卷积神经网络——FPN论文翻译
论文链接: https://arxiv.org/abs/1612.03144
Feature Pyramid Networks for Object Detection
0.摘要
特征金字塔是识别系统中用于检测不同尺度目标的基本组成部分。但是最近的深度学习对象检测器开始放弃使用金字塔方式,部分原因是它们是计算和内存密集型的(使用特征金字塔会增加算力和内存的消耗)。在本文中,我们利用深度卷积网络固有的多尺度、金字塔层级,以很小的额外成本建构特征金字塔。开发出一种具有横向连接的自顶向下的体系结构,用于构建各种尺度的高层语义特征图。该结构——被称为特征金字塔网络(FPN),展现出作为一个通用特征提取器对几个应用都有显著的提升。在一个基础版本的 Faster R-CNN系统中使用FPN,我们的方法在不使用任何精度提升技巧的前提下(这可能包括数据增强等一些操作)在COCO检测基准上实现了单模型最好的精度结果,超过了所有现有的单模式,包括COCO 2016挑战赛冠军。此外,我们的方法可以在GPU运行速度达到6fps,因此是一种实用而精确的多尺度目标检测方法。代码后面将公开。
总结一下: 由于现在的深度卷积网络要消耗大量的算力和内存,以前的特征金字塔已经逐渐被放弃, 我们现在提出了一种新的解决方案, 只用很小的成本就可以实现特征金字塔的特征提取,对精度有显著的提升,运行速度还很快
1. 绪论(Introduction)
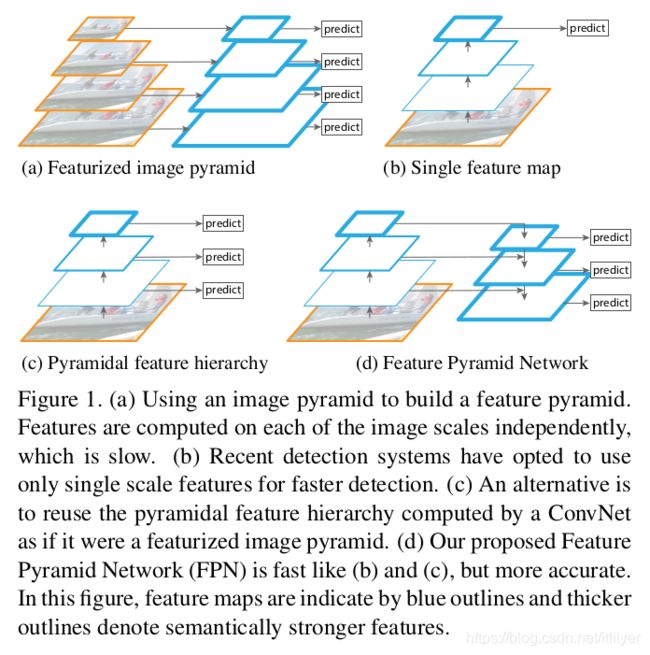
在计算机视觉中,识别不同尺度的物体是一个基本的挑战。基于图像金字塔创建的特征金字塔(我们简称为特征化的图像金字塔,featurized image pyramid)变成了标准解决方案的基础[1] (图1(a))。这些金字塔是尺度不变的,从某种意义上说,对象的尺度变化是通过改变金字塔中的级别来抵消的(个人理解:这里指通过变化对象的尺度也就是图像大小同时有与之对应的金字塔的层级,也就是说不同尺度的图像在特征金字塔中有对应尺度的特征图)。直观地说,此属性使模型能够通过扫描不同位置和金字塔级别的模型来检测大范围尺度的对象。
特征化图像金字塔在手工设计特征的时代被大量使用[5,25]。特征金字塔对于像DPM[7]这样的目标检测器至关重要以至于需要非常密集尺度采样才能达到很好的效果(例如每个octave 10个尺度)。对于识别任务,手动设计的特征在很大程度上已被深卷积网络(ConvNets)[19,20]计算的特征所取代。除了能够表示更高层次的语义之外,Convnet能够更好的适应尺度上的变化,因此有助于使用单个输入尺度上计算的特征进行识别[15,11,29](图1(b))。但是即使有了对于尺度变化的鲁棒性,金字塔仍然是获得最好结果所必须的。ImageNet[33]和COCO[21]检测挑战中的所有最新模型都使用了特征化图像金字塔的多尺度测试(例如[16,35])。特征化图像金字塔的每一个层次的主要优点是它产生一个多尺度的特征表示,而且生成的所有层次的语义表达力都很强,包括高分辨率的层次。
octave: 直译是八度。个人理解是只特定分辨率大小的图像。每一种分辨率可能对应了不同的尺度。更详细的解释可以参考SIFT算法
