Spark RDD案例(一)分组TopN
Spark RDD案例(一)分组TopN
1. 背景
- 作为分布式数据处理引擎,Spark抽象出了很多算子,使得编程对比mapreduce更加遍历,实现需求时,也可以更加灵活,但也更容易出错。
- 本文是大数据常见场景分组TopN的简化案例,实际企业生产中也会相对频繁遇到类似需求
2. 案例
- 需求
以下数据是类似网站日志的记录,需要求出每个科目老师访问次数最多的那2个。 - 数据
http://bigdata.doit.cn/laozhang
http://bigdata.doit.cn/laozhang
http://bigdata.doit.cn/laozhao
http://bigdata.doit.cn/laozhao
http://bigdata.doit.cn/laozhao
http://bigdata.doit.cn/laozhao
http://bigdata.doit.cn/laozhao
http://bigdata.doit.cn/laoduan
http://bigdata.doit.cn/laoduan
http://javaee.doit.cn/xiaozhang
http://javaee.doit.cn/xiaozhang
http://javaee.doit.cn/laowang
http://javaee.doit.cn/laowang
http://javaee.doit.cn/laowang
2.1 代码一
package com.doit.practice
import com.doit.foreach.ForeachTest
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
/*
* 数据形式如下,http://bigdata.doit.cn/laozhang
* 需求是得出每个科目最受欢迎老师
* 以下是所有数据
* */
object TopNTest1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(TopNTest1.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.textFile("E:\\DOITLearning\\12.Spark\\teacherlog.txt")
// 先把数据匹配出来
val mapedRdd: RDD[((String, String), Int)] = rdd1.map(line => {
val strings: Array[String] = line.split("/+")
val domian: String = strings(1)
val domainSplits: Array[String] = domian.split("\\.")
val subject: String = domainSplits(0)
val name: String = strings(2)
((subject, name), 1)
})
/*
* mapedRdd: ArrayBuffer(((bigdata,laozhang),1), ((bigdata,laozhang),1),
* ((bigdata,laozhao),1), ((bigdata,laozhao),1), ((bigdata,laozhao),1),
* ((bigdata,laozhao),1), ((bigdata,laozhao),1), ((bigdata,laoduan),1),
* ((bigdata,laoduan),1), ((javaee,xiaozhang),1), ((javaee,xiaozhang),1),
* ((javaee,laowang),1), ((javaee,laowang),1), ((javaee,laowang),1))
* */
println("mapedRdd: " + mapedRdd.collect().toBuffer)
// 使用key进行聚合,把观看次数聚合起来
val reduceRDD: RDD[((String, String), Int)] = mapedRdd.reduceByKey(_ + _)
/*
* reduceRDD: ArrayBuffer(((javaee,xiaozhang),2), ((bigdata,laozhang),2),
* ((javaee,laowang),3), ((bigdata,laozhao),5), ((bigdata,laoduan),2))
* */
println("reduceRDD: " + reduceRDD.collect().toBuffer)
// 降序排列
val sortedRDD: RDD[((String, String), Int)] = reduceRDD.sortBy(_._2, false)
/*
* sortedRDD: ArrayBuffer(((bigdata,laozhao),5), ((javaee,laowang),3),
* ((javaee,xiaozhang),2), ((bigdata,laozhang),2), ((bigdata,laoduan),2))
* */
println("sortedRDD: " + sortedRDD.collect().toBuffer)
// 按照学科分类
val subjectReducedRDD: RDD[(String, Iterable[((String, String), Int)])] = reduceRDD.groupBy(_._1._1)
/*
* subjectReducedRDD: ArrayBuffer((javaee,CompactBuffer(((javaee,xiaozhang),2), ((javaee,laowang),3))),
* (bigdata,CompactBuffer(((bigdata,laozhang),2), ((bigdata,laozhao),5), ((bigdata,laoduan),2))))
* */
println("subjectReducedRDD: " + subjectReducedRDD.collect().toBuffer)
// 将学科分类后数据进行区粒度处理
