生成对抗网络(Generative Adversarial Networks)
参考 生成对抗网络(Generative Adversarial Networks) - 云+社区 - 腾讯云
目录
一、生成对抗网络原理
1、模型的起源
2、模型的结构和损失函数
二、对GAN的改进
1、零和博弈
2、非饱和博弈
3、最大似然博弈
三、GAN的训练
四、GAN面临的问题
1、很难达到纳什均衡点
2、无法有效监控收敛状态
3、模型崩溃
4、不适合离散输出
五、GAN的应用
1、图像生成
2、由文本生成图片
3、超分辨Super-Resolution
一、生成对抗网络原理
1、模型的起源
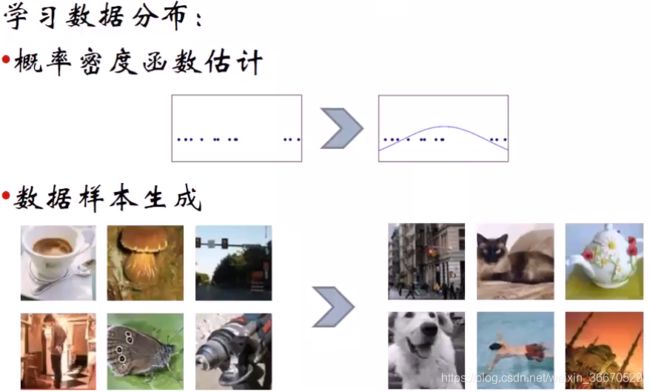
传统的生成指的是生成图像数据,生成有两种策略,一种是直接估计概率密度函数,机器学习模型分为两类一类是判别式模型,一类是生成式模型,生成模型是基于联合概率,判别性模型基于条件概率,生成式模型判别的是一种共生关系,判别式判别的是一种因果关系。知己估计概率密度函数生成的是概率密度函数或者概率密度函数的参数。另一种是绕开直接估计概率密度函数,直接学习数据样本生成的过程,里面没有显式函数的学习。第一种方式比较直观,但有的情况下直接生成数据样本更合适,可以避开显式概率密度函数的估计和设计,直接达到目的。

训练数据集有一个模型,目标模型是生成样本的模型,假设这个模型是存在的,只是在学习过程中无法直接获取表达式,学习过程就是让这连个模型无限接近相等,也就是说让生成样本的模型无限逼近训练数据集的模型,因为训练数据集背后隐式的存在一个概率密度函数(只是有时不知道这个函数的显式表达式)。因为目前的模型能力有限,直接去模拟数据分布能力不够,可以换个思路,我们直接去模拟它的生成过程,让生成过程尽量接近,这样的话就可以使生成样本的模型逼近训练数据集的模型,也就是![]() 。这种生成模型的方法更适合高维数据和复杂的概率分布,这种分布通常比较难以直接去拟合,另外一方面无论直接拟合概率分布还是拟合数据生成过程,都可以解决数据缺失问题。因为已经有了生成模型的过程,可以补充训练集的缺陷数据。多模态输出的含义是数据本身有不同的模态,不限于文本和图像之间的差异,是数据里面的模态,本质上还是一种复杂数据的体现。真实输出任务也是补充数据集,半监督无监督这种形式。数据预测的含义是已经拿到了数据生成的模型,无论是显示的概率分布函数,还是生成器,都可以生成想要的数据
。这种生成模型的方法更适合高维数据和复杂的概率分布,这种分布通常比较难以直接去拟合,另外一方面无论直接拟合概率分布还是拟合数据生成过程,都可以解决数据缺失问题。因为已经有了生成模型的过程,可以补充训练集的缺陷数据。多模态输出的含义是数据本身有不同的模态,不限于文本和图像之间的差异,是数据里面的模态,本质上还是一种复杂数据的体现。真实输出任务也是补充数据集,半监督无监督这种形式。数据预测的含义是已经拿到了数据生成的模型,无论是显示的概率分布函数,还是生成器,都可以生成想要的数据
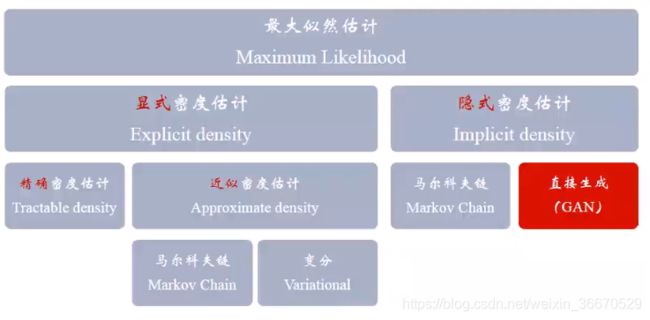
生成模型如上图所示,GAN属于最大似然估计这个机器学习分支。其中做分支是显示密度估计,右分支是隐式密度估计,显示密度估计又包括精确密度估计,还有近似密度估计,绝大多数情况都是近似密度估计,近似密度估计有马尔科夫链和变分。隐式密度估计也有马尔科夫链,主要是GAN。

