数据建模初入门笔记
文章目录
-
- 前言:
- 班级成绩案例之大数据分析
-
- 相关矩阵热图
- 柱状图
- 直方图
- 散点图
- UCI 肿瘤数据集之大数据分析
-
- 准备阶段
- 数据集
- 模型训练
- 预测结果
- UCI观影数据集之大数据分析
-
- 读取CSV
- 数据清理
- 统计数据与作图
- Kaggle竞赛之“泰坦尼克号”大数据分析
-
- 准备工作
- 数据清洗
- 探索可视化
- 特征工程
- 基本建模和评估
- 炼丹
- 集成方法
- 预测
前言:
鄙人搞开发和安全的,对这个数据建模有点兴趣。也是第一次参加,然后的话这里面涉及模型的训练。但是预测模型都是组合调参,不会太涉及改网络啥的。着重点是在分析参数以及找到合适的回归模型。
有点人工智能基础,python也算个精通,然后比赛的话发了教程啥的,看了下,然后写了如下笔记。相较于专门打这种的,肯定没有别人专业。但是通过笔记能学到东西,那么目的都达到了。
如果想迅速了解什么是数据建模。建议直接看“泰坦尼克号”大数据分析我尽我努力写完善了,但是还有些代码(尤其是人工智能模型那块)半吊子吧,不能说是熟练。大佬看了笑笑就好~
“泰坦尼克号”大数据分析的资料我放到云盘了。
下载链接 提取码:eand |文章首发于https://sleepymonster.cn/
班级成绩案例之大数据分析
相关矩阵热图
相关系数: https://baike.baidu.com/item/%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0/3109424
相关系数是用以反映变量之间相关关系密切程度的统计指标。
相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度.
# #### Correlation between All Columns
# The 3 most important features for admission to the Master: CGPA, GRE SCORE, and TOEFL SCORE
# The 3 least important features for admission to the Master: Research, LOR, and SOP
fig, ax = plt.subplots(figsize=(10, 10))
sns.heatmap(df.corr(), ax=ax, annot=True, linewidths=0.05, fmt='.2f', cmap='magma')
plt.show()
柱状图
- 数据中分析是否成立可视化
例如: 在这里为是否做过科学研究可视化
这个就很基础,直接放代码。但是效果好丑,excel可以考虑。
y = np.array([len(df[df.Research == 0]),len(df[df.Research == 1])])
x = np.arange(2)
plt.bar(x,y)
plt.title("Research Experience")
plt.xlabel("Canditates")
plt.ylabel("Frequency")
plt.xticks(x,('Not having research','Having research'))
plt.show()
- 统计某项的情况
例如: 在这里为是否托福的最高分 最低分 平均分
y = np.array([df['TOEFL Score'].min(),df['TOEFL Score'].mean(),df['TOEFL Score'].max()])
x = np.arange(3)
plt.bar(x,y)
plt.title('TOEFL Score')
plt.xlabel('Level')
plt.ylabel('TOEFL Score')
plt.xticks(x,('Worst','Average','Best'))
plt.show()
直方图
- 统计直方图
例如:绘制 GRE 成绩直方图
df['GRE Score'].plot(kind='hist',bins=200,figsize=(6,6))
plt.title('GRE Score')
plt.xlabel('GRE Score')
plt.ylabel('Frequency')
plt.show()
散点图
参考链接: https://baike.baidu.com/item/%E6%95%A3%E7%82%B9%E5%9B%BE
判断两变量之间是否存在某种关联或总结坐标点的分布模式
例如:学校排名与CGPA的散点图
plt.scatter(df['University Rating'],df['CGPA'])
plt.title('CGPA Scores for University ratings')
plt.xlabel('University Rating')
plt.ylabel('CGPA')
plt.show()
UCI 肿瘤数据集之大数据分析
准备阶段
- 拿到数据集
数据库来源:https://archive.ics.uci.edu/ml/datasets.php
- ID确定 2 .结果确定 3. 指标确定
- 包装的机器学习库 scikit-learn
官方地址: https://scikit-learn.org/stable/
数据集
- 导入数据集并且处理
import pandas as pd
column_names = ['Sample code number','Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class'] # 创建特征列表
data = pd.read_csv('./breast-cancer-wisconsin.data',names=column_names)
print(data)
- 处理数据集
#将?替换为标准缺失值表示
data = data.replace(to_replace='?',value = np.nan)
print(data)
#丢弃带有缺失值的数据(只要有一个维度有缺失便丢弃)
# 这里的意思就是数据不全 缺少某一列啥的
data = data.dropna(how='any')
#查看data的数据量和维度
print(data.shape)
- 分割数据集
#使用sklearn.cross_validation里的train_test_split模块分割数据集
from sklearn.model_selection import train_test_split
#随机采样25%的数据用于测试,剩下的75%用于构建训练集
X_train,X_test,y_train,y_test = train_test_split(data[column_names[1:10]],data[column_names[10]],test_size = 0.25,random_state = 33)
# 这里的X为前面10列再切割1:3
#查看训练样本的数量和类别分布
print(y_train.value_counts())
#查看测试样本的数量和类别分布
print(y_test.value_counts())
模型训练
#从sklearn.preprocessing导入StandardScaler
from sklearn.preprocessing import StandardScaler # StandardScaler归一化 是数据方差为1
#从sklearn.linear_model导入LogisticRegression(逻辑斯蒂回归)
from sklearn.linear_model import LogisticRegression
#从sklearn.linear_model导入SGDClassifier(随机梯度参数)
from sklearn.linear_model import SGDClassifier #标准化数据,保证每个维度的特征数据方差为1,均值为,使得预测结果不会被某些过大的特征值而主导(在机器学习训练之前, 先对数据预先处理一下, 取值跨度大的特征数据,
我们浓缩一下, 跨度小的括展一下, 使得他们的跨度尽量统一.)
