Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review 综述 自动驾驶中图像和点云融合的深度学习
题目:Deep Learning for Image and Point Cloud Fusionin Autonomous Driving: A Review
原文连接:Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review | IEEE Journals & Magazine | IEEE Xplore
出处 2021 IEEE Transactions on Intelligent Transportation Systems
翻译了一些重要的内容,还有一点点自己的总结,在()中,加了一点自己认为比较重要的提到的论文的结构图,内容较长,约1w5字。
csdn右侧有目录,可以展开结构更加清晰。
摘要:
1、到目前为止,还没有针对基于深度学习的摄像机-激光雷达融合方法的重要评论。为了弥合这一差距并激励未来的研究,本文致力于回顾最近利用图像和点云的基于深度学习的数据融合方法。
2、图像+点云的数据处理 的深度学习:深度补全、目标检测、语义分割和跟踪。
1. INTRODUCTION
本篇论文的三个贡献
1、第一篇专注于自动驾驶中基于深度学习的图像和点云融合方法的调查,包括深度补全、目标检测、语义分割和目标跟踪。(注第一篇:作者是这么认为的 To the best of our knowledge)
2、本文根据融合方法对方法进行了组织和回顾。此外,本文还介绍了最新的 (2014-2020) 概述和最新的相机-激光雷达融合方法的性能比较。
3、本文提出了被忽视的开放问题,例如在线自校准和传感器无关框架,这些问题对于自动驾驶技术的实际部署至关重要。此外,还总结了趋势和面临的挑战。
结构安排:第二章:简要概述深度学习在图像和点云的方法;第三章:深度补全;第四章:3d目标检测;第五章:语义分割;第六章:目标跟踪;第七章:未来趋势。
2. A BRIEF REVIEW OF DEEP LEARNING 各自的常见方法
2.1 Deep Learning on Image 图像
这个就很熟悉了CNN(卷积)和MLP(多层感知机)
2.2 Deep Learning on Point Cloud 点云
点云是一组数据点,它们是检测到的物体表面的测量值。在数据结构上,点云是稀疏、不规则、无秩序和连续的。点云以3D结构和反射强度对信息进行编码,这些信息对于尺度,刚性变换和置换是不变的。这些特征对于现有的基于CNN的深度学习模型具有挑战性,需要对现有模型或专门设计的模型进行修改。因此,本节重点介绍一些常用的点云处理方法。
(就是说点云不能直接用CNN来处理 )
2.2.1 Volumetric representation based 体素的方法
优点:体积表示方法将点云划分成3D的小格子,可以通过 手工设计/学习 的方法 对格子进行特征提取。这种划分通常是固定分辨率,因此可以套用标准的CNN来处理。
缺点:高分辨率保留更丰富的细粒度几何名单时,增加了计算和内存成本,体素的数量随着分辨率增长。
2.2.2 Tree-like representation based 树的表示方法
优点:高分辨率和计算成本之间的的平衡。通过将点云划分为一系列不平衡树,可以根据其点密度对区域进行划分。这允许点密度较低的区域具有较低的分辨率,从而减少了不必要的计算和内存成本。使用类似卷积的操作沿树结构提取点特征。
2.2.3 2D Views Representation Based 基于 2D 视图表示
点云的 2D 视图表示是通过将点云投影到某个 2D 视图平面/网格来生成的。这会产生一个类似图像的特征图,其中每个像素/网格都编码该 2D 像素/网格内的点特征。最受欢迎的视图之一是鸟瞰图 (BEV),其中透视遮挡是最小的,并且保留了有关对象方向的原始信息,x/y 坐标。常用的点特征包括平均点高度、密度和强度。标准的 2D 卷积和现成的 CNN 架构可以直接应用于 BEV 表示。

2.2.4 Graph Representation Based基于图表示
点云可以表示为图,并且可以在空间或谱域中的图上实现类似卷积的操作。
对于空间域中的图卷积,MLP 对空间相邻点执行操作。
对于谱域图卷积通过拉普拉斯光谱扩展了卷积作为图上的谱滤波。
2.2.5 Point representation based 点云直接表示
基于点表示的方法处理原始点云。以PointNet为代表,它采用了独立的T-Net模块来对齐点云,并共享多层感知器 (mlp) 来处理单个点,以进行逐点特征提取。允许处理无序数据的关键思想是采用对称函数 (最大池化)。
