BEIT: BERT Pre-Training of Image Transformers(图像Transformer的BERT预训练)
文章目录
- 摘要
- 1. Introduction
- 2. 方法
-
- 2.1 图像表示
-
- 2.1.1 Image Patch(图像块)
- 2.1.2 Visual Token
- 2.2 Backbone Network:Image Transformer
- 2.3 预训练BEiT:Masked Image Modeling
- 2.4 From the Perspective of VAE(从VAE视角进行解释)
- 2.5 预训练设置
- 2.6 Fine-Tuning BEiT on Downstream Vision Tasks(下游任务微调)
- 3 实验
-
- 3.1 图像分类
- 3.2 语义分割
- 3.3 消融研究
- 3.4 Self-Attention Map分析
- 4. 相关工作
-
- 4.1 自监督视觉表示学习
- 4.2 自监督ViT
- 4.3 BERT-style pre-training in NLP
- 5. 结论
题目:BEIT: BERT Pre-Training of Image Transformers
论文:PDF
论文:Code
Publish Year: 2021
摘要
文中介绍了自监督视觉表示模型BEiT(Bidirectional Encoder Image Transformers)。受BERT在NLP领域中的表现,文中提出masked image modeling(掩码图像建模)任务来预训练Vision Transformer。在预训练中,每张图像有两个视角,第一:image patches(比如16 x 16像素),第二:vision tokens(离散tokens)。首先,讲原始图像tokenize为visual tokens;然后,随机掩盖(遮蔽)一些image patches后将其输入backbone Transformer。pre-training(预训练)的目标是基于掩盖的image patches来恢复原有visual tokens。预训练BEiT之后,可以通过在预训练的encoder上添加特定任务的层,直接对下游任务的模型参数进行微调。在图像分类贺语义分割数据集上的结果展示,BEiT取得了与之前预训练方法(从头开始预训练的模型)相当的结果。比如,在同样设置条件下,base-size的BEiT在ImageNet-1K上的top-1准确率达83.2%,超过从头开始预训练模型DeiT取得的81.8%的准确率。而large-size的BEiT在ImageNet-1K上top-1准确率达86.3%,超过ViT-L在ImageNet-22K上监督训练的结果(85.2%)。
1. Introduction
2017年,Transformer经过近几年的发展,在CV领域,表现可谓十分出众。但是研究表明,vision Transformer相比CNN需要更多的训练数据,而自监督预训练则可以利用大规模图像数据来克服data-hungry问题。
2019年,Google提出BERT,在NLP业界产生巨大颠覆性影响。在BERT当中,masked language modeling(MLM,遮蔽语言模型)首先随机掩盖文本tokens的一部分,然后根据Transformer编码corrupted text(掩盖文本)的结果恢复masked tokens。在BERT启发下以及业界研究人员的关注度上,进而去研究denoising auto-encoding(去噪自编码器)来预训练ViT。直接将BERT-style应用到图像数据中,是一个很大的挑战,一种直观的想法就是将该任务视作为一个回归问题,即预测masked patches的原始像素,但这种像素级别的恢复任务往往会将建模能力浪费在短程依赖贺高频细节上。这篇论文的目标就是克服ViT的这种问题。
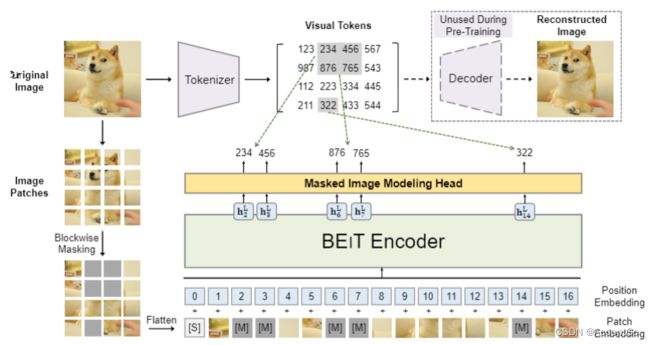
图一:BEiT预训练概览。预训练之前,通过自编码器学习一个image tokenizer,其根据学习到的vocabulary,可以将一幅图像tokenized为离散visual tokens。在预训练期间,每个图像有两种视角:image patches和visual tokens。随机掩盖Image patches的一部分,并且用特定的mask embedding [M]替换,然后将patches输入到backbone vision Transformer。预训练任务的目的就是根据corrupted image(掩盖图像)的编码向量预测原始图像的visual tokens。