但是,对图像金字塔的每一层都进行特征化这种做法有非常明显局限性。会导致推理时间大大增加(例如,[11]中增加了4倍),使得这种方法不太可能用到实际应用中。此外,使用图像金字塔端到端地训练深层网络在内存方面是不可行的,因此,如果要使用的话,图像金字塔只能用在测试时使用[15,11,16,35],这将导致训练/测试阶段推断的不一致。基于这些原因,Fast和Faster R-CNN[11,29]在默认设置中不使用特征化的图像金字塔。(总结一下这几段: 主要讲了从图像金字塔提取特征金子塔的方法在以前的识别和检测方法中是必不可少的,但是由于它的一些缺点,在Fast和Faster RCNN中没有使用)
但是,图像金字塔并不是计算多尺度特征的唯一方法。深度卷积网络逐层计算一个特征层次,通过子采样层,特征层次具有固有的多种尺度、金字塔的形状。这种网络内的特征层次结构生成了不同空间分辨率的特征图,但由于深度的不同而引入了较大的语义鸿沟(个人理解:这里应该只的不同卷积层对应的深度)。高分辨率特征图的低层次特征损害了它们对物体识别中的表现能力。(low-level features:低层次特征主要指图像中的小的细节信息,例如边缘、角度、颜色、像素、梯度等信息,可以通过滤波器、SIFT和HOG来获取;high-level feature:高层次的特征是建立在低层次特征之上的,可以用于目标或物体识别和检测,拥有更丰富的语义信息。通常卷积网络前几层学到的是低层次特征,后面几层学到高层次特征)
The Single Shot Detector(SSD)[22]是第一次尝试使用ConvNet的金字塔状的特征层次结构,它好像是一个特征化的图像金字塔(图1(c))。理想情况下,SSD风格的金字塔将重用在前向过程中不同卷积层计算出的的多个尺度特征映射,这样不需要增加任何成本。但是为了避免使用low-level feature,SSD没有重用已经计算层的特征,而是从网络的高层开始构建金字塔(例如VGG nets[36]的conv4 3),然后添加几个新的层。因此,它错过了重用高分辨率的特征层的机会。我们将证明这对于探测小物体很重要。(SSD中特征金字塔的使用)
本文的目标是在创建一个在所有尺度上都具有强大语义的特征金字塔的时候能够很自然地利用ConvNet特征层次的金字塔形状来达到目的。为了实现这一目标,我们依赖一种通过自上而下的途径和横向连接将低分辨率、高分辨率的强语义特征、语义弱的特征相结合的架构(图1(d))。其结果是一个特征金字塔,它在所有级别都有丰富的语义,并且可以从单个输入图像尺度中快速构建出来。换言之,我们展示了如何在不牺牲表现力、速度或内存消耗的情况下, 创建一个可用于替换特征化图像金字塔的网络内的特征金字塔。
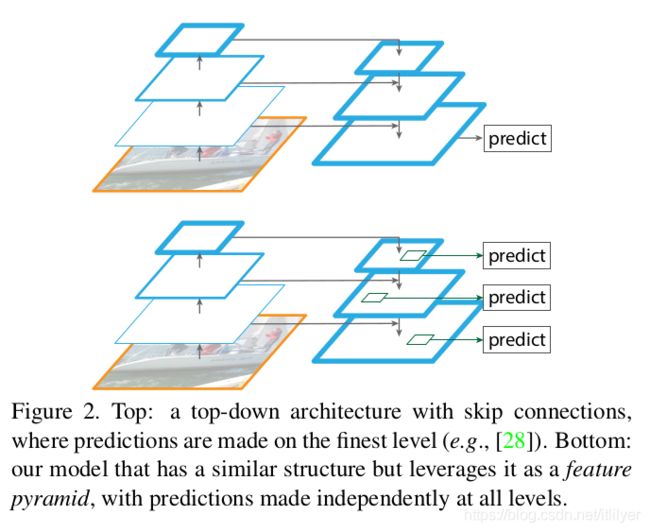
类似的架构——使用自上而下的跳跃链接,在最近的研究中非常流行[28,17,8,26]。他们的目标是产生一个单一的高分辨率的高层次特征图,在这个特征图上进行预测(图2上)。相反,我们的方法将该架构看做一个特征金字塔,在每个层次上独立地进行预测(例如,目标检测)(图2底部)。我们的模型与一个特征化的图像金字塔相呼应,在这些方案中还没有被探索过。
该方法——我们称为特征金字塔网络(FPN),在各种检测和分割系统中进行了评估[11,29,27]。在没有使用各种手段的前提下,我们在很有挑战性的COCO检测基准[21]上达到了一个性能最好的单模型结果,它仅仅基于FPN和一个基础版本的Faster R-CNN检测器[29],超过了所有现有精心设计的竞赛优胜者的单模型参赛作品。在消融实验中,我们发现对于候选边框,FPN大幅提升了Average Recall(AR)达8个百分点;对于目标检测,它将COCO-style的Average Precision(AP)提高了2.3个点,PASCAL-style的AP提高了3.8个点,超过了ResNets上Faster R-CNN非常牛x的单尺度基线[16]。