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test) #初始化两种模型
lr = LogisticRegression() # 调用逻辑斯蒂回归 学习率
lr.fit(X_train,y_train) # 使用fit函数训练模型参数 把训练集来拟合
lr_y_predict = lr.predict(X_test) #此时的lr已经训练过了 调用predict来预测测试集
sgdc = SGDClassifier() # 随机梯度参数 分类器
sgdc.fit(X_train,y_train) #调用随机梯度的fit函数优化
sgdc_y_predict = sgdc.predict(X_test) # 使用训练好的模型sgdc对X_test进行预测,结果储存在变量sgdc_y_predict中
print(sgdc_y_predict)
预测结果
# 从sklearn.metrics导入classification_report
from sklearn.metrics import classification_report
# 使用逻辑斯蒂回归模型自带的评分函数score获得模型在测试集上的准确性结果
print('Accuracy of LR Classifier:', lr.score(X_test, y_test)) # 这个score的意思可以理解为 输入了X_test 经过lr等与y_test比对 然后最后返回正确率的包装。
# 使用classification_report模块获得逻辑斯蒂模型其他三个指标的结果(召回率,精确率,调和平均数)
print(classification_report(y_test, lr_y_predict, target_names=['Benign', 'Malignant']))
#使用随机梯度下降模型自带的评分函数score获得模型在测试集上的准确性结果
print('Accuarcy of SGD Classifier:',sgdc.score(X_test,y_test))
##使用classification_report模块获得随机梯度下降模型其他三个指标的结果
print(classification_report(y_test,sgdc_y_predict,target_names=['Benign','Malignant']))
UCI观影数据集之大数据分析
读取CSV
import warnings
warnings.filterwarnings('ignore')#忽略警告
movie = pd.read_csv('movies.csv')
credit = pd.read_csv('credits.csv')
# 不写数字默认是5行
print(movie.head(1)) # 从第一条数据读取1条
print(movie.tail(3)) # 从末尾数据读取3条
print(movie.info()) # 查看信息
数据清理
#数据清理
#movie genres电影流派,便于归类
movie['genres']=movie['genres'].apply(json.loads) #apply function to axis in df, 对df中某一行、列应用某种操作。
print(movie['genres'].head())
print(list(zip(movie.index,movie['genres']))[:2])
# 重新规整电影流派
# [{'id': 35, 'name': 'Comedy'}, {'id': 18, 'name': 'Drama'}, {'id': 10749, 'name': 'Romance'}, {'id': 10770, 'name': 'TV Movie'}] => ['Comedy', 'Drama', 'Romance', 'TV Movie']
for index, i in zip(movie.index, movie['genres']):
genresList = [each["name"] for each in i]
movie.loc[index, 'genres'] = str(genresList)
# 还可以添加新的列
# 提取crew中director,增加电影导演一列,用作后续分析
def director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
credit['crew']=credit['crew'].apply(director) # 传入函数
credit.rename(columns={'crew':'director'},inplace=True) # 更改名称
# 数据合并
# 观察movie中id和credit中movie_id相同,可以将两个表合并,将所有信息统一在一个表中。
fulldf = pd.merge(movie,credit,left_on='id',right_on='movie_id',how='left')
print(fulldf.head(1))
print(fulldf.shape)
# 杂七杂八完善表格
#观察到有相同列title,合并后自动命名成title_x,title_y
fulldf.rename(columns={'title_x':'title'},inplace=True)
fulldf.drop('title_y',axis=1,inplace=True)
#缺失值
NAs = pd.DataFrame(fulldf.isnull().sum())
NAs[NAs.sum(axis=1)>0].sort_values(by=[0],ascending=False)
#补充release_date
fulldf.loc[fulldf['release_date'].isnull(),'title'] # 不知道这句话的作用处
