pytorch下使用BiLSTM_CRF完成命名实体识别(BiLSTM_CRF的NER任务)
理论部分
有空再写..
全部实现实践代码
环境: pytorch 1.3.1; sklearn;tqdm
训练语料:链接:https://pan.baidu.com/s/1Pa42E2q9fZ2zXLJ7vLvx8g
提取码:o2rg
--来自百度网盘超级会员V1的分享
项目结构:

#!/usr/bin/env python
# -#-coding:utf-8 -*-
# author:by ucas iie 魏兴源
# datetime:2021/11/15 19:08:03
# software:PyCharm
import os
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
from sklearn.metrics import f1_score
from tqdm import trange
from tqdm import tqdm
# 构建数据集
def build_corpus(split, data_dir):
"""
:param split: 分割类型,是训练集,验证集or测试集
:param data_dir: 数据路径
:return: word_lists(原始数据), tag_lists(标签数据), word2index, tag2index
"""
assert split in ['train', 'dev', 'test']
word_lists = []
tag_lists = []
with open(data_dir, 'r', encoding='utf-8') as f:
word_list = []
tag_list = []
for line in f:
if line != '\n':
word, tag = line.strip('\n').split()
# print("word=", word)
# print("tag=", tag)
word_list.append(word)
tag_list.append(tag)
else:
word_lists.append(word_list)
tag_lists.append(tag_list)
word_list = []
tag_list = []
# 进行排序
sorted_word_lists = sorted(word_lists, key=lambda x: len(x), reverse=False)
sorted_tag_lists = sorted(tag_lists, key=lambda x: len(x), reverse=False)
# 返回word2index tag2index
word2index = build_map(sorted_word_lists)
tag2index = build_map(sorted_tag_lists)
# print("word2index=", word2index)
# print("tag2index=", tag2index)
word2index[''] = len(word2index)
word2index[''] = len(word2index)
tag2index[''] = len(tag2index)
return word_lists, tag_lists, word2index, tag2index
# 构建word2index和tag2index字典
def build_map(lists):
"""
:param lists:
:return: 返回一个字典
"""
maps = {}
for list in lists:
for element in list:
if element not in maps:
maps[element] = len(maps)
return maps
word_lists, tag_lists, word2index, tag2index = build_corpus('train', 'data/train.txt')
# print(word2index)
# print(tag2index)
# 定义数据集对象
class MyDataset(Dataset):
# 初始化对象元素
def __init__(self, datas, tags, word_2_index, tag_2_index):
self.datas = datas
self.tags = tags
self.word_2_index = word_2_index
self.tag_2_index = tag_2_index
def __getitem__(self, index):
data = self.datas[index]
tag = self.tags[index]
#
data_index = [self.word_2_index[i] for i in data]
tag_index = [self.tag_2_index[i] for i in tag]
return data_index, tag_index
def __len__(self):
# 每句话的长度肯定和标签的长度一样
assert len(self.datas) == len(self.tags)
return len(self.tags)
# 这里是对每个batch做数据处理,进行数据的拼接
# 这batch_datas长度是batch_size中规定的那个维度
# 里面包含了data和tag
def pro_batch_data(self, batch_datas):
global device
datas = []
tags = []
batch_lens = []
for data, tag in batch_datas:
datas.append(data)
tags.append(tag)
batch_lens.append(len(data))
# print("batch_datas=", batch_datas)
# print("datas=", datas)
# print("tags=", tags)
batch_max_len = max(batch_lens)
datas = [i + [self.word_2_index[""]] * (batch_max_len - len(i)) for i in datas]
tags = [i + [self.tag_2_index[""]] * (batch_max_len - len(i)) for i in tags]
return torch.tensor(datas, dtype=torch.int64, device=device), torch.tensor(tags, dtype=torch.long,
device=device)
# 模型
class BiLSTM_CRF(nn.Module):
def __init__(self, corpus_num, embedding_num, hidden_num, class_num, biFlag=True):
"""
:param corpus_num: 训练语料长度
:param embedding_num: 词嵌入的维度
:param hidden_num: 隐藏层维度
:param class_num: 分类的种类多少
