Pytorch一行代码便可以搭建整个transformer模型
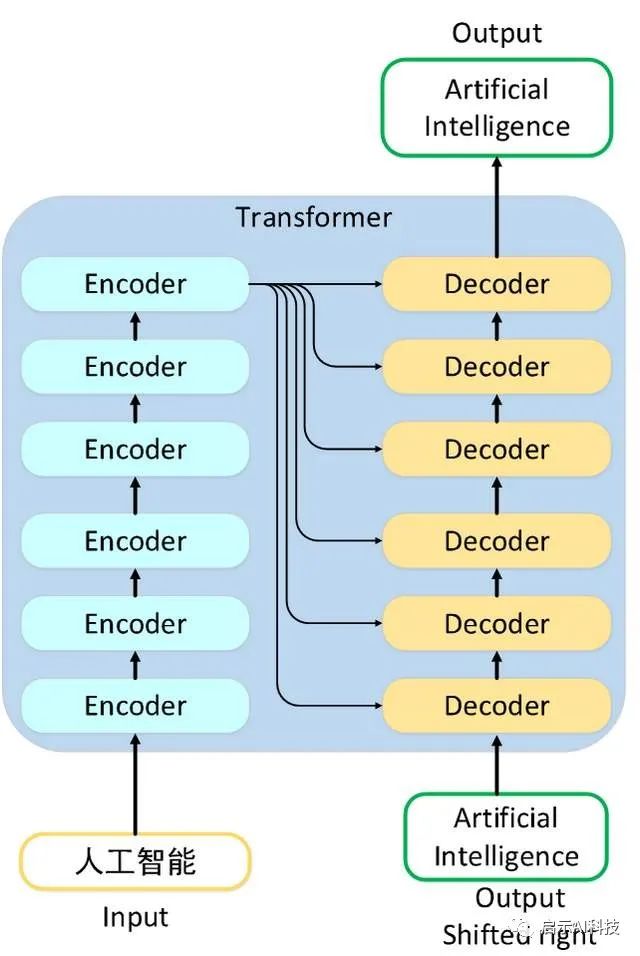
transformer模型是在NLP领域发表的论文attention is all you need中提出的一种语言处理模型,其transformer模型由于加速了模型推理时间与训练精度,越来越受到了广大机器学习爱好者的追求。特别是transformer模型应用到CV计算机视觉领域后,transformer模型更是得到了广大的应用。
更多Transformer模型VIT 模型SWIN Transformer模型参考头条号:人工智能研究所
最近大火的AI绘图stable diffusion也是应用到了transformer模型。虽然transformer模型是Google发布的论文,且最初的实现代码是基于TensorFlow实现的,但是pytorch的流行,让很多机器学习爱好者使用pytorch来实现transformer模型。
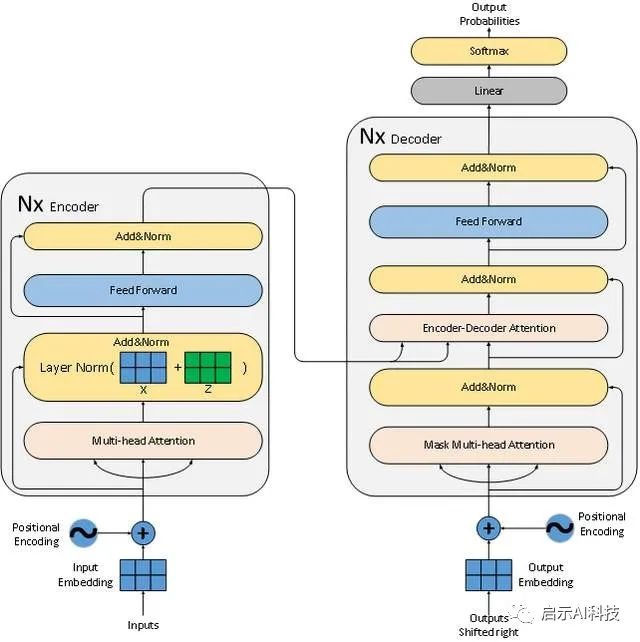
从transformer模型的架构图可以看出,其模型存在6层的编码器与6层的解码器组成,每层的编码器包含multi-head attention多头注意力机制与feed-forward前馈神经网络,且经过每次block功能外,还添加一层的add&norm的残差连接与归一化操作。
——1——
Pytorch代码实现transformer模型-encoder层搭建
在我们介绍transformer模型的时候,为了讲解得更加清晰,每个block的代码实现过程都是一行一行代码讲解来实现的,但是从pytorch 1.12版本开始,pytorch就开始集成了transformer模型的代码API,主要模块代码如下:
nn.Embedding :Embedding 操作函数
nn.Linear :线性变换
nn.Dropout :置零比率
nn.TransformerEncoderLayer:TransformerEncoderLayer is made up of self-attn and feedforward network.
