A股实践 :图神经网络与新闻共现矩阵策略(附代码)

量化投资与机器学习微信公众号,是业内垂直于量化投资、对冲基金、Fintech、人工智能、大数据等领域的主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险、高校等行业30W+关注者,荣获2021年度AMMA优秀品牌力、优秀洞察力大奖,连续2年被腾讯云+社区评选为“年度最佳作者”。
量化投资与机器学习公众号独家撰写
感谢ChinaScope对本文提供数据支持
核心观点
本文在Qlib已实现的图神经网络模型GATs上进行改进,引入以基于数库SmarTag新闻分析数据的共现矩阵作为显性图关系;
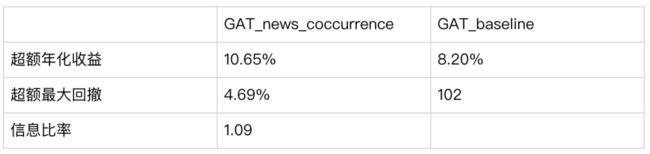
实证结果证明,引入新闻共现矩阵的GATs模型,相对沪深300指数,有11%的超额年化收益;
相比Qlib原始的GATs模型,也有4%的超额收益。
前言
深度学习已经广泛的应用于量化投资研究,特别是基于因子模型的量化策略研究。传统的多因子模型是基于截面上的因子暴露与预测目标(超额收益)之间的线性关系,对股票未来的收益进行预测。于是,策略的竞争实则变成的因子挖掘的竞争。深度学习模型的出现,在输入不变的情况下,为我们带来了另一个维度的创新:更多的挖掘因子与预测目标之间的非线性关系。
例如传统的序列神经网络模型中,输入的每个样本数据为一个二维的矩阵。在量化研究场景中,通常,这个矩阵的表示某个股票多个因子过去一段时间的数据。
序列神经网络模型最大的优势是能够对单样本多特征之间的非线性关系进行建模,但问题是无法考虑不同样本(股票)间的关联性。证券市场中,股票价格的涨跌受多种因素影响,同时某只股票的行情变动同样也会影响其他股票。这种股票间的关联性是不仅仅是多种多样的,而且还是时变的。
股票之间的关联性如果度量?如何在预测时,考虑股票间的关联性?这种关联性的加入,是否能够提升模型的预测效果?针对以上这三个问题,我们会以A股为研究对象,努力寻找答案。
新闻共现
新闻共现,指的是两个或多个股票出现在同一篇新闻中的情况。如果多个股票出现在同一篇新闻中,说明这些股票一定程度上有内在的关联性。它们可能来自同一个行业,或者都与近期的市场热点或概念有关联,又或者是出于同一条产业链或供应链等等。我们在之前的文章中《News Co-Occurrences:关注同时出现在新闻中的股票》中已经提到,股票同时出现在新闻的频率与股票市值、股票波动及分析师覆盖度之间存在明显的关联性。个股之间的相关性随着在新闻中同时出现频率的增加而增加。个股在新闻中同时出现频率可以用于预测未来个股之间的相关性。
在最近的一篇文章《新闻共现:股票长期与动态关联性表征的因子挖掘》中,基于股票在新闻中的共现网络,提出了Equity2Vec的方法,把股票在新闻中的共现关系用一个向量表征表示。这个过程中即考虑了股票间的长期关系,也考虑了股票间的短期动态关系。基于这种共现关系使用机器学习模型提取出的表征信息与常用的股票因子,包括量价因子,一起输入到深度学习序列预测模型中,如LSTM,从而对股票的价格进行预测。
以新闻共现刻画股票的关联性,相对传统的如收益率协方差矩阵、行业上下游等关联性的特点是能够隐性同时包含多种关系。且随着不断的有新闻消息的更新,整个共现网络也能及时的更新。但问题是,无法单独的量化新闻共现中的某一类关联性,需要模型对新闻共现网络中的隐含表征进行提取,而图神经网络就是提取图中节点表征的有力工具。
图注意力神经网络GAT
在前不久的文章《Quant进阶:用『最少』的数学,学『最全』的图神经网络》我们已经详细从图的表示到动态时序图详细介绍了图神经网络。相比传统的深度学习,图神经网络最大的特点是能够将不同节点的关联性带入模型中进行学习。
不同的图神经网络模型的主要差别在于邻节点向中心节点进行消息传递与聚合的机制,图注意力神经网络相对于GCN等模型最大的特点是通过注意力机制,隐式地训练学习邻居节点对中心节点消息传递的重要性,然后根据重要性对邻居节点的特征进行加权求和,得到新的节点表征。
基于Qlib的实证分析
Qlib是微软开发的开源AI量化框架。该平台以机器学习在量化研究的应用为核心,整合了数据下载、数据预处理、机器学习预测模型及回测和策略评价的全流程。Qlib框架中有很多已经实现的机器学习模型,其中就包括GATs模型。该模型的整体框架如下:
输入数据:为某股票池(后续实证使用沪深300成分股)每个股票过去158个技术指标的历史时间序列作为特征数据。这158个技术指标是Qlib内置的常用的技术指标。每个训练的样本为一只股票158个特征过去N天的历史数据构成的矩阵。
一个batch的上述时间序列数据首先输入到LSTM模型得到 ,即LSTM在最后一个时刻T的隐藏状态特征。这一层主要使用LSTM捕捉序列长期相关性,学习股票的时间序列特征。
GAT层:GAT层的核心是建立可以描述股票间关联关系的模型,Qlib中实现的GAT采用全局自注意力机制,这种方式不需要构建显示的股票关系图,而是对每个节点计算其与其他所有节点的重要性,再加权聚合其他节点的特征。在上一层LSTM学习到每个股票的时间序列特征后,这些特征作为这个图中每个节点的属性,并通过注意力机制聚合其他节点的属性,并输入到非线性激活层,从而达到学习整个图结构的隐含表征。
预测目标:在Qlib实现的GATs模型中,预测目标为t+2日与t+1日收盘价计算的收益率,而损失函数则选用的最直观的MSE函数。
以上为Qlib中实现的基于图注意力网络GAT实现的股票收益预测模型,其在构建图网络的过程中,并没有考虑股票间的显性关系。在最早提出GAT的论文中,作者只考虑了有显示图关系的节点间消息的传递,这样的方式称为Masked Self-Attention,即只计算邻节点之间的注意力系数。基于这个逻辑,我们在Qlib已实现的GATs模型中引入基于新闻共现的显示图关系,并测试在最终策略应用层面显示图关系引入后模型效果是否有提升。
构建新闻共现矩阵
我们基于数库科技提供的SmarTag新闻分析数据构建新闻共现矩阵,这个矩阵作为邻阶矩阵传入GAT模型中。我们使用SmarTag数据中的股票标签表(news_compnay_label表),新闻数据的跨度为2017年1月1日至2022年3月1日,其数据结构如下图标签数据表所示:
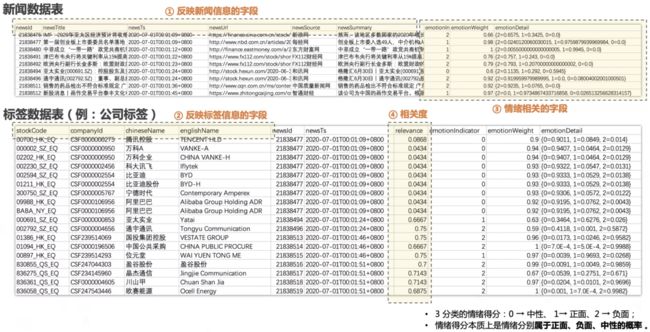
我们首先以每个交易日下午三点为切割时间,把收盘后的新闻算做下一交易日的新闻,这样就可以把日历日映射到交易日,然后在基于以下代码计算每个交易日的股票共现矩阵:
import pandas as pd
from joblib import Parallel
def get_coc_dt(news_data, dt):
temp = news_data.query("trade_date==@dt").reset_index(drop=True)
temp['cnt'] = 1
coc_df = temp.pivot_table(index='news_id', columns='sec_code', values='cnt').fillna(0)
coc_mat, coc_codes = coc_df.values, coc_df.columns.tolist()
adj_mat = coc_mat.T.dot(coc_mat)
adj_df = pd.DataFrame(data=adj_mat, index=coc_codes , columns=coc_codes ).replace(0, np.nan).unstack().dropna()
return (dt, adj_df)
def get_coc_all(news_data):
all_dts_str = [str(dt) for dt in news_data['trade_date'].dt.date.unique()]
coc_all_lst = Parallel(n_jobs=5)(delayed(get_coc_dt)(com_senti_fil, dt) for dt in tqdm(all_dts_str))
return coc_all_lst由于共现矩阵非常稀疏,如果直接保存矩阵将浪费大量空间与效率,所以我们使用多重索引的Series保存每日的股票共现数据,并删除空值记录。
每日的股票共现情况变动过去频繁,我们对每日的共现矩阵计算20日的指数加权滚动均值,这样既能动态反映共现关系的变化,也能使数据变动平稳。由于我们仅需要沪深300的共现矩阵,所以需要从原先全A的记录中过滤出沪深300的每日共现矩阵,然后计算滚动均值:
from collections import OrderDict
# 以下代码中csi300_sec_code为沪深300所有历史成分股的代码列表
coc_all_lst = get_coc_all(news_data)
for dt, coc_mat in coc_all_lst:
temp = coc_mat.unstack().reindex(csi300_sec_code).T.reindex(csi300_sec_code)
