NNDL 实验六 卷积神经网络(3)LeNet实现MNIST
文章目录
- 5.3 基于LeNet实现手写体数字识别实验
-
- 5.3.1 数据
-
- 5.3.1.1 数据预处理
- 5.3.2 模型构建
- 5.3.3 模型训练
- 5.3.4 模型评价
- 5.3.5 模型预测
- 选做题
-
- 使用前馈神经网络实现MNIST识别,与LeNet效果对比。(选做)
- 可视化LeNet中的部分特征图和卷积核,谈谈自己的看法。(选做)
- 总结
-
- 心得体会
- 参考链接
5.3 基于LeNet实现手写体数字识别实验
在本节中,我们实现经典卷积网络LeNet-5,并进行手写体数字识别任务。
5.3.1 数据
手写体数字识别是计算机视觉中最常用的图像分类任务,让计算机识别出给定图片中的手写体数字(0-9共10个数字)。由于手写体风格差异很大,因此手写体数字识别是具有一定难度的任务。
我们采用常用的手写数字识别数据集:MNIST数据集。MNIST数据集是计算机视觉领域的经典入门数据集,包含了60,000个训练样本和10,000个测试样本。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28×28像素)。下图给出了部分样本的示例。

为了节省训练时间,本节选取MNIST数据集的一个子集进行后续实验,数据集的划分为:
- 训练集:1,000条样本
- 验证集:200条样本
- 测试集:200条样本
MNIST数据集分为train_set、dev_set和test_set三个数据集,每个数据集含两个列表分别存放了图片数据以及标签数据。比如train_set包含:
图片数据:[1 000, 784]的二维列表,包含1 000张图片。每张图片用一个长度为784的向量表示,内容是 28×28 尺寸的像素灰度值(黑白图片)。
标签数据:[1 000, 1]的列表,表示这些图片对应的分类标签,即0~9之间的数字。
观察数据集分布情况,代码实现如下:
import json
import gzip
# 打印并观察数据集分布情况
train_set, dev_set, test_set = json.load(gzip.open('./mnist.json.gz'))
train_images, train_labels = train_set[0][:1000], train_set[1][:1000]
dev_images, dev_labels = dev_set[0][:200], dev_set[1][:200]
test_images, test_labels = test_set[0][:200], test_set[1][:200]
train_set, dev_set, test_set = [train_images, train_labels], [dev_images, dev_labels], [test_images, test_labels]
print('Length of train/dev/test set:{}/{}/{}'.format(len(train_set[0]), len(dev_set[0]), len(test_set[0])))
运行结果:
Length of train/dev/test set:1000/200/200
可视化观察其中的一张样本以及对应的标签,代码如下所示:
import matplotlib.pyplot as plt
import numpy as np
import PIL
from PIL import Image
image, label = train_set[0][0], train_set[1][0]
image, label = np.array(image).astype('float32'), int(label)
# 原始图像数据为长度784的行向量,需要调整为[28,28]大小的图像
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
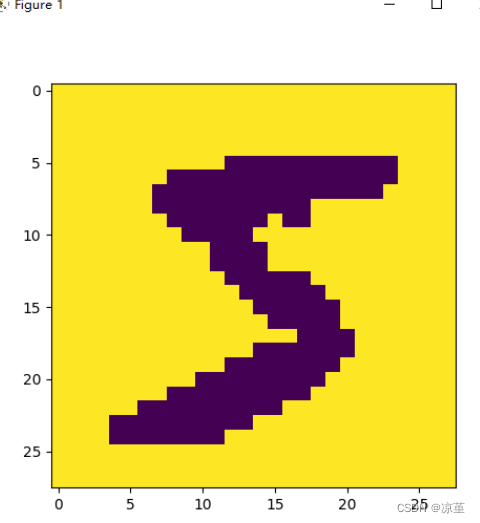
print("The number in the picture is {}".format(label))
plt.figure(figsize=(5, 5))
plt.imshow(image)
plt.savefig('conv-number5.pdf')
运行结果:
The number in the picture is 5
5.3.1.1 数据预处理
图像分类网络对输入图片的格式、大小有一定的要求,数据输入模型前,需要对数据进行预处理操作,使图片满足网络训练以及预测的需要。本实验主要应用了如下方法:
- 调整图片大小:LeNet网络对输入图片大小的要求为 32×32 ,而MNIST数据集中的原始图片大小却是 28×28 ,这里为了符合网络的结构设计,将其调整为32×32;
- 规范化: 通过规范化手段,把输入图像的分布改变成均值为0,标准差为1的标准正态分布,使得最优解的寻优过程明显会变得平缓,训练过程更容易收敛。
代码实现如下:
# 5.3.1.1
from torchvision.transforms import Compose, Resize, Normalize
# 数据预处理
transforms = Compose([Resize(32), Normalize(mean=[127.5], std=[127.5])])
将原始的数据集封装为Dataset类,以便DataLoader调用。
import random
from torch.utils.data import Dataset,DataLoader
import torchvision.transforms as transforms
class MNIST_dataset(Dataset):
def __init__(self, dataset, transforms, mode='train'):
self.mode = mode
self.transforms =transforms
self.dataset = dataset
def __getitem__(self, idx):
# 获取图像和标签
image, label = self.dataset[0][idx], self.dataset[1][idx]
image, label = np.array(image).astype('float32'), int(label)
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
image = self.transforms(image)
return image, label
def __len__(self):
return len(self.dataset[0])
random.seed(0)
# 加载 mnist 数据集
train_dataset = MNIST_dataset(dataset=train_set, transforms=transforms, mode='train')
test_dataset = MNIST_dataset(dataset=test_set, transforms=transforms, mode='test')
dev_dataset = MNIST_dataset(dataset=dev_set, transforms=transforms, mode='dev')
5.3.2 模型构建
LeNet-5虽然提出的时间比较早,但它是一个非常成功的神经网络模型。
基于LeNet-5的手写数字识别系统在20世纪90年代被美国很多银行使用,用来识别支票上面的手写数字。