nn.TransformerDecoderLayer:TransformerDecoderLayer is made up of self-attn, multi-head-attn and feedforward network.
nn.Transformer: A transformer model.
nn.TransformerEncoder:TransformerEncoder is a stack of N encoder layers.
nn.TransformerDecoder:TransformerDecoder is a stack of N decoder layersnn.TransformerEncoderLayer函数,从命名的函数名称来看,其函数主要是负责transformer模型的encoder编码器层的实现,其函数包含multi-head attention多头注意力机制,feed-forward前馈神经网络以及add&norm的操作,其函数代码如下
CLASS torch.nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward=2048,
dropout=0.1, activation=, layer_norm_eps=1e-05,
batch_first=False, norm_first=False, device=None, dtype=None)
d_model (int) – embedding 后的矩阵维度,transformer模型默认为512
nhead (int) –多头注意力机制的头数,transformer模型为8
dim_feedforward (int) –feedforward前馈神经网络矩阵维度,transformer模型为2048
dropout (float) – 置零比率,默认0.1.
activation (Union[str, Callable[[Tensor], Tensor]]) – 激励函数(“relu” or “gelu”) 默认 relu
layer_norm_eps (float) –layer normalization teps 值 (默认1e-5).
batch_first (bool) – If True, then the input and output tensors are provided as (batch, seq, feature). Default: False (seq, batch, feature).
norm_first (bool) – if True, layer norm is done prior to attention and feedforward operations, respectively. Otherwise it’s done after. Default: False (after).
此参数主要考虑是VIT模型,后期我们会分享有关VIT模型的知识
forward(src, src_mask=None, src_key_padding_mask=None)实现函数
src (Tensor) –输入encoder层的矩阵序列,此矩阵已经经过embedding与位置编码
src_mask (Optional[Tensor]) – mask矩阵,在encoder层主要是pad mask
src_key_padding_mask (Optional[Tensor]) – the mask for the src keys per batch (optional). 其nn.TransformerEncoderLayer已经封装了transformer encoder层所有需要的函数,因此,我们只需要传递给此函数相应的参数即可,当然我们的transformer模型是用了6层的结构,因此我们还需要另外一个函数把这6层的encoder函数串起来,当然这个函数pytorch也已经实现了。
CLASS torch.nn.TransformerEncoder(encoder_layer, num_layers, norm=None,
enable_nested_tensor=True, mask_check=True)
encoder_layer – 就是我们上面的nn.TransformerEncoderLayer
num_layers – encoder层的数量,Transformer默认为6层结构
norm – the layer normalization
forward(src, mask=None, src_key_padding_mask=None)实现函数
src (Tensor) –输入encoder层的矩阵序列,此矩阵已经经过embedding与位置编码
src_mask (Optional[Tensor]) – mask矩阵,在encoder层主要是pad mask