我们的方法也很容易扩展到生成mask候选,并提高了实例分割的AR和速度,超过了目前性能最好的方法——非常依赖于图像金字塔。此外,我们的金字塔结构可以用所有的尺度进行端到端的训练,并且保持训练/测试阶段一致,这在使用图像金字塔时内存是不满足的。因此,FPNs能够比所有现有的最先进的方法获得更高的精度。此外,这种提升是与单尺度基线相比不增加测试时间的前提下实现的。我们相信这些进展将促进未来的研究和应用。我们的代码将公开。
2. 相关工作(Related Work)
手工设计特征和早期的神经网络。 SIFT特征[25]最初在尺度空间极值处提取,用于特征点匹配。HOG特征[5],以及后来的SIFT特征,都是在整个图像金字塔上密集计算得到的。这些HOG和SIFT金字塔在图像分类、目标检测、人体姿态估计等领域有着广泛的应用。快速计算特征图像金字塔也引起了人们的极大兴趣。Dollár等人[6] 展示了快速金字塔计算,首先计算稀疏采样(按尺度取)金字塔,然后利用插值补充缺失的金字塔层(个人理解:也就是先计算部分层,然后利用插值计算其他的值)。在HOG和SIFT之前,ConvNets[38,32]在人脸检测方面的早期应用中计算了图像金字塔上的浅层网络,以跨尺度检测人脸。
深度卷积网络目标检测。 随着现代深度卷积网络(ConvNets)[19]的发展,像Over Feat[34]和R-CNN[12]这样的目标探测器在精确度上有了显著的提高。OverFeat使用了与早期神经网络人脸检测类似的策略,将卷积网络作为一个在图像金字塔上的滑动窗口检测器。R-CNN使用的是基于候选区域的策略[37],每个候选区域在分类前都使用ConvNet进行了尺度标准化。SPPNet[15]证明了将这种基于区域的检测器应用到从单一图像尺度提取的特征图上会更加有效。最近更精确的检测方法,如Fast R-CNN[11]和Faster R-CNN[29]提倡使用从单一尺度计算的特征,因为它很好的平衡了精度和速度。然而,多尺度检测仍然表现得更好,特别是对于小目标。
使用多层的方法。 最近的许多方法通过使用ConvNet中不同的层来提升检测和分割的精度。FCN[24]将每个类别在多个尺度上的分数相加来计算语义分割。其他几种方法(HyperNet[18]、ParseNet[23]和ION[2])在预测之前将多层特征串联起来,这相当于对转换后的特征进行求和。SSD[22]和MS-CNN[3]在多个特征层次上预测对象,而不是特征或分数结合起来。
最近有一些方法利用横向/跳跃连接将分辨率和语义级别的低层特征图关联起来,包括用于分割的U-Net[31]和Sharp Mask[28],用于人脸检测的Recombinator网络[17],以及用于关键点估计的Stacked Hourglass网络[26]。Ghiasi等人[8]为FCN提出了一种拉普拉斯(Laplacian)金字塔表示法,以逐步细化分割。尽管这些方法采用金字塔形状的结构,但它们不同于特征化图像金字塔[5,7,34],在这些金字塔中,预测是在所有级别独立进行的,见图2。事实上,对于图2(上图)中的金字塔结构,仍然需要图像金字塔来识别跨越多个尺度的对象[28]。
3. 特征金字塔网络(Feature Pyramid Networks)核心章节