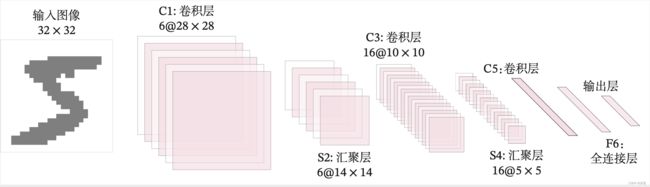
我们使用上面定义的卷积层算子和汇聚层算子构建一个LeNet-5模型。
这里的LeNet-5和原始版本有4点不同:
1.C3层没有使用连接表来减少卷积数量。
2.汇聚层使用了简单的平均汇聚,没有引入权重和偏置参数以及非线性激活函数。
3.卷积层的激活函数使用ReLU函数。
4.最后的输出层为一个全连接线性层。
网络共有7层,包含3个卷积层、2个汇聚层以及2个全连接层的简单卷积神经网络接,受输入图像大小为32×32=1024,输出对应10个类别的得分。
具体实现如下:
import torch.nn.functional as F
import torch.nn as nn
class Model_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Model_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5×5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5×5,步长为1
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=(2, 2), stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5×5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(120, 84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(84, num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, dim=3)
output = torch.squeeze(output, dim=2)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output
下面测试一下上面的LeNet-5模型,构造一个形状为 [1,1,32,32]的输入数据送入网络,观察每一层特征图的形状变化。代码实现如下:
# 这里用np.random创建一个随机数组作为输入数据
inputs = np.random.randn(*[1, 1, 32, 32])
inputs = inputs.astype('float32')
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
print(model)
# 通过调用LeNet从基类继承的sublayers()函数,查看LeNet中所包含的子层
print(model.named_parameters())
x = torch.tensor(inputs)
print(x)
for item in model.children():
# item是LeNet类中的一个子层
# 查看经过子层之后的输出数据形状
item_shapex = 0
names = []
parameter = []
for name in item.named_parameters():
names.append(name[0])
parameter.append(name[1])
item_shapex += 1
try:
x = item(x)
except:
# 如果是最后一个卷积层输出,需要展平后才可以送入全连接层
x = x.reshape([x.shape[0], -1])
x = item(x)
if item_shapex == 2:
# 查看卷积和全连接层的数据和参数的形状,
# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b
print(item, x.shape, parameter[0].shape, parameter[1].shape)
else:
# 汇聚层没有参数
print(item, x.shape)
运行结果:
Model_LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(pool4): AvgPool2d(kernel_size=(2, 2), stride=2, padding=0)
(conv5): Conv2d(16, 120, kernel_size=(5, 5), stride=(1, 1))
(linear6): Linear(in_features=120, out_features=84, bias=True)
(linear7): Linear(in_features=84, out_features=10, bias=True)
)
<generator object Module.named_parameters at 0x000001FB08489F10>
tensor([[[[-0.3585, -0.5452, 1.3631, ..., 1.2136, -0.1091, 2.4632],
[-0.1857, 0.4949, -0.8363, ..., -0.8915, -0.6937, 1.2373],
[ 0.0445, 1.9412, 2.5286, ..., -1.4750, -0.1582, -0.2900],
...,
[-0.8129, 0.9677, -0.7584, ..., -0.9465, -0.5650, 0.9721],
[-1.0167, -1.6895, 0.6300, ..., 2.8304, -0.5249, 0.1658],
[ 0.1880, -1.6031, -1.4927, ..., 1.9868, 0.4754, 0.1171]]]])
Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) torch.Size([1, 6, 28, 28]) torch.Size([6, 1, 5, 5]) torch.Size([6])
MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False) torch.Size([1, 6, 14, 14])
Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) torch.Size([1, 16, 10, 10]) torch.Size([16, 6, 5, 5]) torch.Size([16])
AvgPool2d(kernel_size=(2, 2), stride=2, padding=0) torch.Size([1, 16, 5, 5])
Conv2d(16, 120, kernel_size=(5, 5), stride=(1, 1)) torch.Size([1, 120, 1, 1]) torch.Size([120, 16, 5, 5]) torch.Size([120])
Linear(in_features=120, out_features=84, bias=True) torch.Size([1, 84]) torch.Size([84, 120]) torch.Size([84])
Linear(in_features=84, out_features=10, bias=True) torch.Size([1, 10]) torch.Size([10, 84]) torch.Size([10])
从输出结果看,
- 对于大小为32×32的单通道图像,先用6个大小为5×5的卷积核对其进行卷积运算,输出为6个28×28大小的特征图;
