李沐基于Pytorch的深度学习笔记(1)
首先,本文是李沐老师的视频的笔记,里面的编程部分是我用Pycharm编写的,希望对大家有所参考。
1 数据结构与数据操作:
1.1 机器学习和深度学习的数据结构,基本都是N维数组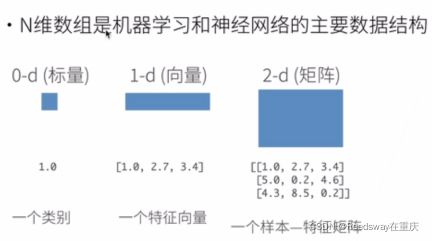
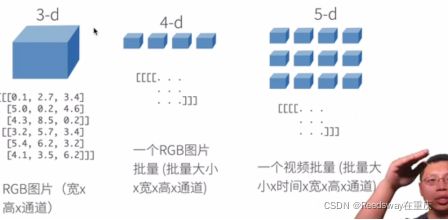
1.2 创建一个数组
创建数组需要具备的条件:
①形状:3*4/4*5…………,就像矩阵的行列比一样
②数据类型:int、float、long、以及int32、float64这种细分领域的类型,非常多
③元素的值:例如X1=10,X2=1.2,这种值

如上图所示,第一个是正态分布,第二个书均匀分布,这里所用的是RGB灰度图的形式表示的。
1.3 访问元素

这里的话,我们必须清楚,在计算机语言中,排序是0开始的,所以[1, 2]表示的是第二行,第三列。
Eg:修正:一列:[:1, :]
注意:子区域[1:3, 1:],这里的1:3表示的是[1, 3),并不是我们认为的包含了第四行。
子区域[::3, ::2],这里值得是每3行一跳,每两列一跳。
1.4 开始操作数据(torch中的数据操作)
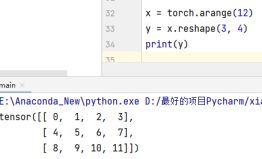
1.4.1 arange、shape、numel

这里我们引入了张量。张量是啥意思呢,指的是由数值组成的数组。这个数组可能是多维度的。

通过.shape和.numel来查看张量的形状(这里由于我们本身引入的是一个一维的数组,所以只有一维的形状),以及张量的元素数量(永远为个数的标量)。
1.4.2 reshape、zeros、ones
我们可以通过.reshape来改变张量的形状,当然我们也可以通过.zeros来创建全零的矩阵,或者.ones创建全1的矩阵:

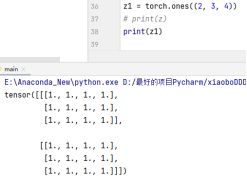
这里其实比较好理解,即:两个矩阵,分别为3行4列。
1.4.3 tensor、cat、逻辑判断、.sum
通过.tensor来直接提供包含确定数值的python列表,来基于张量每一个元素确切的值。
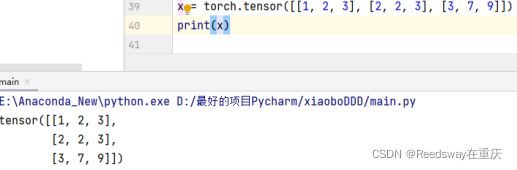
其中多少个[ ]表示为几维数组,比如 [ [ [ ] ] ] 指的就是三维数组。我们可以利用普通的加减乘除商幂(python的好处在于不计较数值的类型进行计算【别太离谱就行】)
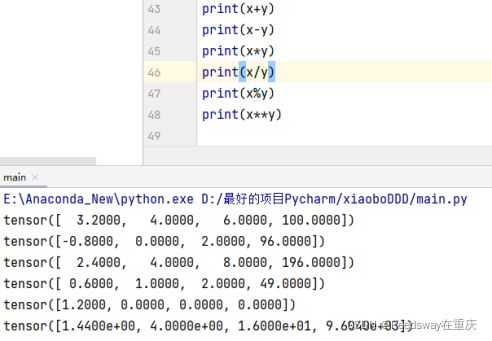
下一步我们尝试使用.cat对两个数组进行合并。首先创建一个12位的序列,类型是float32,并且重塑为3*4的矩阵张量。之后呢,使用.cat进行合并,dim=0 ,表示在第0维合并。dim=1表示在第1维合并。那么在这个矩阵中,第1维就是行,第2维就是列。(由于这里创建的就只是一个二维数组,所以不存在第3维了)