csi300_coc_dct[dt] = temp.unstack().dropna()
# 计算共现矩阵滚动均值(指数加权,半衰期为10),以{dt: Series}的格式保存,
# 以下代码只是作为示例,我们最终是在GATs内部实现的
df_csi300 = pd.concat(csi300_coc_dct.values(), keys=csi300_coc_dct.keys(), axis=1).fillna(0)
coc_ewa_csi300 = df_csi300.ewm(halflife=10, min_periods=1, axis=1).mean()
coc_ewa_csi300 = coc_ewa_csi300.where(coc_ewa_csi300>=0.25, np.nan) # 过滤共现次数均值小于0.25的记录
coc_ewa_csi300_dct = OrderedDict()
for col in coc_ewa_csi300:
coc_ewa_csi300_dct[col] = coc_ewa_csi300[col].dropna()以下就是共现矩阵的示例数据,总结构建过程就是基于日度新闻中股票共现的数据,按10日半衰期计算指数移动均值,并过滤掉数值小于0.25的记录:

修改Qlib内置GATs代码,引入新闻共现矩阵
Qlib内置的GATs模型在以下路径:qlib.contrib.model.pytorch_gats_ts中的GATModel,这个模型中没有使用显性的图结构数据,我们需要做以修改,主要分以下两个步骤:
1、在GATModel中引入邻接矩阵,修改后的代码如下,主要变化在cal_attention函数里,在47行attenion_out经非线性激活函数leaky_relu激活后,并没有直接输入到softmax进行权重归一,而是使用邻接矩阵adj将adj中记录等于0的节点的注意力权重过滤掉(设为零),然后在经softmax进行权重归一。
2、我们还引入了图结构中的dropout层,参数为gat_dropout,用于对图注意力中的权重随机dropout,提升模型稳健性。
class GATModel(nn.Module):
def __init__(self, d_feat=6, hidden_size=64, num_layers=2, lstm_dropout=0.0, gat_dropout=0.0, base_model="GRU"):
super().__init__()
if base_model == "GRU":
self.rnn = nn.GRU(
input_size=d_feat,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=lstm_dropout,
)
elif base_model == "LSTM":
self.rnn = nn.LSTM(
input_size=d_feat,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=lstm_dropout,
)
else:
raise ValueError("unknown base model name `%s`" % base_model)
self.hidden_size = hidden_size
self.d_feat = d_feat
self.transformation = nn.Linear(self.hidden_size, self.hidden_size)
self.a = nn.Parameter(torch.randn(self.hidden_size * 2, 1))
self.a.requires_grad = True
self.fc = nn.Linear(self.hidden_size, self.hidden_size)
self.fc_out = nn.Linear(hidden_size, 1)
self.leaky_relu = nn.LeakyReLU()
self.softmax = nn.Softmax(dim=1)
self.dropout = nn.Dropout(gat_dropout)
def cal_attention(self, x, y, adj):
x = self.transformation(x)
y = self.transformation(y)