val res: RDD[(String, List[((String, String), Int)])] = subjectReducedRDD.mapValues(iter => {
iter.toList.sortBy(-_._2).take(2)
})
/*
* res: ArrayBuffer((javaee,List(((javaee,laowang),3), ((javaee,xiaozhang),2))),
* (bigdata,List(((bigdata,laozhao),5), ((bigdata,laozhang),2))))
* */
println("res: " + res.collect().toBuffer)
sc.stop()
}
}
运行结果
res: ArrayBuffer((javaee,List(((javaee,laowang),3), ((javaee,xiaozhang),2))), (bigdata,List(((bigdata,laozhao),5), ((bigdata,laozhang),2))))
上述代码,有用到toList再排序,需要注意内存消耗以及数据量大小,过大则不适合这么处理。
2.2 代码二
val conf: SparkConf = new SparkConf().setAppName(TopNTest1.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
// http://javaee.doit.cn/laowang
val rdd1: RDD[String] = sc.textFile("E:\\DOITLearning\\12.Spark\\teacherlog.txt")
val reducedRDD: RDD[((String, String), Int)] = rdd1.map(line => {
val strings: Array[String] = line.split("/+")
val domain: String = strings(1)
val name: String = strings(2)
val domainSplits: Array[String] = domain.split("\\.")
val subject: String = domainSplits(0)
((subject, name), 1)
}).reduceByKey(_ + _)
println("reducedRDD: " + reducedRDD.collect().toBuffer)
/**
* reducedRDD: ArrayBuffer(((javaee,xiaozhang),2), ((bigdata,laozhang),2),
* ((javaee,laowang),3), ((bigdata,laozhao),5), ((bigdata,laoduan),2))
**/
// 获取科目数组,注意需要去重
val subjects: Array[String] = reducedRDD.map(e => e._1._1).distinct().collect()
/**
* ArrayBuffer((javaee,CompactBuffer(((javaee,xiaozhang),2), ((javaee,laowang),3))),
* (bigdata,CompactBuffer(((bigdata,laozhang),2), ((bigdata,laozhao),5), ((bigdata,laoduan),2))))
**/
for (elem <- subjects) {
// 过滤出当前科目的所有数据
val filteredSubjectRDD: RDD[((String, String), Int)] = reducedRDD.filter(e => e._1._1.equals(elem))
// 过滤后数据使用takeOrdered取前2个
val res: Array[((String, String), Int)] = filteredSubjectRDD.takeOrdered(2)(new Ordering[((String, String), Int)] {
override def compare(x: ((String, String), Int), y: ((String, String), Int)): Int = {
-(x._2 - y._2)
}
})
println("res: ")
res.foreach(println(_))
}
sc.stop()
运行结果
res:
((javaee,laowang),3)
((javaee,xiaozhang),2)
res:
((bigdata,laozhao),5)
((bigdata,laozhang),2)
这个代码思路,前期还是先切分line,key就是科目于名字组成的元组,value就是一条数据的量
然后针对这个数据进行聚合,reduceByKey,这样就可以得到每个科目,对应老师总的访问量
然后再统计有多少个科目,注意这里需要去重,所以使用map转换,然后distinct去重
之后for循环,在for循环中,filter筛选出每个科目对应的数据
之后再使用takeOrdered进行数据采集,不过需要自定义一个排序规则,这里使用还是传统java写法,scala写法如下
val conf: SparkConf = new SparkConf().setAppName(TopNTest1.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
// http://javaee.doit.cn/laowang
val rdd1: RDD[String] = sc.textFile("E:\\DOITLearning\\12.Spark\\teacherlog.txt")
val reducedRDD: RDD[((String, String), Int)] = rdd1.map(line => {
val strings: Array[String] = line.split("/+")
val domain: String = strings(1)
val name: String = strings(2)
val domainSplits: Array[String] = domain.split("\\.")
