【论文笔记】Oscar Object-Semantics Aligned Pre-training for Vision-Language Tasks
Our method is motivated by the observation that the salient objects in an image can be accurately detected, and are often mentioned in the paired text.
motivation : 图片中比较重要(salient 突出)的地方是能够通过一些目标检测方法精确检测到的。而且这一部分又往往会出现在配对的文本数据里。
For example, on the MS COCO dataset, the percentages that an image and its paired text share at least 1, 2, 3 objects are 49.7%, 22.2%, 12.9%, respectively.
以coco数据集为例,图片和配套文本中含有共指目标的概率很高。
.
While existing methods simply concatenate image region features and text features as input to the model to be pre-trained and use self-attention to learn image-text semantic alignments in a brute force manner, in this paper, we propose a new learning method Oscar, which uses object tags detected in images as anchor points to significantly ease the learning of alignments.
作者在摘要中与现存的预训练模型进行了对比:
- 现存的方法:将文本特征和图片特征简单的级联在一起然后输入做SA来获取对齐信息(作者认为这是一种野蛮粗暴的方式)
- 提出的方法:将检测到的目标标签作为锚点,显著降低了对齐难度。
简介
However, the lack of explicit alignment information between the image regions and text poses alignment modeling a weakly-supervised learning task. In addition, visual regions are often over-sampled [2], noisy and ambiguous, which makes the task even more challenging,
- 训练过程中缺乏准确的跨模态对齐信息,导致在对齐方面的学习只能算是弱监督学习。
- 图片往往被过度采样(太多图片框),导致噪音和歧义。
.
We propose a new VLP method Oscar, where we define the training samples as triples, each consisting of a word sequence, a set of object tags, and a set of image region features.
数据是三元组形式:
- 文本序列
- 目标的标签(对应检测到的目标),图片标签既有文本性质又有视觉性质,属于中间模态
- 图片特征(对应检测到的目标)

.
背景知识
The goal of pre-training is to learn cross-modal representations of image-text pairs in a self-supervised manner, which can be adapted to serve various down-stream tasks via fine-tuning.
关于预训练的目标解释的很清晰:关键是以自监督的方式学习表征,同时保证能应用到各种不同的下游任务。
.
Though intuitive and effective, existing VLP methods suffer from two issues:
(i) Ambiguity. The visual region features are usually extracted from over-sampled regions [2] via Faster R-CNN object detectors [28], which inevitably results in overlaps among image regions at different positions. This renders ambiguities for the extracted visual embeddings. For example, in Fig. 2(a) the region features for dog and couch are not easily distinguishable, as their regions heavily overlap.
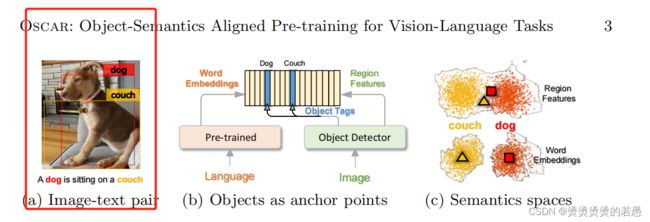
现存的方法的一些问题:
- 图片中的物体都是通过Faster-RCNN检测出来的,会有过度采样
- (这个Faster-RCNN是用来进行目标检测的,在其他文章里也频繁出现,应该是CV领域的常用工具)
- 这种采样方式会带来歧义问题,比如图片中的两个关键目标:狗 和 沙发之间有大量的重合部分。
(ii) Lack of grounding. VLP is naturally a weakly-supervised learning problem because there is no explicitly labeled alignments between regions or objects in an image and words or phrases in text. However, we can see that salient objects such as dog and couch are presented in both image and its paired text as in Fig. 2(a), and can be used as anchor points for learning semantic alignments between image regions and textual units as in Fig. 2(b). In this paper we propose a new VLP method that utilizes these anchor points to address the aforementioned issues.
- 作者一直在强调Transformer预训练过程中在对齐方面的弱监督性。
- 而本文利用锚点的概念,解决了上述问题。
。
Oscar预训练方法

输入
the alignments between q and w, both in text, are relatively easy to identified by using pretrained BERT models [6], which are used as initialization for VLP in Oscar.
- Oscar是使用BERT进行的初始化。
。
Faster R-CNN [28] is used to extract the visual semantics of each region as (v’ , z), where region feature v’ ∈ RP is a P-dimensional vector (i.e., P = 2048), and region position z a R-dimensional vector (i.e., R = 4 or 6)We concatenate v‘ and z to form a position-sensitive region feature vector, which is further transformed into v using a linear projection to ensure that it has the same vector dimension as that of word embeddings.
这里讲的是图片Embedding的获取方式:
- 利用Faster R-CNN得到semantic特征v’,和位置编码z
- 将v’与z进行级联,得到包含位置信息的图片特征
- 对该特征进行线性映射,得到v
- 保证v的维度与文本embedding相同
。
预训练目标
The Oscar input can be viewed from two different perspectives as
where x is the modality view to distinguish the representations between a text and an image; while x’ is the dictionary view to distinguish the two different semantic spaces, in which the input is represented.
三种输入,从两个不同的角度看有不同的分类法:
从模态角度看:标签代表的是图片
从词典角度看:标签的embedding是属于文本embedding空间的
可以看出标签数据的特殊性,他是中间模态的信息
而这两种不同的切分角度也产生了两种不同预训练目标
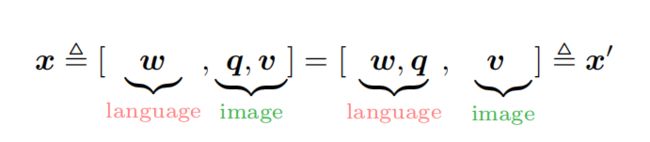

词典角度:遮盖词预测
We define the discrete token sequence as h=[w, q], and apply the Masked Token Loss (MTL) for pre-training. At each iteration, we randomly mask each input token in h with probability 15%, and replace the masked one hi with a special token [MASK]. The goal of training is to predict these masked tokens based on their surrounding tokens h\i and all image features v.
从方法上来看:和Bert的MLM基本一致
模态角度:标签匹配预测 Contrastive Loss
For each input triple, we group h’=[q, v] to represent the image modality, and consider w as the language modality. We then sample a set of “polluted” image representations by replacing q with probability 50% with a different tag sequence randomly sampled from the dataset D.Since the encoder output on the special token [CLS] is the fused vision-language representation of (h‘ , w), we apply a fully-connected (FC) layer on the top of it as a binary classifier f(.) to predict whether the pair contains the original image representation (y = 1) or any polluted ones (y = 0).
这个标签匹配的预训练任务在其他论文里也见过类似的:
- 把标签序列q随机替换
- 利用bert的CLS标签进行二分类,预测是否进行过替换
- 有一个问题是,随机替换的难度是不是会太低了(模型很容易就能区分出来呀)
预训练数据集
- COCO
- CC
- SBU captions
- flicker30k
- GQA
预训练实现细节
匹配下游任务
图文检索
图片描述
新图片描述
VQA 图片问答
GQA(类似VQA,但是关注原因)
Natural Language Visual Reasoning for Real (NLVR2)
实验结果
与现存SOTA模型的对比

质量研究