- 6个28×28大小的特征图经过大小为2×2,步长为2的汇聚层后,输出特征图的大小变为14×14;
- 6个14×14大小的特征图再经过16个大小为5×5的卷积核对其进行卷积运算,得到16个10×10大小的输出特征图;
- 16个10×10大小的特征图经过大小为2×2,步长为2的汇聚层后,输出特征图的大小变为5×5;
- 16个5×5大小的特征图再经过120个大小为5×5的卷积核对其进行卷积运算,得到120个1×1大小的输出特征图;
- 此时,将特征图展平成1维,则有120个像素点,经过输入神经元个数为120,输出神经元个数为84的全连接层后,输出的长度变为84。
- 再经过一个全连接层的计算,最终得到了长度为类别数的输出结果。
考虑到自定义的Conv2D和Pool2D算子中包含多个for循环,所以运算速度比较慢。飞桨框架中,针对卷积层算子和汇聚层算子进行了速度上的优化,这里基于paddle.nn.Conv2D、paddle.nn.MaxPool2D和paddle.nn.AvgPool2D构建LeNet-5模型,对比与上边实现的模型的运算速度。代码实现如下:
class Torch_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Torch_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5*5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5*5
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5*5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(in_features=120, out_features=84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(in_features=84, out_features=num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, dim=3)
output = torch.squeeze(output, dim=2)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output
测试两个网络的运算速度。
import time
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 创建Torch_LeNet类的实例,指定模型名称和分类的类别数目
torch_model = Torch_LeNet(in_channels=1, num_classes=10)
# 计算Model_LeNet类的运算速度
model_time = 0
for i in range(60):
strat_time = time.time()
out = model(x)
end_time = time.time()
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
model_time += (end_time - strat_time)
avg_model_time = model_time / 50
print('Model_LeNet speed:', avg_model_time, 's')
# 计算Torch_LeNet类的运算速度
torch_model_time = 0
for i in range(60):
strat_time = time.time()
torch_out = torch_model(x)
end_time = time.time()
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
torch_model_time += (end_time - strat_time)
avg_torch_model_time = torch_model_time / 50
print('Torch_LeNet speed:', avg_torch_model_time, 's')
运行结果:
Model_LeNet speed: 0.0004978704452514648 s
Torch_LeNet speed: 0.000518350601196289 s
这里还可以令两个网络加载同样的权重,测试一下两个网络的输出结果是否一致。
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 获取网络的权重
params = model.state_dict()
# 自定义Conv2D算子的bias参数形状为[out_channels, 1]
# torch API中Conv2D算子的bias参数形状为[out_channels]
# 需要进行调整后才可以赋值
for key in params:
if 'bias' in key:
params[key] = params[key].squeeze()
# 创建Torch_LeNet类的实例,指定模型名称和分类的类别数目
torch_model = Torch_LeNet(in_channels=1, num_classes=10)
# 将Model_LeNet的权重参数赋予给Torch_LeNet模型,保持两者一致
torch_model.load_state_dict(params)
# 打印结果保留小数点后6位
torch.set_printoptions(6)
# 计算Model_LeNet的结果
output = model(x)
print('Model_LeNet output: ', output)
# 计算Torch_LeNet的结果
torch_output = torch_model(x)
print('Torch_LeNet output: ', torch_output)
运行结果:
Model_LeNet output: tensor([[ 0.026521, 0.122189, -0.049708, -0.073667, -0.013976, -0.019401,
0.041322, -0.131140, -0.007805, -0.044831]],
grad_fn=<AddmmBackward0>)
Torch_LeNet output: tensor([[ 0.026521, 0.122189, -0.049708, -0.073667, -0.013976, -0.019401,
0.041322, -0.131140, -0.007805, -0.044831]],
grad_fn=<AddmmBackward0>)
可以看到,输出结果是一致的。
这里还可以统计一下LeNet-5模型的参数量和计算量。
参数量
按照公式(5.18)进行计算,可以得到:
- 第一个卷积层的参数量为:6×1×5×5+6=156;
- 第二个卷积层的参数量为:16×6×5×5+16=2416;
- 第三个卷积层的参数量为:120×16×5×5+120=48120;
- 第一个全连接层的参数量为:120×84+84=10164;
- 第二个全连接层的参数量为:84×10+10=850;
所以,LeNet-5总的参数量为61706。
在飞桨中,还可以使用paddle.summaryAPI自动计算参数量。
from torchsummary import summary
model = Torch_LeNet(in_channels=1, num_classes=10)
params_info = summary(model, (1, 32, 32))
print(params_info)
运行结果:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 156
MaxPool2d-2 [-1, 6, 14, 14] 0
Conv2d-3 [-1, 16, 10, 10] 2,416
AvgPool2d-4 [-1, 16, 5, 5] 0
Conv2d-5 [-1, 120, 1, 1] 48,120
Linear-6 [-1, 84] 10,164
Linear-7 [-1, 10] 850
================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.06
Params size (MB): 0.24
Estimated Total Size (MB): 0.30
----------------------------------------------------------------
None
可以看到,结果与公式推导一致。
计算量
按照公式(5.19)进行计算,可以得到:
- 第一个卷积层的计算量为: 28 × 28 × 5 × 5 × 6 × 1 + 28 × 28 × 6 = 122304 28\times 28\times 5\times 5\times 6\times 1 + 28\times 28\times 6=122304 28×28×5×5×6×1+28×28×6=122304;
- 第二个卷积层的计算量为: 10 × 10 × 5 × 5 × 16 × 6 + 10 × 10 × 16 = 241600 10\times 10\times 5\times 5\times 16\times 6 + 10\times 10\times 16=241600 10×10×5×5×16×6+10×10×16=241600;
- 第三个卷积层的计算量为: 1 × 1 × 5 × 5 × 120 × 16 + 1 × 1 × 120 = 48120 1\times 1\times 5\times 5\times 120\times 16 + 1\times 1\times 120=48120 1×1×5×5×120×16+1×1×120=48120;
- 平均汇聚层的计算量为: 16 × 5 × 5 = 400 16\times 5\times 5=400 16×5×5=400
- 第一个全连接层的计算量为: 120 × 84 = 10080 120 \times 84 = 10080 120×84=10080;
- 第二个全连接层的计算量为: 84 × 10 = 840 84 \times 10 = 840 84×10=840;
所以,LeNet-5总的计算量为 423344 423344 423344。
在飞桨中,还可以使用paddle.flopsAPI自动统计计算量。
可以看到,结果与公式推导一致。
5.3.3 模型训练
使用交叉熵损失函数,并用随机梯度下降法作为优化器来训练LeNet-5网络。
用RunnerV3在训练集上训练5个epoch,并保存准确率最高的模型作为最佳模型。
import torch
from torch import nn as nn
import torch.nn.functional as F
import numpy as np
from PIL import Image
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
y = torch.tensor(y, dtype=torch.int64)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
self.optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
y = torch.tensor(y, dtype=torch.int64)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
model_state_dict = torch.load(model_path)
self.model.set_state_dict(model_state_dict)
class torch_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(torch_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5*5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5*5
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5*5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(in_features=120, out_features=84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(in_features=84, out_features=num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output
lr = 0.1
# 批次大小
batch_size = 64
class MNIST_dataset(torch.utils.data.Dataset):
def __init__(self, dataset, transforms, mode='train'):
self.mode = mode
self.transforms =transforms
self.dataset = dataset
def __getitem__(self, idx):
# 获取图像和标签
image, label = self.dataset[0][idx], self.dataset[1][idx]
image, label = np.array(image).astype('float32'), int(label)
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
image = self.transforms(image)
return image, label
def __len__(self):
return len(self.dataset[0])
from torchvision.transforms import Compose, Resize, Normalize,ToTensor
def accuracy(preds, labels):
# 判断是二分类任务还是多分类任务,preds.shape[1]=1时为二分类任务,preds.shape[1]>1时为多分类任务
if preds.shape[1] == 1:
# 二分类时,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
# 使用'torch.tensor()'将preds的数据类型转换为float32类型
preds = torch.as_tensor((preds >= 0.5),dtype=torch.float32)
else:
# 多分类时,使用'torch.argmax'计算最大元素索引作为类别
preds = torch.argmax(preds, dim=1).int()