#上网查询补充
fulldf['release_date']=fulldf['release_date'].fillna('2014-06-01')
#runtime为电影时长,按均值补充
fulldf['runtime'] = fulldf['runtime'].fillna(fulldf['runtime'].mean())
#为方便分析,将release_date(object)转为datetime类型,并提取year,month
fulldf['release_year'] = pd.to_datetime(fulldf['release_date'],format='%Y-%m-%d').dt.year
fulldf['release_month'] = pd.to_datetime(fulldf['release_date'],format='%Y-%m-%d').dt.month
统计数据与作图
# 统计出现种类最多的排名前10
# 电影类型genres
# 观察其格式,我们需要做str相关处理,先移除两边中括号
# 相邻类型间有空格,需要移除
# 再移除单引号,并按,分割提取即可
fulldf['genres']=fulldf['genres'].str.strip('[]').str.replace(" ","").str.replace("'","")
fulldf['genres']=fulldf['genres'].str.split(',')
allList=[]
for i in fulldf['genres']:
allList.extend(i)
gen_list=pd.Series(allList).value_counts()[:10].sort_values(ascending=False)
gen_df = pd.DataFrame(gen_list)
gen_df.rename(columns={0:'Total'},inplace=True) # 就一列 给第一列重新命名
# 画图
plt.subplots(figsize=(10,8))
sns.barplot(y=gen_df.index,x='Total',data=gen_df,palette='GnBu_d')
plt.xticks(fontsize=15)#设置刻度字体大小
plt.yticks(fontsize=15)
plt.xlabel('Total',fontsize=15)
plt.ylabel('Genres',fontsize=15)
plt.title('Top 10 Genres',fontsize=20)
plt.show()
# 统计年份与电影种类的关系
# 对电影类型去重
l=[] # l就是去重后的电影类型
for i in list1:
if i not in l:
l.append(i)
year_min = fulldf['release_year'].min()
year_max = fulldf['release_year'].max()
year_genr =pd.DataFrame(index=l,columns=range(year_min,year_max+1))
year_genr.fillna(value=0,inplace=True)#初始值为0
intil_y = np.array(fulldf['release_year'])#用于遍历所有年份
z = 0
for i in fulldf['genres']:
splt_gen = list(i) # 每一部电影的所有类型
for j in splt_gen:
year_genr.loc[j,intil_y[z]] = year_genr.loc[j,intil_y[z]]+1#计数该类型电影在某一年份的数量
z+=1
year_genr = year_genr.sort_values(by=2006, ascending=False)
year_genr = year_genr.iloc[0:10, -49:-1]
plt.subplots(figsize=(10,8))
plt.plot(year_genr.T)
plt.title('Genres vs Time',fontsize=20)
plt.xticks(range(1969,2020,5))
plt.legend(year_genr.T)
plt.show()
Kaggle竞赛之“泰坦尼克号”大数据分析
准备工作
# 这些代码都是发下来的
# 我添加上对应的注释
# 好明白在干什么 更好的学习
# 将发下来的训练集以及数据集合并
train=pd.read_csv('./Data/train.csv')
test=pd.read_csv('./Data/test.csv')
full=pd.concat([train,test],ignore_index=True,sort=False) # 在下面叠加并且不排序
full.head() # 查看前5行看看是不是我想要的数据
数据清洗
首先来看缺失数值:Age,Cabin,Embarked,Fare这些变量存在缺失值(Survived是预测值)。
对于缺失值较少的,可以选择众数和中位数进行插补。
对于缺失值较多的,可以考虑有的与没有的跟最后是否生存情况。
可以发现有Cabin数据的乘客的存活率远高于无Cabin数据的乘客,所以我们可以将Cabin的有无数据作为一个特征。
对于Age的缺失值有263个。通过相关系数图发现相关性并不高,则无法预测。
根据名字中的称呼来预测年龄。
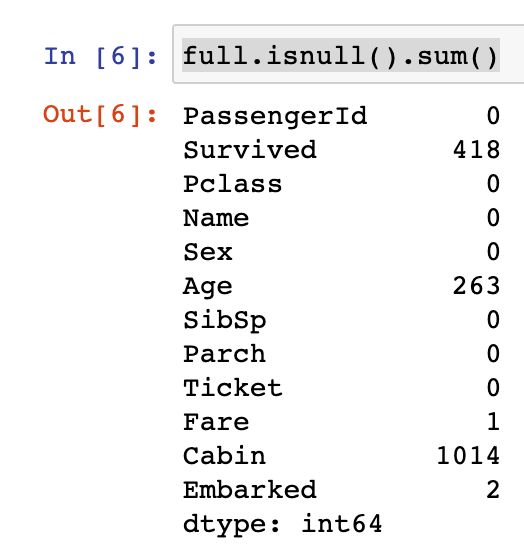
# 挑选出数据集缺失的总和
full.isnull().sum()
# 处理Embarked缺失的2个
full.Embarked.mode() # 取众数 # 参考链接:https://segmentfault.com/q/1010000008252098