val subject: String = domainSplits(0)
((subject, name), 1)
}).reduceByKey(_ + _)
println("reducedRDD: " + reducedRDD.collect().toBuffer)
/**
* reducedRDD: ArrayBuffer(((javaee,xiaozhang),2), ((bigdata,laozhang),2),
* ((javaee,laowang),3), ((bigdata,laozhao),5), ((bigdata,laoduan),2))
**/
// 获取科目数组,注意需要去重
val subjects: Array[String] = reducedRDD.map(e => e._1._1).distinct().collect()
/**
* ArrayBuffer((javaee,CompactBuffer(((javaee,xiaozhang),2), ((javaee,laowang),3))),
* (bigdata,CompactBuffer(((bigdata,laozhang),2), ((bigdata,laozhao),5), ((bigdata,laoduan),2))))
**/
for (elem <- subjects) {
// 过滤出当前科目的所有数据
val filteredSubjectRDD: RDD[((String, String), Int)] = reducedRDD.filter(e => e._1._1.equals(elem))
implicit val ord = Ordering[Int].on[((String, String), Int)](t => -t._2)
// 过滤后数据使用takeOrdered取前2个
val res: Array[((String, String), Int)] = filteredSubjectRDD.takeOrdered(2)/*(new Ordering[((String, String), Int)] {
override def compare(x: ((String, String), Int), y: ((String, String), Int)): Int = {
-(x._2 - y._2)
}
})*/
println("res: ")
res.foreach(println(_))
}
sc.stop()
2.3 代码三
package com.doit.practice
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.collection.mutable
object TopNTest3 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(TopNTest1.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
// http://javaee.doit.cn/laowang
val rdd1: RDD[String] = sc.textFile("E:\\DOITLearning\\12.Spark\\teacherlog.txt")
val mapedRDD: RDD[((String, String), Int)] = rdd1.map(line => {
val strings: Array[String] = line.split("/+")
val domain: String = strings(1)
val name: String = strings(2)
val domainSplit: Array[String] = domain.split("\\.")
val subject: String = domainSplit(0)
((subject, name), 1)
})
val reducedRDD: RDD[((String, String), Int)] = mapedRDD.reduceByKey(_ + _)
println("reducedRDD:" + reducedRDD.collect().toBuffer)
/*
* ArrayBuffer(((javaee,xiaozhang),2), ((bigdata,laozhang),2), ((javaee,laowang),3), ((bigdata,laozhao),5), ((bigdata,laoduan),2))
* */
val subjects: Array[String] = mapedRDD.map(e => e._1._1).distinct().collect()
// 创建分区器
val subjectPartitioner = new SubjectPartitioner(subjects)
// 按照自定义分区器进行分区
val partitionedRDD: RDD[((String, String), Int)] = reducedRDD.partitionBy(subjectPartitioner)
println("partitionedRDD:" + partitionedRDD.collect().toBuffer)
/**
*
* */
val resRDD: RDD[((String, String), Int)] = partitionedRDD.mapPartitions(iter => {
// 在这里做自定义排序
implicit val ord = Ordering[Int].on[((String, String), Int)](t => -t._2)
// TreeSet是可排序集合,这里设置一个隐式参数,用来指定排序规则
val treeSet = new mutable.TreeSet[((String, String), Int)]()(ord)
// 这里做元素添加
iter.foreach(ele => {
treeSet += ele
if (treeSet.size >= 3) {
treeSet.remove(treeSet.last)
}
})
// 返回一个迭代器
treeSet.iterator
})
println("resRDD:" + resRDD.collect().toBuffer)
sc.stop()
}
}
class SubjectPartitioner(val arg1: Array[String]) extends Partitioner {
val map = new mutable.HashMap[String, Int]()
var index = 0
arg1.foreach(e => {
map.put(e, index)
index += 1
})
override def numPartitions: Int = arg1.length
override def getPartition(key: Any): Int = {
val tuple: (String, String) = key.asInstanceOf[(String, String)]
map.getOrElse(tuple._1, 0)
}
}
运行结果
reducedRDD:ArrayBuffer(((javaee,xiaozhang),2), ((bigdata,laozhang),2), ((javaee,laowang),3), ((bigdata,laozhao),5), ((bigdata,laoduan),2))
partitionedRDD:ArrayBuffer(((javaee,xiaozhang),2), ((javaee,laowang),3), ((bigdata,laozhang),2), ((bigdata,laozhao),5), ((bigdata,laoduan),2))
resRDD:ArrayBuffer(((javaee,laowang),3), ((javaee,xiaozhang),2), ((bigdata,laozhao),5), ((bigdata,laozhang),2))
这里的处理逻辑,前部分和其他一样,先切分每一行文本,转换为科目,名字的元组,并作为key,次数1作为key
然后使用这个匹配的数据转换,筛选出有哪些科目,注意distinct防止重复
然后就是创建自定义分区器,分区这里参数是字符串数组,创建时传入科目数组,得到一个分区器。注意getPartition这里的参数需要做一下强制转换。
分区器中的index是通过对数组中字符串为key,然后index从0累加。因为是去重过的科目数组,所以这里不会发生相同key的问题,index可以依次累加
map转换之后的rdd,再reduceBYKey,key就是科目和名字组成的元组,这样可以得到科目,名字组成的key对应的累计条数
再把这个reduce之后的rdd使用分区器分区一下
之后再把这个分区后的RDD使用mapPartitions来针对每个分区做数据处理。
分区中处理,其实就是一个排序,取出最前面2个数据的过程。因为分区时,针对科目划分,所以这里每个partition就是每个科目对应的数据。
这里没有使用有界优先队列,而是使用treeSet来排序,所以传入了一个隐式参数,隐式参数指定排序规则。
然后就是把每个分区对应迭代器中数据逐条放入这个treeset中,超过指定的条数时,就将最末尾的数据删除,可以使用remove,也可以使用 -=。
然后返回这个treeset的迭代器,因为mapPartitions要求也是返回迭代器
这时候,结果集合中的数据就是按照科目划分出来的,topN条数据,并且数据是有序的,因为创建treeset时,指定了排序规则
2.4 代码四
package com.doit.practice
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.collection.mutable
object TopNTest4 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(TopNTest1.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
// http://javaee.doit.cn/laowang
val rdd1: RDD[String] = sc.textFile("E:\\DOITLearning\\12.Spark\\teacherlog.txt")
// 先对数据做转换
val mapedRDD: RDD[((String, String), Int)] = rdd1.map(line => {
val strings: Array[String] = line.split("\\/+")
val name: String = strings(2)
val domain: String = strings(1)
val domainSplits: Array[String] = domain.split("\\.")
val subject: String = domainSplits(0)
((subject, name), 1)
})
println("mapedRDD: " + mapedRDD.collect().toBuffer)
// 对条数做聚合
val reduceRDD: RDD[((String, String), Int)] = mapedRDD.reduceByKey(_ + _)
println("reduceRDD: " + reduceRDD.collect().toBuffer)
// 然后搜集科目数,创建自定义分区器
val subjects: Array[String] = mapedRDD.map(ele => ele._1._1).distinct().collect()
println("subjects: ")
subjects.foreach(println(_))
val partitoner = new SubjectPartitoner2(subjects)
// 使用reduceByKey,传入相应的分区器进行聚合操作
val partitionAndReducedRDD: RDD[((String, String), Int)] = reduceRDD.reduceByKey(partitoner, _ + _)
println("partitionAndReducedRDD: " + partitionAndReducedRDD.collect().toBuffer)
/**
* ArrayBuffer(((javaee,xiaozhang),2), ((javaee,laowang),3), ((bigdata,laozhang),2), ((bigdata,laozhao),5), ((bigdata,laoduan),2))
* */
// 使用mapPartitions中,对分区中进行自定义排序,涉及到treeset