我们的目标是利用ConvNet的金字塔状的特征层次结构,它具有从低级别到高级别的语义,构建一个具有高层次语义的特征金字塔。由此得到的特征金字塔网络是通用的,在本文中我们重点研究滑动窗口方案(Region proposition Network,简称RPN)[29]和基于区域的检测器(Fast R-CNN)[11]。我们还将FPNs推广到章节6中实例分割方案上。
该方法以任意大小的单尺度图像为输入,以完全卷积的方式输出多个层次的大小成比例的特征图。这个过程独立于骨干网络的卷积结构(例如[19,36,16]),在本文中,我们给出了使用resnet[16]的结果。我们金字塔的构建包括一个自下而上的路径,一个自上而下的路径和横向连接,如下所述。
自下而上的路径。(Bottom-up pathway.) 自下而上的路径是骨干网络ConvNet的前向计算,计算得到一个由多个尺度的特征图组成的特征层次结构, 缩放的步长为2。通常有许多层生成相同大小的特征图,我们称这些层处于同一网络阶段。对于我们的特征金字塔,我们为每个阶段定义一个金字塔层级。我们选择每个阶段最后一层的输出作为我们的特征图的参考集,我们将对其进行丰富以创建金字塔。这是很自然的选择,因为每个阶段的最深层应该具有表达性最强的特性。
具体来说,对于resnet[16],我们使用每个阶段最后一个残差块输出的特征激活函数的输出。对于conv2、conv3、conv4和conv5的输出,我们将这些最后剩余块的输出表示为{C2,C3,C4,C5},并注意到它们相对于输入图像的步长为{4、8、16、32}像素。由于conv1占用大量内存,我们不将conv1包含在金字塔中。
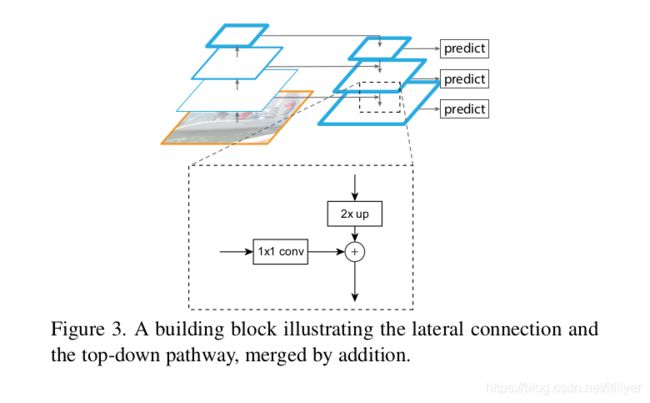
自上而下的路径和横向连接。(Top-down pathway and lateral connections.) 自上而下的路径通过对更高的金字塔层次的特征图(这些特征图虽然空间上粗糙,但是有更强的语义表达)进行上采样来模拟产生更高分辨率的特征。这些高分辨率的特征随后会通过与自底向上路径的特征进行横向连接来增强。每个横向连接将从自下而上的路径路径和自顶向下的路径中合并具有相同空间大小的特征图。自下而上的特征图具有较低层次的语义,但由于其子采样次数较少,因此其激活函数能够更精确地定位目标位置。
图3展示了构造自顶向下的特征图的构建单元块。对于较粗分辨率的特征映射,我们将空间分辨率通过上采样提高2倍(为简单起见,使用最近邻上采样)。然后,将上采样得到的特征图与相应的自下而上的特征图(经过1×1卷积层以减小channel尺寸) 通过逐元素相加进行合并。这个过程会通过迭代反复进行,直到生成最高分辨率的特征图。在迭代开始前,我们只需在C5后附加一个1×1的卷积层来生成最粗略的分辨率特征。最后,我们在每个合并后的特征图后面附加一个3×3的卷积来生成最终的特征图,以减少上采样的锯齿效应。最后生成的一组特征图称为{P2,P3,P4,P5},分别对应于空间大小相同的{C2,C3,C4,C5}。
由于金字塔的所有层都像传统的特征化图像金字塔一样使用共享的分类器/回归器(classifiers/regressors),所以我们将所有的特征图的维度设置为固定值(通道数,用d表示)。在本文中我们设置d=256,因此所有新增的的卷积层都有256个channel输出。在这些新增的层中没有引入非线性的操作,我们根据经验判断没有这些非线性操作影响很小。
我们设计的核心是简单,我们发现我们的模型对许多设计选择都有很好的鲁棒性。我们用更复杂的block(这里应该指上面提到的build block)进行了实验(例如,使用多层残差块体[16]作为连接模块),结果有很小的提升。本文的重点不是设计更好的连接模块,所以我们选择上面描述的简单设计。