:param BiFlag: 是否为双向LSTM,默认为双向,这样的话全连接层就要有2倍的输入
"""
super().__init__()
self.embedding = nn.Embedding(corpus_num, embedding_num)
self.lstm = nn.LSTM(embedding_num, hidden_num, batch_first=True, bidirectional=biFlag)
# 损失函数
self.cross_loss = nn.CrossEntropyLoss()
if biFlag:
self.linear = nn.Linear(hidden_num * 2, class_num)
else:
self.linear = nn.Linear(hidden_num, class_num)
def forward(self, batch_data, batch_tag=None):
embedding = self.embedding(batch_data)
out, _ = self.lstm(embedding)
pre = self.linear(out)
# 预测集合中最大的那一个就是预测值
self.pre = torch.argmax(pre, dim=-1).reshape(-1)
if batch_tag is not None:
preReshape = pre.reshape(-1, pre.shape[-1])
batch_tag_reshape = batch_tag.reshape(-1)
print("preShape‘s shape", preReshape.shape)
print("batchTagReshape", batch_tag_reshape.shape)
loss = self.cross_loss(preReshape, batch_tag_reshape)
return loss
else:
return self.pre
# 测试函数,用户输入文字,看看模型运行结果
def usage():
global word_2_index, model, index_2_tag, device
while True:
text = input("输入:")
# text = "张定宇是金银潭医院的一名教授"
text_index = [[word_2_index[i] for i in text]]
print("text_index=", text_index)
text_index = torch.tensor(text_index, dtype=torch.int64, device=device)
model.forward(text_index)
pre = [index_2_tag[i] for i in model.pre]
print([f'{w}_{s}' for w, s in zip(text, pre)])
if __name__ == "__main__":
device = "cuda:0" if torch.cuda.is_available() else "cpu"
train_data, train_tag, word_2_index, tag_2_index = build_corpus("train", "data/train.txt")
dev_data, dev_tag, _, none_ = build_corpus("dev", "data/test_Demo.txt")
index_2_tag = [i for i in tag_2_index]
corpus_num = len(word_2_index)
"""
这里为什么分类的类别是tag2index的长度呢,因为命名实体识别的本质就是对每个字分类
和文本分类有思想上的相同性,所以就是标签类型的长度
"""
class_num = len(tag_2_index)
# 超参数
epoch = 5
train_batch_size = 5
dev_batch_size = 5
embedding_num = 101
hidden_num = 107
bi = True
lr = 0.001
# 搞到训练数据
train_dataset = MyDataset(train_data, train_tag, word_2_index, tag_2_index)
train_dataloader = DataLoader(train_dataset, train_batch_size, shuffle=False,
collate_fn=train_dataset.pro_batch_data)
# 验证数据
dev_dataset = MyDataset(dev_data, dev_tag, word_2_index, tag_2_index)
dev_dataloader = DataLoader(dev_dataset, dev_batch_size, shuffle=False, collate_fn=train_dataset.pro_batch_data)
# 定义模型
model = BiLSTM_CRF(corpus_num, embedding_num, hidden_num, class_num, bi)
opt = torch.optim.Adam(model.parameters(), lr=lr)
model = model.to(device)
# 定义交叉熵损失函数
cross_loss = nn.CrossEntropyLoss()
for e in trange(epoch):
model.train()
for batch_data, batch_tag in tqdm(train_dataloader):
train_loss = model.forward(batch_data, batch_tag)
train_loss.backward() # 反向传播
# 更新参数
opt.step()
opt.zero_grad()
# 开始测试
model.eval()
# 保存模型
torch.save(model, "D:\\Model")
all_pre = []
all_tag = []
for dev_batch_data, dev_batch_tag in train_dataloader:
dev_loss = model.forward(dev_batch_data, dev_batch_tag)
all_pre.extend(model.pre.detach().cpu().numpy().tolist())
all_tag.extend(dev_batch_tag.detach().cpu().numpy().reshape(-1).tolist())
score = f1_score(all_tag, all_pre, average="micro")
print(f"{e},f1_score:{score:.3f},dev_loss:{dev_loss:.3f},train_loss:{train_loss:.3f}")
# 调用测试函数
usage()
反思总结与改进
在我们运行的时候会产生一些问题
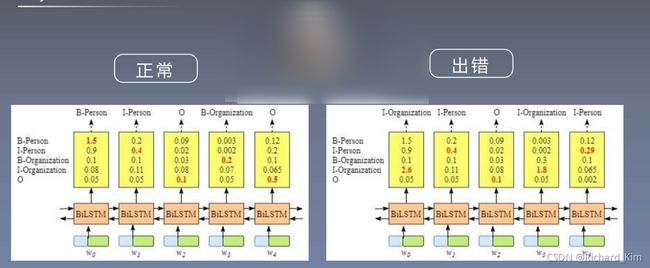
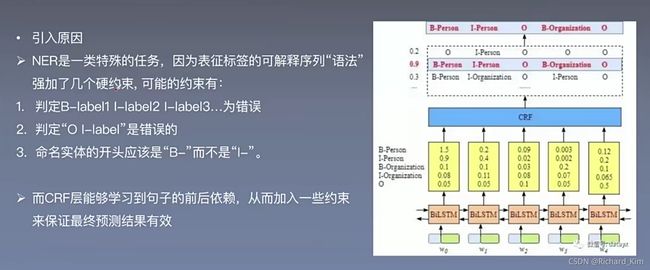
所以我们引入了条件随机场。下面这个代码有GPU加速,但是速度还是很慢很慢。找原因ing...
