1.一脚踹进ViT——Pytorch搭建ViT框架
一脚踹进ViT——Pytorch搭建ViT框架
本系列根据百度飞浆Paddle教程,学习整理后的博客,本文主要使用pytorch对残差网络ResNet18进行实现,首先对代码以及结构搭建进行熟悉,进而介绍简单的机器学习以及tensor使用,最后实现ViT的基本框架,请各位仔细食用!
1.ResNet18的实现
第一部分为了对经典残差网络进行复现,后续ViT中也将残差思想多次运用
1.1 首先,搭建最简单的网络框架
mport torch
import torch.nn as n
def main():
# 定义一个tensor,四个数分别是 batch_size=4,channel=3, 图像宽、高都是32,32
t = torch.randn([4,3,32,32])
# 定义一个ResNet模型类
model = ResNet()
# 打印模型参数供查看
print(model)
# 将输入传入模型得到结果
out = model(t)
print(out.shape)
if __name__=="__main__":
main()
1.2 创建ResNet类
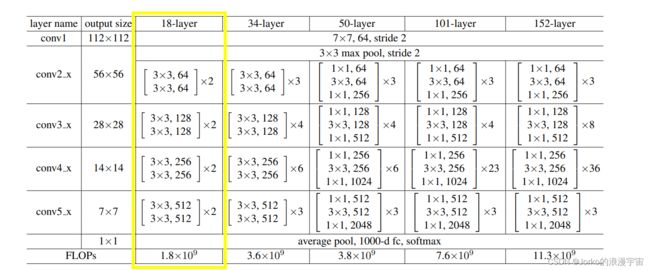
定义好框架后,需要定义ResNet类了,需要定义 init函数和 forward前向传播函数,查看图中结构,输入后经过7×7的卷积,我们实现用3×3的卷积核代替,结构用到的无非就是卷积,最大池化,多个卷积块(其中卷积、BN、激活)、平均池化,因为卷积中仅输出通道不同,以及有多个block堆叠,我们可以定义一个生成卷积层的函数 以及 创建Block的函数 。
对于我们网络的输入通道数设置:in_dim=64,最终假设同MNIST数据集num_classes=10,之前传入的tensor尺寸是28×28的,我们模拟该过程。
class ResNet(nn.Module):
def __init__(self,in_dim=64,num_classes=10):
# 继承父类,记得写
super().__init__()
# 定义所需内容
def forward(self,x):
# 对输入进行处理
return x
def _make_layer(self,dim,n_blocks,stride):
# 构建卷积模块
return nn.Sequential(*layer_list)
接着我们对于每一步进行补充即可
1.2.1 初始化函数定义所需操作
def __init__(self,in_dim=64,num_classes=10):
super().__init__()
self.in_dim = in_dim
self.conv1 = nn.Conv2d(in_channels=3,
out_channels=in_dim,
kernel_size=3,
stride=1,
padding=1,
bias=False)
self.bn1 = nn.BatchNorm2d(in_dim)
self.relu = nn.ReLU()
# 定义blocks,第一个卷积层,输入输出维度不变,后三层其中第一块将图像减半,第二次卷积图像大小不变,每层输出通道数加倍
self.layer1 = self._make_layer(dim=64, n_blocks=2,stride=1)
self.layer2 = self._make_layer(dim=128, n_blocks=2,stride=2)
self.layer3 = self._make_layer(dim=256, n_blocks=2,stride=2)
self.layer4 = self._make_layer(dim=512, n_blocks=2,stride=2)
# head layer
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Linear(512,num_classes) #最终分类
1.2.2 forward构建模块
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
# 对于后面维度进行拉直
x = x.flatten(1)
x = self.classifier(x)
1.3.3 _make_layer函数
def _make_layer(self,dim,n_blocks,stride):
# 定义一个list,存放构建的block,dim是out dim
layer_list = []
layer_list.append(Block(self.in_dim,dim,stride))
self.in_dim = dim
for i in range(1, n_blocks):
layer_list.append(Block(self.in_dim, dim, stride=1))
# 使用* 将list中所有元素取出来 构建层
return nn.Sequential(*layer_list)
1.3 Block块
每个Block块由两次conv bn 以及一个激活函数组成, 对于stride=2 或者 输入维度和输出维度不一样的时候,说明是 第一次构建块或者残差实现时,则加一个下采样层,得到输出维度,否则进行一个恒等映射Indentity(),这个类其实很简单,将输入作为结果进行输出。
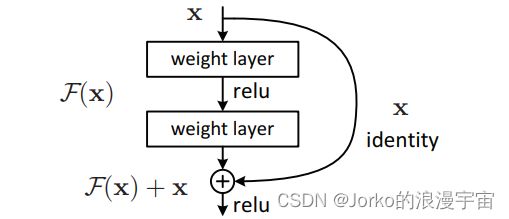
class Block(nn.Module):
def __init__(self,in_dim,out_dim,stride):
super().__init__()
self.conv1 = nn.Conv2d(in_dim,out_dim,3 ,stride=stride,padding=1,bias=False)
self.bn1 = nn.BatchNorm2d(out_dim)
self.conv2= nn.Conv2d(out_dim,out_dim,3 ,stride=1,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(out_dim)
self.relu = nn.ReLU()
if stride == 2 or in_dim != out_dim:
self.downsample = nn.Sequential(*[
nn.Conv2d(in_dim,out_dim,1,stride=stride),
nn.BatchNorm2d(out_dim)])
else:
self.downsample = Indentity()
def forward(self,x):
# 残差实现,将x保留作为h,最终将维度统一后与经过特征提取后的结果相加
h = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
identity = self.downsample(h)
x = x+identity
x = self.relu(x)
return x
这样就构建完成了,最终将Indentity()类一补充就完成了,是不是很清晰呢?
class Indentity(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
return x
看看结果吧?
网络结构输出可以自行输出看一下,我这里放一部分,因为我们的网络太大了!哈哈
输出的Shape:torch.Size([4, 10])
是不是就得到了4个batch,每个中十类的值,最终接个softmax就可以分类了。
2.机器学习
正常情况在数学情况中,2x+1=y ,求x和y;
而机器学习是,ax+b=y,给定(x,y),让你求最优的a和b,而线性函数表示范围比较小,用二次函数能拟合更多情况,那是不是越复杂的函数他就可以表示越多种情况呢?
这个函数就能叫做model,model可以是任意复杂的函数,我们机器学习就是来找最优的参数拟合函数
3.tensor
简单介绍一下pytorch中 tensor的简单构建和操作
from PIL import Image
import numpy as np
import torch
torch.device('cpu')
def main():
# 1. 创建一个tensor
t = torch.zeros([3,3])
print(t)
# 2. 创建一个随机tensor
t = torch.randn([5,3])
print(t)
# 3.从图片中创建一个tensor
# 随机加载一个 28×28的图片,遍历输出
img = np.array(Image.open('ok.jpg'))
for i in range(28):
for j in range(28):
print(f'{img[i,j]:03} ',end='')
print()
t = torch.tensor(img,dtype = torch.float32)
# 4. 打印tensor类型,和tensor的 dtype(里面值的类型)
print(type(t))