return torch.mean(torch.as_tensor((preds == labels),dtype=torch.float32))
import torch
class Accuracy():
def __init__(self, is_logist=True):
"""
输入:
- is_logist: outputs是logist还是激活后的值
"""
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = is_logist
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, dim=-1)
if self.is_logist:
# logist判断是否大于0
preds = torch.tensor((outputs >= 0), dtype=torch.float32)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.tensor((outputs >= 0.5), dtype=torch.float32)
else:
# 多分类时,使用'paddle.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1)
preds = torch.tensor(preds, dtype=torch.int64)
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
# 数据预处理
transforms = Compose([Resize(32),ToTensor(), Normalize(mean=[127.5], std=[127.5])])
# 加载 mnist 数据集
train_dataset = MNIST_dataset(dataset=train_set, transforms=transforms, mode='train')
test_dataset = MNIST_dataset(dataset=test_set, transforms=transforms, mode='test')
dev_dataset = MNIST_dataset(dataset=dev_set, transforms=transforms, mode='dev')
# 加载数据
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = torch.utils.data.DataLoader(dev_dataset, batch_size=batch_size)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
# 定义LeNet网络
# 自定义算子实现的LeNet-5
# model = Model_LeNet(in_channels=1, num_classes=10)
# 飞桨API实现的LeNet-5
model = torch_LeNet(in_channels=1, num_classes=10)
# 定义优化器
optimizer = torch.optim.SGD(lr=lr, params=model.parameters())
# 定义损失函数
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy(is_logist=True)
# 实例化 RunnerV3 类,并传入训练配置。
runner = RunnerV3(model=model, optimizer=optimizer,loss_fn = loss_fn, metric=metric)
# 启动训练
log_steps = 15
eval_steps = 15
runner.train(train_loader, dev_loader, num_epochs=5, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
运行结果:
[Train] epoch: 0/5, step: 0/80, loss: 2.31964
[Train] epoch: 0/5, step: 15/80, loss: 1.96424
[Evaluate] dev score: 0.31000, dev loss: 1.94272
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.31000
[Train] epoch: 1/5, step: 30/80, loss: 1.90126
[Evaluate] dev score: 0.58500, dev loss: 1.58386
[Evaluate] best accuracy performence has been updated: 0.31000 --> 0.58500
[Train] epoch: 2/5, step: 45/80, loss: 0.92311
[Evaluate] dev score: 0.63000, dev loss: 1.17126
[Evaluate] best accuracy performence has been updated: 0.58500 --> 0.63000
[Train] epoch: 3/5, step: 60/80, loss: 0.31175
[Evaluate] dev score: 0.80000, dev loss: 0.40704
[Evaluate] best accuracy performence has been updated: 0.63000 --> 0.80000
[Train] epoch: 4/5, step: 75/80, loss: 0.36434
[Evaluate] dev score: 0.83000, dev loss: 0.44397
[Evaluate] best accuracy performence has been updated: 0.80000 --> 0.83000
[Evaluate] dev score: 0.85000, dev loss: 0.50347
[Evaluate] best accuracy performence has been updated: 0.83000 --> 0.85000
[Train] Training done!
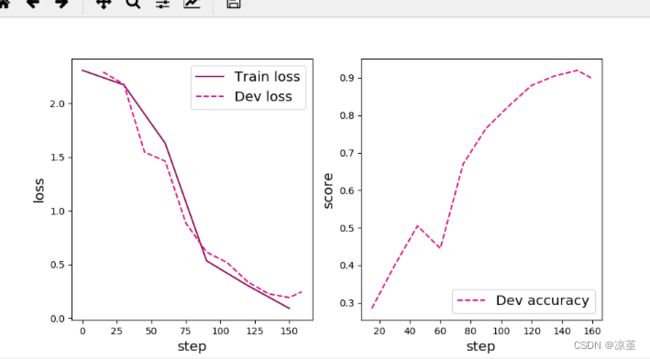
可视化观察训练集与验证集的损失变化情况。
# 可视化误差
def plot(runner, fig_name):
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
train_items = runner.train_step_losses[::30]
train_steps = [x[0] for x in train_items]
train_losses = [x[1] for x in train_items]
plt.plot(train_steps, train_losses, color='#8E004D', label="Train loss")
if runner.dev_losses[0][0] != -1:
dev_steps = [x[0] for x in runner.dev_losses]
dev_losses = [x[1] for x in runner.dev_losses]
plt.plot(dev_steps, dev_losses, color='#E20079', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='x-large')
plt.xlabel("step", fontsize='x-large')
plt.legend(loc='upper right', fontsize='x-large')
plt.subplot(1, 2, 2)
# 绘制评价准确率变化曲线
if runner.dev_losses[0][0] != -1:
plt.plot(dev_steps, runner.dev_scores,
color='#E20079', linestyle="--", label="Dev accuracy")
else:
plt.plot(list(range(len(runner.dev_scores))), runner.dev_scores,
color='#E20079', linestyle="--", label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize='x-large')
plt.xlabel("step", fontsize='x-large')
plt.legend(loc='lower right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()
runner.load_model('best_model.pdparams')
plot(runner, 'cnn-loss1.pdf')
运行结果:
[Evaluate] dev score: 0.50000, dev loss: 1.37084
[Evaluate] best accuracy performence has been updated: 0.30000 --> 0.50000
[Train] epoch: 4/10, step: 75/160, loss: 1.79037
[Evaluate] dev score: 0.39500, dev loss: 1.68836
[Train] epoch: 5/10, step: 90/160, loss: 0.97746
[Evaluate] dev score: 0.72000, dev loss: 0.99998
[Evaluate] best accuracy performence has been updated: 0.50000 --> 0.72000
[Train] epoch: 6/10, step: 105/160, loss: 0.65764
[Evaluate] dev score: 0.76000, dev loss: 0.60664
[Evaluate] best accuracy performence has been updated: 0.72000 --> 0.76000
[Train] epoch: 7/10, step: 120/160, loss: 0.36129
[Evaluate] dev score: 0.77000, dev loss: 0.60093
[Evaluate] best accuracy performence has been updated: 0.76000 --> 0.77000
[Train] epoch: 8/10, step: 135/160, loss: 0.28965
[Evaluate] dev score: 0.84000, dev loss: 0.39456
[Evaluate] best accuracy performence has been updated: 0.77000 --> 0.84000
[Train] epoch: 9/10, step: 150/160, loss: 0.15746
[Evaluate] dev score: 0.87500, dev loss: 0.31205
[Evaluate] best accuracy performence has been updated: 0.84000 --> 0.87500
[Evaluate] dev score: 0.89500, dev loss: 0.28777
[Evaluate] best accuracy performence has been updated: 0.87500 --> 0.89500
[Train] Training done!
5.3.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失变化情况。
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
运行结果:
[Test] accuracy/loss: 0.9050/0.2857
5.3.5 模型预测
同样地,我们也可以使用保存好的模型,对测试集中的某一个数据进行模型预测,观察模型效果。
# 获取测试集中第一条数
X, label = next(iter(test_loader))
logits = runner.predict(X)
# 多分类,使用softmax计算预测概率
pred = F.softmax(logits, dim=1)
print(pred.shape)
# 获取概率最大的类别
pred_class = torch.argmax(pred[1]).numpy()
print(pred_class)
label = label[1].numpy()
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
# 可视化图片
plt.figure(figsize=(2, 2))
image, label = test_set[0][1], test_set[1][1]
image= np.array(image).astype('float32')
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
plt.imshow(image)
plt.savefig('cnn-number2.pdf')
运行结果:
The true category is 1 and the predicted category is 1
选做题
使用前馈神经网络实现MNIST识别,与LeNet效果对比。(选做)
# coding=gbk
import numpy as np
import torch
import matplotlib.pyplot as plt
from torchvision.datasets import mnist
from torchvision import transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
train_batch_size = 64#超参数
test_batch_size = 128#超参数
learning_rate = 0.01#学习率
nums_epoches = 20#训练次数
lr = 0.1#优化器参数
momentum = 0.5#优化器参数
train_dataset = mnist.MNIST('./data', train=True, transform=transforms.ToTensor(), target_transform=None, download=True)
test_dataset = mnist.MNIST('./data', train=False, transform=transforms.ToTensor(), target_transform=None, download=False)
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)
class model(nn.Module):
def __init__(self, in_dim, hidden_1, hidden_2, out_dim):
super(model, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, hidden_1, bias=True), nn.BatchNorm1d(hidden_1))
self.layer2 = nn.Sequential(nn.Linear(hidden_1, hidden_2, bias=True), nn.BatchNorm1d(hidden_2))
self.layer3 = nn.Sequential(nn.Linear(hidden_2, out_dim))
def forward(self, x):
# 注意 F 与 nn 下的激活函数使用起来不一样的
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x
#实例化网络
model = model(28*28,300,100,10)
#定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
#momentum:动量因子
optimizer = optim.SGD(model.parameters(),lr=lr,momentum=momentum)
def train():
# 开始训练 先定义存储损失函数和准确率的数组
losses = []
acces = []
# 测试用
eval_losses = []
eval_acces = []
for epoch in range(nums_epoches):
# 每次训练先清零
train_loss = 0
train_acc = 0
# 将模型设置为训练模式
model.train()
# 动态学习率
if epoch % 5 == 0:
optimizer.param_groups[0]['lr'] *= 0.1
for img, label in train_loader:
# 例如 img=[64,1,28,28] 做完view()后变为[64,1*28*28]=[64,784]
# 把图片数据格式转换成与网络匹配的格式
img = img.view(img.size(0), -1)
# 前向传播,将图片数据传入模型中
# out输出10维,分别是各数字的概率,即每个类别的得分
out = model(img)
# 这里注意参数out是64*10,label是一维的64
loss = criterion(out, label)
# 反向传播
# optimizer.zero_grad()意思是把梯度置零,也就是把loss关于weight的导数变成0
optimizer.zero_grad()
loss.backward()
# 这个方法会更新所有的参数,一旦梯度被如backward()之类的函数计算好后,我们就可以调用这个函数
optimizer.step()
# 记录误差
train_loss += loss.item()
# 计算分类的准确率,找到概率最大的下标
_, pred = out.max(1)
num_correct = (pred == label).sum().item() # 记录标签正确的个数
acc = num_correct / img.shape[0]
train_acc += acc
losses.append(train_loss / len(train_loader))
acces.append(train_acc / len(train_loader))
eval_loss = 0
eval_acc = 0
model.eval()
for img, label in test_loader:
img = img.view(img.size(0), -1)
out = model(img)
loss = criterion(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
eval_loss += loss.item()
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
print('epoch:{},Train Loss:{:.4f},Train Acc:{:.4f},Test Loss:{:.4f},Test Acc:{:.4f}'
.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader),
eval_loss / len(test_loader), eval_acc / len(test_loader)))
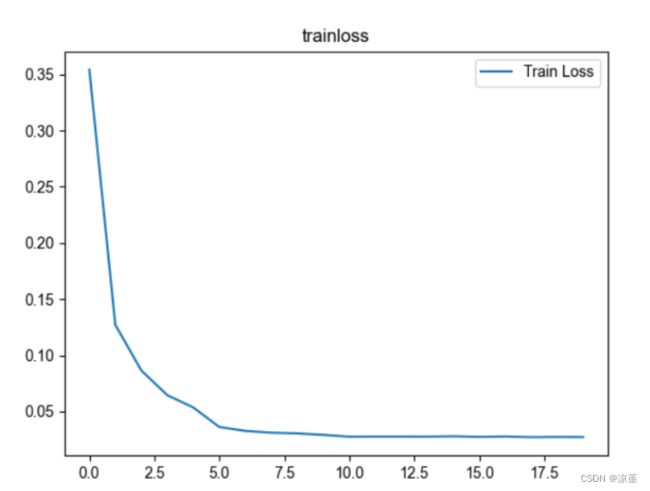
plt.title('trainloss')
plt.plot(np.arange(len(losses)), losses)
plt.legend(['Train Loss'], loc='upper right')
#测试
from sklearn.metrics import confusion_matrix
import seaborn as sns
def test():
correct = 0
total = 0
y_predict=[]
y_true=[]
with torch.no_grad():
for data in test_loader:
input, target = data
input = input.view(input.size(0), -1)
output = model(input)#输出十个最大值
_, predict = torch.max(output.data, dim=1)#元组取最大值的下表
#
#print('predict:',predict)
total += target.size(0)
correct += (predict == target).sum().item()
y_predict.extend(predict.tolist())
y_true.extend(target.tolist())
print('正确率:', correct / total)
print('correct=', correct)
sns.set()
f, ax = plt.subplots()
C2 = confusion_matrix(y_true, y_predict, labels=[0, 1, 2,3,4,5,6,7,8,9])
print(C2)
plt.imshow(C2, cmap=plt.cm.Blues)
plt.xticks(range(10),labels=[0, 1, 2,3,4,5,6,7,8,9] , rotation=45)
plt.yticks(range(10),labels=[0, 1, 2,3,4,5,6,7,8,9])
plt.colorbar()
plt.xlabel('True Labels')
plt.ylabel('Predicted Labels')
plt.title('Confusion matrix (acc=' + str(correct / total)+ ')')
plt.show()
train()
test()
运行结果:
epoch:0,Train Loss:0.3542,Train Acc:0.9152,Test Loss:0.1281,Test Acc:0.9617
epoch:1,Train Loss:0.1271,Train Acc:0.9665,Test Loss:0.0822,Test Acc:0.9767