#!/usr/bin/env python
# -#-coding:utf-8 -*-
# author:by ucas iie 魏兴源
# datetime:2021/11/19 22:16:16
# software:PyCharm
import sys
import torch
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
from tqdm import trange
from tqdm import tqdm
from sklearn.metrics import f1_score
from torch.utils.data import Dataset, DataLoader
torch.manual_seed(1)
def argmax(vec):
# return the argmax as a python int
# 返回vec的dim为1维度上的最大值索引
_, idx = torch.max(vec, 1)
return idx.item()
# Compute log sum exp in a numerically stable way for the forward algorithm
# 前向算法是不断累积之前的结果,这样就会有个缺点
# 指数和累积到一定程度后,会超过计算机浮点值的最大值,变成inf,这样取log后也是inf
# 为了避免这种情况,用一个合适的值clip去提指数和的公因子,这样就不会使某项变得过大而无法计算
# SUM = log(exp(s1)+exp(s2)+...+exp(s100))
# = log{exp(clip)*[exp(s1-clip)+exp(s2-clip)+...+exp(s100-clip)]}
# = clip + log[exp(s1-clip)+exp(s2-clip)+...+exp(s100-clip)]
# where clip=max
def log_sum_exp(vec):
max_score = vec[0, argmax(vec)]
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
return max_score.to(DEVICE) + torch.log(torch.sum(torch.exp(vec - max_score_broadcast))).to(DEVICE)
# 构建数据集
def build_corpus(split, data_dir):
"""
:param split: 分割类型,是训练集,验证集or测试集
:param data_dir: 数据路径
:return: word_lists(原始数据), tag_lists(标签数据), word2index, tag2index
"""
assert split in ['train', 'dev', 'test']
word_lists = []
tag_lists = []
with open(data_dir, 'r', encoding='utf-8') as f:
word_list = []
tag_list = []
for line in f:
if line != '\n':
word, tag = line.strip('\n').split()
# print("word=", word)
# print("tag=", tag)
word_list.append(word)
tag_list.append(tag)
else:
word_lists.append(word_list)
tag_lists.append(tag_list)
word_list = []
tag_list = []
# 进行排序
# sorted_word_lists = sorted(word_lists, key=lambda x: len(x), reverse=False)
# sorted_tag_lists = sorted(tag_lists, key=lambda x: len(x), reverse=False)
# 返回word2index tag2index
word2index = build_map(word_lists)
tag2index = build_map(tag_lists)
# print("word2index=", word2index)
# print("tag2index=", tag2index)
word2index[''] = 0
tag2index[''] = 0
print(tag2index)
return word_lists, tag_lists, word2index, tag2index
# 构建word2index和tag2index字典
def build_map(lists):
"""
:param lists:
:return: 返回一个字典
"""
maps = {}
for list in lists:
for element in list:
if element not in maps:
maps[element] = len(maps)
return maps
# 超参数
BATCH_SIZE = 5
EMBEDDING_DIM = 50
HIDDEN_DIM = 50
EPOCH = 2
# DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
DEVICE = torch.device("cpu")
# 定义数据集对象
class MyDataset(Dataset):
# 初始化对象元素
def __init__(self, datas, tags, word_2_index, tag_2_index):
self.datas = datas
self.tags = tags
self.word_2_index = word_2_index
self.tag_2_index = tag_2_index
def __getitem__(self, index):
data = self.datas[index]
tag = self.tags[index]
data_index = []
# for i in data:
# if i in word2index:
# data_index.append(word2index[i])
# else:
# data_index.append(0)
data_index = [self.word_2_index[i] for i in data]
tag_index = [self.tag_2_index[i] for i in tag]
return data_index, tag_index
def __len__(self):
# 每句话的长度肯定和标签的长度一样
assert len(self.datas) == len(self.tags)
return len(self.tags)
# 这里是对每个batch做数据处理,进行数据的拼接
# 这batch_datas长度是batch_size中规定的那个维度
# 里面包含了data和tag
def pro_batch_data(self, batch_datas):
global device
datas = []
tags = []
batch_lens = []
for data, tag in batch_datas:
datas.append(data)
tags.append(tag)