4. 应用(Applications)
我们的方法是在deep ConvNets中构建特征金字塔的通用解决方案。下面将我们的方法应用到RPN[29]中来生成候选框,并应用到Fast R-CNN[11]中进行目标检测。为了证明我们方法的简单性和有效性,我们对[29,11]的原始系统进行了最小程度的修改,以适应我们的特征金字塔。
4.1. RPN中使用特征金字塔网络(Feature Pyramid Networks for RPN)
RPN[29]是一个滑动窗口未知类别对象检测器。在原始的RPN设计中,一个小的子网络在单尺度卷积特征图上使用密集的3×3滑动窗口进行估计,实现对象/非对象二元分类和边界框回归。这是通过一个3×3卷积层实现的,随后跟了两个并行的1×1卷积分别进行分类和回归,我们称之为头部(head)网络。对象/非对象的定义标准和边界框回归目标是根据一组称为anchor的参考框定义的[29]。anchor是具有多个预先定义好的尺度和纵横比,以便覆盖不同形状的对象。
我们通过用FPN代替单尺度特征图来适配RPN。我们在特征金字塔的每一层都增加了一个相同设计的头部(head)网络(3×3 的卷积后面跟着两个并行的1×1 卷积)。因为头部(head)网络会在所有金字塔层级的所有位置上密集滑动,所以不必在某一层级上使用多种尺度的anchor。相反,我们给每个层级都指定了一个尺度。我们将anchor定定义为在{P2,P3,P4,P5}上具有{322,642,1282,2562,5122}像素大小的区域。与[29]中一样,我们还在每个级别使用多个纵横比{1:2,1:1,2:1}的anchor。所以金字塔上总共有15种anchor。
我们根据anchor与真实边界框的交集比(IoU)为anchor分配训练标签,如[29]中所述。形式上,如果anchor与给定真值框有最高IoU或与任意真值框(ground-truth box)的IoU超过0.7,则为anchor分配一个正标签;如果anchor与所有的真值框的IoU低于0.3则分配负标签。请注意,真值框的尺度并没有明确用于将它们与金字塔的层级相关联;相反,真值框与anchor关联,anchor已被关联到了对应的金字塔层级。因此,除了[29]中的规则外,我们没有引入额外的规则。
我们注意到head网络的参数在所有特征金字塔层级上是共享的;我们还评估了没有共享参数的替代方案,并得到了类似的精度。共享参数的良好性能表明金字塔的各个层次共享相似的语义层次。这一优势类似于使用特征化图像金字塔,其中一个通用的head分类器可以应用于在任何图像尺度上计算的特征。
通过上述调整,RPN可以用我们的FPN进行顺利的训练和测试,其方式与[29]中相同。我们在实验中详细阐述了实现细节。
4.2 Fast R-CNN中使用特征金字塔(Feature Pyramid Networks for Fast R-CNN)
Fast R-CNN[11]是一种基于区域的目标检测器,其中使用感兴趣区域(RoI)池来提取特征。Fast R-CNN通常是在单一尺度的特征图上进行目标的检测。要将其与我们的FPN组合到一起,我们需要将不同比例的RoI对应到不同金字塔层级。
我们将特征金字塔看做就好像它是从一个图像金字塔产生的。因此,当基于区域的检测器在图像金字塔上运行时,我们可以调整它们的匹配策略[15,11]。从形式上讲,我们将宽度为w和高度为h(在网络的输入图像上)的RoI对应到我们的特征金字塔的Pk级别,方法是:
这里224是典型的ImageNet预训练大小,k0是w×h=2242的RoI应该映射到的目标级别。类似于基于ResNet的Faster R-CNN系统[16],它使用C4作为单尺度特征映射,我们将k0设置为4。直观地说,等式(1)意味着如果RoI的比例变小(比如224的1/2),它应该映射到更高分辨率级别(比如k=3)。
我们在所有层级的所有RoI后面都添加了一个用于预测的head网络(在Fast R-CNN中,head网络是特定类的分类器和边界框回归器)。同样,不考虑层级所有的head网络都共享参数。在[16]中,一个ResNet的conv5层(一个9层深的子网)被用作基于conv4层特征的head网络,但是我们的方法已经将conv5用于构造特征金字塔。因此与文献[16]不同的是,我们简单地采用RoI池化来提取7×7特征,并在最终分类和边界框回归层之前附加两个隐藏的1024-d全连接(fc)层(每个层后面接ReLU)。这些层是随机初始化的,因为resnet中没有预先训练过的fc层。请注意,与标准conv5 head网络相比,我们的2-fc MLP head权重更少,速度更快。
基于这些适配修改,我们可以在特征金字塔上训练和测试Fast R-CNN。实验部分给出了具体的实现细节。
5. 目标检测实验(Experiments on Object Detection)
我们在80分类的COCO检测数据集上进行实验[21]。我们使用80k的train数据集和35k的val数据集子集(trainval35k[2])的合集进行训练,并发布了在val数据集中5k子集(minival)上的消融实验。我们还发布了在标准测试集(test-std)[21]的最终结果,该测试集的标签没有公开。
正如常见的做法[12],所有网络主干都在ImageNet 1k分类集[33]上进行预训练,然后在检测数据集上进行微调(fine-tune)。我们使用预先训练的ResNet-50和ResNet-101模型,这些模型是公开的(https://github.com/kaiminghe/deep-residual-networks)。我们的代码是使用Caffe2(https://github.com/caffe2/caffe2)重新实现py-faster-rcnn(https://github.com/rbgirshick/py-faster-rcnn)。
5.1 RPN创建候选区域(Region Proposal with RPN)
根据文献[21]中的定义,我们评估了COCO风格Average Recall(AR)和小、中、大目标(ARs、ARm和ARs)的AR。我们发布了每幅图像100个和1000个候选的结果(AR100和AR1k)。
实现细节。 表1中的所有架构通过端到端的训练。调整输入图像的大小, 使较短边长度为800像素。我们采用同步SGD在8个GPU上进行训练。每个GPU上一个mini-batch包含2个图像,每个图像256个anchor。我们使用0.0001的权重衰减和0.9的momentum。前30k个mini-batch的学习率为0.02,后面10k个mini-batch的学习率为0.002。对于所有的RPN实验(包括基线),我们将超出图像范围的anchor也会用于训练,这与[29]中不同,它会忽略这些anchor。其他实现细节见[29]。在8个GPU上使用COCO训练FPN+RPN大约需要大约8个小时。
5.1.1 消融实验(Ablation Experiments)
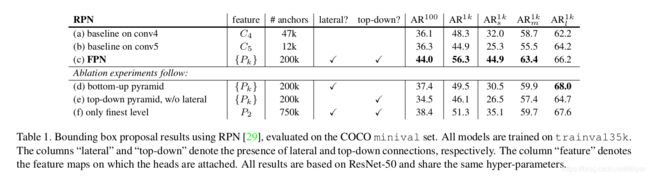