首先,对抗式生成网络时无监督的,对大数据不需要耗时的人工标注,就能把数据中的特性学习出来,并不会取代有监督,只是有监督的一个补充。第二个特点是GAN使用隐含码,这种隐含码其实是一种输入。GAN在实际设计出来的时候就是一个有监督框架,两个有监督的网络在一起构成无监督操作,需要的数据是无标注的,在操作过程中还是有另外一种输入的。从框架上来讲是一种有监督框架,只是作用是有监督学习。第三个特点是可以直接生成高质量和高维数的样本数据。GAN的两大特征是无监督生成高维数。
2、模型的结构和损失函数
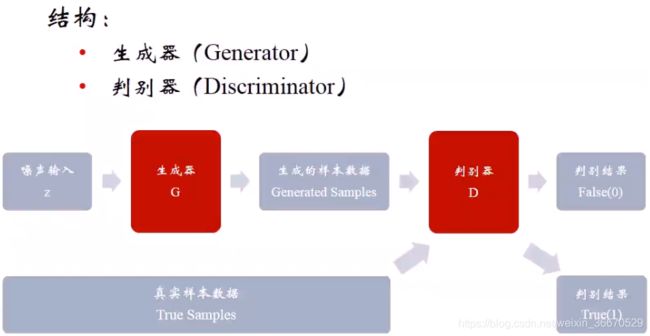
一个很直观的例子是将生成器比喻成造假币的机器,判别器比喻成验钞机,而且这两个机器都有学习能力,都会不断根据现有的数据情况进行改进。对图像数据生成来讲,生成器是伪造数据,判别器判别数据是伪造的还是真实的。网络分两部分,生成器部分和判别器部分。生成器的输入是随机噪声,比如一个1x1000维的随机向量,输入后通过生成器映射到一个假想的数据上,生成样本数据,如果生成器足够好,所有生成器都会对应一个极真实的数据。判别器的作用是判别生成的样本数据相对于真实样本数据的真假,假的数据直接判为False,真的数据就判别为True。在训练过程中分为两步,判别器和生成器轮流升级,相互竞争。刚开始时是判别器先好起来,生成器才能不断的优化造假能力。第一步是优化判别器,判别器这时的输入有两种数据,一种是真实数据,另一种是还没有训练过的生成器生成的假数据,这时生成的数据特别假,因此判别器很轻松的就能学习。第二步是优化生成器,这时将判别器固定下来,判别器具有一定的判别能力,这时生成器需要根据判别器回传的数据,这些数据为什么为假的梯度信息去优化自己,提升自己的造假能力,造假的方向是判别器的能力极限。因为在训练生成器的时候不使用真实数据,只使用之前判别过的假数据,但这是判别器已经将真实数据集成到自己的网络中了,所以判别器网络自带了网络的真实信息,所以判别器回传时,必然回传的是真实数据和生成器造假的数据之间的差异性。从这个角度来讲,判别器是一种损失函数,只不过这种损失函数是在对抗学习中不断升级时动态的,而且向生成器回传假数据时是间接性的回传,也就是学习完成后基于自身学习到的东西来回传,所以生成器的基线是判别器,并不是像有监督中的真实数据。因此,生成器不会出现过拟合问题,因为生成器不会直接对接真实数据。