优点:点云的全局特征可以通过最大池化从这些逐点特征中聚合。该方法对刚性变换和置换具有不变性。
缺点:局部点间几何结构并未得到充分探索。此外,对齐网络引入了额外的计算成本。
pointnet 结构图 (1)点云的置换不变性=>对称函数 (2)点云的旋转不变性 =>T-Net

3. DEPTH COMPLETION 深度补全
自动驾驶汽车大规模商业化的障碍之一是传感器的成本。特别是高分辨率激光雷达(64 或 128 通道)的成本极高。此外,即使使用高端激光雷达,远程目标的测量仍然有限且稀疏。这种稀疏性极大地限制了 3D 感知算法并使其复杂化,这些算法通常旨在处理密集和规则的数据。深度补全旨在通过将稀疏的不规则数据上采样为密集的规则数据来解决此问题。基于相机-LiDAR 融合的方法通常利用高分辨率图像来指导深度上采样,这也导致逐像素融合并产生密集的深度图像。
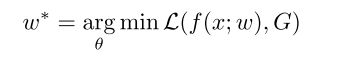
深度补全模型可以用这个公式补全,f是网络,w是网络的参数,x是输入(可以理解为图片),G是真值(真实的深度),L是误差函数loss函数。(其实就是算 网络的预测和真实标签之间的差距)
融合级别、时间线:

融合效果、运行时间
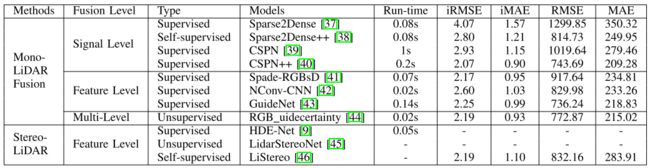
3.1 Mono Camera and LiDAR fusion 单目+激光融合
当前有关深度完成的大多数研究都集中在使用单声道相机的图像来指导深度完成。这个想法是密集的RGB/颜色信息包含相关的3D几何形状,可以将其用作深度上采样的参考。
3.1.1 Signal-level fusion 信号级别融合
Sparse-to-dense提出了一种基于ResNet 的自动编码器网络,该网络利用 稀疏深度图连接的图像来生成 密集深度图。此方法采用信号级别融合,并且优于其他深度完成方法。然而,这种方法需要像素级深度地面真相。
Self-supervised sparse-to-dense 这种自我监督是通过采用稀疏的深度约束,光度损失和平滑度损失来实现的。但是,这种方法假定对象是静止的。此外,所得的深度输出是模糊的,并且输入深度可能无法保留。
CSPN尝试将RGB-D图像送入卷积空间传播网络,直接提取图像相关的亲和矩阵,以较少的运行时间在关键测量中产生显著更好的结果。
CSPN++为了减少计算量,提出动态选择卷积核大小和迭代次数,此外,CSPN++采用加权组装来提高其性能。
3.1.2 Feature-level fusion 特征级别级别融合
Sparse and dense data with cnns一种自动编码器网络,该网络可以执行深度完成或从稀疏深度和图像进行语义分割,而无需应用有效性掩码。图像和稀疏深度图首先由两个并行的基于NASNet的编码器处理,然后将它们融合到共享解码器中。即使使用非常稀疏的深度输入 (8通道激光雷达),这种方法也可以实现不错的性能。
GuideNet将图像特征融合到编码器不同阶段的稀疏深度特征,以指导稀疏深度的上采样。值得注意的是,GuideNet是KITTI深度完成基准中当前性能最好的模型。
3.1.3 Multi-level fusion 多层次融合
Sparse and noisy lidar completion with rgb guidance and uncertainty在图像引导深度完成网络中进一步结合了信号级融合和特征级融合技术。该网络由一个全局分支和一个本地分支组成,用于并行处理rgb-d数据和深度数据,然后根据置信度图将其融合。这种方法是实时的,在KITTI深度完成基准上排名第一。
3.2 Stereo Cameras and LiDAR fusion
与RGB图像相比,双目相机的密集深度差异包含更丰富的地面真相3D几何形状。另一方面,激光雷达深度稀疏,但精度更高。立体深度和激光雷达深度的互补特征使得可以从中计算出密集且更准确的深度。但是,双目相机的可测距性有限,并且在高遮挡,无纹理的环境中挣扎,使其不太适合自动驾驶。
3.2.1 Feature-level fusion 特征级别融合
High-precision depth estimation using uncalibrated lidar and stereo fusion使用两阶段CNN从密集立体视差和点云计算出高精度密集视差图。CNN的第一阶段采用激光雷达和立体视差来产生融合视差。在第二阶段,将此融合的视差和左RGB图像融合在特征空间中,以预测最终的高精度视差。最后,可以从这种高精度视差中重建3D场景。这种方法的瓶颈是需要大规模带注释的立体激光雷达数据集,但是这种数据很难获得。