sample_num = x.shape[0]
dim = x.shape[1]
e_x = x.expand(sample_num, sample_num, dim)
e_y = torch.transpose(e_x, 0, 1)
attention_in = torch.cat((e_x, e_y), 2).view(-1, dim * 2)
self.a_t = torch.t(self.a)
attention_out = self.a_t.mm(torch.t(attention_in)).view(sample_num, sample_num)
attention_out = self.leaky_relu(attention_out)
zero_vec = -9e15*torch.ones_like(attention_out)
attention_out = torch.where(adj > 0, attention_out, zero_vec)
att_weight = self.softmax(attention_out)
att_weight = self.dropout(att_weight)
return att_weight
def forward(self, x, adj):
out, _ = self.rnn(x)
hidden = out[:, -1, :]
att_weight = self.cal_attention(hidden, hidden, adj)
hidden = att_weight.mm(hidden) + hidden
hidden = self.fc(hidden)
hidden = self.leaky_relu(hidden)
return self.fc_out(hidden).squeeze()那么我们使用数库Smartag计算的显示图关系(新闻共现矩阵)怎么以参数adj传入GATModel的forward函数中呢?GATModel是在GATs类的fit方法中被调用,所以我们只要在GATs初始化的过程中读取全部历史的新闻共现数据,然后在训练过程中按照日期和当期的成分股代码进行读取即可,详细代码如下,主要改动的地方有:
1、初始化时读取全部新闻共现的历史数据,load_adj_data函数根据输入的半衰期adj_hf和阈值adj_th,计算指数移动加权的新闻共现矩阵
2、get_adj_matrix根据参数dt和codes,返回指定日期某一组股票的共现矩阵,这里有个细节需要注意是,我们把对角矩阵都用1填充,因为GAT在消息聚合时需要加上自身节点的特征。
3、如何在train的过程中知道当前训练数据的日期和股票代码?我们可以看到在train_epoch和test_epoch中我们通过dataloader.dataset.get_index()获得了所有训练日期及股票代码,这样每次for循序内,我们就可以知道当前训练数据的日期和股票代码。
class GATs(Model):
adj_path = './csi300_coc_dct.pkl'
"""GATs Model
Parameters
----------
lr : float
learning rate
d_feat : int
input dimensions for each time step
metric : str
the evaluate metric used in early stop
optimizer : str
optimizer name
GPU : int
the GPU ID used for training
"""
def __init__(
self,
adj_hf=10,
adj_th=0.2,
d_feat=20,
hidden_size=64,
num_layers=2,
lstm_dropout=0.0,
gat_dropout=0.0,
n_epochs=200,
lr=0.001,
metric="",
early_stop=20,
loss="mse",
base_model="GRU",
model_path=None,
optimizer="adam",
GPU=0,
n_jobs=10,
seed=None,
**kwargs
):
# Set logger.
self.logger = get_module_logger("GATs")
self.logger.info("GATs pytorch version...")