生成器负责样本生成,输入为高斯白噪声,z是一个1x100的随机向量,输出为样本数据x,中间使用CNN来构建的,也可以直接使用现成的网络。GAN很重要的一点是必须可微分,也就是说数据必须是连读的可微分,这就是GAN在图像中应用广泛的原因,在离散或语义不连续的数据上,比如文本,效果很一般。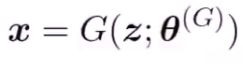 为GAN的公式,
为GAN的公式,![]() 代表生成器网络的参数。
代表生成器网络的参数。

判别器负责判别样本数据真假,要判别的数据有可能是生成器生成的样本数据,也有可能是真实数据集中采样出的样本数据,输出为真假标签,但是在最终预测输出时也不一定为0或1,也有可能是中间值,或者说标签其实是对应概率,0和1为两端的极值。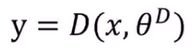 ,x为输入的样本,
,x为输入的样本,![]() 为判别器的参数,数据必须是可微分的。因为数据需要回传到生成器,因此必须使用神经网络。
为判别器的参数,数据必须是可微分的。因为数据需要回传到生成器,因此必须使用神经网络。
直观的理解GAN也是一种DNN网络,只是前半部分是生成器,后半部分是判别器,这两个网络时轮流优化的,而且优化是受前一阶段其他模型结果影响的。这种策略和EM算法类似,只是EM是同方向优化的,而GAN是反向优化的。GAN是同一个函数生成器让它最大化,判别器让它最小化,而EM算法是同方向优化到一个极大值或极小值。GAN本质上是将网络优化到一种平衡状态,基本上已经部分上下了,继续学习并能提升性能,这时候可以认为是一个平局。达到平局的时候,生成器生成的数据,判别器已经无法区分真假了,同时判别器已经足够优越了,生成器生成的真实数据的仿真性也足够优越了。

有监督一般是损失函数,而对GAN网络来说,不是达到最大或最小,而是达到一个均衡,这个均衡的点是纳什均衡点。![]() 是真实数据集里面采样的数据,
是真实数据集里面采样的数据,![]() 是生成器生成的数据,z是1x100的高斯白噪声的随机向量,
是生成器生成的数据,z是1x100的高斯白噪声的随机向量, 是z的分布。价值函数第一部分是真实数据,第二部分是将生成器生成的数据送入判别器后求取在z上的期望,理想情况下D(x)为1,D(G(z))为零。前面的含义是生成器要最小化这个函数,判别器要最大化这个函数。这两部分是对价值函数进行相反方向的优化,这就是对抗的实际意义。
是z的分布。价值函数第一部分是真实数据,第二部分是将生成器生成的数据送入判别器后求取在z上的期望,理想情况下D(x)为1,D(G(z))为零。前面的含义是生成器要最小化这个函数,判别器要最大化这个函数。这两部分是对价值函数进行相反方向的优化,这就是对抗的实际意义。
固定生成器G,判别器式价值函数进行大,因此使log(D(x))尽量为1,使D(G(z))尽量为0,由于第二项用1减去D(G(z)),因此前后两项都是最大化的操作。固定判别器D,优化生成器G,第一项对生成器优化不用考虑,生成器生成的数据要进行真实,判别器就有可能误判,生成器希望判别器尽可能误判,式D(G(z))尽量输出为1,用1减去后就是最小化。总的来讲生成器通过最大化D(G(z))阿里最小化价值函数,判别器通过最小化D(G(z))、最大化D(x)来最大化价值函数,到最终G和D都没有改进的地方时达到纳什均衡点。对生成器和判别器来讲都是两个有监督优化,这里用的是一般的损失函数
二、对GAN的改进
1、零和博弈