LidarStereoNet通过无监督学习方案避免了这一困难,该方案不需要深度地面真理。无监督方案采用图像翘曲/光度损失,稀疏深度损失,平滑度损失和平面拟合损失进行端到端训练。此外,“反馈环” 的引入使LidarStereoNet对噪声点云和传感器错位具有鲁棒性。
4. DYNAMIC OBJECT DETECTION 动态物体检测
3D对象检测旨在定位,分类和估计3D空间中的定向边界框。物体检测有两种主要方法: 顺序法(两阶段)和一步法。
基于顺序的模型包括提案阶段和3D边界框 (bbox) 回归阶段。在提案阶段,提出了可能包含感兴趣对象的区域。在bbox回归阶段,根据从3D信息中提取的区域特征对区域建议进行分类。但是,顺序融合的性能受到每个阶段的限制。
一步模型由一个阶段组成,其中以并行方式处理2D和3D信息。
时间线和性能

三种常见3D目标检测框架对比 后边有相应介绍+原论文结构图

4.1 2D Proposal Based Sequential Models 2D提议 顺序模型
基于2D提案的顺序模型尝试在提案阶段利用2D图像语义,该模型利用了现成的图像处理模型。具体地,这些方法利用图像对象检测器来生成2D区域建议,可以将其作为检测种子投影到3D空间。有两种投影方法可以将2D提案转换为3D。第一个是将图像平面中的边界框投影到3D点云,从而形成截头形的3D搜索空间。第二种方法将点云投影到图像平面,从而产生具有逐点2D语义信息的点云。然而,遥远或被遮挡的物体通常由少数稀疏点表示,使得3D bbox回归变得困难。
4.1.1 Result-level Fusion 结果级融合
在这些方法中,信息聚合发生在结果级别。这些方法背后的直觉是使用现成的2D对象检测器来缩小3D对象检测器的兴趣区域。实现2D bbox到3D种子区域的最常见方法是通过反向相机投影。这用多个较小的感兴趣区域代替了整个点云的处理,从而大大减少了计算和运行时间。但是,由于整个管道取决于2D对象检测器的结果,因此该方法的整体性能在很大程度上受到2D对象检测器性能的限制。结果级融合的核心思想不是使用多模态数据相互补充,而是减少计算量。
FPointNets 其中 2D 边界框首先从图像数据生成,然后投影到 3D 空间。生成的投影平截头体(看成一个三角锥也行)提议区域被输入基于 PointNet的检测器,用于 3D 对象检测。FPointNets结构图:

4.1.2 Multi-level Fusion
另一个可能的改进方向是将结果级融合与特征级融合相结合,其中一项工作是 PointFusion。 PointFusion 首先利用现有的 2D 对象检测器来生成 2D bbox。这些 bbox 用于选择对应的点,通过将点投影到图像平面并定位穿过 bbox 的点。最后,基于 ResNet 和 PointNet的网络结合图像和点云特征来估计 3D 对象。在这种方法中,图像特征和点云特征被融合到每个提案中,用于 3D 中的最终对象检测,这有助于 3D bbox 回归。但是,提案阶段仍然是非模态的。在 SIFRNet中,首先从图像生成平截头体提议。然后将这些截锥体提议中的点云特征与其相应的图像特征相结合,以进行最终的 3D bbox 回归。为了实现尺度不变,PointSIFT被合并到网络中。此外,SENet 模块用于抑制信息量较少的特征。
4.1.3 Feature-level Fusion
多模态融合的早期尝试是按像素进行的,其中3D几何图形被转换为图像格式或作为图像的附加通道附加。直觉是将3D几何投影到图像平面上,并利用成熟的图像处理方法来提取信息。然而,结果输出也在图像平面上,这对于在3D空间中定位对象并不理想。2014年,Gupta等人提出了DepthRCNN,一种基于RCNN (二维对象检测、实例和语义分割的体系结构)。它在图像的RGB通道中编码来自Microsoft Kinect相机的3D几何图形,它们是水平视差,地面高度和重力角度 (HHA)。Gupta等人。通过对齐3D CAD模型,扩展了用于3D对象检测的Depth-RCNN。2015年,从而显着提高了性能。2016年,Gupta等人开发了一种新颖的技术,用于在基于图像数据和看不见的成对图像模态 (深度图像) 训练的网络之间进行有监督的知识转移 。
为了在3D中准确定位对象,当前的工作通常采用逐点融合。在这种方法中,图像特征被附加到点云中的每个点。这是通过将点投影到图像平面以进行点-像素关联来实现的。PointPainting采用将点投影到2D语义图的想法,而不是进行逐点融合。简单地将2D语义作为附加通道附加到点云上,而不是使用2D语义来过滤点云。作者认为,这种技术使PointPainting变得灵活,因为它使任何基于点云的网络都可以应用于此融合数据。为了证明这种灵活性,融合的点云被馈送到多个现有的点云检测器中,这些检测器基于PointRCNN,VoxelNet 和pointpills。