文中介绍了自监督vision representation model (BEiT),其是Image Transformer的Bidirectional Encoder(双向编码器)表示。受BERT影响,提出一个预训练任务Masked image modeling(MIM)(该paper之重点)。把图像切分为patches作为backbone Transformer的输入。此外,通过离散变分自编码器将图像tokenize为离散visual tokens。模型学习恢复原始图像的visual tokens,而不是masked patches的原始像素。
为验证BEiT的有效性,对预训练后的BEiT在两个下游任务:图像分类和语义分割上做微调。实验结果表明,BEiT优于之前从0开始训练的自监督模型。此外,其收敛速度和训练成本(微调减少了训练成本)都得到一定提升。同时,还证明了自监督BEiT通过预训练学习到合理的semantic regions(语义区域),大有发展之劲头。
该Paper主要贡献如下:
- 提出
masked image modeling(MIM)任务并以自监督方式预训练Vision Transformer,并从变分自编码器视角对其进行理论解释。 - 预训练
BEiT,并应用到下游任务图像分类和语义分割中(下游任务数据集中微调BEiT)。 - 提出自监督
BEiT的self-attention机制可以学习区分semantic regions(语义区域)和object boundaries(对象边界),即使是无标注数据。
2. 方法
给定输入图像x,BEiT将其编码为上下文向量表示。如图一所示,BEiT通过MIM任务以自监督学习方式完成预训练。MIM目标在于基于编码向量恢复掩盖的image patches。对于下游任务,比如图片分类、语义分割,通过在预训练的BEiT添加相关任务层,并且在特定任务数据集上微调BEiT参数。
2.1 图像表示
该paper中一个图像有两种表示视角:image patch 和visual tokens,分别作为预训练的输入和输出表示。
2.1.1 Image Patch(图像块)
将二维图像分割为patches序列,这样才可以使标准Transformer直接接受图像数据。形式上,要把图像 x ∈ R H × W × C x \in R^{H \times W \times C} x∈RH×W×C 切分为 N = H W P 2 N=\frac{HW}{P^2} N=P2HW 个patches,每一块 x p ∈ R N × ( P 2 C ) x^p \in R^{N \times (P^2C)} xp∈RN×(P2C),其中 C C C 是通道数, ( H , W ) (H,W) (H,W) 是输入图像的分辨率, ( P , P ) (P,P) (P,P) 是每个patch的分辨率。将image patches { x i p } i = 1 N \{x_i^p\}_{i=1}^N {xip}i=1N flatten(平铺)为向量并进行线性映射(这里的话类似于BERT中的word embedding)。Image patches 保存原始像素,并在预训练BEiT中作为输入特征。
在该paper实验中,将 224 × 224 224 \times 224 224×224的图像分割为 14 × 14 14 \times 14 14×14个image patches,每一个patch为 16 × 16 16 \times 16 16×16。
2.1.2 Visual Token
类似于自然语言,通过image tokenizer将图像表示为离散tokens序列,而不是图像像素。对于图像 x ∈ R H × W × C x \in R^{H \times W \times C} x∈RH×W×C ,将其tokenize为 z = [ z 1 , z 2 , . . . , z N ] ∈ V h × w z=[z_1,z_2,...,z_N] \in V^{h \times w} z=[z1,z2,...,zN]∈Vh×w,其中, V = { 1 , . . . , ∣ V ∣ } V=\{ 1,...,|V|\} V={1,...,∣V∣}是离散token indices。
这里通过离散变分自编码器学习到image tokenizer。在visual token学习期间,有两个模块:tokenizer和decoder。tokenizer q Φ ( z ∣ x ) q_{\Phi}(z|x) qΦ(z∣x)根据visual codebook映射图像像素x为离散tokenz。decoder p ψ ( x ∣ z ) p_{\psi}(x|z) pψ(x∣z)基于visual token z z z 重构输入图像x。重构目标为:
E z ∽ q Φ ( z ∣ x ) [ l o g p ψ ( x ∣ z ) ] E_{z \backsim q_{\Phi}(z|x)} [log_{p_{\psi}}(x|z)] Ez∽qΦ(z∣x)[logpψ(x∣z)]