相对于最早的GAN,这里判别器的价值函数改进方式为取符号,然后乘以二分之一,二分之一是为了方便计算,取负号的作用是用最大化代替最小化。因为是零和博弈,这里将生成器定义为负的判别器的代价函数,只有一项的原因是第一项对生成器来讲是常数,优化不起作用。生成器最小化目标为判别器将生成数据识别为假的概率的log值,也就是让D(G(z))尽量接近0。存在的问题是均衡点是判别器代价函数的鞍点(saddle point),会困在鞍点上不做优化。
2、非饱和博弈

非饱和博弈在生成器的价值函数去掉1减,并在前面加上负的二分之一,直接去优化llogD(G(z)),生成器的最大化目标为判别器将生成数据误判为真的概率的Log值。
3、最大似然博弈

在非饱和博弈的基础上,将生成器的代价函数有log函数替换为![]() ,当判别器最优时,生成器的梯度与最大似然估计匹配。
,当判别器最优时,生成器的梯度与最大似然估计匹配。
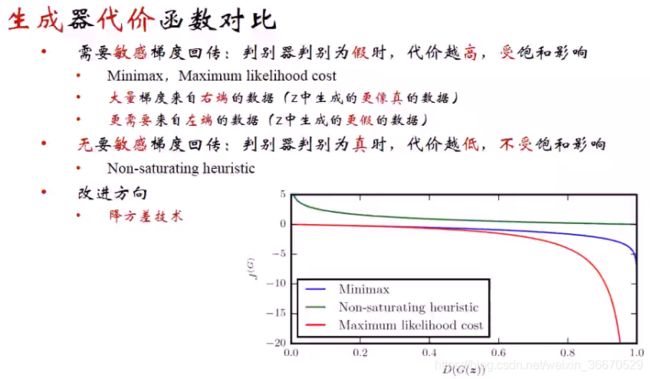
上图解释了为什么三种博弈方法使用不同的生成器函数,其中零和博弈和最大似然估计效果比较差,非饱和效果比较好。曲线的输入为D(G(z)),范围为0到1,曲线的含义为生成器不同外函数的输出,因为都是代价函数,所以都要做最小化优化,优化目标为最小值,也就是上图曲线的最右端。因为非饱和博弈在梯度需要回传的地方对梯度很敏感,在这些地方梯度可以无失真无衰减的传回去。饱和的含义在需要回传的地方梯度很小,回传不到网络内部。判别的标准为生成器器网络D能不能拿到判别器传回的大量梯度无衰减的梯度。蓝色曲线在把数据都判别趋近于假,也就是曲线左端的时候,曲线在左端很长一段区间都为零,尤其是在0到0.2之间,几乎都为零。这个区域很平坦,导数基本上都为零,在这个区段需要误差回传的话,即使误差很大也没办法回传,无法传到生成器上面。当把假数据判别为真的时候,也就是曲线趋近于右端,梯度比较敏感。也就是说对于判别为真的数据效果很好,对于判别为假的数据,效果很差,而需要传回的中要信息是判别器如何将生成数据判别为假来提升生成器的造假能力。因此最大似然比零和博弈效果更差,大量的样本被判别为真,导致判别为真样本将判别为假样本掩膜,最终会导致模型崩溃。
三、GAN的训练

