深入理解numpy库中的order参数
创建数组对象中的order
- 要理解order参数首先要需要明确ndarray对象的数据结构
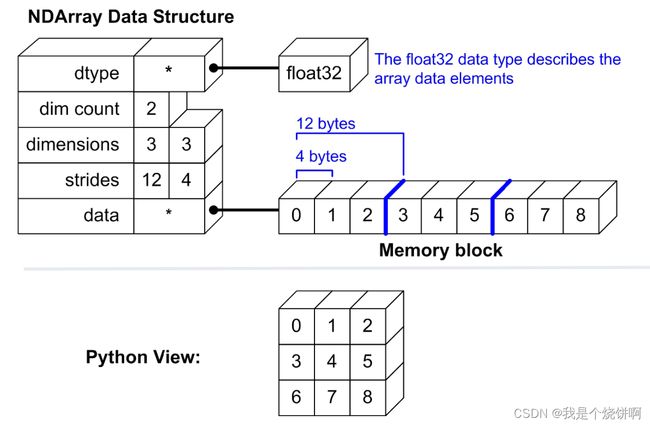
从ndarray.strides可以读出数据的存储方式:
- 第一个参数代表第一个维度(行)之间相差的字节数,a[0,0]与a[1,0]相差12个字节
- 第二个参数代表第二个维度(列)之间相差的字节数,a[0,0]与a[1,0]相差4个字节
(12,4)可以读出该数组是按行存储的,即一行中的元素在内存中是相互邻近的
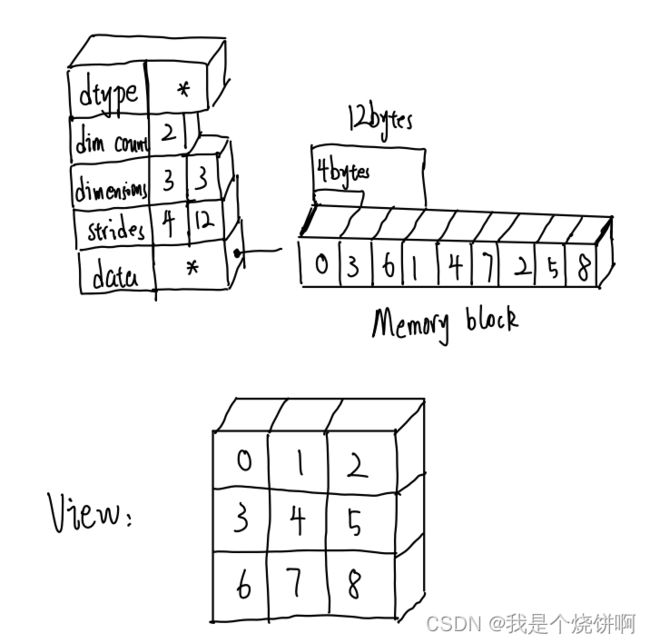
a = np.array([[0,1,2],[3,4,5],[6,7,8]],order='F')
print(a)
a.strides
[[0 1 2]
[3 4 5]
[6 7 8]]
(4, 12)
order='F'即按列读取数据并存储到内存中
(4,12)可以读出该数组是按列存储的,一列中的元素在内存中是相互邻近的
在引申到三维数组
x = np.array(
[[[ 1 , 0],
[ 3 , 2],
[ 5 , 4]],
[[ 7 , 6],
[ 9 , 8],
[11, 10]],
[[12 ,13],
[14 ,15],
[16 ,17]]],order='C')
print(x)
x.strides
[[[ 1 0]
[ 3 2]
[ 5 4]]
[[ 7 6]
[ 9 8]
[11 10]]
[[12 13]
[14 15]
[16 17]]]
(24, 8, 4)
内存中的存储顺序为(1,0,3,2,5,4,…)
order='C'即按行读取数据并存储到内存中
(24,8,4)第一个维度(块)元素之间相差24字节、第二个维度(行)元素之间相差8个字节,第三个维度(列)元素之间相差4个字节,一个块中的元素在内存中是相互邻近的
x = np.array(
[[[ 1 , 0],
[ 3 , 2],
[ 5 , 4]],
[[ 7 , 6],
[ 9 , 8],
[11, 10]],
[[12 ,13],
[14 ,15],
[16 ,17]]],order='F')
print(x)
x.strides
[[[ 1 0]
[ 3 2]
[ 5 4]]
[[ 7 6]
[ 9 8]
[11 10]]
[[12 13]
[14 15]
[16 17]]]
(4, 12, 36)
内存中的存储顺序为(1,7,12,3,9,14)
(4,12,36) 第一个维度(块)元素之间相差4个字节,第二个维度(行)元素之间相差12个字节,第三个维度(列)元素之间相差36个字节,先块后行再列存储
reshape中的order
reshape()的返回值:
This will be a new view object if possible; otherwise, it will be a copy. Note there is no guarantee of the memory layout (C- or Fortran- contiguous) of the returned array.