src_key_padding_mask (Optional[Tensor]) – the mask for the src keys per batch (optional).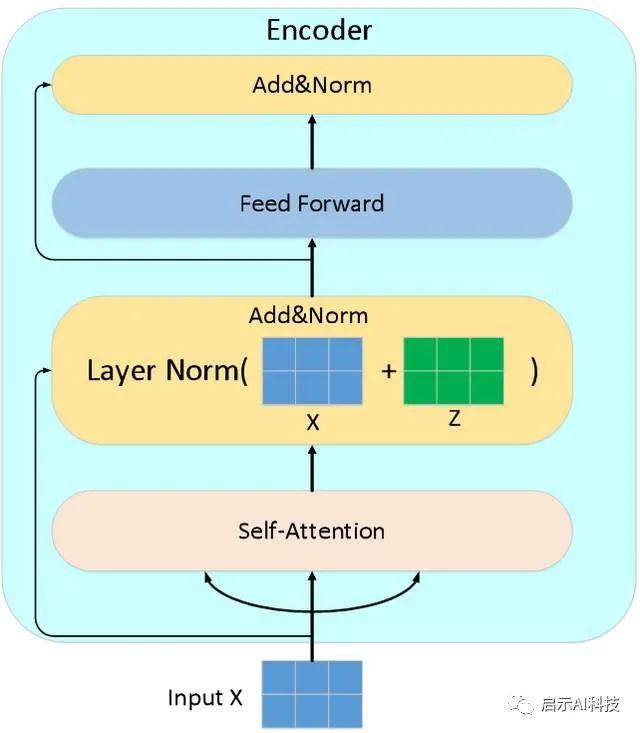
encoder layer
以上便是整个transformer模型encoder层的搭建,其主要是利用了pytorch提供的2个函数torch.nn.TransformerEncoder与torch.nn.TransformerEncoderLayer,为了便于以上函数的理解,我们举个例子
import torch
import torch.nn as nn
input = torch.LongTensor([[5,2,1,0,0],[1,3,1,4,0]])
import numpy as np
src_vocab_size = 10
d_model = 512
class Embeddings(nn.Module):
def __init__(self, vocab_size, d_model):
super(Embeddings, self).__init__()
self.emb = nn.Embedding(vocab_size,d_model)
def forward(self,x):
return self.emb(x)
word_emb = Embeddings(src_vocab_size,d_model)
word_embr = word_emb(input)
print('word_embr',word_embr.shape)
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)
encoder_out = transformer_encoder(word_embr)
print('encoder_out',encoder_out.shape)首先,我们初始化一个输入矩阵序列,其矩阵维度为[2,5],然后我们把输入序列经过word-embedding后,我们的输入矩阵维度为[2,5,512],然后使用上面介绍的2个pytorch函数来搭建transformer模型的编码器层的操作,最后,我们把矩阵输入其transformer模型编码器层进行注意力的计算操作,其最终输出矩阵维度依然是[2,5,512]。
——2——
Pytorch代码实现transformer模型-decoder层搭建
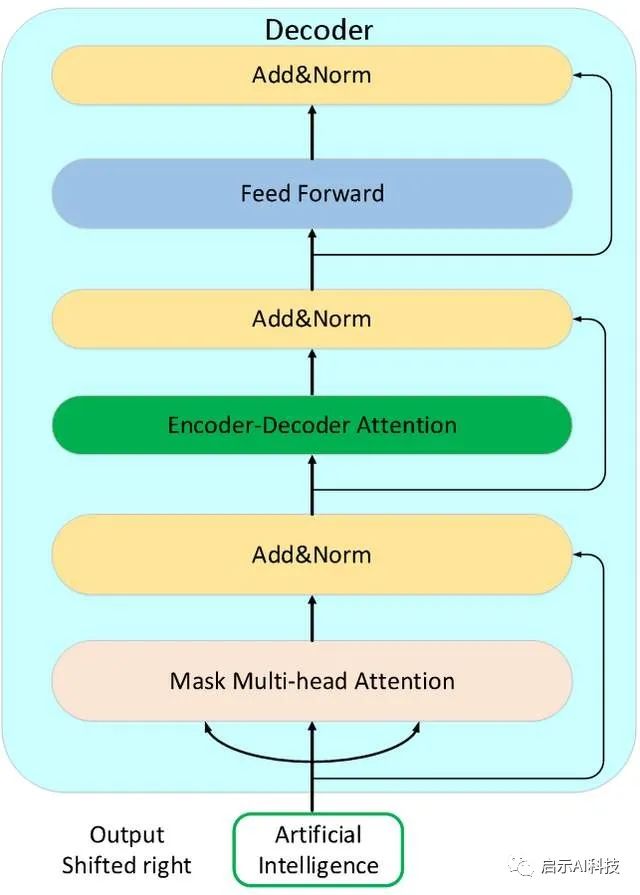
decoder layer
Pytorch不仅提供了2个编码器层的函数,同样也提供了2个解码器层的函数,函数如下:
CLASS torch.nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward=2048,
dropout=0.1, activation=,
layer_norm_eps=1e-05, batch_first=False, norm_first=False,
device=None, dtype=None)
d_model (int) – embedding 后的矩阵维度,transformer模型默认为512
nhead (int) –多头注意力机制的头数,transformer模型为8
dim_feedforward (int) –feedforward前馈神经网络矩阵维度,transformer模型为2048
dropout (float) – 置零比率,默认0.1.
activation (Union[str, Callable[[Tensor], Tensor]]) – 激励函数(“relu” or “gelu”) 默认 relu
layer_norm_eps (float) –layer normalization teps 值 (默认1e-5).
forward(src, src_mask=None, src_key_padding_mask=None)实现函数
src (Tensor) –输入decoder层的矩阵序列,此矩阵已经经过embedding与位置编码
src_mask (Optional[Tensor]) – mask矩阵,在decoder层主要是pad mask 与sequence mask 同样的道理,pytorch也提供了decoder 层的函数
torch.nn.TransformerDecoder,虽然与encoder比起来,decoder部分多了一层encoder-decoder attention交互层,但是整个模型搭建函数不变
CLASS torch.nn.TransformerDecoder(decoder_layer, num_layers, norm=None)
decoder_layer – 就是上面搭建的torch.nn.TransformerEncoderLayer
num_layers – decoder层的数量,transformer模型默认6层
norm – the layer normalization component (optional).