# Adj Matirx
self.adj = self.load_adj_data(self.adj_path, adj_hf, adj_th)
# set hyper-parameters.
self.d_feat = d_feat
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm_dropout = lstm_dropout
self.gat_dropout = gat_dropout
self.n_epochs = n_epochs
self.lr = lr
self.metric = metric
self.early_stop = early_stop
self.optimizer = optimizer.lower()
self.loss = loss
self.base_model = base_model
self.model_path = model_path
self.device = torch.device("cuda:%d" % (GPU) if torch.cuda.is_available() and GPU >= 0 else "cpu")
self.n_jobs = n_jobs
self.seed = seed
self.logger.info(
"GATs parameters setting:"
"\nd_feat : {}"
"\nhidden_size : {}"
"\nnum_layers : {}"
"\nlstm_dropout : {}"
"\ngat_dropout : {}"
"\nn_epochs : {}"
"\nlr : {}"
"\nmetric : {}"
"\nearly_stop : {}"
"\noptimizer : {}"
"\nloss_type : {}"
"\nbase_model : {}"
"\nmodel_path : {}"
"\nvisible_GPU : {}"
"\nuse_GPU : {}"
"\nseed : {}".format(
d_feat,
hidden_size,
num_layers,
lstm_dropout,
gat_dropout,
n_epochs,
lr,
metric,
early_stop,
optimizer.lower(),
loss,
base_model,
model_path,
GPU,
self.use_gpu,
seed,
)
)
if self.seed is not None:
np.random.seed(self.seed)
torch.manual_seed(self.seed)
self.GAT_model = GATModel(
d_feat=self.d_feat,
hidden_size=self.hidden_size,
num_layers=self.num_layers,
lstm_dropout=self.lstm_dropout,
gat_dropout=self.gat_dropout,
base_model=self.base_model,
)
self.logger.info("model:\n{:}".format(self.GAT_model))
self.logger.info("model size: {:.4f} MB".format(count_parameters(self.GAT_model)))
if optimizer.lower() == "adam":
self.train_optimizer = optim.Adam(self.GAT_model.parameters(), lr=self.lr)
elif optimizer.lower() == "gd":
self.train_optimizer = optim.SGD(self.GAT_model.parameters(), lr=self.lr)
else:
raise NotImplementedError("optimizer {} is not supported!".format(optimizer))
self.fitted = False
self.GAT_model.to(self.device)
def load_adj_data(self, adj_path, adj_hf, adj_th):
with open('./csi_coc_mat.pkl', 'rb') as f:
csi300_coc_dct = pickle.load(f)
df_csi300 = pd.concat(csi300_coc_dct.values(), keys=csi300_coc_dct.keys(), axis=1).fillna(0)
coc_ewa_csi300 = df_csi300.ewm(halflife=adj_hf, min_periods=1, axis=1).mean()
coc_ewa_csi300 = coc_ewa_csi300.where(coc_ewa_csi300>=adj_th, np.nan)
coc_ewa_csi300_dct = OrderedDict()
for col in coc_ewa_csi300:
coc_ewa_csi300_dct[col] = coc_ewa_csi300[col].dropna()
return coc_ewa_csi300_dct
@property
def use_gpu(self):
return self.device != torch.device("cpu")
def mse(self, pred, label):
loss = (pred - label) ** 2
return torch.mean(loss)
def loss_fn(self, pred, label):
mask = ~torch.isnan(label)
if self.loss == "mse":
return self.mse(pred[mask], label[mask])
raise ValueError("unknown loss `%s`" % self.loss)
def metric_fn(self, pred, label):
mask = torch.isfinite(label)
if self.metric in ("", "loss"):
return -self.loss_fn(pred[mask], label[mask])
raise ValueError("unknown metric `%s`" % self.metric)
def get_daily_inter(self, df, shuffle=False):
# organize the train data into daily batches
daily_count = df.groupby(level=0).size().values
daily_index = np.roll(np.cumsum(daily_count), 1)
daily_index[0] = 0
if shuffle:
# shuffle data
daily_shuffle = list(zip(daily_index, daily_count))
np.random.shuffle(daily_shuffle)
daily_index, daily_count = zip(*daily_shuffle)
return daily_index, daily_count
def get_adj_matrix(self, dt, codes):
if not isinstance(dt, str):
dt_str = str(dt.date())
else:
dt_str = dt