full['Embarked'].fillna('S',inplace=True) # 用众数填充到缺失的部分
# 处理Fare缺失的一个
full[full.Fare.isnull()] # 找出缺失那一个的数据
# 发现是属于Pclass为3的,则去找为3的Fare的中位数
full.Fare.fillna(full[full.Pclass==3]['Fare'].median(),inplace=True) # 用中位数填充
# 发现Cabin缺的太多了,那么存在Cabin与不存在的最后的存活率
full.loc[full.Cabin.notnull(),'Cabin']=1
full.loc[full.Cabin.isnull(),'Cabin']=0
# 画图展示
pd.pivot_table(full,index=['Cabin'],values=['Survived']).plot.bar(figsize=(8,5))
plt.title('Survival Rate')
# 展示 是否存活与是否Cabin的数量
cabin=pd.crosstab(full.Cabin,full.Survived) # Crosstab 交叉列表取值 参考链接:https://learnku.com/articles/27452
cabin.rename(index={0:'no cabin',1:'cabin'},columns={0.0:'Dead',1.0:'Survived'},inplace=True)
cabin # 看一下
# 转换为图形
cabin.plot.bar(figsize=(8,5))
plt.xticks(rotation=0,size='xx-large')
plt.title('Survived Count')
plt.xlabel('')
plt.legend()
# 开始处理age
# age可以从名字中的称呼来计算例如Mr.
full['Title']=full['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip()) # 切割名字
full.Title.value_counts() # 看一下统计数量
full[(full.Title=='Dr')&(full.Sex=='female')] # 找出唯一那个Dr但是是女性的
nn={'Capt':'Rareman', 'Col':'Rareman','Don':'Rareman','Dona':'Rarewoman',
'Dr':'Rareman','Jonkheer':'Rareman','Lady':'Rarewoman','Major':'Rareman',
'Master':'Master','Miss':'Miss','Mlle':'Rarewoman','Mme':'Rarewoman',
'Mr':'Mr','Mrs':'Mrs','Ms':'Rarewoman','Rev':'Mr','Sir':'Rareman',
'the Countess':'Rarewoman'} # 建立映射
full.Title=full.Title.map(nn) # 把花里胡哨的名称换下来
full.loc[full.PassengerId==797,'Title']='Rarewoman' # 单独把那一个人换一下
full.Title.value_counts() # 重新观察下
full[full.Title=='Master']['Sex'].value_counts() # Master不知道指的啥看下性别
full[full.Title=='Master']['Age'].describe() # 看下Master下的年龄各个指标
# 最后发现了“主人”主要代表小男孩,但是同时需要找小女孩 因为当时的Sex只有男孩
# 那就到Miss中去寻找 如果这个Miss缺少了年龄
# 开始处理Miss中的小女孩年龄
full.Age.fillna(999,inplace=True) # 把缺少年龄的先设置为999
# 函数进行筛选
def girl(aa):
if (aa.Age!=999)&(aa.Title=='Miss')&(aa.Age<=14):
return 'Girl'
elif (aa.Age==999)&(aa.Title=='Miss')&(aa.Parch!=0):
return 'Girl'
else:
return aa.Title
full['Title']=full.apply(girl,axis=1) # 使用函数
full.Title.value_counts() # 发现Girl出现了
full[full.Age==999]['Age'].value_counts()
Tit=['Mr','Miss','Mrs','Master','Girl','Rareman','Rarewoman']
for i in Tit:
full.loc[(full.Age==999)&(full.Title==i),'Age']=full.loc[full.Title==i,'Age'].median() # 把缺失的赋值为中位数
full.info() # 恭喜 全部1309条数据根据逻辑补充完整
探索可视化
- 普遍认为泰坦尼克号中女人的存活率远高于男人
- 显示年龄与存活人数的关系,可以看出小于5岁的小孩存活率很高
- 客舱等级(Pclass)自然也与存活率有很大关系
# 这里就是不停的试
# 用不同的图来展示各种关系
# 根据Title查看年龄分布
full.groupby(['Title'])[['Age','Title']].mean().plot(kind='bar',figsize=(8,5))
plt.xticks(rotation=0)
plt.show()
# 女的比男的生存高
pd.crosstab(full.Sex,full.Survived).plot.bar(stacked=True,figsize=(8,5),color=['#4169E1','#FF00FF'])
plt.xticks(rotation=0,size='large')
plt.legend(bbox_to_anchor=(0.55,0.9))
# 年龄和存活的关系
agehist=pd.concat([full[full.Survived==1]['Age'],full[full.Survived==0]['Age']],axis=1)
agehist.columns=['Survived','Dead']
agehist.plot(kind='hist',bins=30,figsize=(15,8),alpha=0.3)
# Fare与Survived关系
farehist=pd.concat([full[full.Survived==1]['Fare'],full[full.Survived==0]['Fare']],axis=1)
farehist.columns=['Survived','Dead']
farehist.head()
# 根据Title查看死亡分布
full.groupby(['Title'])[['Title','Survived']].mean().plot(kind='bar',figsize=(10,7))
plt.xticks(rotation=0)
# 将性别与Pclass结合来看生存
fig,axes=plt.subplots(2,3,figsize=(15,8)) # 2 x 3
Sex1=['male','female']
for i,ax in zip(Sex1,axes):
for j,pp in zip(range(1,4),ax):
PclassSex=full[(full.Sex==i)&(full.Pclass==j)]['Survived'].value_counts().sort_index(ascending=False)
pp.bar(range(len(PclassSex)),PclassSex,label=(i,'Class'+str(j)))
pp.set_xticks((0,1))
pp.set_xticklabels(('Survived','Dead'))
pp.legend(bbox_to_anchor=(0.6,1.1))
特征工程
由于训练集和测试集的数量过少,容易产生过拟合。
根据可视化探索出来的特征变量来处理特征。
# 根据探索出来的特征值做进一步的处理
full.AgeCut=pd.cut(full.Age,5) # create age bands
full.FareCut=pd.qcut(full.Fare,5) # create fare bands
full.AgeCut.value_counts().sort_index() # 可以对每个值进行计数并且排序
full.FareCut.value_counts().sort_index()
# 处理年龄
full.loc[full.Age<=16.136,'AgeCut']=1
full.loc[(full.Age>16.136)&(full.Age<=32.102),'AgeCut']=2
full.loc[(full.Age>32.102)&(full.Age<=48.068),'AgeCut']=3
full.loc[(full.Age>48.068)&(full.Age<=64.034),'AgeCut']=4
full.loc[full.Age>64.034,'AgeCut']=5
# 处理Fare
full.loc[full.Fare<=7.854,'FareCut']=1
full.loc[(full.Fare>7.854)&(full.Fare<=10.5),'FareCut']=2
full.loc[(full.Fare>10.5)&(full.Fare<=21.558),'FareCut']=3
full.loc[(full.Fare>21.558)&(full.Fare<=41.579),'FareCut']=4
full.loc[full.Fare>41.579,'FareCut']=5
full[['FareCut','Survived']].groupby(['FareCut']).mean().plot.bar(figsize=(8,5))
full.corr() # 查看相关系数
full[full.Survived.notnull()].pivot_table(index=['Title','Pclass'],values=['Survived']).sort_values('Survived',ascending=False) # 查看Pclass相关
full[full.Survived.notnull()].pivot_table(index=['Title','Parch'],values=['Survived']).sort_values('Survived',ascending=False) # 查看Parch相关
TPP=full[full.Survived.notnull()].pivot_table(index=['Title','Pclass','Parch'],values=['Survived']).sort_values('Survived',ascending=False)
TPP # 加维度看相关
# From the plot, we can draw some horizontal lines and make some classification. I only choose 80% and 50%, because I'm so afraid of overfitting.