当然我们可以使用逻辑符号,判断元素的逻辑,从而构成二维的逻辑张量。

也可以使用.sum来求得元素的和,可以得到一个元素的张量

1.4.4 广播机制
如果说存在,形状不一样的张量相加,我们就会存在NUMPY中存在的广播机制。啥意思呢,就是有点复制粘贴的意思。就是本身a是3*1,会被复制成3*2的矩阵;同时本身b是1*2的矩阵会被复制成3*2的矩阵。这种情况下再做相加。这就是广播机制
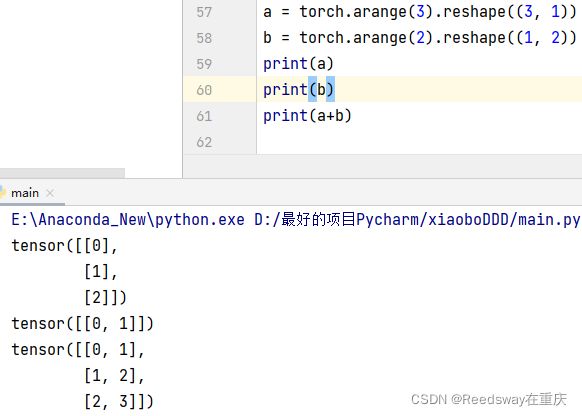
1.4.5 元素访问、zeros_like()
比如[-1]表示的是啥;[1: 3]表示啥;我们可以做一个小小的说明。因为其实第一行是第0行,所以-1是最后一行。而[1: 3]也就是[1, 4)就是第二行到第三行嘛。

由于python并没有考虑内存的问题,所以在实际操作中,还是需要避免因为矩阵过大,操作频繁导致内存出现问题。

这里可以看出,在原本的Y占用内存后,我们像通过重新赋值给Y新的数值时,会出现无法赋值的情况。这时候我们就需要重新提供一个元素来进行操作。.zeros_like这个函数是让Z同原本的Y数值、shape等一模一样。
Z[ :]这里指的是让Z所有元素等于X+Y,这样就可以创建新的内存了。当然如果说后续的X没有被频繁使用,也可以使用X[:]=X+Y来达到目的。
这一节主要是为了提醒!
1.4.6 转换张量

numpy本身是最为常见的python的一个框架,因此经常需要转换。要么就是转化为标量。其实标量的转换还是非常简单的,比如之前学的.sum之类的。
1.5 数据预处理(将CSV数据变成张量)
首先,建立一个人工数据集,储存在CSV文件中,CSV文件即每一行是一个数据。

利用Pandas来读取csv文件。其中NA指的是未知的数据。

那么为了处理位置数据,一般来说的方法是删除或者插值来进行的。我们这里考虑插值法。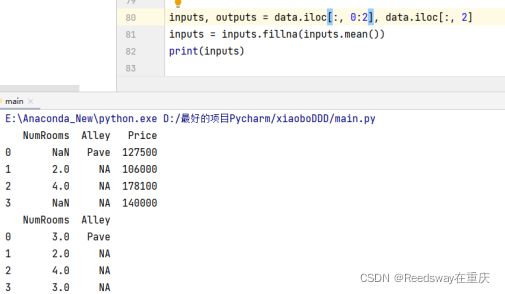
这里使用了.iloc,是为了吧数据集中的确实列单独提出来,作为一个输入输出。其中,后面使用了.fillna,这是为了填充数据。填充的就是inputs.means(),指的是不是NaN的均值。Alley没有变换,是因为没有均值。
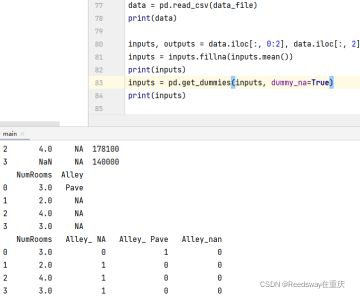
那么对于不是均值的数值来说,我们把这一列中所有出现不是值的标识,全部变成特征来看待。Pave变成0,NA变成1,同样的,后面都变成了特征值。

利用torch,将inputs和outputs变成张量。