从理论上GAN的生成器和判别器各需要优化一次,但在实际操作中判别器需要优化好多次。首先生成m个随机向量,生成假样本数据G(z),再从数据集里面随机挑出m个真实样本数据,最后使用梯度上升优化判别器的代价函数,即最大化价值函数。固定D,随机生成m个随机噪声向量,使用梯度下降优化生成器的代价函数D(G(z))。从流程操作来讲,生成器的优化是要遍及所有网络。
四、GAN面临的问题
1、很难达到纳什均衡点
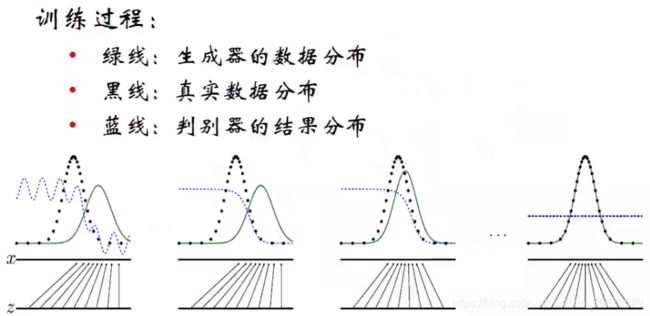
训练过程中z是随机噪声,生成器可以理解为一种映射操作,因为z是随机采样的,通过生成器映射到样本空间中某一个区域,或者说是样本空间中某一些样本点。上面的四个图,从左到右是不断的优化过程。第一步可以理解为初始状态,第二步可以理解为进行了一次轮流优化之后,第三步是进行了两次,最后一个图代表进行了很多次的优化达到纳什均衡点。蓝色曲线代表判别结果,最后变为0.5,也就是完全靠采,丧失了判别能力。

GAN的训练比较困难,因为很难达到纳什均衡点。我们先优化判别器,假设判别器优化分十级,那么生成器也会优化十级达到和判别器同等水平。先将判别器优化到低一级,再将生成器优化到低一级,再将判别器优化到第二级,再将生成器优化到第二级,这样不断交替优化都达到了十级。如果步伐不均匀,比如判别器先优化到四级,由于判别器性能太强,生成器很难达到四级,有可能只优化到两级,这样会导致判别器性能越来越好,生成器性能越来越差,生成器没办法与判别器达到纳什均衡
2、无法有效监控收敛状态
在有监督优化过程中,loss可以实时查看。因为价值函数是一种反方向上的优化,就没有办法监控收敛状态。虽然W-GAN优化了生成器函数和判别器函数,同时提出了一种相关性很强的监控指标。
3、模型崩溃
生成器只挑一部分数据去优化自己,这些数据为判别器最认可的空间点,也就是生成器只去学习一小部分数据集,这小部分数据集,这部分数据很容易判别为真。只在有限的数据集上学习,这样导致输出多样性很低。原因为生成器跟不上判别器的优化速度。
4、不适合离散输出
对于不连读的数据,比如文本。
五、GAN的应用
1、图像生成
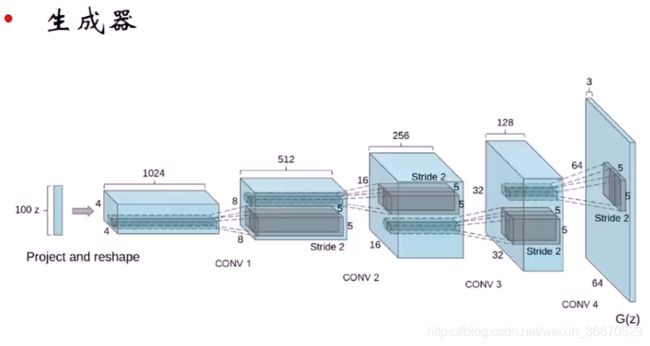
DCGAN是第一个把GAN用到图像生成的工作,DCGAN使用了小数步长的转置卷积。输入为1x100维的随机向量,使用转置卷积后输出4x4x1024的特征图,下层使用转置卷积后变为8x8x512的特征图,也就是说大小2x2倍的扩大,通道数2倍的缩小。最后变为64x64的3通道真实图像,为生成器的输出G(z)。