因为潜在的visual tokens是离散的,所以模型训练不可微。这里使用Gumbel-softmax relaxation来训练模型参数,而且在离散变分自编码器训练期间,对 q Φ q_{\Phi} qΦ进行统一先验检测。
tokenize每张图像为 14 × 14 14 \times 14 14×14个visual tokens。这里对于一幅图像,visual tokens的数量和image patches的数量是相同的。vocabulary size ∣ V ∣ = 8192 |V|=8192 ∣V∣=8192。
2.2 Backbone Network:Image Transformer
同ViT一样,这里仍使用标准Transformer作为backbone network。
Transformer的输入是image patches序列 { x i p } i = 1 N \{x_i^p\}_{i=1}^N {xip}i=1N ,patches线性映射得到patch embeddings E x i p Ex_i^p Exip,其中, E ∈ R ( P 2 C ) × D E \in R^{(P^2C) \times D} E∈R(P2C)×D,此外,在输入序列前添加一个特殊token [S]。并且添加标准可学习一维position embeddings(位置嵌入) E p o s ∈ R N × D E_{pos} \in R ^{N \times D} Epos∈RN×D 到patch embeddings。则Transformer的输入向量为 H 0 = [ e [ S ] , E x i p , . . . , E x N p ] + E p o s H_0=[e_{[S]},E x_i^p ,...,Ex_N^p]+E_{pos} H0=[e[S],Exip,...,ExNp]+Epos。encoder包含L层Transformer blocks H l = T r a n s f o r m e r ( H l − 1 ) H^l =Transformer(H^{l-1}) Hl=Transformer(Hl−1),其中, l = 1 , 2 , . . . , L l=1,2,...,L l=1,2,...,L。最后一层输出向量 H L = [ h [ S ] L , H 1 L , . . . , h N L ] H^L=[h_{[S]}^L,H_1^L,...,h_N^L] HL=[h[S]L,H1L,...,hNL]作为image patches的编码表示,其中 h i L h_i^L hiL 是第 i i i个image patch的向量。
2.3 预训练BEiT:Masked Image Modeling
paper中提出masked image modeling(MIM)任务来预训练BEiT,即随机掩盖一部分image patches,然后预测对应掩盖patches的visual tokens。
图一中展示了MIM,正如2.1小节,给定输入图像x,将其分割为N个image patches ( { x i p } i = 1 N ) (\{x_i^p\}_{i=1}^N) ({xip}i=1N)和N个visual tokens ( { z i } i = 1 N ) (\{z_i\}_{i=1}^N) ({zi}i=1N)。随机掩盖约40%的image patches,所掩盖的位置标记为 M ∈ { 1 , . . . , N } 0.4 N M \in \{ 1,...,N\}^{0.4N} M∈{1,...,N}0.4N。然后使用一个学习到的embedding e [ M ] ∈ R D e_{[M]} \in R^D e[M]∈RD替换掩盖的patches。被掩盖的image patches x M = { x i p : i ∉ M } i = 1 N ∪ { e [ M ] : i ∈ M } i = 1 N x^M=\{x_i^p: i \notin M \}_{i=1}^N \cup \{ e_{[M]}: i \in M\}_{i=1}^N xM={xip:i∈/M}i=1N∪{e[M]:i∈M}i=1N输入到2.2节描述的L层Transformer。最后隐层向量 { h i L } i = 1 N \{h_i^L\}_{i=1}^N {hiL}i=1N 是输入patches的编码表示。对于每一个掩盖位置 { h i L : i ∈ M } i = 1 N \{h_i^L :i \in M\}_{i=1}^N {hiL:i∈M}i=1N,用一个Softmax分类器预测masked image patches对应的visual tokens P M I M ( z ′ ∣ x M ) = s o f t m a x z ′ ( W c h i L + b c ) P_{MIM} (z'|x^M) =softmax_{z'}(W_c h_i^L +b_c) PMIM(z′∣xM)=softmaxz′(WchiL+bc),其中, x M x^M xM是掩盖的图像, W c ∈ R ∣ V ∣ × D , b c ∈ R ∣ V ∣ W_c \in R^{|V| \times D},b_c \in R^{|V|} Wc∈R∣V∣×D,bc∈R∣V∣。预训练的目标就是给定图像(包括masked images)最大化正确的visual token的对数似然函数,如下:
m a x ∑ x ∈ D E M [ ∑ i ∈ M l o g P M I M ( z i ∣ x M ) ] max \sum_{x \in D} E_M \left[\sum_{i \in M} log P_{MIM}(z_i |x^M) \right] maxx∈D∑EM[i∈M∑logPMIM(zi∣xM)]
其中, D D D是训练预料库,M表示随机掩盖位置, x M x^M xM 是根据位置M对应的掩盖图像。
该paper并没有随机选择掩盖位置M的patches,而是采用blockwise masking。blockwise算法如下:
# Algorithm 1: Blockwise Masking
Input: N(=h x w) image patches
Output: Masked positions M
M ← {}
repeat
s ← Rand(16,0.4N - |M|) # Block size
r ← Rand(0.3,1/0.3) # Aspect ratio of block
a ← sqrt(s.r);b ← sqrt(s/r)
t ← Rand(0,h-1);l ← Rand(0,w-b)
M ← M ∪ {(i,j):i ∈[t,t+a],j ∈ [l,l+b])}
until |M| >0.4N # Masking ratio 为40%
return M
对于每个block,设置patches最小数量为16。然后为masking block随机选择一个aspect ratio,重复上述步骤直到达到足够的masked patches(0.4N),其中N是image patches的总数,0.4是masking ratio。
MIM任务受masked language modeling(MLM)启发,并且blockwise(或n-gram)掩盖也被广泛应用于BERT-like模型中。然而,在视觉预训练中直接使用像素级自编码器会使模型专注于short-range依赖和high-frequency细节。而BEiT通过预测离散visual tokens(更抽象的细节表示)克服了上述问题,进一步在3.3节的消融研究证明所提出的方法优于像素级自编码器。
2.4 From the Perspective of VAE(从VAE视角进行解释)
这一小节从变分自编码器视角对BEiT进行了解释。BEiT预训练可以被看做是变分自编码器训练。假设 x x x 表示原始图像, x ~ \widetilde{x} x 表示掩盖图像, z z z为visual token。考虑对数似然函数 p ( x ∣ x ~ ) p(x|\widetilde{x}) p(x∣x )的Evidence Lower Bound(ELBO),证据下界。从掩盖图像中恢复原始图像:
∑ ( x i , x ~ i ) ∈ D log p ( x i ∣ x ~ i ) ≥ ∑ ( x i , x ~ i ) ∈ D ( E z i ∼ q ϕ ( z ∣ x i ) [ log p ψ ( x i ∣ z i ) ] ⏟ Visual Token Reconstruction − D K L [ q ϕ ( z ∣ x i ) , p θ ( z ∣ x ~ i ) ] ) ( 2 ) \sum_{\left(x_{i}, \tilde{x}_{i}\right) \in \mathcal{D}} \log p\left(x_{i} \mid \tilde{x}_{i}\right) \geq \sum_{\left(x_{i}, \tilde{x}_{i}\right) \in \mathcal{D}}(\underbrace{\mathbb{E}_{z_{i} \sim q_{\phi}\left(\mathbf{z} \mid x_{i}\right)}\left[\log p_{\psi}\left(x_{i} \mid z_{i}\right)\right]}_{\text {Visual Token Reconstruction }}-D_{\mathrm{KL}}\left[q_{\phi}\left(\mathbf{z} \mid x_{i}\right), p_{\theta}\left(\mathbf{z} \mid \tilde{x}_{i}\right)\right]) \quad(2) (xi,x~i)∈D∑logp(xi∣x~i)≥(xi,x~i)∈D∑(Visual Token Reconstruction Ezi∼qϕ(z∣xi)[logpψ(xi∣zi)]−DKL[qϕ(z∣xi),pθ(z∣x~i)])(2)