TPP.plot(kind='bar',figsize=(16,10))
plt.xticks(rotation=40)
plt.axhline(0.8,color='#BA55D3')
plt.axhline(0.5,color='#BA55D3')
plt.annotate('80% survival rate',xy=(30,0.81),xytext=(32,0.85),arrowprops=dict(facecolor='#BA55D3',shrink=0.05))
plt.annotate('50% survival rate',xy=(32,0.51),xytext=(34,0.54),arrowprops=dict(facecolor='#BA55D3',shrink=0.05))
# use 'Title','Pclass','Parch' to generate feature 'TPP'.
Tit=['Girl','Master','Mr','Miss','Mrs','Rareman','Rarewoman']
for i in Tit:
for j in range(1,4):
for g in range(0,10): # 0.8与0.5是选择的分界线
if full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g)&(full.Survived.notnull()),'Survived'].mean()>=0.8:
full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g),'TPP']=1
elif full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g)&(full.Survived.notnull()),'Survived'].mean()>=0.5:
full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g),'TPP']=2
elif full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g)&(full.Survived.notnull()),'Survived'].mean()>=0:
full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g),'TPP']=3
else:
full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g),'TPP']=4
# 查看'Title','Pclass','Parch'都毫无相关性的
full[full.TPP==4]
# 单独处理拿回到数据集中
full.loc[(full.TPP==4)&(full.Sex=='female')&(full.Pclass!=3),'TPP']=1
full.loc[(full.TPP==4)&(full.Sex=='female')&(full.Pclass==3),'TPP']=2
full.loc[(full.TPP==4)&(full.Sex=='male')&(full.Pclass!=3),'TPP']=2
full.loc[(full.TPP==4)&(full.Sex=='male')&(full.Pclass==3),'TPP']=3
# 看看处理了特征值之后
full.TPP.value_counts()
基本建模和评估
开始选择算法,做交叉验证,最后取最好的结果。
-
K近邻(k-Nearest Neighbors)
-
逻辑回归(Logistic Regression)
-
朴素贝叶斯分类器(Naive Bayes classifier)
-
决策树(Decision Tree)
-
随机森林(Random Forest)
-
梯度提升树(Gradient Boosting Decision Tree)
-
支持向量机(Support Vector Machine)
由于K近邻和支持向量机对数据的scale敏感,所以先进行标准化(standard-scaling)
选择比较不错的模型之后,接下来可以挑选一个模型进行错误分析
提取该模型中错分类的观测值,寻找其中规律进而提取新的特征,以图提高整体准确率
predictors=['Cabin','Embarked','Parch','Pclass','Sex','SibSp','Title','AgeCut','TPP','FareCut','Age','Fare']
# 可以看到 相比较于最开始的
# 新加了'Title','AgeCut','TPP','FareCut'
# 不要了 ID Name Ticket
full_dummies=pd.get_dummies(full[predictors]) 将分类变量转换为数值变量
full_dummies.head() # 这下都是处理后的一些数值了
炼丹
调整参数,时间与运气的集合。
# 为了有点区分度
# 我把模型的代码放到这里来了
from sklearn.model_selection import cross_val_score
# 对应7中模型
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.svm import SVC
models=[KNeighborsClassifier(),LogisticRegression(),GaussianNB(),DecisionTreeClassifier(),RandomForestClassifier(),
GradientBoostingClassifier(),SVC()]
full.shape,full_dummies.shape
# 数据集划分
X=full_dummies[:891]
y=full.Survived[:891]
test_X=full_dummies[891:]
# As some algorithms such as KNN and SVM are sensitive to the scaling of the data, here we also apply standard-scaling to the data.
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_scaled=scaler.fit(X).transform(X)
test_X_scaled=scaler.fit(X).transform(test_X)
# 开始训练模型
# sklearn都是高度包装的
# 完全不用担心去修改模型
# 最多就是打组合拳看效果
names=['KNN','LR','NB','Tree','RF','GDBT','SVM']
for name, model in zip(names,models):
score=cross_val_score(model,X,y,cv=5)
print("{}:{},{}".format(name,score.mean(),score))
# used scaled data
# 也就是用标准化后的数据
names=['KNN','LR','NB','Tree','RF','GDBT','SVM']
for name, model in zip(names,models):
score=cross_val_score(model,X_scaled,y,cv=5)
print("{}:{},{}".format(name,score.mean(),score))
# 使用GradientBoostingClassifier中的(特征重要性)来查看哪些特征是重要的。
model=GradientBoostingClassifier()
model.fit(X,y)
model.feature_importances_
fi=pd.DataFrame({'importance':model.feature_importances_},index=X.columns)
fi.sort_values('importance',ascending=False)
fi.sort_values('importance',ascending=False).plot.bar(figsize=(11,7))
plt.xticks(rotation=30)
plt.title('Feature Importance',size='x-large') # Based on the bar plot, 'TPP','Fare','Age' are the most important.