4.2 3D Proposal Based Sequential Model
在基于3D提案的顺序模型中,直接从2D或3D数据生成3D提案。消除2D到3D转换极大地缩小了用于对象检测的3D搜索空间。用于3D提案生成的常用方法包括多视图方法和点云体素化方法。
基于多视图的方法利用点云的鸟瞰图 (BEV) 表示来生成3D提案。BEV是首选视点,因为它避免了透视遮挡并保留了对象的方向和x,y坐标的原始信息。这些方向和x,y坐标信息对于3D物体检测至关重要,同时使BEV和其他视图之间的坐标变换直接进行。
点云体素化将连续的不规则数据结构转换为离散的规则数据结构。这使得可以应用标准的3D离散卷积并利用现有的网络结构来处理点云。缺点是损失了一些空间分辨率,其中可能包含细粒度的3D结构信息。
4.2.1 Feature-level fusion
MV3D是从BEV表示生成3D提案的开创性和最重要的工作之一 。MV3D在像素化的自上而下的激光雷达特征图 (高度,密度和强度) 上生成3D建议。然后将这些3D候选物投影到LiDAR前视图和图像平面,以提取并融合区域特征以进行bbox回归。MV3D结构图:
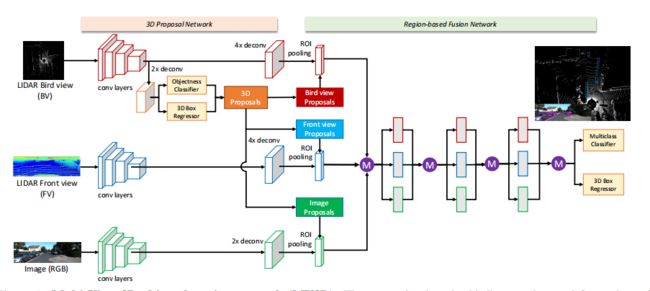
尽管 MV3D 的性能明显优于最先进的模型,但仍然存在一些缺陷。首先,在 BEV 上生成 3D 提议假设所有感兴趣的对象都被捕获,而不受该视点和该 LiDAR 传感器的干扰。这个假设不适用于小物体实例,例如行人和骑自行车的人,它们可能被点云中的其他大物体完全遮挡。其次,连续卷积操作导致的特征图下采样过程中丢失了小对象实例的空间信息。第三,以对象为中心的融合通过 ROI-pooling 结合图像和点云的特征图,在此过程中破坏了细粒度的几何信息。还值得注意的是,冗余提案会导致 bbox 回归阶段的重复计算。为了缓解这些挑战,已经提出了多种方法来改进 MV3D。
聚合视图对象检测网络(AVOD)首先使用来自 BEV 点云和图像的特征图改进了 MV3D 中的提议阶段。此外,采用自动编码器架构将最终特征图上采样到其原始大小。这可以缓解小物体可能通过连续卷积操作被下采样到一个“像素”的问题。所提出的特征融合区域提议网络(RPN)首先通过裁剪和调整大小操作从多种模态(BEV 点云和图像)中提取等长特征向量。其次是 1X1 卷积运算,用于特征空间降维,可以降低计算成本并提高速度。AVOD结构图

mvx-net 介绍了两种将图像和点云数据逐点或逐体素融合的方法。两种方法都采用预训练的2D CNN进行图像特征提取,并采用基于VoxelNet网络来估计融合点云中的对象。在逐点融合方法中,首先将点云投影到图像特征空间,以提取体素化之前的图像特征,并由VoxelNet进行处理。体素方向融合方法首先对点云进行体素化,然后将非空体素投影到图像特征空间进行体素/区域方向特征提取。这些体素特征仅在体素网络的后期附加到其相应的体素。MVX-Net在KITTI基准上实现了最先进的结果并优于其他基于激光雷达的方法,同时降低了假阳性和假阴性率。
MVX-net结构图

4.3 One-step Models
一步模型在一个阶段执行提案生成和 bbox 回归。通过将提案和 bbox 回归阶段融合为一步,这些模型通常在计算上更有效。这使它们更适合移动计算平台上的实时应用程序。Sensor fusion for joint 3d object detection and semantic segmentation将 LaserNet 扩展到多任务和多模式网络,对融合的图像和 LiDAR 数据执行 3D 对象检测和 3D 语义分割。两个 CNN 并行处理深度图像(从点云生成)和前视图图像,并通过将点投影到图像平面将它们融合以关联相应的图像特征。该特征图被输入到 LaserNet 以预测边界框的每点分布,并将它们组合成最终的 3D 提议。这种方法非常高效,同时实现了最先进的性能。
5. STATIONARY ROAD OBJECT DETECTION 静态物体检测
本节着重回顾基于摄像机-激光雷达融合的固定道路物体检测方法的最新进展。固定道路物体可以分为道路物体 (例如路面和道路标记) 和非道路物体 (例如交通标志)。道路和非道路物体为自动驾驶车辆提供法规,警告禁令和指导。车道线检测:

交通信号标志识别:

5.1 Lane/Road Detection 车道线检测
现有的研究对传统的多模式道路检测方法进行了详细评论。这些方法主要依靠视觉进行道路/车道检测,同时利用 LiDAR 进行路边拟合和障碍物遮蔽。因此,本节重点介绍基于深度学习的道路提取融合策略的最新进展。
基于深度学习的道路检测方法可以分为基于BEV或front-camera-view-based。
BEV-based的方法 将激光雷达深度和图像投影到BEV进行道路检测,从而保留了物体的原始x,y坐标和方向。=使用CNN从点云预测密集BEV高度估计,然后将其与BEV图像融合以进行准确的车道检测。但是,这种方法不能区分不同的车道类型。
Front-camera-view-based 方法将雷达深度投影到相机平面提取道路表面,但是2D到3D边界比那换会有精度损失。
5.2 Traffic Sign Recognition交通信号识别
在激光雷达扫描中,交通标志因其逆反射特性而具有高度可区分性,但缺乏密集纹理使其难以分类。相反,交通标志图像补丁可以很容易地分类。然而,基于视觉的 TSR 系统很难在 3D 空间中定位这些交通标志。因此,各种研究提出将相机和激光雷达用于 TSR。
对于采用典型TSR融合管道的方法,主要区别在于分类器。这些分类器包括基于深度玻尔兹曼机 (DBMs) 的分层分类器 [102] 、svm [101] 和DNN [104]。总而言之,这些方法都采用结果级融合和分层对象检测模型。他们认为在激光雷达扫描中可以看到交通标志,但由于遮挡,有时情况并非如此。此外,该管道受到移动LiDARs的检测范围的限制。
为了缓解这些挑战,Deng 和 Zhou [106] 结合图像和点云来生成彩色点云,用于交通标志检测和分类。此外,利用检测到的交通标志的 3D 几何特性来减少误报。在[107]中,交通标志检测基于先验知识,包括道路几何信息和交通标志几何信息。检测到的交通标志补丁由 Gaussian-Bernoulli DBMs 模型分类。遵循这一理想,Guan 等人。 [105]使用卷积胶囊网络进一步改进了交通标志识别部分。总而言之,这些方法利用多模态数据和先验知识改进了交通标志检测阶段。然而,先验知识通常是特定于地区的,这使得很难推广到世界其他地区。
6. 2D/3D SEMANTIC SEGMENTATION 语义分割
2D/3D语义分割旨在预测每个像素和每个点的类标签,而实例分割还关心单个实例。时间线:

典型的网络结构:

6.1 2D Semantic Segmentation 2D语义分割
6.1.1 Feature-level fusion
稀疏和密集 [46] 提出了一种基于NASNet的自动编码器网络,该网络可用于利用图像和稀疏深度进行2D语义分割或深度完成。图像和相应的稀疏深度图在融合到共享解码器之前由两个并行编码器处理。
6.2 3D Semantic Segmentation 3D语义分割
6.2.1Feature-Level Fusion
3DMV,这是一种用于3D语义分割的多视图网络,该网络融合了体素化点云中的图像语义和点特征。由2D cnn从多个对齐的图像中提取图像特征,并将其投影回3D空间。这些多视图图像特征是最大池体素,并与3D几何图形融合,然后再输入3D cnn以进行每个体素语义预测。3DMV在ScanNet [110] 基准上优于其他基于体素的方法。但是,基于体素的方法的性能取决于体素分辨率,并受到体素边界伪影的阻碍。
6.3 Instance Segmentation 实例分割
本质上,实例分割旨在共同执行语义分割和对象检测。它通过区分类中的单个实例来扩展语义分割任务,这使其更具挑战性。
6.3.1 Proposal based 基于提议的(两阶段)
3D-SIS,两阶段3D CNN,对多视图图像和rgb-d扫描数据执行体素方向3D实例分割。在3D检测阶段,使用基于ENet的网络提取多视图图像特征并进行下采样。此下采样过程解决了高分辨率图像特征图和低分辨率体素化点云特征图之间的不匹配问题。这些下采样的图像特征图被投影回3D体素空间,并附加到相应的3D几何特征,然后将其馈送到3D CNN中以预测对象类和3D bbox姿势。在3D遮罩阶段,3D CNN拍摄图像,点云特征和3D对象检测结果,以预测每个体素实例标签。
Narita等人 [116] 扩展了2D全景分割,以对RGB图像和深度图像联合执行场景重建、3D语义分割和3D实例分割。这种方法将RGB和深度帧作为实例和2D语义分割网络的输入。为了跟踪帧之间的标签,通过关联和集成到体积图来引用这些帧预测的全景注释和相应的深度。在最后一步中,使用完全连接的条件随机场 (CRF) 来微调输出。但是,这种方法不支持动态场景,并且容易受到长期后期漂移的影响。
6.3.2 Proposal-free based(没有提议阶段)