其中,
- q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x) 表示获得
visual tokens的image tokenizer。 - p ψ ( x ∣ z ) p_{\psi}(x|z) pψ(x∣z) 解码原始图像给定输入
visual tokens。 - p θ ( z ∣ x ~ ) p_{\theta}(z|\widetilde{x}) pθ(z∣x )基于掩盖图像恢复
visual tokens,这是MIM预训练任务。
模型学习分为两个阶段,第一阶段,由离散变分自编码器获得image tokenizer(最小化重构损失 − E z i ∼ q ϕ ( z ∣ x i ) [ log p ψ ( x i ∣ z i ) ] -\mathbb{E}_{z_{i} \sim q_{\phi}\left(\mathbf{z} \mid x_{i}\right)}\left[\log p_{\psi}\left(x_{i} \mid z_{i}\right)\right] −Ezi∼qϕ(z∣xi)[logpψ(xi∣zi)])。第二阶段,保持 p θ 和 q ϕ p_{\theta}和q_{\phi} pθ和qϕ固定,学习先验分布 p θ p_{\theta} pθ 。并且使用最可能的visual tokens z i ^ = a r g m a x z q ϕ ( z ∣ x i ) \hat{z_i}=arg max_z q_{\phi}(z|x_i) zi^=argmaxzqϕ(z∣xi)简化 q ϕ ( z ∣ x i ) q_{\phi}\left({z} | x_{i}\right) qϕ(z∣xi)为one-point分布,所以(2)式重写为:
∑ ( x i , x ~ i ) ∈ D ( E z i ∼ q ϕ ( z ∣ x i ) [ log p ψ ( x i ∣ z i ) ] ⏟ Stage 1: Visual Token Reconstruction + log p θ ( z ^ i ∣ x ~ i ) ⏟ Stage 2: Masked Image Modeling ) \sum_{\left(x_{i}, \tilde{x}_{i}\right) \in \mathcal{D}}(\underbrace{\mathbb{E}_{z_{i} \sim q_{\phi}\left(z \mid x_{i}\right)}\left[\log p_{\psi}\left(x_{i} \mid z_{i}\right)\right]}_{\text {Stage 1: Visual Token Reconstruction }}+\underbrace{\log p_{\theta}\left(\hat{z}_{i} \mid \tilde{x}_{i}\right)}_{\text {Stage 2: Masked Image Modeling }}) (xi,x~i)∈D∑(Stage 1: Visual Token Reconstruction Ezi∼qϕ(z∣xi)[logpψ(xi∣zi)]+Stage 2: Masked Image Modeling logpθ(z^i∣x~i))
其中,第二项就是BEiT预训练的目标。
2.5 预训练设置
为进行有效比较,BEiT网络架构遵循ViT-Base架构。使用12层Transformer,带有768个隐藏单元和12个attention heads。前馈网络的中间规模是3072。这里默认为 16 × 16 16 \times 16 16×16的输入patch大小。直接使用论文Zero-Shot Text-to-Image Generation中训练过的image tokenizer。visual tokens的vocabulary大小为8192。
在ImageNet-1K数据集上预训练BEiT,该数据集包含1200万张图片。这里使用到的数据增强策略有:random resized cropping(随机裁剪)、horizontal flipping(水平翻转)、color jittering(颜色数据增强),注意到自监督训练并不使用数据标签。实验中图像的分辨率均为 224 × 224 224 \times 224 224×224,因此,输入分割为 14 × 14 14 \times 14 14×14的image patches,其数量同visual tokens的数量相当,实验中最大掩盖75个patches(总量的40%)。