即该函数返回的不一定是数组的视图,实验后发现当order参数与原数组order参数一致时,返回原数组的视图,否则会重新开辟一块内存创建一个新的数组,返回该数组的视图
参数不一致
import numpy as np
x = np.array(
[[[ 1 , 0],
[ 3 , 2],
[ 5 , 4]],
[[ 7 , 6],
[ 9 , 8],
[11, 10]],
[[12 ,13],
[14 ,15],
[16 ,17]]])
x1 = np.array(x,order='C') # 内存中顺序(1,0,3,2,5,4,...)
x2 = x1.reshape(3,2,3,order ='F') # 内存中顺序(1,7,12,3,9,14,...)
print(x2)
print(x2.strides)
x2.base is x1
[[[ 1 5 2]
[ 3 0 4]]
[[ 7 11 8]
[ 9 6 10]]
[[12 16 15]
[14 13 17]]]
(4, 12, 24) # 内存顺序(1,7,12,...)显示时1和7相差4个字节,
False # 说明返回的不是原数组的视图
参数一致
x1 = np.array(x,order='C') # 内存中顺序(1,0,3,2,5,4,...)
x2 = x1.reshape(3,2,3,order ='C') # 内存中顺序(1,0,3,2,5,4...)
print(x2)
print(x2.strides)
x2.base is x1
[[[ 1 0 3]
[ 2 5 4]]
[[ 7 6 9]
[ 8 11 10]]
[[12 13 14]
[15 16 17]]]
(24, 12, 4) #
True # 说明返回为原数组的视图
reshape()工作流程:
- 根据传入的
order参数读取数组,如果参数与原数组参数相同则引用原数组的数据,否则新开辟内存 - 根据
order参数设置返回数组的strides,C就是按行主序显示,F就是按列主序显示 - 根据
strides返回view(这里的view指数据显示为什么样的数组)
下面用一个例子帮助理解:
arr = np.array([[1,2],
[4,5],
[7,8]],order='F')
arr1 = arr.reshape((2,3),order='F') # 参数一致,引用原数组数据,内存中顺序为(1,4,7,2,5,8)
arr2 = arr.reshape((2,3),order='C') # 参数不一致,按行读取数据,内存中顺序为(1,2,4,5,7,8)
print("是否引用原数组数据:")
print('arr1:',arr1.base is arr)
print('arr2:',arr2.base is arr)
print("数据的strides:") #决定如何显示数据,即数组的外观
print('arr1.strides:',arr1.strides)
print('arr2.strides:',arr2.strides)
print("arr1为:",'\n',arr1)
print("arr2为:",'\n',arr2)
是否引用原数组数据:
arr1: True
arr2: False
数据的strides:
arr1.strides: (4, 8)
arr2.strides: (12, 4)
arr1为:
[[1 7 5]
[4 2 8]]
arr2为:
[[1 2 4]
[5 7 8]]
arr1.strides为(4,8),即显示的行元素之间相差4个字节,列元素之间相差8个字节,其中1和4相差4个字节1和7相差8个字节符合内存中的顺序(1,4,7,2,5,8)
arr2.strides为(12,4),即显示的行元素之间相差12个字节,列元素之间相差8个字节,其中1和5相差12个字节1和2相差4个字节符号内存中的顺序(1,2,4,5,7,8)
因此可以通过order参数获取以列主序的数据
arr = np.array([[1,2],
[4,5],
[7,8]],order='F')
arr1 = arr.reshape((6,),order='F') # 参数一致,引用原数组数据,内存中顺序为(1,4,7,2,5,8)
arr1
array([1, 4, 7, 2, 5, 8])
order=‘K’ 和 order=‘A’
除了比较常见的C(行主序)和F(列主序)外,order还可以为K和A
order='C':按行去读取x数组
order='F':按列去读取x数组
order='K':按内存中的顺序读取数据
order='A':按行或列读取数组(不推荐)
import numpy as np
x = np.array(
[[[ 1 , 0],
[ 3 , 2],
[ 5 , 4]],
[[ 7 , 6],
[ 9 , 8],
[11, 10]],
[[12 ,13],
[14 ,15],
[16 ,17]]])
re_x = x.reshape(3,2,3) # 引用x的数据,内存中顺序为(1,0,3,2,5,4,...)并按行主序显示
swap_x = re_x.swapaxes(1,2) # 返回re_x的视图,因此数据仍引用x的数据,该函数作用交换指定维度的strides
print("交换前strides:",re_x.strides)
print("交换后strides:",swap_x.strides)
x_C=np.ravel(swap_x, order='C')
x_F=np.ravel(swap_x, order='F')
x_K=np.ravel(swap_x, order='K') # 按内存布局的顺序读取数据
x_A=np.ravel(swap_x, order='A')
print('reshape:\n',re_x)
print('swapaxe:\n',swap_x)
print('order=C:',x_C)
print('order=F:',x_F)
print('order=K:',x_K)
print('order=A:',x_A)
交换前strides: (24, 12, 4)
交换后strides: (24, 4, 12)
reshape:
[[[ 1 0 3]
[ 2 5 4]]
[[ 7 6 9]
[ 8 11 10]]
[[12 13 14]
[15 16 17]]]
swapaxe:
[[[ 1 2]
[ 0 5]
[ 3 4]]
[[ 7 8]
[ 6 11]
[ 9 10]]
[[12 15]
[13 16]
[14 17]]]
order=C: [ 1 2 0 5 3 4 7 8 6 11 9 10 12 15 13 16 14 17]
order=F: [ 1 7 12 0 6 13 3 9 14 2 8 15 5 11 16 4 10 17]
order=K: [ 1 0 3 2 5 4 7 6 9 8 11 10 12 13 14 15 16 17]
order=A: [ 1 2 0 5 3 4 7 8 6 11 9 10 12 15 13 16 14 17]