batch_lens.append(len(data))
batch_max_len = max(batch_lens)
datas = [i + [self.word_2_index[""]] * (batch_max_len - len(i)) for i in datas]
tags = [i + [self.tag_2_index[""]] * (batch_max_len - len(i)) for i in tags]
return torch.tensor(datas, dtype=torch.int64, device=DEVICE), torch.tensor(tags, dtype=torch.long,
device=DEVICE)
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim # word embedding dim
self.hidden_dim = hidden_dim # Bi-LSTM hidden dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# 将BiLSTM提取的特征向量映射到特征空间,即经过全连接得到发射分数
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# 转移矩阵的参数初始化,transitions[i,j]代表的是从第j个tag转移到第i个tag的转移分数
self.transitions = nn.Parameter(
torch.randn(self.tagset_size, self.tagset_size))
# 初始化所有其他tag转移到START_TAG的分数非常小,即不可能由其他tag转移到START_TAG
# 初始化STOP_TAG转移到所有其他tag的分数非常小,即不可能由STOP_TAG转移到其他tag
self.transitions.data[tag_to_ix[START_TAG], :] = -10000
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000
self.hidden = self.init_hidden()
def init_hidden(self):
# 初始化LSTM的参数
return (torch.randn(2, 1, self.hidden_dim // 2).to(DEVICE),
torch.randn(2, 1, self.hidden_dim // 2).to(DEVICE))
def _get_lstm_features(self, sentence):
# 通过Bi-LSTM提取特征
self.hidden = self.init_hidden()
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
def _score_sentence(self, feats, tags):
# 计算给定tag序列的分数,即一条路径的分数
score = torch.zeros(1).to(DEVICE)
tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long).to(DEVICE), tags])
for i, feat in enumerate(feats):
# 递推计算路径分数:转移分数 + 发射分数
score = score + self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score
def _forward_alg(self, feats):
# 通过前向算法递推计算
init_alphas = torch.full((1, self.tagset_size), -10000.).to(DEVICE)
# 初始化step 0即START位置的发射分数,START_TAG取0其他位置取-10000
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# 将初始化START位置为0的发射分数赋值给previous
previous = init_alphas
# 迭代整个句子
for obs in feats:
# The forward tensors at this timestep
# 当前时间步的前向tensor
alphas_t = []
for next_tag in range(self.tagset_size):
# 取出当前tag的发射分数,与之前时间步的tag无关
emit_score = obs[next_tag].view(1, -1).expand(1, self.tagset_size).to(DEVICE)
# 取出当前tag由之前tag转移过来的转移分数
trans_score = self.transitions[next_tag].view(1, -1)
# 当前路径的分数:之前时间步分数 + 转移分数 + 发射分数
next_tag_var = previous.to(DEVICE) + trans_score.to(DEVICE) + emit_score.to(DEVICE)
# 对当前分数取log-sum-exp
alphas_t.append(log_sum_exp(next_tag_var).view(1))
# 更新previous 递推计算下一个时间步
previous = torch.cat(alphas_t).view(1, -1)
# 考虑最终转移到STOP_TAG
terminal_var = previous + self.transitions[self.tag_to_ix[STOP_TAG]]
# 计算最终的分数
scores = log_sum_exp(terminal_var)
return scores.to(DEVICE)
def _viterbi_decode(self, feats):
backpointers = []
# 初始化viterbi的previous变量
init_vvars = torch.full((1, self.tagset_size), -10000.).cpu()
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
previous = init_vvars
for obs in feats:
# 保存当前时间步的回溯指针
bptrs_t = []
# 保存当前时间步的viterbi变量
viterbivars_t = []
for next_tag in range(self.tagset_size):
# 维特比算法记录最优路径时只考虑上一步的分数以及上一步tag转移到当前tag的转移分数
# 并不取决与当前tag的发射分数
next_tag_var = previous.cpu() + self.transitions[next_tag].cpu()
best_tag_id = argmax(next_tag_var)
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
# 更新previous,加上当前tag的发射分数obs
previous = (torch.cat(viterbivars_t).cpu() + obs.cpu()).view(1, -1)
# 回溯指针记录当前时间步各个tag来源前一步的tag
backpointers.append(bptrs_t)