预训练以2k的batch size,500k的steps训练800个epochs,训练使用的是Adam优化器,其中 β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9,\beta_2=0.999 β1=0.9,β2=0.999;学习率设置为 l r = 1.5 e − 3 lr=1.5e-3 lr=1.5e−3,预热10个epochs,并使用cosine learning rate decay)(学习率衰减策略)。权重衰减设置为0.05,并弃用dropout。执行500k的training steps(iteration)需要使用16块Nvidia Telsa V100 32GB GPU5天时间。
2.6 Fine-Tuning BEiT on Downstream Vision Tasks(下游任务微调)
预训练BEiT之后,在Transformer上添加一个下游任务层,并在下游任务的标注数据集上进行微调。这里下游任务为:图像分类和语义分割。当然也可以应用于其他下游任务。
- 图像分类 :对于图像分类,直接添加一个简单的线性分类器作为下游任务层。具体来说,就是使用平均池化聚合向量表示,然后将这些信息输入到
softmax分类器。分类概率通过 s o f t m a x ( a v g ( { h i L } i = 1 N ) ) softmax(avg(\{h_i^L\}_{i=1}^N)) softmax(avg({hiL}i=1N))计算, h i L h_i^L hiL 是第 i i i个image patch的最终编码向量, W c ∈ R D × C W_c \in R^{D \times C} Wc∈RD×C是参数矩阵, C C C是标签的数量。通过更新BEiT和softmax分类器参数来最大化标签数据的可能性。 - 语义分割:使用SETR-PUP作为
task layer,具体说,使用预训练的BEiT为backbone编码器,结合多个反卷积层作为解码器进行分割。类似于图像分类,这里也是端到端微调。 - 中间微调:在自监督预训练之后,可以进一步在数据丰富的中间数据集上训练
BEiT,然后再目标下游任务上微调模型。这种做法在NLP领域中,经常可以看到BERT做类似的微调。
3 实验
该paper在图像分类和语义分割上进行实验,并展现了预训练的各种消融研究,对BEiT学习到的特征进行分析。
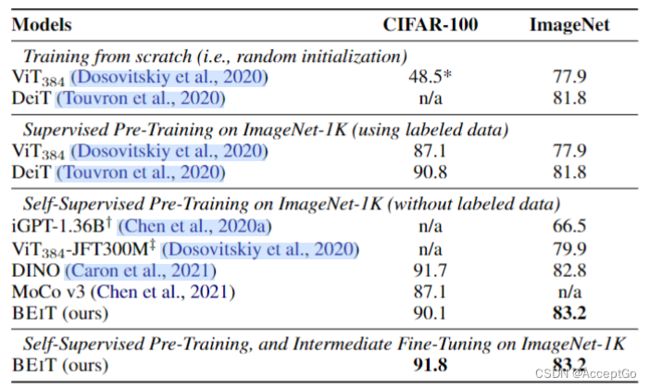
表1:图像分类任务在CIFAR-100和ImageNet-1K上的 Top-1 准确率。其中,除了 V i T 384 和 V i T 384 − J F T 300 M ViT_{384}和ViT_{384}-JFT300M ViT384和ViT384−JFT300M使用图像分辨率为 384 × 384 384 \times 384 384×384,其余模型使用的图像分辨率 224 × 224 224 \times 224 224×224。除特别说明之外,所有结果均为base-size的模型得到。 ∗ : *: ∗:结果来自包含13.6亿个参数的iGPT-1.36B,ViT-JFT300M是在Google in-house 300M images上以masked patch prediction任务进行的预训练。
3.1 图像分类
为做有效比较,在微调实验中,直接使用DeiT的绝大多数超参数,因为BEiT已经预训练过,所以较少了fine-tuning epochs,并且使用更大的layer-wise decay(分层衰减)的学习率。
表1是在图像分类任务上的top-1准确率。将BEiT与通过随机初始化、监督预训练和之前自监督学习方法的ViT进行比较。除iGPT有13.6亿个参数外,所有的模型大小均为base-size。除ViT-JFT300M是在Google in-house 300M images上预训练外,其余模型预训练均在ImageNet上完成。
在CIFAR-100数据集中,ViT从头开始训练仅有48.5%的准确率,而BEiT则达到了90.1%的准确率。这个结果证明了BEiT的有效性,所以可以大大降低标准工作量。同样,BEiT提高了在ImageNet上的性能,说明了在较大规模数据下的有效性。
此外,也将BEiT同之前基于Transformer的SOTA方法进行比较,比如DINO和MoCo v3。BEiT在ImageNet上微调的结果优于之前模型。iGPT使用clustered image tokens作为图像GPT和图像BERT的输入和输出,作为对比,BEiT使用image patches作为输入保存原始像素,并使用离散visual tokens作为预测bottleneck(瓶颈)。ViT-JFT300预测每个掩盖图像的mean和3-bit color,而不是预测由离散变分自编码器学习到的visual tokens。
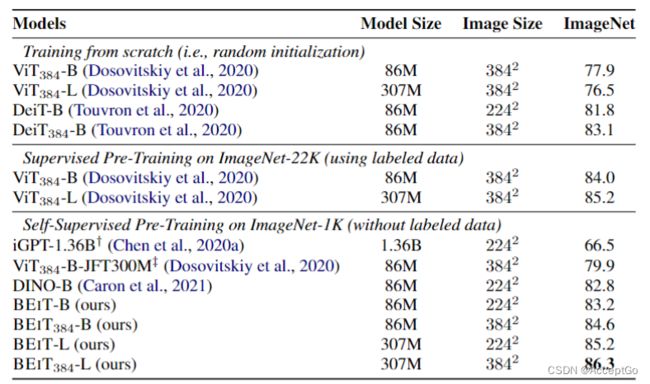