print(t.dtype)
# print(t.transpose(1,0))
# 5.chunk 切分
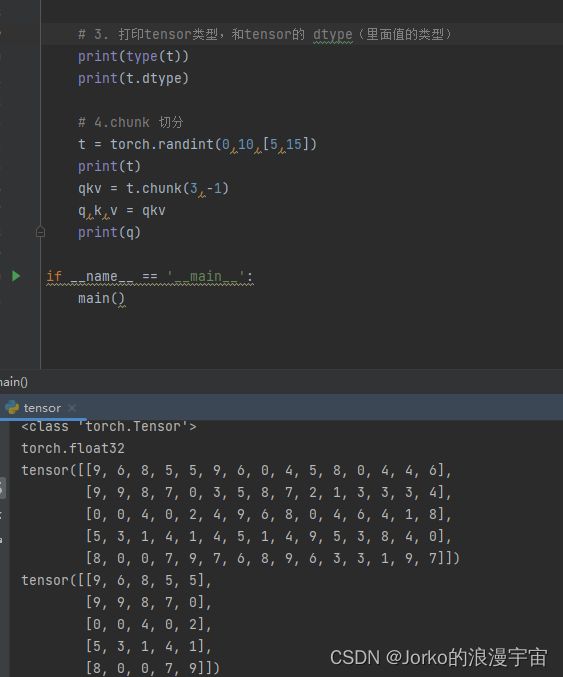
t = torch.randint(0,10,[5,15])
print(t)
qkv = t.chunk(3,-1)
q,k,v = qkv
print(q)
if __name__ == '__main__':
main()
根据代码中五个部分分别查看不同输出来看函数的使用
第一个输出为:
tensor([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]])
第二个输出为:
tensor([[ 0.8475, -0.6581, -0.2290], [ 0.4138, 0.2462, -1.1374], [-0.1824, -1.6705, -0.4217], [ 0.1481, -0.7515, -1.7304], [ 0.2509, -0.1405, 0.2673]])
第三个输出 太大了,如果读取的是MNIST数据集的话,可以根据像素值,远看表示的哪个数字,大家可以试试
第四个输出:
type来表示t的类型是 Tensor,而 dtype是其中的值的类型
第五个输出:
可以看到原始的t被切成三份q,k,v,竖着切了三分,由图可见
4.ViT中 Patch Embedding
ViT中最重要的就是将图像切为Patch块,排成序列后,通过线性映射,通过image tokens输入网络最终得到特征
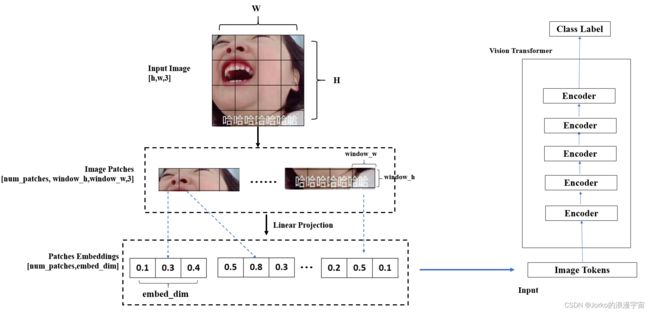
Patch Embedding就作为 image tokens输入网络,进行多个encoder进行特征提取,每一个image token/patch embedding 输入到 transformer中它还会单独输出一个tensor
若输入是 7*7=49个tensor,输出还是49个tensor,那怎么做分类呢?
可以用avgpool取平均,放入head中
接下来就实现Patch Embedding 同样是类似刚ResNet构建思路,搭建框架,主函数中输入一个28×28的图像,然后Patch Embedding就会将图像切为Patch,得到Image Patches后,进行线性投射(可以用卷积来实现,卷积核大小与Patch块大小一样,步长为卷积块大小),可以得到Patch Embeddings,我们embed_dim设置为1,最终得到的就是单个序列
import torch
import torch.nn as nn
from PIL import Image
import numpy as np
class PatchEmbedding(nn.Module):
def __init__(self,image_size, patch_size, in_channels, embed_dim ,dropout=0.):
super().__init__()
self.patch_embed = nn.Conv2d(in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size,
bias=False)
self.patch_embed.weight = nn.Parameter(nn.init.constant_(self.patch_embed.weight,1.0))
self.dropout = nn.Dropout(p=dropout)
def forward(self,x):
# x: [1, 1, 28, 28]
x = self.patch_embed(x)
# x: [n, embed_dim, h', w']
x = x.flatten(2) #后两个维度拉直[n, embed_dim, h'*w']
x = x.permute(0, 2, 1) #[n, h'*w', embed_dim]
x = self.dropout(x)
return x
def main():
# 1. 加载图像并且转化为tensor
img = Image.open('ok.jpg')
img = np.array(img)
for i in range(28):
for j in range(28):
print(f'{img[i, j]:03} ', end='')
print()
