这个AI算法,可以帮“元宇宙”虚拟人进行虚拟更换衣服
上期视频,我们制作了一个AI算法更换模特身上的衣服,本期教程,介绍一下如何来实现视频中的代码以及实现过程
AI算法,可以帮你进行虚拟换衣,元宇宙虚拟人再也不用愁衣服少了

——1——
什么是HR-VITON
其视频是基于一种称之为HR-VITON的技术,它实现了高分辨率的虚拟人物试穿衣服,通过提供试穿条件生成器,减少了由于传统翘曲和分割图之间的不一致而导致的失真。
传统上,虚拟试衣包括:翘曲,以使服装的图像适合人体,并生成分割图以生成最终图像。这时,翘曲模块和分割图独立移动,可能会造成不一致,尤其是当身体的一部分遮挡衣服时,会造成伪影(失真)。

HR-VITON
因此,HR-VITON对人的图像(I)和衣服的图像(c )进行预处理,然后使用Try-on Condition Generator生成翘曲和分割图,通过融合减少伪影和虚拟化实现了高分辨率拟合。

——2——
HR-VITON 代码实现
基于图像的虚拟试穿任务旨在将目标服装项目转移到人的相应区域,这通常通过将项目装配到所需的身体部位并将扭曲的项目与人融合来解决。虽然近几年已经进行了越来越多的研究,但合成图像的分辨率仍然很低(例如256x192)。

这种局限性源于几个挑战:随着分辨率的增加,在最终结果中,翘曲衣服和所需衣服区域之间的错位区域中的伪影变得明显;现有方法中使用的架构在生成高质量身体部位和保持衣服纹理锐度方面的性能较低。为了应对这些挑战,此模型提出了一种称为VITON-HD的新型虚拟试穿方法,该方法成功地合成了1024x768个虚拟试穿图像。

具体来说,首先准备分割图来指导模型的虚拟试穿合成,然后将目标服装项目大致适合给定的人的身体。接下来,模型提出了对齐感知段归一化和别名生成器来处理错位区域,并保留1024x768输入的细节。通过与现有方法的严格比较,证明VITON-HD在定性和定量上都大大优于其他模型。

# 源代码#https://github.com/sangyun884/HR-VITON! git clone https://github.com/cedro3/HR-VITON.git
%cd HR-VITON
! pip install tensorboardX
! pip install torchgeometryimport gdown
gdown.download('https://drive.google.com/uc?id=1XJTCdRBOPVgVTmqzhVGFAgMm2NLkw5uQ', 'mtviton_step_100000.pth', quiet=False)
gdown.download('https://drive.google.com/uc?id=1BkSA8UJo-6eOkKcXTFOHK80Esc4vBmVC', 'gen_step_110000.pth', quiet=False)
gdown.download('https://drive.google.com/uc?id=1CcgCubhLc9iF6jGACdUgGhTDWMC7Gjzr', 'test.zip', quiet=False)
! unzip test.zipfrom function import *import warningswarnings.filterwarnings("ignore")
! mkdir download首先,需要下载预训练模型与数据集,并解压出来,方便我们调用里面的图片(模特与衣服)
模型使用VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization
的数据集训练和评估此模型。
下载数据集:https://github.com/shadow2496/VITON-HD。然后我们把所有图片解压在image文件夹中,并设置一个随机参数来从数据集中随机挑选出5个模特与 5件衣服,以便模型把5件衣服分别穿在5个不同模特的身上。并把图片信息保持在test_pairs.txt文件中。
import glob
import randomimport shutil
import osseed_number = 120random.seed(seed_number)
reset_folder('image')
image_files = sorted(glob.glob('test/test/image/*.jpg'))
cnt = len(image_files)
num = random.sample(range(cnt),5)
image_names = []for i in num:
shutil.copy(image_files[i], 'image/'+os.path.basename(image_files[i]))
image_names.append(image_files[i])
image_names.sort()
display_pic('image')
reset_folder('cloth')
cloth_files = sorted(glob.glob('test/test/cloth/*.jpg'))
cnt = len(cloth_files)
num = random.sample(range(cnt),5)
cloth_names =[]for j in num:
shutil.copy(cloth_files[j], 'cloth/'+os.path.basename(cloth_files[j]))
cloth_names.append(cloth_files[j])
cloth_names.sort()
display_pic('cloth')if os.path.isfile('test/test/test_pairs.txt'): os.remove('test/test/test_pairs.txt')
f = open('test/test/test_pairs.txt', 'w', encoding='UTF-8')for image_name in image_names: for cloth_name in cloth_names:
f.write(os.path.basename(image_name)+' ')
f.write(os.path.basename(cloth_name)+'\n')
f.close()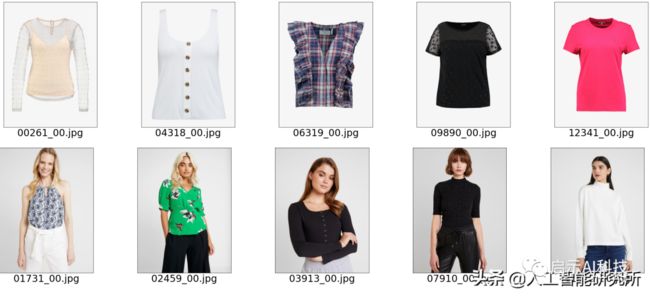
reset_folder('output')
! python3 test_generator.py --occlusion --tocg_checkpoint './mtviton_step_100000.pth'\
--gpu_ids 0\
--gen_checkpoint './gen_step_110000.pth'\
--datasetting unpaired\
--dataroot './test'\
--data_list './test/test_pairs.txt'clear_output()
display_pic_png('output/mtviton_step_100000.pth/test/unpaired/generator/output')然后我们根据下载的预训练模型与随机选择的图片与衣服进行模型的预测,预测结果保存在output文件夹下

模型预训完成后,会把5件衣服穿在5个模特身上,并依次排列出模特试穿衣服的效果
当然,我们也可使用ffmpeg来把生成的图片合成视频,若想查看其他衣服与模特可以修改第二段代码中的随机因子
import cv2
import glob
reset_folder('movie1')
reset_folder('movie2')
result_files = sorted(glob.glob('output/mtviton_step_100000.pth/test/unpaired/generator/output/*.png'))
cnt = 0
black = cv2.imread('black.jpg')
for image_name in image_names:
for cloth_name in cloth_names:
left = cv2.imread(image_name)
center = cv2.imread(cloth_name)
right = cv2.imread(result_files[cnt])
tmp = cv2.hconcat([left, center])
img1 = cv2.hconcat([tmp, right])
cv2.imwrite('movie1/'+str(cnt).zfill(4)+'.jpg', img1)
up = cv2.hconcat([black, center])
down = cv2.hconcat([left, right])
img2 = cv2.vconcat([up, down])
cv2.imwrite('movie2/'+str(cnt).zfill(4)+'.jpg', img2)
cnt +=1
! ffmpeg -y -r 1 -i movie1/%04d.jpg -vcodec libx264 -pix_fmt yuv420p -loglevel error output1.mp4
! ffmpeg -y -r 1 -i movie2/%04d.jpg -vcodec libx264 -pix_fmt yuv420p -loglevel error output2.mp4display_mp4('output1.mp4')
更多Transformer 视频动画教程
请参考头条号:人工智能研究所VX搜索小程序:AI人工智能工具,体验不一样的AI工具