表2:ImageNet-1K上的Top-1准确率。这里评估了分辨率在 224 × 224 和 384 × 384 224 \times 224和384 \times 384 224×224和384×384base-("-B")和large-size("-L")的模型。iGPT-1.36B包含13.6亿参数,其他模型均为base-size大小。
微调 384 × 384 384 \times 384 384×384分辨率。在 224 × 224 224 \times 224 224×224图片微调之后,添加了在10个epochs的 384 × 384 384 \times 384 384×384图像的微调。这里的微调遵循DeiT的设置,除使用更少的epochs之外。对于输入分辨率更高的patch,Transformer的输入序列长度会更长。表2则展示了采用更高分辨率的图片可以使BEiT在ImageNet上提高1+个百分点。更值得注意的是,采用同样的输入分辨率,在ImageNet-1K上预训练的 B E i T 384 BEiT_{384} BEiT384性能超过了在ImageNet-22K上预训练的 V i T 384 ViT_{384} ViT384。
Scaling up to larger size.(扩展到更大尺寸)。将BEiT扩展到更大的尺寸(如ViT-L这般)。表2中展示,在ImageNet数据集上,若从头开始训练, V i T 384 − L ViT_{384}-L ViT384−L表现差于 V i T 384 ViT_{384} ViT384,这说明了ViT的data-hungry问题。而在ImageNet-22K上进行监督预训练则环节了该问题, V i T 384 − L ViT_{384}-L ViT384−L性能好于$ViT_{384} 1.2 倍 。 相 比 之 下 , ‘ B E i T − L ‘ 比 ‘ B E i T ‘ 性 能 好 两 倍 , 1.2倍。相比之下,`BEiT-L`比`BEiT`性能好两倍, 1.2倍。相比之下,‘BEiT−L‘比‘BEiT‘性能好两倍,BEiT_{384}-L 比 比 比BEiT_{384}$好1.7倍。换句话说,将BEiT扩展到BEiT-L的好处要优于监督预训练模型(ImageNet-22K上)。更重要的是,比较 B E i T 384 BEiT_{384} BEiT384和在ImageNet上监督预训练的 V i T 384 ViT_{384} ViT384,随着模型规模从base扩展到large,BEiT性能提升更大,这也说明BEiT更适合于复杂、达的模型(1B,10B),尤其是标注数据不充分时对于大模型机型监督预训练时。

图二:ImageNet-1K上从头训练DeiT和微调BEiT
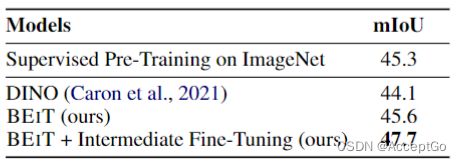
表3:ADE20K上的语义分割结果。直接使用同样的SETR-PUP任务层,且只使用single-scale推断
收敛曲线。图二是从头开始训练DeiT和先预训练再微调BEiT的收敛曲线。可以发现,BEiT不仅性能更好,而且比DeiT收敛更快。微调可以再很少的epochs就可以得到不错的准确率。
3.2 语义分割
语义分割的目的是为输入图像的每个像素预测一个对应的类别。这里是在ADE20K基准(包含25K图片和150个语义类别)上对BEiT进行评估,对所有语义类别的mean Intersection of Union(mIoU)(均交并比)进行度量。按照2.6节阐述,直接遵循task layer和SETR-PUP中描述的超参数。在ADE20K上,使用Adam优化器,学习率设置为1e-3,并带有layer-wise decay(同图像分类设置一样),batch_size设置为16,使用160K的图像进行微调。
如表3所示,将BEiT同依赖于ImageNet标注数据的监督预训练模型进行比较。结果表明,BEiT比监督预训练表现更好,即使是BEiT不需要大批量标注数据情况下。而且,还可以在中间过程使用标注ImageNet数据集对BEiT进行微调(首先可以在ImageNet上对BEiT进行微调,然后在语义分割数据集ADE20K上进行微调)。实验结果表明,中间过程的微调可以进一步提高BEiT在语义分割任务上的性能。
3.3 消融研究
通过消融研究来分析在BEiT中每个组件的作用。BEiT在图像分类(ImageNet)和语义分割(ADE20K)上进行评估。对于消融实验,设置预训练步骤为300epochs(之前实验总的迭代数的37.5%)。

表4:BEiT预训练在图像分类和语义分割任务上的消融实验
