Matlab吴恩达机器学习编程练习ex2:逻辑回归Logistic Regression
这篇文章是基于bilibili的吴恩达机器学习经典名课【中英字幕】所写的第三周的编程练习,这个作业是关于逻辑回归的。
作业大纲
- 1 逻辑回归
-
- 1.1 数据可视化
- 1.2 具体实现过程
-
- 1.2.1 热身练习:sigmoid函数sigmoid.m
- 1.2.2 代价函数梯度 costFunction.m
- 1.2.3 使用fminunc函数调参
- 1.2.4 评估逻辑回归 predict.m
- 2 正则化逻辑回归
-
- 2.1 数据可视化
- 2.2 特征映射 mapFeature.m
- 2.3 代价函数和梯度 costFunctionReg.m
-
- 2.3.1 使用fminunc函数调参
- 2.4 画出决策边界
- 2.5 选做练习
- 总结
1 逻辑回归
这是一个预测学生能否被大学录取的二分类问题。问题给了学生两门考试的成绩以及能否被录取的结果。在这个部分,有一个ex2.m的主函数,以及辅助运行需要你去完成的子函数。
1.1 数据可视化
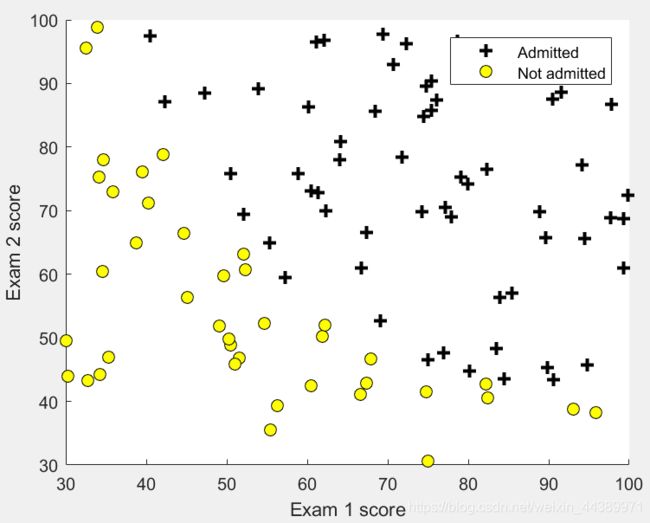
就是将两门成绩画在平面坐标轴上,然后是否录取要分开标识出来,并且将plotData.m函数补充完整。
function plotData(X, y)
figure; hold on;
pos = find(y==1); neg = find(y==0);
plot(X(pos,1),X(pos,2),'k+','LineWidth',2,'MarkerSize', 7);
plot(X(neg, 1), X(neg, 2), 'ko', 'MarkerFaceColor', 'y', 'MarkerSize', 7);
hold off;
end画出来的图像是这样的:
1.2 具体实现过程
1.2.1 热身练习:sigmoid函数sigmoid.m
这个部分是要我们完成sigmoid函数的表示方法,同时要支持向量,这个就是对于输入的z的每一个值都计算他的sigmoid值就可以了,那就是用向量的点乘即可。
function g = sigmoid(z)
g = 1 ./ (1 + exp(-z));
end1.2.2 代价函数梯度 costFunction.m
给出逻辑回归的代价函数,以及各个梯度的公式,要求你在 costFunction.m 这个函数中,将这两个公式进行实现,需要注意的是,这些变量都是矩阵之间的计算。
代价函数:

梯度:

function [J, grad] = costFunction(theta, X, y)m = length(y); % number of training examples
h = sigmoid(X*theta);
J = (-y'*log(h)-(1-y)'*log(1-h))/m;
grad = X'*(h-y)/m;
% =============================================================
end1.2.3 使用fminunc函数调参
这个就不用做什么,老师把代码都写在ex2.m这个函数里面。就是使用fminunc这个函数,并且调用你自己写的costFunction.m就可以了。
1.2.4 评估逻辑回归 predict.m
对于自己已经选好的最合适的参数,怎么去检验这个模型的好坏呢?应用自己的模型在训练集上进行测试,看看预测的准确率。完成predict.m函数。
function p = predict(theta, X)
p = sigmoid(X*theta);
n = length(p);
for i=1:n
if p(i)>=0.5
p(i) = 1;
else
p(i) = 0;
end
end
% =========================================================================
end2 正则化逻辑回归
对于正则化,就是为了避免所选的模型过拟合overfit,过拟合就是指在训练集样本上拟合得很好,但是其泛化能力很差,即不能有效地应用在测试样本上。正则化就是在原有的代价函数上增加惩罚项,使所选取的参数不能无限制的大。
在这个部分,给到的是预测制造工厂的微芯片是否通过质量保证(QA),训练集还是为两个测试的分数,以及能否通过的0-1变量。这个部分的主函数是ex2 reg.m 。
2.1 数据可视化
还是一样,拿到数据就尽量可视化在坐标轴上面。这个部分都不用改,直接用上面的plotData函数即可。得到的图形:
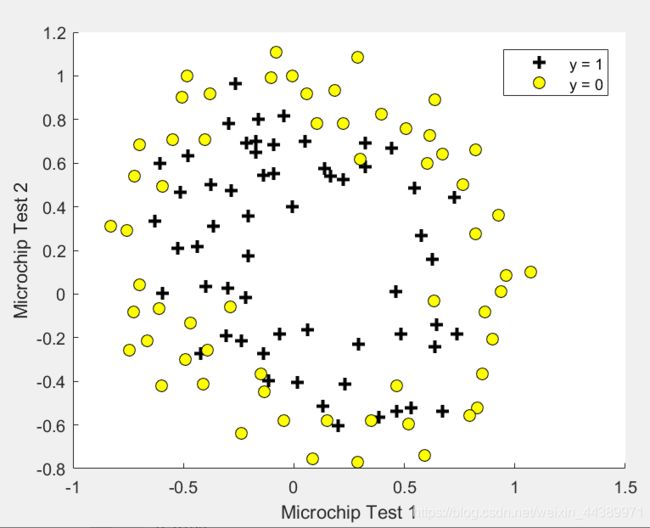
从图上就可以看出来,这次的模型一定会比较复杂一些。
2.2 特征映射 mapFeature.m
对于更好拟合这个问题,我们可以采用增加特征的方法。在已经给出的mapFeature.m这个函数中,将x1和x2的所有多项式项都升幂到了6次。

一共有28项,(1+7)*7/2=28.
2.3 代价函数和梯度 costFunctionReg.m
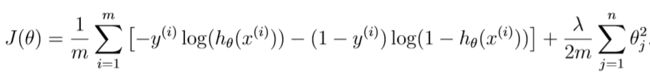
这个就是加了正则项的代价函数。
梯度:

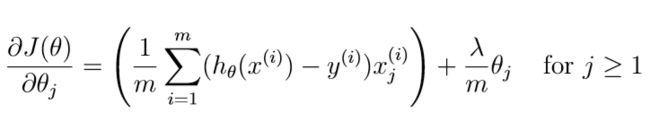
注意这里的theta(0)要分开写。
2.3.1 使用fminunc函数调参
老师把代码都写在ex2_reg.m这个函数里面。就是使用fminunc这个函数,并且调用你自己写的costFunctionReg.m就可以了。
2.4 画出决策边界
也不用自己动手

2.5 选做练习
就是改变正则化参数λ的值,看看边界会发生什么变化,我这里就不演示啦。
总结
其实我觉得老师布置的题目还是少了一点力度,就是说老师帮我们做的太多啦。但是对于这种要上交评分的作业,可能是要规定一些格式吧,能做到这样子已经很棒啦。
我也是在上了老师的课之后才真正地了解到一些自己在用的算法到底是什么做到的,总之就是很有意思的东西。
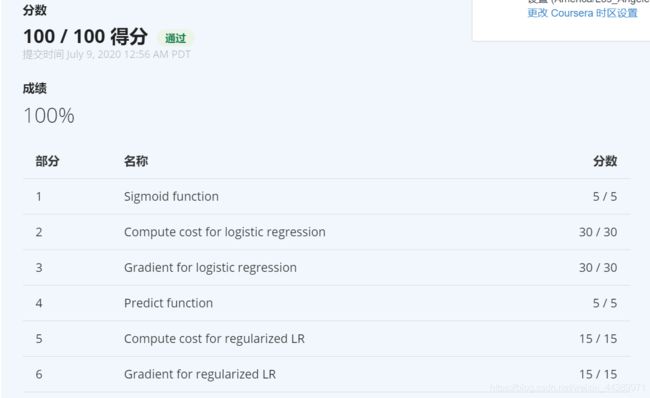
我的成绩: