机器学习训练过程中需要很高的通信带宽,所以消息需要进行压缩。比如在训练迭代过程中key没有变化,第二次消息传递就只需要key的hash就行;value中部分模型参数并没有变化也不需要进行通信,此时需要进行过滤。
一致性哈希和server的管理在本问不做详细说明。