forward(tgt, memory, tgt_mask=None, memory_mask=None,
tgt_key_padding_mask=None, memory_key_padding_mask=None)
tgt (Tensor) – decoder 输入矩阵
memory (Tensor) – encoder 编码器层最终的输出矩阵
tgt_mask (Optional[Tensor]) – decoder输入矩阵的mask矩阵,
主要包含pad mask 与sequence mask
memory_mask (Optional[Tensor]) – the mask for the memory sequence (optional).
Encoder层的mask矩阵,主要用来交互层的使用跟encoder类似,以上2个decoder函数便完整搭建了transformer模型的解码器层的函数,我们可以初始化了2个函数来代码实现一下decoder的搭建
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=6)
decoder_out = transformer_decoder(word_embr,encoder_out)
print('decoder_out',decoder_out.shape)我们初始化decoder_layer与transformer_decoder函数,并输入2个矩阵,一个是decoder的输入,另外一个是encoder层的最终输出,最后打印出来经过decoder层的最终输出,其矩阵维度依然是[2,5,512]
——3——
Pytorch一行代码实现transformer模型
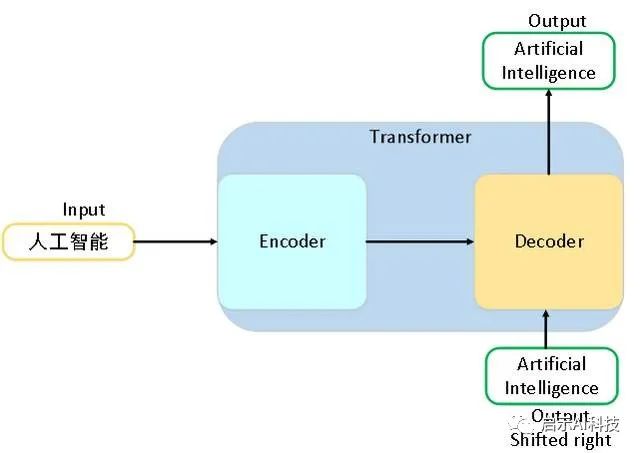
transformer
当然,我们的transformer模型需要同时包含encoder层与decoder层,除了以上提供的4个函数外,pytorch直接提供了一个函数torch.nn.Transformer来搭建整个transformer模型,其函数包含了encoder与decoder层的所有函数。
torch.nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation=, custom_encoder=None, custom_decoder=None,
layer_norm_eps=1e-05, batch_first=False, norm_first=False, device=None,
dtype=None)
d_model (int) –encoder与decoder 输入的embedding参数 (默认512).
nhead (int) –multi-head-attention 多头注意力的头数(默认=8).
num_encoder_layers (int) –encoder层的数量 (默认6).
num_decoder_layers (int) –decoder 层的数量(默认6).
dim_feedforward (int) –feedforward 前馈神经网络的矩阵维度 (默认2048).
dropout (float) – dropout置零比率,默认0.1
activation (Union[str, Callable[[Tensor], Tensor]]) – 激励函数(“relu” or “gelu”) 默认: relu
layer_norm_eps (float) –normalization eps参数 (默认1e-5). 通过以上的nn.Transformer一行代码,我们便可以搭建整个transformer模型,我们可以初始化一个nn.Transformer函数,然后输入我们的输入矩阵,最后打印出来函数的输出矩阵,其维度依然保持不变[2,5,512]
transformer_model = nn.Transformer()
transformer_out = transformer_model(word_embr,word_embr)
print('transformer_out',transformer_out.shape)当然此函数并没有包含模型的数据初始化部分与模型的最终输出部分,包含word-embedding与位置编码以及输出部分的softmax与linear线性层
更多Transformer模型
VIT 模型
SWIN Transformer模型
参考头条号:人工智能研究所当然,若我们直接来使用nn.Transformer函数来写我们的代码,我们对整个transformer的搭建与代码实现并不会理解很透彻,建议我们从原始代码函数,一个一个函数来写代码,这样,我们就可以对整个transformer模型了解的比较透彻,当我们对整个transformer模型了解完成后,当然可以直接来使用pytorch使用的此行代码来搭建我们的transformer模型,或者改写其他的模型代码,来优化整体代码量。
VX搜索小程序:AI人工智能工具,体验不一样的AI工具