res = self.adj.get(dt_str).unstack()
res = res.reindex(codes).T.reindex(codes)
fill_df = pd.DataFrame(np.diag(np.ones(len(res))[np.newaxis:]), index=res.index, columns=res.columns)
res = res.combine_first(fill_df)
adj = torch.FloatTensor(res.values)
return adj.to(self.device)
def train_epoch(self, data_loader):
self.GAT_model.train()
idx = data_loader.dataset.get_index()
dts = idx.get_level_values(0).unique().tolist()
codes_idx = idx.get_level_values(1)
i = 0
for data in data_loader:
codes = codes_idx[idx.get_loc(dts[i])].tolist()
adj = self.get_adj_matrix(dts[i], codes)
data = data.squeeze()
feature = data[:, :, 0:-1].to(self.device)
label = data[:, -1, -1].to(self.device)
pred = self.GAT_model(feature.float(), adj)
loss = self.loss_fn(pred, label)
self.train_optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_value_(self.GAT_model.parameters(), 3.0)
self.train_optimizer.step()
i += 1
def test_epoch(self, data_loader):
self.GAT_model.eval()
scores = []
losses = []
idx = data_loader.dataset.get_index()
dts = idx.get_level_values(0).unique().tolist()
codes_idx = idx.get_level_values(1)
i = 0
for data in data_loader:
codes = codes_idx[idx.get_loc(dts[i])].tolist()
adj = self.get_adj_matrix(dts[i], codes)
data = data.squeeze()
feature = data[:, :, 0:-1].to(self.device)
# feature[torch.isnan(feature)] = 0
label = data[:, -1, -1].to(self.device)
pred = self.GAT_model(feature.float(), adj)
loss = self.loss_fn(pred, label)
losses.append(loss.item())
score = self.metric_fn(pred, label)
scores.append(score.item())
i += 1
return np.mean(losses), np.mean(scores)
def fit(
self,
dataset,
evals_result=dict(),
save_path=None,
):
dl_train = dataset.prepare("train", col_set=["feature", "label"], data_key=DataHandlerLP.DK_L)
dl_valid = dataset.prepare("valid", col_set=["feature", "label"], data_key=DataHandlerLP.DK_L)
if dl_train.empty or dl_valid.empty:
raise ValueError("Empty data from dataset, please check your dataset config.")
dl_train.config(fillna_type="ffill+bfill") # process nan brought by dataloader
dl_valid.config(fillna_type="ffill+bfill") # process nan brought by dataloader
sampler_train = DailyBatchSampler(dl_train)
sampler_valid = DailyBatchSampler(dl_valid)
train_loader = DataLoader(dl_train, sampler=sampler_train, num_workers=self.n_jobs, drop_last=True)
valid_loader = DataLoader(dl_valid, sampler=sampler_valid, num_workers=self.n_jobs, drop_last=True)
save_path = get_or_create_path(save_path)
stop_steps = 0
train_loss = 0
best_score = -np.inf
best_epoch = 0
evals_result["train"] = []
evals_result["valid"] = []
# load pretrained base_model
if self.base_model == "LSTM":
pretrained_model = LSTMModel(d_feat=self.d_feat, hidden_size=self.hidden_size, num_layers=self.num_layers)
elif self.base_model == "GRU":
pretrained_model = GRUModel(d_feat=self.d_feat, hidden_size=self.hidden_size, num_layers=self.num_layers)
else:
raise ValueError("unknown base model name `%s`" % self.base_model)
if self.model_path is not None:
self.logger.info("Loading pretrained model...")
pretrained_model.load_state_dict(torch.load(self.model_path, map_location=self.device))
model_dict = self.GAT_model.state_dict()
pretrained_dict = {
k: v for k, v in pretrained_model.state_dict().items() if k in model_dict # pylint: disable=E1135
}
model_dict.update(pretrained_dict)
self.GAT_model.load_state_dict(model_dict)
self.logger.info("Loading pretrained model Done...")
# train
self.logger.info("training...")
self.fitted = True
for step in range(self.n_epochs):
self.logger.info("Epoch%d:", step)
self.logger.info("training...")
self.train_epoch(train_loader)
self.logger.info("evaluating...")
train_loss, train_score = self.test_epoch(train_loader)
val_loss, val_score = self.test_epoch(valid_loader)
self.logger.info("train %.6f, valid %.6f" % (train_score, val_score))
evals_result["train"].append(train_score)
evals_result["valid"].append(val_score)
if val_score > best_score:
best_score = val_score
stop_steps = 0
best_epoch = step
best_param = copy.deepcopy(self.GAT_model.state_dict())
else:
stop_steps += 1
if stop_steps >= self.early_stop:
self.logger.info("early stop")
break
self.logger.info("best score: %.6lf @ %d" % (best_score, best_epoch))
self.GAT_model.load_state_dict(best_param)
torch.save(best_param, save_path)
if self.use_gpu:
torch.cuda.empty_cache()
def predict(self, dataset):
if not self.fitted:
raise ValueError("model is not fitted yet!")
dl_test = dataset.prepare("test", col_set=["feature", "label"], data_key=DataHandlerLP.DK_I)
dl_test.config(fillna_type="ffill+bfill")
sampler_test = DailyBatchSampler(dl_test)
test_loader = DataLoader(dl_test, sampler=sampler_test, num_workers=self.n_jobs)
self.GAT_model.eval()
preds = []
idx = test_loader.dataset.get_index()
dts = idx.get_level_values(0).unique().tolist()
codes_idx = idx.get_level_values(1)
i = 0
for data in test_loader:
codes = codes_idx[idx.get_loc(dts[i])].tolist()
adj = self.get_adj_matrix(dts[i], codes)
data = data.squeeze()
feature = data[:, :, 0:-1].to(self.device)
with torch.no_grad():
pred = self.GAT_model(feature.float(), adj).detach().cpu().numpy()
preds.append(pred)
i += 1
return pd.Series(np.concatenate(preds), index=dl_test.get_index())最终我们在进行一系列配置后(代码如下),其中训练区间为2017年1月1日至2019年12月31日,验证集为2020年1月1日至2020年12月31日,测试集为2021年1月1日至2022年3月1日。使用3090的显卡进行训练,每个epoch大概需要5分钟,一共200epoch,训练时间在15个小时左右。
import os
import qlib
import pandas as pd
from qlib.constant import REG_CN
from qlib.utils import exists_qlib_data, init_instance_by_config
from qlib.workflow import R
from qlib.workflow.record_temp import SignalRecord, PortAnaRecord
from qlib.utils import flatten_dict
provider_uri = "~/qlib_data/cn_data/" # target_dir
qlib.init(provider_uri=provider_uri, region=REG_CN)