sample = torch.tensor(img,dtype=torch.float32)
# 模拟一个batch的数据
sample = sample.reshape([1,1,28,28])
print(sample.shape) #[1,1,28,28]
# 2. Patch Embedding
patch_embed = PatchEmbedding(image_size =28, patch_size=7, in_channels=1,embed_dim=1)
out = patch_embed(sample)
print(out.shape)
print(out)
for i in range(0,28, 7):
for j in range(0, 28, 7):
# 固定卷积核中weight权重为1,卷积后输出与直接将对应位置数字相加后得到的相同
print(torch.sum(sample[0,0,i:i+7, j:j+7]).numpy().item())
if __name__ == '__main__':
main()
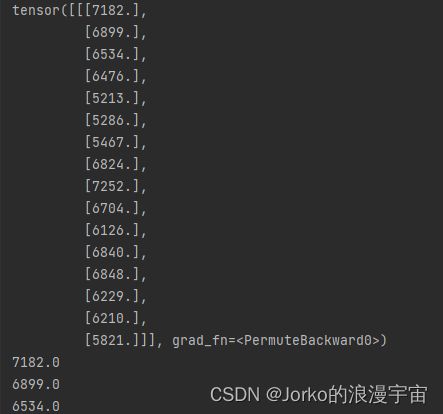
可以看到经过Patch Embedding之后得到的值,与(进行weight全为1)卷积的输出匹配,所以将图像切成了16个 7×7大小的块,tensor的shape为:torch.Size([1, 16, 1]) ,分别是batch_size大小,patch的长度,以及embed_dim维度大小,我们设置的为1。
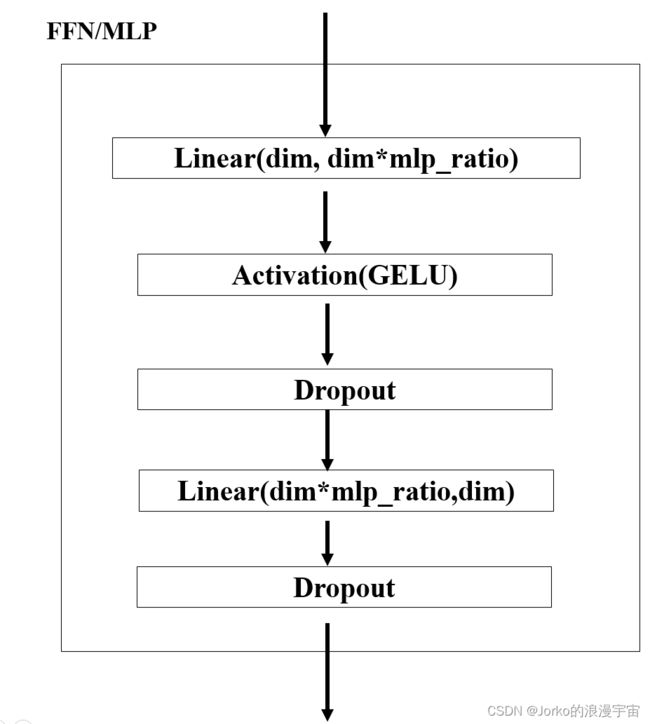
接下来再加个MLP层,初始化 定义参数embed_dim,以及mlp_ratio进行输出维度大小的扩大,使用GELU激活函数
class Indentity(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
return x
class Mlp(nn.Module):
def __init__(self,embed_dim, mlp_ratio=4.0, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(embed_dim, int(embed_dim* mlp_ratio))
self.fc2 = nn.Linear(int(embed_dim* mlp_ratio),embed_dim)
self.act = nn.GELU()
self.dropout = nn.Dropout(p=dropout)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
主函数中加入MLP的调用
# 3.MLP
mlp = Mlp(1)
out = mlp(out)
print('out shape=',out.shape)
输入维度 torch.Size([1, 1, 28, 28])
patch embedding后 torch.Size([1, 16, 1])
经过MLP输出维度out shape= torch.Size([1, 16, 1])
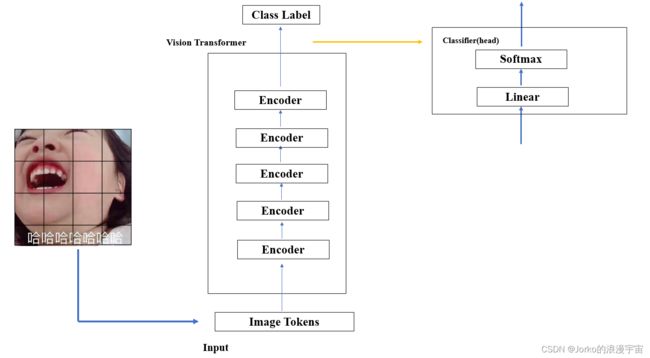
除了MSA没有实现,其实ViT大致已经可以实现了,我们三步走:
-
用卷积操作做 patch Embedding 得到了 Image Tokens
-
实现ViT class,其中实现了五层的Encoder
-
最后用head 头做分类, 一般是Liner接一个Softmax层,本次实现中省掉了softmax,直接拿linear做分类
有了这些在forward中:图像做patch embedding得到了Image Tokens,分别五次前向Encoder,之后经过Linear层
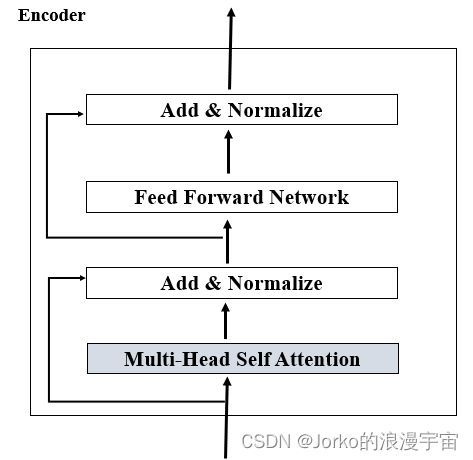
而 Encoder部分,MSA用 TODO代替,暂时先不做,用residual块进行连接,进行LayerNorm,实现了MLP(FFN),之后又实现了residual block,再实现一次LayerNorm。将它复制N次,构成多个Encoder。
定义一个ViT类
import torch
import torch.nn as nn
class Indentity(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
return x
class Mlp(nn.Module):