表4是各种模型变体的结果。首先,通过随机采样掩盖位置来消融blockwise masking。可以发现,blockwise masking对两种任务都是有益的,尤其是对语义分割。其次,通过预测masked patches的原始像素消融visual tokens的使用,此时,预训练任务变为像素回归问题目标是恢复masked patches。同表1的结果相比,在两个下游任务上,消融实验的结果要比从头开始训练ViT的结果差,这个结果表明,visual tokens的预测是BEiT的关键组成部分。第三,同时去除visual tokens和blockwise masking,进行实验,可以发现,blockwise masking对像素级自编码器更有帮助,它可以减轻short-distance依赖。第四,比较不同迭代次数的BEiT,更多的epochs,BEiT在下游任务性能更好。
3.4 Self-Attention Map分析

图3:不同参考点的Self-attention map。BEiT中的自注意力机制可以分离对象(即使在自监督预训练时没有标签数据情况)
BEiT中self-attention机制可以分离对象,即使是不依赖任何手工标注。这些探测图像来自于MS COCO语料库。
如图3所示,绘制了一幅图中不同参考点的self-attention映射。该可视化结果是由最后一层Q-K乘积计算出的注意力分数产生的。对于每一个参考点,使用对应的patch作为query,并显示所关注的patch。预训练后,BEiT使用self-attention heads区分语义区域,而无需特定任务的监督。这个property说明了BEiT为什么对下游任务是有用的。比如通过BEiT获得的知识可以提高微调过的模型的泛化能力,特别是在小规模数据集上。
4. 相关工作
4.1 自监督视觉表示学习
近几年,引入了各种方法以自监督方式对视觉模型进行预训练。开创性的工作设计了许多任务,比如预测patch顺序、着色以及预测totation angles(旋转角度)。最近的研究遵循了一种对比范式,诸如:Oord et al.2018;Wu et al;Hjelm et al., 2019等。模型通常将各种数据增强视作图像的不同视图,然后使positive pair(正对)的表示尽可能相似,negative pairs(负对)表示尽可能远离。为在对比学习中获得足够的负样本,这种方法通常依赖于较大memory bank(内存库)或batch size。BYOL和SimSiam进一步消除了负样本的要求,使用各种技术来避免表示坍塌。还有一种方法就是使用聚类方法来组织图像样例。
4.2 自监督ViT
由于data-hungry问题,预训练ViT最近受到极大关注。iGPT首先通过k-means聚类RGB像素创建一个9-bit调色板,然后使用聚类tokens(标记)来表示图像,再接下来,iGPT使用BERT和GPT任务预训练Transformer。相比之下,本文提出的方法使用image patches作为输入而不丢失像素级信息。此外,visual tokens通过离散变分自编码器而非聚类获得。ViT利用masked patch预测任务进行了初步探索()。预测masked patches的3位均值颜色。Dosovitskiy et al. (2020)中实验说明,若BERT直接从NLP到CV中,像素级自编码器表现很差。不同于使用启发式设计的预训练任务,文中提出的模型利用离散变分自编码器学习到的visual tokens,不仅实现了更好性能,且理论上更具解释性。除了masked auto-encoding(掩码自编码)外,其他主流工作也有使用对比学习(Chen et al.,2021;Xie et al.,2021)和自蒸馏(Caron et al.,2021)。相比之下,BEiT在预训练吞吐量和内存消耗上可以提升数倍。这些优势使BEiT对扩展ViT更有吸引力。
4.3 BERT-style pre-training in NLP
预训练语言模型重塑了NLP格局。BERT中提出的masked language modeling(MLM)任务是最成功的预训练任务之一。随后,不同的MLM变体相继提出改进Transformer预训练的性能。MLM也被成功应用于multilingual language(跨语言)表示的预训练中(Conneau and Lample,2019;Conneau et al.,2020)。此外,可以调整MLM任务来训练large-scale sequence-to-sequence Transformer(大规模序列到序列Transformer)(Raffel et al.,2020)。此外,blockwise masking策略在NLP中也被证明是有效的。
5. 结论
文中描述了一个Vision Transformer自监督预训练框架,并在如图像分类和语义分割下游任务实现了很好的微调结果。在文中也表明所提出的方法对于image Transformer做BERT-like预训练是至关重要的。再者,还展示了自动获取的关于语义区域的知识的属性,而不需使用任何人工标注数据。
未来,仍可以从以下两方面推进这项工作:
- 在数据大小和模型大小方面扩大
BEiT预训练,以达到BERT在NLP中的地位。 - 以更加统一方式,使用文本和图像的相似目标和共享架构,进行多模态预训练。