3D-BEVIS,该框架使用聚类方法在与2D语义聚合的点上共同执行3D语义和实例分割任务。3D-BEVIS首先从2D BEV表示 (RGB和地面高度) 中提取全局语义分数图和实例特征图。使用图神经网络将这两个语义图传播到点。最后,mean shift算法使用这些语义特征将点聚类为实例。这种方法主要受其依赖于来自BEV的语义特征,可能会从传感器位移中引入遮挡。
7. OBJECTS TRACKING 物体跟踪
多对象跟踪 (MOT) 旨在维护对象身份并跨数据帧 (随时间推移) 跟踪其位置,这对于自动驾驶车辆的决策是必不可少的。为此,本节回顾了基于摄像机-激光雷达融合的对象跟踪方法。基于对象初始化方法,MOT算法可以分类为基于检测的跟踪 (DBT) 和无检测跟踪 (DFT) 框架。DBT或逐个检测跟踪框架利用对象检测器产生的一系列对象假设和更高级别的线索来跟踪对象。在DBT中,通过数据 (检测序列) 关联或多重假设跟踪跟踪对象。相反,DFT框架基于有限集统计 (FISST) 进行状态估计。常见的方法包括多目标多伯努利 (成员) 滤波器和概率假设密度 (PHD) 滤波器。表五显示了KITTI多目标跟踪基准 (car) 上不同型号的性能 [56]。图10提供了DBT和DFT方法之间的比较。

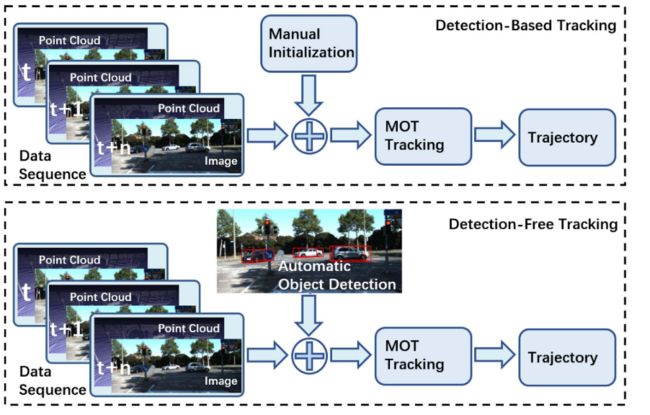
7.1 Detection-Based Tracking (DBT)基于检测的跟踪
检测跟踪框架由两个阶段组成。在第一阶段,检测感兴趣的对象。第二阶段随着时间的推移将这些对象关联起来,并将它们形成轨迹,这些轨迹被表述为线性程序。 Frossard 和 Urtasun [119] 提出了一个端到端的可训练跟踪检测框架,由多个独立的网络组成,这些网络同时利用图像和点云。该框架连续执行目标检测、提议匹配和评分、线性优化。为了实现端到端的学习,检测和匹配是通过深度结构化模型(DSM)制定的。
7.2 Detection-Free Tracking (DFT)不需要检测的跟踪
在 DFT 中,对象通过基于过滤的方法手动初始化和跟踪。 complexer-YOLO [122] 是一个实时框架,用于对图像和点云数据进行解耦的 3D 对象检测和跟踪。在 3D 对象检测阶段,提取 2D 语义并将其逐点融合到点云中。该语义点云被体素化并输入 3D complex-YOLO 以进行 3D 对象检测。为了加快训练过程,IoU 被一种称为 Scale-Rotation-Translation score (SRT) 的新指标取代,该指标评估边界框位置的 3 个自由度。多目标跟踪与检测分离,并通过标记多伯努利随机有限集滤波器 (LMB RFS) 实现推理。
8 ONLINE CROSS-SENSOR CALIBRATION
相机-激光雷达融合管道的先决条件之一是传感器之间的完美配准/校准,这可能很难满足。传感器之间的校准参数由于机械振动和热量波动而不断变化。由于大多数融合方法对校准误差极为敏感,因此可能会严重削弱其性能和可靠性。此外,离线校准是一个麻烦且耗时的过程。因此,在线自动交叉传感器校准的研究具有显着的实际效益。(应该就是自动标定,感觉这一章写的大意就是,在线标定都挺难)
8.1 Classical Online Calibration 传统的在线标定
在线校准方法在没有校准目标的自然环境中估计外部。许多研究 [124]-[127] 通过最大化互信息 (MI) (强度值或边缘强度) 在不同模态之间。但是,基于MI的方法对纹理丰富的环境,传感器位移引起的大校准和遮挡并不可靠。或者,基于LiDARenabled视觉测距的方法 [128] 使用相机的自我运动来估计和评估相机激光雷达外部参数。尽管如此,[128] 仍在与大的去校准作斗争,并且无法实时运行。
8.2 Classical Online Calibration 深度学习的在线标定
设计了一个实时的CNN(RegNet)来估计外在的,它是在随机去校准的数据上训练的。所提出的 RegNet 在两个平行分支中提取图像和深度特征,并将它们连接起来以生成融合特征图。这个融合的特征图被输入到网络中的网络(NiN)模块堆栈和两个完全连接的层中,用于特征匹配和全局回归。然而,RegNet 对传感器的内在参数是不可知的,一旦这些内在参数发生变化,就需要重新训练。为了解决这个问题,CalibNet [130] 学习以自我监督的方式最小化错误校准和目标深度之间的几何和光度不一致。因为内在函数仅在 3D 空间变换期间使用,所以 CalibNet 可以应用于任何经过内在校准的相机。然而,基于深度学习的跨传感器校准方法的计算成本很高。
9.TRENDS, OPEN CHALLENGES AND PROMISING DIRECTIONS 趋势、开放挑战和有希望的方向
点云融合总结三点
• 2D到3D: 在3D特征提取方法的进步下,在3D空间中定位,跟踪和分割对象已成为研究的热点领域。
• 单任务到多任务: 结合了多个互补的任务,例如对象检测,语义分割和深度完成,以实现更好的整体性能并降低计算成本。
• 信号级到多级融合: 早期的工作经常利用信号级融合,其中3D几何图形被转换到图像平面以利用现成的图像处理模型,而最近的模型试图在多层次 (例如早期融合,晚期融合) 和时间上下文编码中融合图像和激光雷达。
9.1 Performance-related Open Research Questions与性能相关的开放研究问题
9.1.1 What Should Be the Data Representation of Fused Data?融合数据的数据表示应该是什么
选择融合数据的数据表示形式在设计任何数据融合算法中起着至关重要的作用。图像和点云融合的当前数据表示包括:
• 图像表示: 附加3D几何形状作为图像的附加通道。基于图像的表示支持现成的图像处理模型。但是,结果在2D图像平面中也受到限制,这对于自动驾驶而言不太理想。
• 点表示: 附加RGB信号/特征作为点云的附加通道。然而,高分辨率图像和低分辨率点云之间的分辨率不匹配导致效率低下。
• 中间数据表示: 将图像和点云特征/信号转换为中间数据表示,例如体素化点云 [82]。但是,基于体素的方法的可伸缩性很差。
最近许多用于点云处理的工作都集中在定义显式点卷积操作 [32],[444],[35]-[38],[62],它们显示出巨大的潜力。这些点卷积更适合提取细粒度的perpoint和局部几何。因此,我们认为融合数据的点表示与点卷积结合在相机-激光雷达融合研究中具有巨大的潜力。
9.1.2 How to Encode Temporal Context?如何编码时间上下文?
当前大多数基于深度学习的感知系统都倾向于忽略时间上下文。这导致许多问题,例如低刷新率引起的点云变形和传感器之间不正确的时间同步。这些问题导致图像、点云与实际环境不匹配。因此,将时间上下文纳入感知系统至关重要。在自动驾驶的情况下,可以使用RNN或LSTM模型合并时间环境。在 [131] 中,LSTM自动编码器用于估计周围车辆的未来状态并相应地调整计划的轨迹,这有助于自动驾驶车辆运行更平稳和更稳定。在 [121] 中,利用时间上下文来估计自我运动,这有利于后来的任务相关报头网络。此外,时间上下文可以通过基于视觉测距的方法 [128] 受益于在线自校准。遵循这种趋势,可以通过编码时间上下文和生成模型来解决由LiDAR低刷新率引起的不匹配。
9.1.3 What Should Be the Learning Scheme?学习方案应该是什么?
大多数当前的相机-激光雷达融合方法都依赖于监督学习,这需要大量带注释的数据集。但是,注释图像和点云既昂贵又耗时。这限制了当前多模态数据集的大小和监督学习方法的性能。这个问题的答案是无监督和弱监督的学习框架。最近的一些研究显示了这方面的巨大潜力 [24],[43],[50],[101],[132]。遵循这一趋势,在无监督和弱监督学习融合框架中的未来研究可以使网络在大型未标记/粗略标记的数据集上进行训练,并带来更好的性能。
9.1.4 When to Use Deep Learning Methods?何时使用深度学习方法?
深度学习技术的最新进展加速了自动驾驶技术的发展。然而,在许多方面,传统方法在当前的自动驾驶系统中仍然是必不可少的。与深度学习方法相比,传统方法具有更好的可解释性,并且消耗的计算资源明显更少。跟踪决策的能力对于自动驾驶汽车的决策和规划系统至关重要。尽管如此,当前的深度学习算法不是可追溯的,因此不适合这些应用程序。除了这种黑箱困境之外,传统算法还因其实时功能而受到青睐。总而言之,我们认为深度学习方法应应用于具有明确目标可客观验证的应用程序。
9.2 Reliability-related Open Research Questions可靠性相关开放研究问题
9.2.1 How to Mitigate Camera-LiDAR Coupling?如何减轻相机-激光雷达耦合?
从工程的角度来看,冗余设计自主车辆中的至关重要的安全.虽然融合激光雷达和相机提高了感知性能,但它也伴随着信号耦合的问题。如果其中一个信号路径突然出现故障,整个管道能够分解并削弱下游模块.这是不可接受的自动驾驶系统,这需要强大的感知管道.针对这一问题,我们应该制定一个传感器无关.例如,可以采用多个融合模块具有不同的传感器输入.此外,我们还可以使用多路径融合模块采取异步多模态数据.然而,最好的解决方案仍处于打开状态的研究.
9.2.2 How to Improve All-weather/Lighting Conditions?如何改善全天候/照明条件?
自动驾驶汽车需要在所有天气和照明条件下工作。但是,当前的数据集和方法大多集中在具有良好照明和天气条件的场景上。这会导致在照明和天气条件更加复杂的现实世界中表现不佳。解决此问题的第一步是开发更多数据集,这些数据集包含广泛的照明和天气条件。此外,采用多模式数据来解决复杂的照明和天气条件的方法需要进一步研究。(很多比赛增加了雨雪等天气)
9.2.3 Adversarial Attacks and Corner Cases?如何处理对抗性攻击和角落案件?
针对基于摄像头的感知系统的对抗性攻击已被证明是有效的。这对自动驾驶汽车构成了严重的危险,因为它在安全关键的环境中运行。可能很难识别为某些感觉方式明确设计的攻击。然而,感知结果可以通过不同的方式进行验证。在这种情况下,可以进一步探索利用3D几何形状和图像来共同识别这些攻击的研究。由于自动驾驶汽车在具有无限可能性的不可预测的开放环境中运行,因此在感知管道的设计中考虑拐角和边缘情况至关重要。感知系统应该预见到看不见的和不寻常的障碍,奇怪的行为和极端天气。例如,骑自行车的人的图像印在大型车辆上,人们穿着服装。仅使用摄像机或激光雷达管道通常很难处理这些角落的情况。但是,利用来自多模态的数据来识别这些角落情况可能比来自单一模态传感器的数据更有效(特斯拉???),更可靠。在此方向上的进一步研究可以极大地促进自动驾驶技术的安全性和商业化。
9.2.4 How to Solve Open-Set Object Detection?如何解决Open-Set对象检测?
Open-set对象检测是在来自未知/看不见的类的实例上测试对象检测器的场景(出现在训练集之外的场景)。开集问题对于自动驾驶汽车至关重要,因为它在具有无限类别对象的不受约束的环境中运行。当前的数据集通常对不感兴趣的任何对象使用后台类。但是,没有数据集可以在后台类中包含所有不需要的对象类别。因此,对象检测器在开放设置中的行为是高度不确定的,这对于自动驾驶而言不太理想。缺乏开放集对象检测意识,测试协议和度量标准,导致在当前对象检测研究中对开放集性能的明确评估很少。Dhamija等人最近的一项研究已经讨论和研究了这些挑战 [133],其中提出了一种新颖的开放集协议和度量。作者提出了一个额外的混合未知类别,其中包含已知的 “背景” 对象和未知/看不见的对象。基于此协议,在具有从现有数据集的组合生成的混合未知类别的测试集上测试一下当前方法。在最近关于点云的另一项研究中,Wong等人 [134] 提出了一种将来自不同类别的不需要的对象映射到类别不可知的嵌入空间中以进行聚类的技术。开放式挑战对于在现实世界中部署基于深度学习的感知系统至关重要。它需要整个研究界的更多努力和关注 (强调未知对象的数据集和方法,测试一下协议和度量标准等)
9.2.5 How to Balance Speed-Accuracy Trade-offs?如何平衡速度-精度的权衡?
多个高分辨率图像和大规模点云的处理给现有的移动计算平台带来了巨大的压力。这有时会导致丢帧,这可能会严重降低感知系统的性能。更一般地,它导致高功率消耗和低可靠性。因此,在实际部署中平衡模型的速度和准确性非常重要。有研究试图检测掉帧。在 [135] 中,Imre等人提出了一种利用相机对上的多个片段 (虚线) 拟合的多相机帧掉落检测算法。但是,丢帧检测只能解决一半的问题。最困难的部分是防止因丢帧而导致的性能下降。生成模型的最新进展已经证明了预测视频序列中丢失帧的巨大潜力 [136],这可以在自动驾驶中用于填充图像和点云管道中的丢失帧。但是,我们认为解决丢帧问题的最有效方法是通过减少硬件工作量来防止它。这可以通过仔细平衡模型的速度和精度来实现 [137]。为了实现这一目标,深度学习模型应该能够降低其计算成本,同时保持可接受的性能。这种可扩展性通常是通过减少输入的数量 (点,像素,体素) 或网络的深度来实现的。从先前的研究 [30],[38],[138],基于点和多视图的融合方法比基于体素的方法更具可扩展性。
(性能 和 精度,轻量化 老生常谈了)
10.CONCLUSION
本文对自动驾驶背景下的点云和图像融合深度学习模型的最新进展进行了深入回顾。具体来说,这篇综述根据它们的融合方法组织了方法,涵盖了深度完成、动态和静止物体检测、语义分割、跟踪和在线交叉传感器校准。此外,表格中还列出了公开可用数据集的性能比较,模型的重点和优缺点。典型的模型体系结构如图所示。最后,我们总结了总体趋势,并讨论了开放的挑战和可能的未来方向。这项调查还提高了人们的认识,并提供了对研究界忽略但困扰自动驾驶技术实际部署的问题的见解。
整理不易,求点赞~