def __init__(self,embed_dim, mlp_ratio=4.0, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(embed_dim, int(embed_dim* mlp_ratio))
self.fc2 = nn.Linear(int(embed_dim* mlp_ratio),embed_dim)
self.act = nn.GELU()
self.dropout = nn.Dropout(p=dropout)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class PatchEmbedding(nn.Module):
def __init__(self,image_size, patch_size, in_channels, embed_dim ,dropout=0.):
super().__init__()
self.patch_embed = nn.Conv2d(in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size,
bias=False)
self.patch_embed.weight = nn.Parameter(nn.init.constant_(self.patch_embed.weight,1.0))
self.dropout = nn.Dropout(p=dropout)
def forward(self,x):
# x: [1, 1, 28, 28]
x = self.patch_embed(x)
# x: [n, embed_dim, h', w']
x = x.flatten(2) #[n, embed_dim, h'*w']
x = x.permute(0, 2, 1) #[n, h'*w', embed_dim]
x = self.dropout(x)
return x
class Encoder(nn.Module):
def __init__(self,embed_dim):
super().__init__()
self.attn = Indentity() #TODO
self.attn_norm = nn.LayerNorm(embed_dim)
self.mlp = Mlp(embed_dim)
self.mlp_norm = nn.LayerNorm(embed_dim)
def forward(self,x):
h = x
x = self.attn_norm(x)
x = self.attn(x)
x = x+h
h = x
x = self.mlp_norm(x)
x = self.mlp(x)
x = x+h
return x
class ViT(nn.Module):
def __init__(self):
super().__init__()
self.patch_embed = PatchEmbedding(224, 7, 3, 16)
# 存五个Encoder
layer_list = [Encoder(16) for i in range(5)]
self.encoders = nn.ModuleList(layer_list)
self.head = nn.Linear(16, 10) #10:num_classes
self.avgpool = nn.AdaptiveAvgPool1d(1)
def forward(self, x):
x = self.patch_embed(x)
for encoder in self.encoders:
x = encoder(x)
# layernorm
# [n, h'*w', c]
x = x.permute(0, 2, 1)
x = self.avgpool(x) # [n , c , 1]
x = x.flatten(1) # [n, c]
x = self.head(x)
return x
def main():
t = torch.randn([4, 3, 224, 224])
model = ViT()
out = model(t)
print('out shape=',out.shape)
if __name__ == '__main__':
main()
结果:out shape= torch.Size([4, 10])
基本ViT的实现框架形成了,但MSA(Mult-Head Self-Attention)自注意力机制的实现下节进行实现