epoch:2,Train Loss:0.0865,Train Acc:0.9769,Test Loss:0.0619,Test Acc:0.9825
epoch:3,Train Loss:0.0646,Train Acc:0.9825,Test Loss:0.0504,Test Acc:0.9857
epoch:4,Train Loss:0.0536,Train Acc:0.9853,Test Loss:0.0423,Test Acc:0.9891
epoch:5,Train Loss:0.0362,Train Acc:0.9912,Test Loss:0.0265,Test Acc:0.9940
epoch:6,Train Loss:0.0328,Train Acc:0.9924,Test Loss:0.0269,Test Acc:0.9940
epoch:7,Train Loss:0.0312,Train Acc:0.9935,Test Loss:0.0258,Test Acc:0.9941
epoch:8,Train Loss:0.0306,Train Acc:0.9930,Test Loss:0.0258,Test Acc:0.9937
epoch:9,Train Loss:0.0293,Train Acc:0.9938,Test Loss:0.0251,Test Acc:0.9941
epoch:10,Train Loss:0.0276,Train Acc:0.9943,Test Loss:0.0249,Test Acc:0.9944
epoch:11,Train Loss:0.0277,Train Acc:0.9944,Test Loss:0.0242,Test Acc:0.9941
epoch:12,Train Loss:0.0277,Train Acc:0.9945,Test Loss:0.0243,Test Acc:0.9948
epoch:13,Train Loss:0.0277,Train Acc:0.9943,Test Loss:0.0241,Test Acc:0.9947
epoch:14,Train Loss:0.0280,Train Acc:0.9941,Test Loss:0.0237,Test Acc:0.9946
epoch:15,Train Loss:0.0275,Train Acc:0.9945,Test Loss:0.0242,Test Acc:0.9952
epoch:16,Train Loss:0.0278,Train Acc:0.9942,Test Loss:0.0242,Test Acc:0.9950
epoch:17,Train Loss:0.0272,Train Acc:0.9945,Test Loss:0.0248,Test Acc:0.9944
epoch:18,Train Loss:0.0274,Train Acc:0.9946,Test Loss:0.0236,Test Acc:0.9947
epoch:19,Train Loss:0.0273,Train Acc:0.9950,Test Loss:0.0240,Test Acc:0.9946
正确率: 0.9946
correct= 9946
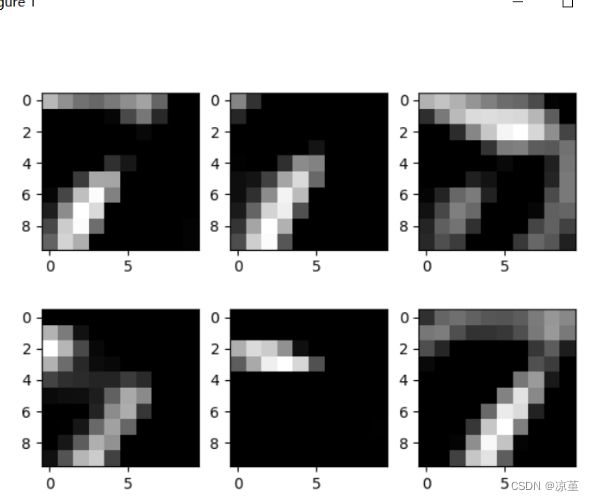
可视化LeNet中的部分特征图和卷积核,谈谈自己的看法。(选做)




代码如下:
class Paddle_LeNet1(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Paddle_LeNet1, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5*5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5*5
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5*5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(in_features=120, out_features=84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(in_features=84, out_features=num_classes)
def forward(self, x):
image=[]
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
image.append(output)
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
image.append(output)
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
image.append(output)
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, dim=3)
output = torch.squeeze(output, dim=2)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return image
# create model
model1 = Paddle_LeNet1(in_channels=1, num_classes=10)
# model_weight_path ="./AlexNet.pth"
model_weight_path = 'best_model.pdparams'
model1.load_state_dict(torch.load(model_weight_path))
# forward正向传播过程
out_put = model1(X)
print(out_put[0].shape)
for i in range(0,3):
for feature_map in out_put[i]:
# [N, C, H, W] -> [C, H, W] 维度变换
im = np.squeeze(feature_map.detach().numpy())
# [C, H, W] -> [H, W, C]
im = np.transpose(im, [1, 2, 0])
print(im.shape)
# show 9 feature maps
plt.figure()
for i in range(6):
ax = plt.subplot(2, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
# [H, W, C]
# 特征矩阵每一个channel对应的是一个二维的特征矩阵,就像灰度图像一样,channel=1
# plt.imshow(im[:, :, i])i,,
plt.imshow(im[:, :, i], cmap='gray')
plt.show()
break

总结
心得体会
此次实验完成了基于LeNet实现手写体字数字识别实验,对LeNet网络的构建和参数量、计算量有了更深的了解,与LeNet效果进行对比,得出在准确率和loss上,LeNet要明显好于FNN。
参考链接
NNDL 实验六 卷积神经网络(3)LeNet实现MNIST
NNDL 实验5(上) - HBU_DAVID - 博客园 (cnblogs.com)
7. 现代卷积神经网络 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)