与基线比较。 为了与原始版本RPN[29]进行公平比较,我们使用C4(与[16]相同)或C5的单尺度特征图运行两个基线(表1(a,b)),两者都使用与我们相同的超参,包括5个尺度的anchor{322,642,1282,2562,5122}。表1(b)与(a)相比没有任何优势,这表明只用更高层次特征图是不够的,因为需要在低分辨率和强语义之间进行权衡。
在RPN中使用FPN可使AR1k提高到56.3(表1©),比单尺度的RPN基线提高了8.0点(表1(a))。此外,在小物体(AR1ks)上的性能得到了大幅度的提高,达到12.9个百分点。我们的金字塔方式大大提高了RPN对对象尺度变化的鲁棒性。
自上而下的路径对特征进行有多重要? 表1(d)显示了没有自上而下路径的特征金字塔的结果。修改方法: 金字塔的每层接了一个1x1的横向连接,每个1x1的连接后面在接一个3x3的卷积。该架构模拟重用金字塔特征层次的效果(图1(b))。
表1(d)中的结果与RPN基线相当,但远远落后于我们的结果。我们推测这是因为在自下而上的金字塔(图1(b))的不同层次之间存在着很大的语义差距,特别是对于非常深的ResNet。我们还评估了表1(d)的一个变体,没有共享head网络的参数,但是观察到了类似的性能下降。这个问题不能简单地由指定层级的head网络来解决。
横向连接有多重要? 表1(e)显示了没有1x1横向连接的自上而下特征金字塔的消融实验结果。这种自上而下的金字塔具有很强的语义特征和高分辨率。但我们认为这些特征的位置并不精确,因为这些特征图已经过多次下采样和上采样。更精确的特征位置可以通过横向连接直接从自下而上特征图传递到自上向下的特征图。因此,FPN的AR1k得分比表1(e)高10个百分点。
金字塔表示特征有多重要? 不使用金字塔表示法,人们可以将head网络附加到最高分辨率、强语义特征图(即金字塔中最精细的层次)的P2特征图上。与单尺度的基线类似,我们在P2的特征图上取所有尺度的anchor。这种变体(表1(f))优于基线,但不如我们的方法。RPN是一种窗口大小固定的滑动窗口检测器,因此在金字塔多个层级上扫描可以提高其对尺度变化的鲁棒性。
此外,我们注意到,单独使用P2会生成更多的anchor(750k,表1(f)),这是由其较大的空间分辨率造成的。这一结果表明,较大的anchor数量并不足以提高精度。
5.2 使用Fast/Faster R-CNN实现目标检测(Object Detection with Fast/Faster R-CNN)
接下来我们研究将FPN应用与基于区域(非滑动窗口)的检测器。我们用COCO风格的平均精度(AP)和PASCAL风格的AP(单个IoU阈值为0.5)来评估目标检测。根据[21]中的定义,我们还发布 小型、中型和大型物体(即APs、APm和APs)的COCO AP。
实现细节。 调整输入图像的大小,将其较短边resize成800像素。采用同步的SGD在8个GPU上对模型进行训练。每个GPU上的mini-batch包含 2张图像,每张图像上512个ROI。我们的weight decay取0.0001和momentum取0.9。前60k的mini-batch学习率为0.02,后面的20k为0.002,训练时每幅图像2000 ROI,测试时1000个ROI。使用COCO数据集训练带有FPN的Fast R-CNN需要大约10小时。
5.2.1 Fast R-CNN(使用固定的候选框)
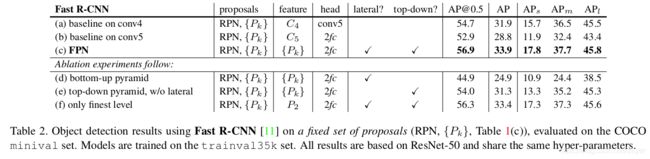