# 考虑转移到STOP_TAG的转移分数
terminal_var = previous.cpu() + self.transitions[self.tag_to_ix[STOP_TAG]].cpu()
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# 通过回溯指针解码出最优路径
best_path = [best_tag_id]
# best_tag_id作为线头,反向遍历backpointers找到最优路径
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# 去除START_TAG
start = best_path.pop()
assert start == self.tag_to_ix[START_TAG] # Sanity check
best_path.reverse()
return path_score, best_path
def neg_log_likelihood(self, sentence, tags):
# CRF损失函数由两部分组成,真实路径的分数和所有路径的总分数。
# 真实路径的分数应该是所有路径中分数最高的。
# log真实路径的分数/log所有可能路径的分数,越大越好,构造crf loss函数取反,loss越小越好
# print("len=", len(sentences))
# print("sentence=", sentences)
# print("tags=", tags)
feats = self._get_lstm_features(sentence)
forward_score = self._forward_alg(feats)
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
# 这里LSTM和CRF共同前向输出
def forward(self, sentence):
sentence = sentence.reshape(-1)
# 通过BiLSTM提取发射分数
lstm_feats = self._get_lstm_features(sentence)
# 根据发射分数以及转移分数,通过viterbi解码找到一条最优路径
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
START_TAG = ""
STOP_TAG = ""
# 构造一些训练数据,测试数据
train_data, train_tag, word2index, tag2index = build_corpus('train', 'data/train_Demo.txt')
dev_data, dev_tag, word2index_dev, tag2index_dev = build_corpus("dev", "data/test_Demo.txt")
print(len(train_data))
print(len(dev_data))
tag_to_ix = {'O': 0, 'B-LOC': 1, 'I-LOC': 2, 'B-ORG': 3, 'I-ORG': 4, 'B-PER': 5, 'I-PER': 6, START_TAG: 7, STOP_TAG: 8,
'': 9}
# 搞到训练数据
train_dataset = MyDataset(train_data, train_tag, word2index, tag_to_ix)
# print("train_dataset'getItem=", train_dataset.getListItem())
train_dataloader = DataLoader(train_dataset, BATCH_SIZE, shuffle=False, collate_fn=train_dataset.pro_batch_data)
# 验证数据
dev_dataset = MyDataset(dev_data, dev_tag, word2index_dev, tag_to_ix)
dev_dataloader = DataLoader(dev_dataset, BATCH_SIZE, shuffle=False, collate_fn=dev_dataset.pro_batch_data)
# 定义模型
model = BiLSTM_CRF(len(word2index), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM).to(DEVICE)
# 优化函数
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
for epoch in trange(EPOCH):
for sentences, tags in tqdm(train_dataloader):
sentences = sentences.reshape(-1)
tags = tags.reshape(-1)
# print("sentences=", sentences)
# print("tags= ", tags)
# 第一步,pytorch梯度累积,需要清零梯度
model.zero_grad()
# 第二步,得到loss
loss = model.neg_log_likelihood(sentences, tags).cuda()
print("crf loss=", loss)
# 第三步,计算loss,梯度,通过optimier更新参数
loss.backward()
optimizer.step()
# 开始测试
model.eval()
# 用于计算f1_score
all_pre = []
all_tag = []
for dev_sentences, dev_tags in tqdm(dev_dataloader):
# 预测的结果
dev_sentences.view(-1)
dev_tags.view(-1)
dev_pre_score, dev_pre_tag = model.forward(dev_sentences)
# print("dev_pre_score", dev_pre_score)
# print("dev_pre_tag", dev_pre_tag)
# 预测的值放入集合中用于计算f1_score,f1_score的输入是两个list和一个average函数
all_pre.extend(dev_pre_tag)
print("dev_pre_tags=", dev_pre_tag)
print("dev_tags=", dev_tags)
# 把测试集的tag拍平
dev_tags_flat = dev_tags.detach().cpu().reshape(-1).tolist()
# 标签值放入集合
all_tag.extend(dev_tags_flat)
# print("dev_data_tag", tagFromDev)
# 计算f1_score
score = f1_score(all_tag, all_pre, average="micro")
print("f1_score:", score)
不知道什么问题,有了GPU速度还是很慢,训练集只跑了两个epocch,第一个epoch之后测试集在模型的f1_score≈92%。

第二个epoch之后测试集在模型的f1_score≈92%
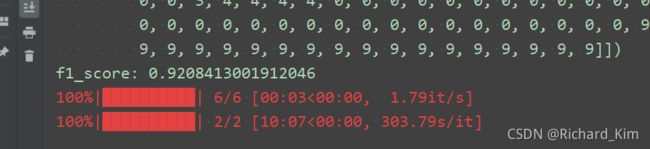
目前正在找原因