val resRDD: RDD[((String, String), Int)] = partitionAndReducedRDD.mapPartitions(iter => {
// 自定义排序集合来排序
implicit val ord: Ordering[((String, String), Int)] = Ordering[Int].on[((String, String), Int)](t => -t._2)
val treeSet = new mutable.TreeSet[((String, String), Int)]()(ord)
// 遍历每个分区集合中数据,添加到集合中,如果超过指定数据条数,删除多余的
// 注意,这里使用foreach遍历,不需要使用map遍历并转换,因为这里只是用来给treeset添加数据使用的
iter.foreach(ele => {
treeSet.add(ele)
if (treeSet.size > 2) {
treeSet -= treeSet.last
}
})
// 返回所需要的迭代器
treeSet.iterator
})
println("resRDD: " + resRDD.collect().toBuffer)
/**
* ArrayBuffer(((javaee,laowang),3), ((javaee,xiaozhang),2), ((bigdata,laozhao),5), ((bigdata,laozhang),2))
* */
sc.stop()
}
}
class SubjectPartitoner2(val arg:Array[String]) extends Partitioner {
// 使用hashmap来定义partition的分区index序号
private val indexMap = new mutable.HashMap[String, Int]()
var index = 0
for (elem <- arg) {
indexMap.put(elem, index)
index += 1
}
override def numPartitions: Int = arg.length
override def getPartition(key: Any): Int = {
val tuple: (String, String) = key.asInstanceOf[(String, String)]
indexMap(tuple._1)
}
}
运行结果
ArrayBuffer(((javaee,laowang),3), ((javaee,xiaozhang),2), ((bigdata,laozhao),5), ((bigdata,laozhang),2))
注意,这里对比代码三的实现,只是使用reduceByKey代理了repartitionBy
整体思路还是先切分,然后对数据做转换,注意tuple的对比,是先对比第一个元素,再对比第二个元素
转换为科目,名字组成的元组为key,1为value
然后采集这个转换后集合中的科目数据,注意要去重,再collect回driver端备用
之后,使用reduceByKey对每条数据的值1进行聚合。这时候已经按照数据元组的key进行次数聚合
再之后,使用搜集回来的科目数组,创建新的分区器。分区数量就是传入的科目数,分区规则就是按照做key的元组,取第一个元素,也就是科目进行分区。
然后使用mapPartitions按照分区进行排序,并取出所需要的数据条数。
注意这里使用treeset作为排序集合,自定义了一个隐式参数来指定treeset的排序规则
然后就是使用foreach遍历,获取每个元素并加进treeset中,超过指定条数如需要2条,超过2条则删除多余的数据
最后将treeset的迭代器返回,这是mappartitions这个算子要求的返回值
2.5 代码五
package com.doit.practice
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import org.apache.spark.rdd.{RDD, ShuffledRDD}
import scala.collection.mutable
object TopNTest5 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(TopNTest1.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
// http://javaee.doit.cn/laowang
val rdd1: RDD[String] = sc.textFile("E:\\DOITLearning\\12.Spark\\teacherlog.txt")
// 先把数据做转换
val mapedRDD: RDD[((String, String), Int)] = rdd1.map(line => {
val strings: Array[String] = line.split("\\/+")
val name: String = strings(2)
val domain: String = strings(1)
val domainSplits: Array[String] = domain.split("\\.")
val subject: String = domainSplits(0)
((subject, name), 1)
})
println("mapedRDD: " + mapedRDD.collect().toBuffer)
/**
* mapedRDD: ArrayBuffer(((bigdata,laozhang),1), ((bigdata,laozhang),1), ((bigdata,laozhao),1), ((bigdata,laozhao),1),
* ((bigdata,laozhao),1), ((bigdata,laozhao),1), ((bigdata,laozhao),1), ((bigdata,laoduan),1), ((bigdata,laoduan),1),
* ((javaee,xiaozhang),1), ((javaee,xiaozhang),1), ((javaee,laowang),1), ((javaee,laowang),1), ((javaee,laowang),1))
**/
// 搜集科目信息
val subjects: Array[String] = mapedRDD.map(ele => ele._1._1).distinct().collect()
println("subjects: ")
subjects.foreach(println(_))
// 创建自定义分区器对象
val partitioner = new SubjectPartitioner3(subjects)
// 将转换后数据根据key 聚合
val reducedRDD: RDD[((String, String), Int)] = mapedRDD.reduceByKey(_ + _)
println("reducedRDD: " + reducedRDD.collect().toBuffer)
// 将数据转换为适合repartitionAndSortWithinPartitions 分区并排序的数据,
// 因为需要使得key是ordering的,也就是要排序的字段要在key里面,所以这里做了转换,因为所有数据都在key里面了,所以value为null即可,节省空间
val mapedForRepartitionRDD: RDD[((String, String, Int), Null)] = reducedRDD.map(ele => ((ele._1._1, ele._1._2, ele._2), null))
// 使用repartitionAndSortWithinPartitions进行分区并排序,排序规则使用隐式参数来设置
// 注意,这个隐式参数是为ShuffledRDD针对key要求是ordering而创建的,所以这里其实是key,也就是(String, String, Int)类型
implicit val ord = Ordering[Int].on[(String, String, Int)](t => -t._3)
// repartitionAndSortWithinPartitions 因为这里其实是调用了ShuffledRDD,而排序规则是要求key 是ordering,
// 所以数据需要转换,不再是((String, String), Int),需要展平以下,把Int次数也放到key里面去
val sorted: RDD[((String, String, Int), Null)] = mapedForRepartitionRDD.repartitionAndSortWithinPartitions(partitioner)
println("sorted: " + sorted.collect().toBuffer)
sc.stop()
}
}
class SubjectPartitioner3(val arg: Array[String]) extends Partitioner {
private val indexMap = new mutable.HashMap[String, Int]()
var index = 0
for (elem <- arg) {
indexMap.put(elem, index)
index += 1
}
override def numPartitions: Int = arg.length
override def getPartition(key: Any): Int = {
// 转换之后,key是 (String, String, Int),而value是null,但这里只需要对key做分区
val tuple: (String, String, Int) = key.asInstanceOf[(String, String, Int)]
indexMap(tuple._1)
}
}
运行结果
ArrayBuffer(((javaee,laowang,3),null), ((javaee,xiaozhang,2),null), ((bigdata,laozhao,5),null), ((bigdata,laozhang,2),null), ((bigdata,laoduan,2),null))
这里最关键的就是使用repartitionAndSortWithinPartitions对数据进行分区时,因为本质是对key要求是ordering的,所以数据需要转换,将需要排序的字段转换以下,放到key里面
然后如果所有数据都放到key里面去了,value可以传null来降低数据传输量,降低传输负载,提升性能。
这里隐式参数,因为是针对key来做排序规则,所以这里的类型是(String, String, Int)的
自定义分区器,也是对key做f分区,所以类型也是转换为(String, String, Int)类型
这个代码实现最精髓的就是使用repartitionAndSortWithinPartitions,这样一来,可以将数据按照指定规则(科目)划分到一个区去。再在分区内做排序。
这样的实现跟使用treeset一样,可以避免因为数据过大导致内存紧张问题。因为treeset中只保存top条数据而不是所有的,使用repartitionAndSortWithinPartitions则是在分区内排序,也可以避免数据量过大导致的内存问题。
2.5 代码六
package com.doit.practice
import org.apache.spark.rdd.{RDD, ShuffledRDD}
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import scala.collection.mutable
object TopNTest6 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(TopNTest1.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
// http://javaee.doit.cn/laowang
val rdd1: RDD[String] = sc.textFile("E:\\DOITLearning\\12.Spark\\teacherlog.txt")
// 先把数据做转换
val mapedRDD: RDD[((String, String), Int)] = rdd1.map(line => {
val strings: Array[String] = line.split("\\/+")
val name: String = strings(2)
val domain: String = strings(1)
val domainSplits: Array[String] = domain.split("\\.")