market = "sh000300"
benchmark = "SH000300"
#### 1. 准备Dataset
data_handler_config = {
'start_time': "2017-01-01",
'end_time': "2022-03-01",
'fit_start_time': "2017-01-01",
'fit_end_time': "2019-12-31",
'instruments': market,
'infer_processors': [
{'class': 'RobustZScoreNorm',
'kwargs': {'fields_group': 'feature', 'clip_outlier': True}},
{'class': 'Fillna', 'kwargs': {'fields_group': 'feature'}}],
'learn_processors': [{'class': 'DropnaLabel'},
{'class': 'CSRankNorm', 'kwargs': {'fields_group': 'label'}}],
'label': ['Ref($open, -2) / Ref($open, -1) - 1']}
dataset_config = {
"class": "TSDatasetH",
"module_path": "qlib.data.dataset",
"kwargs": {
"handler": {
"class": "Alpha158",
"module_path": "qlib.contrib.data.handler",
"kwargs": data_handler_config
},
"segments": {
"train": ("2017-01-01", "2019-12-31"),
"valid": ("2020-01-01", "2020-12-31"),
"test": ("2021-01-01", "2022-03-01")
},
"step_len": 40
}
}
dataset = init_instance_by_config(dataset_config)
#### 2. 配置模型
import gat_model
gat_kwargs = {
'd_feat': 158,
'hidden_size': 64,
'num_layers': 2,
'lstm_dropout': 0.7,
'gat_dropout':0.5,
'n_epochs': 200,
'lr': 1e-4,
'early_stop': 20,
'metric': 'loss',
'loss': 'mse',
'GPU': 0
}
model = gat_model.GATs(**gat_kwargs)
# 开始训练模型
with R.start(experiment_name="train_model_gat_coc_csi300", resume=True):
R.log_params(**flatten_dict(gat_kwargs))
model.fit(dataset)
R.save_objects(trained_model=model)其他实证过程中遇到的问题
1、每次训练的数据结构
模型每个输入的Batch数据为每个日期截面上所有沪深300成份股的特征数据,借用华泰证券在报告《图神经网络选股与Qlib实践》中的示意图,我们可以清楚看到每次训练每个Batch的数据结构:

2、内置数据的质量问题
Qlib内置默认下载的数据存在比较多的缺陷,比如成分股数据不准确,科创板代码归为深交所等问题。所以本文实践中均使用其他第三方商业数据库。把每个股票的后复权的K线数据存为一个文件,并以股票代码命名这个csv文件。把所有文件放在一个文件夹,使用qlib中dump_all的命令就可以将数据文件转为qlib使用的bin格式:
python qlib/scripts/dump_bin.py dump_all --csv_path ~/.qlib/csv_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --include_fields open,close,high,low,volume,factor实证结果
基于模型的预测,我们采用qlib内置的Topkdropout策略进行回测。如下图所示,即在最开始的时候根据预测排名顺序,买入预测值最高的TopK个股票,后面每个交易日,把预测最低的N个股票卖出,替换上预测最高的N个股票重新构建组合。

我们对比了Qlib原始的GAT模型(GAT_baseline)、加入新闻共现的GAT模型(GAT_news_coccurrence)及沪深300指数(CSI300),结果如下:
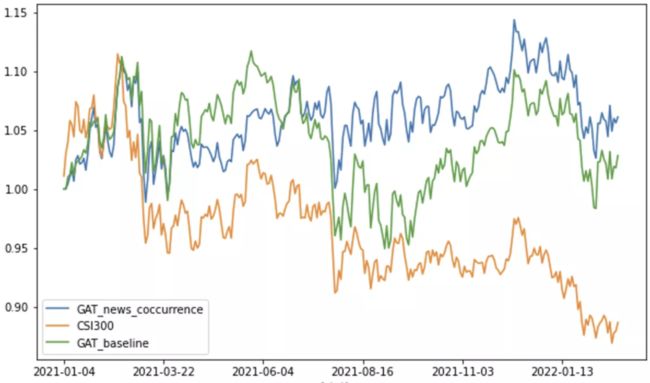
两个模型相对沪深300超额收益统计如下:
后续
本文实证研究新闻共现矩阵作为显性图关系比全局自注意力机制的图神经网络,在策略实现中能获得更高的超额收益率。但本文还有未经事宜,下一步改进会从以下几方面着手:
引入多层GAT模型
改变损失函数,引入股票间的排序作为惩罚因素
验证集中,以因子IC作为验证指标

点击阅读原文,了解更多
SmarTag新闻分析数据