DCGAN的实验技巧为,对判别器来说,因为是一个降维过程,因此使用整数步长卷积,生成器部分用小数步长卷积,相当于在输入中间插入一些零达到小数步长的效果。核心是使用批归一化,没有批归一化一定训练失败。w-GAN提出后就不需要批归一化就可以很好地稳定训练,同时有一个指标能反应是否收敛。并对CNN网络做出了改进,将全连接层都扔掉。生成器ReLU激活函数,最终输出使用Tanh激活函数,判别器使用Leaky ReLU激活函数。

无法捕捉物体的结构,比如生成的鸟可能有三个头。现在还只能生成低分辨率的图片。

用z1生成的输出为戴眼镜的男士,z2是不带眼镜的男士图片,z3代表不带眼镜的女士图片,用z1减去z2加上z3得到z4的向量。z4向量通过生成器之后得到了戴眼镜的女士照片,这本质上是一种语义计算,首先通过无监督学习与眼镜的语义、眼镜戴上去的叠加操作。

另外一个任务是数据插值操作,左上角的脸对应于z1,右上角的脸对应于z2。因为z1和z2在空间上是有一定距离的两个点,在距离中间做均匀的插值。假设中间的插值为z1,z2,z3,...,zn,到中间的时候脸已经变为正脸,继续超右就是朝向另一个方向了
2、由文本生成图片
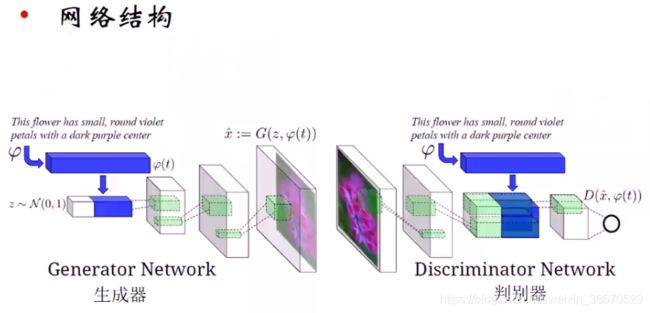
在DCGAN上进行了改进, 在1x1高斯随机向量上追加一个特征,用word2vcc把不定长的句子变为定长的特征,追加到噪声向量之后,生成一个更长的特征向量,相当于加入指导信息,那么生成的图片就生成和指导信息更贴近的图片了。假设句子的特征维1x1x999,那么最终的长度为1x1000。判别的时候和word2vcc做一个比对,最终生成一个优化标签,输出还是0和1,判断这个图片和描述是否一致。
3、超分辨Super-Resolution
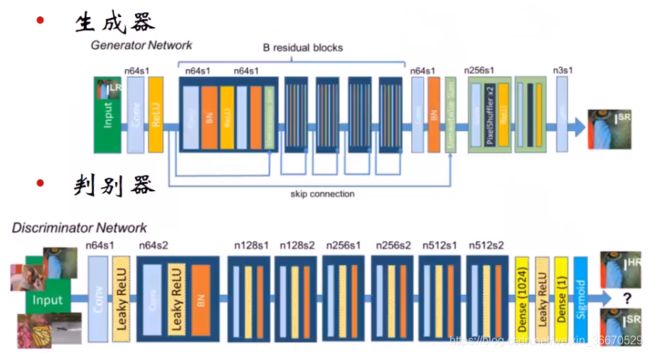
生成器本身是之前的一个旧网络,是一个CNN网络,相当于在生成器网络上面追加了一个判别器,或者说追加了一个动态的优化函数。64指的是卷积尺寸,s1是步长,生成器生成一个高分辨率的图片,判别器输出为真实的高分辨率图片和生成器生成的高分辨率图片进行判断。

其中D和G依然指的是判别器的生成器,只不过D输入为原始高分辨率图片,G输入为低分辨率图像。生成器有两个价值函数,一个是内容代价函数,其实就是MSE,使用了判别器中原始高分辨率图片和生成器生成的图片分别经VGG网络最后几层的响应输出,作为一种损失函数。对抗代价函数来自于判别器回传的损失,使用的是非饱和博弈。