val subject: String = domainSplits(0)
((subject, name), 1)
})
println("mapedRDD: " + mapedRDD.collect().toBuffer)
/**
* mapedRDD: ArrayBuffer(((bigdata,laozhang),1), ((bigdata,laozhang),1), ((bigdata,laozhao),1), ((bigdata,laozhao),1),
* ((bigdata,laozhao),1), ((bigdata,laozhao),1), ((bigdata,laozhao),1), ((bigdata,laoduan),1), ((bigdata,laoduan),1),
* ((javaee,xiaozhang),1), ((javaee,xiaozhang),1), ((javaee,laowang),1), ((javaee,laowang),1), ((javaee,laowang),1))
**/
// 搜集科目信息
val subjects: Array[String] = mapedRDD.map(ele => ele._1._1).distinct().collect()
println("subjects: ")
subjects.foreach(println(_))
// 创建自定义分区器对象
val partitioner = new SubjectPartitioner3(subjects)
// 将转换后数据根据key 聚合
val reducedRDD: RDD[((String, String), Int)] = mapedRDD.reduceByKey(_ + _)
println("reducedRDD: " + reducedRDD.collect().toBuffer)
// 将数据转换为适合repartitionAndSortWithinPartitions 分区并排序的数据,
// 因为需要使得key是ordering的,也就是要排序的字段要在key里面,所以这里做了转换,因为所有数据都在key里面了,所以value为null即可,节省空间
val mapedForRepartitionRDD: RDD[((String, String, Int), Null)] = reducedRDD.map(ele => ((ele._1._1, ele._1._2, ele._2), null))
// 使用repartitionAndSortWithinPartitions进行分区并排序,排序规则使用隐式参数来设置
// 注意,这个隐式参数是为ShuffledRDD针对key要求是ordering而创建的,所以这里其实是key,也就是(String, String, Int)类型
implicit val ord = Ordering[Int].on[(String, String, Int)](t => -t._3)
// repartitionAndSortWithinPartitions 因为这里其实是调用了ShuffledRDD,而排序规则是要求key 是ordering,
// 所以数据需要转换,不再是((String, String), Int),需要展平以下,把Int次数也放到key里面去
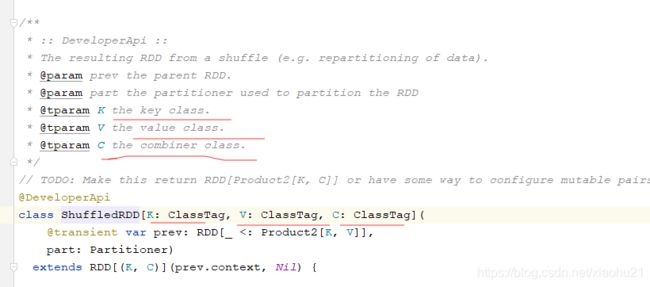
val sorted: ShuffledRDD[(String, String, Int), Null, Null] = new ShuffledRDD[(String, String, Int), Null, Null](mapedForRepartitionRDD, partitioner).setKeyOrdering(ord)
println("sorted: " + sorted.collect().toBuffer)
/*
* ArrayBuffer(((javaee,laowang,3),null), ((javaee,xiaozhang,2),null), ((bigdata,laozhao,5),null), ((bigdata,laozhang,2),null), ((bigdata,laoduan,2),null))
* */
sc.stop()
}
}
class SubjectPartitioner4(val arg: Array[String]) extends Partitioner {
private val indexMap = new mutable.HashMap[String, Int]()
var index = 0
for (elem <- arg) {
indexMap.put(elem, index)
index += 1
}
override def numPartitions: Int = arg.length
override def getPartition(key: Any): Int = {
// 转换之后,key是 (String, String, Int),而value是null,但这里只需要对key做分区
val tuple: (String, String, Int) = key.asInstanceOf[(String, String, Int)]
indexMap(tuple._1)
}
}
运行结果
sorted: ArrayBuffer(((javaee,laowang,3),null), ((javaee,xiaozhang,2),null), ((bigdata,laozhao,5),null), ((bigdata,laozhang,2),null), ((bigdata,laoduan,2),null))
这个代码实现就没有使用使用repartitionAndSortWithinPartitions进行分区排序,而是使用使用repartitionAndSortWithinPartitions底层的ShuffledRDD来排序,这里可以看源码,
第一个参数是key,第二个参数是value,第三个参数是combiner,因为value都是null,不需要combine了,直接null即可。因为这里所有的数据都在key里面了,并且可以根据key进行排序
注意,这里一定要设置keyOrdering参数,否则是不会按照我们预期的进行排序的,而是会按照默认的规则排序,那就不是我们想要的结果了。