# 现在的准确度不满意,那就最小化错误分类的观察结果。
# 因此,如果所有的错误分类的观察发现,也许我们可以看到模式和生成一些新的特征。
# 使用交叉验证来搜索分类错误的观察结果
# 后面的好像环境不对 只能将就看了
from sklearn.model_selection import KFold
kf=KFold(n_splits=10,random_state=1)
kf.get_n_splits(X)
print(kf)
# 提取误分类的指标
rr=[]
for train_index, val_index in kf.split(X):
pred=model.fit(X.loc[train_index],y[train_index]).predict(X.loc[val_index])
rr.append(y[val_index][pred!=y[val_index]].index.values)
# combine all the indices
whole_index=np.concatenate(rr)
len(whole_index)
full.loc[whole_index].head()
diff=full.loc[whole_index]
diff.describe()
diff.describe(include=['O'])
diff.groupby(['Title'])['Survived'].agg([('average','mean'),('number','count')]) # “幸存”的平均值和计数都应该被考虑。
diff.groupby(['Title','Pclass'])['Survived'].agg([('average','mean'),('number','count')]) # 分出来还不够详细
diff.groupby(['Title','Pclass','Parch','SibSp'])['Survived'].agg([('average','mean'),('number','count')])
# 优化模型 根据上面的分析
# 创建MPPS模型即'Mx','Pclass','Parcc','SibSp'
full.loc[(full.Title=='Mr')&(full.Pclass==1)&(full.Parch==0)&((full.SibSp==0)|(full.SibSp==1)),'MPPS']=1
full.loc[(full.Title=='Mr')&(full.Pclass!=1)&(full.Parch==0)&(full.SibSp==0),'MPPS']=2
full.loc[(full.Title=='Miss')&(full.Pclass==3)&(full.Parch==0)&(full.SibSp==0),'MPPS']=3
full.MPPS.fillna(4,inplace=True) # 剩下没涉及到的为4
full.MPPS.value_counts()
# 从2个中找一下 还有不有特征
diff[(diff.Title=='Mr')|(diff.Title=='Miss')].groupby(['Title','Survived','Pclass'])[['Fare']].describe().unstack()
full[(full.Title=='Mr')|(full.Title=='Miss')].groupby(['Title','Survived','Pclass'])[['Fare']].describe().unstack()
# 使用矩阵热图来看
colormap = plt.cm.viridis
plt.figure(figsize=(12,12))
plt.title('Pearson Correlation of Features', y=1.05, size=20)
sns.heatmap(full[['Cabin','Parch','Pclass','SibSp','AgeCut','TPP','FareCut','Age','Fare','MPPS','Survived']].astype(float).corr(),linewidths=0.1,vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True)
# 新的特征值
predictors=['Cabin','Embarked','Parch','Pclass','Sex','SibSp','Title','AgeCut','TPP','FareCut','Age','Fare','MPPS']
full_dummies=pd.get_dummies(full[predictors])
# 处理数据集
X=full_dummies[:891]
y=full.Survived[:891]
test_X=full_dummies[891:]
# 标准化数据
scaler=StandardScaler()
X_scaled=scaler.fit(X).transform(X)
test_X_scaled=scaler.fit(X).transform(test_X)
# 开始用模型对新的特征值训练
from sklearn.model_selection import GridSearchCV
# k-Nearest Neighbors
param_grid={'n_neighbors':[1,2,3,4,5,6,7,8,9]}
grid_search=GridSearchCV(KNeighborsClassifier(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
# Logistic Regression¶
param_grid={'C':[0.01,0.1,1,10]}
grid_search=GridSearchCV(LogisticRegression(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
# second round grid search
param_grid={'C':[0.04,0.06,0.08,0.1,0.12,0.14]}
grid_search=GridSearchCV(LogisticRegression(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
# Support Vector Machine
param_grid={'C':[0.01,0.1,1,10],'gamma':[0.01,0.1,1,10]}
grid_search=GridSearchCV(SVC(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
#second round grid search
param_grid={'C':[2,4,6,8,10,12,14],'gamma':[0.008,0.01,0.012,0.015,0.02]}
grid_search=GridSearchCV(SVC(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
# Gradient Boosting Decision Tree
param_grid={'n_estimators':[30,50,80,120,200],'learning_rate':[0.05,0.1,0.5,1],'max_depth':[1,2,3,4,5]}
grid_search=GridSearchCV(GradientBoostingClassifier(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
#second round search
param_grid={'n_estimators':[100,120,140,160],'learning_rate':[0.05,0.08,0.1,0.12],'max_depth':[3,4]}
grid_search=GridSearchCV(GradientBoostingClassifier(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
集成方法
用了逻辑回归、K近邻、支持向量机、梯度提升树作为第一层模型,随机森林作为第二层模型。
总的来说根据交叉验证的结果,集成算法并没有比单个算法提升太多,原因可能是:
-
个数据集太小,模型没有得到充分的训练
-
集成方法中子模型的相关性太强
-
集成方法可能本身也需要调参
# 我们使用逻辑回归与参数调整来应用bagging
from sklearn.ensemble import BaggingClassifier
bagging=BaggingClassifier(LogisticRegression(C=0.06),n_estimators=100)
# 上面选出比较好的模型
from sklearn.ensemble import VotingClassifier
clf1=LogisticRegression(C=0.06)
clf2=RandomForestClassifier(n_estimators=500)
clf3=GradientBoostingClassifier(n_estimators=120,learning_rate=0.12,max_depth=4)
clf4=SVC(C=4,gamma=0.015,probability=True)
clf5=KNeighborsClassifier(n_neighbors=8)
eclf_hard=VotingClassifier(estimators=[('LR',clf1),('RF',clf2),('GDBT',clf3),('SVM',clf4),('KNN',clf5)])
eclfW_hard=VotingClassifier(estimators=[('LR',clf1),('RF',clf2),('GDBT',clf3),('SVM',clf4), ('KNN',clf5)],weights=[1,1,2,2,1]) # 添加权重
eclf_soft=VotingClassifier(estimators=[('LR',clf1),('RF',clf2),('GDBT',clf3),('SVM',clf4),('KNN',clf5)],voting='soft') # soft voting
eclfW_soft=VotingClassifier(estimators=[('LR',clf1),('RF',clf2),('GDBT',clf3),('SVM',clf4),('KNN',clf5)],voting='soft',weights=[1,1,2,2,1]) # 添加权重
models=[KNeighborsClassifier(n_neighbors=8),LogisticRegression(C=0.06),GaussianNB(),DecisionTreeClassifier(),RandomForestClassifier(n_estimators=500),
GradientBoostingClassifier(n_estimators=120,learning_rate=0.12,max_depth=4),SVC(C=4,gamma=0.015),
eclf_hard,eclf_soft,eclfW_hard,eclfW_soft,bagging] # 一共有12个
names=['KNN','LR','NB','CART','RF','GBT','SVM','VC_hard','VC_soft','VCW_hard','VCW_soft','Bagging']
for name,model in zip(names,models):
score=cross_val_score(model,X_scaled,y,cv=5)
print("{}: {},{}".format(name,score.mean(),score))
# 组合拳
from sklearn.model_selection import StratifiedKFold
n_train=train.shape[0]
n_test=test.shape[0]
kf=StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
def get_oof(clf,X,y,test_X):
oof_train=np.zeros((n_train,))
oof_test_mean=np.zeros((n_test,))
oof_test_single=np.empty((5,n_test))
for i, (train_index,val_index) in enumerate(kf.split(X,y)):
kf_X_train=X[train_index]
kf_y_train=y[train_index]
kf_X_val=X[val_index]
clf.fit(kf_X_train,kf_y_train)
oof_train[val_index]=clf.predict(kf_X_val)
oof_test_single[i,:]=clf.predict(test_X)
oof_test_mean=oof_test_single.mean(axis=0)
return oof_train.reshape(-1,1), oof_test_mean.reshape(-1,1)
LR_train,LR_test=get_oof(LogisticRegression(C=0.06),X_scaled,y,test_X_scaled)
KNN_train,KNN_test=get_oof(KNeighborsClassifier(n_neighbors=8),X_scaled,y,test_X_scaled)
SVM_train,SVM_test=get_oof(SVC(C=4,gamma=0.015),X_scaled,y,test_X_scaled)
GBDT_train,GBDT_test=get_oof(GradientBoostingClassifier(n_estimators=120,learning_rate=0.12,max_depth=4),X_scaled,y,test_X_scaled)
# 第一层
X_stack=np.concatenate((LR_train,KNN_train,SVM_train,GBDT_train),axis=1)
y_stack=y
X_test_stack=np.concatenate((LR_test,KNN_test,SVM_test,GBDT_test),axis=1)
# 第二层
stack_score=cross_val_score(RandomForestClassifier(n_estimators=1000),X_stack,y_stack,cv=5)
stack_score.mean(),stack_score
预测
pred=RandomForestClassifier(n_estimators=500).fit(X_stack,y_stack).predict(X_test_stack)
tt=pd.DataFrame({'PassengerId':test.PassengerId,'Survived':pred})
tt.to_csv('G.csv',index=False)