为了更好地研究FPN对基于区域的检测器的影响,我们使用一组固定的候选框(a fixed set of proposals)对Fast R-CNN进行消融实验。我们选择冻结RPN在FPN上计算出的候选框(表1©),因为它在检测器识别小物体上具有良好的性能。为了简单起见,我们不在Fast R-CNN和RPN之间共享特征,除非特别指定。
作为使用ResNet作为backbone的Faste R-CNN基线,遵循[16],我们采用输出大小为14x14的RoI pool,并将所有conv5层作为head网络的隐藏层。表2(a)中的AP为31.9。表2(b)是利用具有2个隐藏fc层的MLP head的基线,类似于我们架构中的head网络。它得到的AP为28.8,表明2-fc head网络与表2(a)中的基线相比没有任何优势。
表2©显示了我们在Fast R-CNN中使用FPN的结果。与表2(a)中的基线相比,我们的方法将AP提高了2.0个百分点,小目标AP提高了2.1个百分点。与同样采用2fc head的基线(表2(b))相比,我们的方法使AP提高了5.1个百分点。这些比较表明,对于基于区域的目标检测器,我们的特征金字塔优于单尺度特征。
表2(d)和(e)表明,移除自上而下的连接或移除横向连接会导致较差的结果,类似于我们在上述小节中观察到的现象。值得注意的是,删除自上而下的连接(表2(d))会显著降低准确性,这表明Fast R-CNN会受高分辨率特征图上上使用低层特征的负面影响。
在表2(f)中,我们在P2的分辨率最高尺度的特征图作为Fast R-CNN的输入。其结果(33.4 AP)略低于使用所有金字塔层(33.9 AP,表2©)。我们认为这是因为RoI pool是一种扭曲的操作,对区域的尺度不太敏感。尽管这个变体有很好的准确性,但它是基于RPN使用{Pk}创建的候选框,因此已经受益于金字塔表示。


5.2.2 Faster R-CNN
在上面我们使用了一组固定的候选框来研究检测其。但是,在Faster R-CNN系统中[29],RPN和Fast R-CNN必须使用相同的骨干网络(backbone),以便能够进行特征共享。表3显示了我们的方法与两个基线之间的比较,这两个基线中RPN和Fast R-CNN使用了相同的主干网络。表3(a)显示了我们对Faster R-CNN基线系统的复现,如[16]中所述。在有限设置下,我们的FPN(表3©)比这个性能非常好的基线AP高了2.3个百分点和[email protected]高了3.8个百分点。
注意,表3(a)和(b)基线比He等人在[16]中提供的基线表3(*)的性能高很多。我们发现以下不同实现造成了这种差距:(i)我们使用800像素大小的图像,而不是[11,16]中的600像素;(ii)我们训练中每个图像取512个ROI来加速收敛,相比之下[11,16]中只取64个ROI;(iii)我们使用5中尺度的anchor,而不是[16]中的4个(增加了322);(iv)在测试时,我们为每个图像取1000个候选框而不是[16]中的300。因此,与He等人在表3(*)中的ResNet-50 Faster R-CNN基线相比,我们的方法AP提高了7.6个百分点,并且[email protected]高出9.6个百分点。
特征共享。 在上面,为了简单起见,RPN和Fast R-CNN不共享特性值。在表5中,我们根据[29]中描述的4步训练方法来评估共享特征时的性能。与[29]相似,我们发现共享特征在一定程度上提高了准确性。特性共享也减少了测试时间。
执行时间。 通过特征共享,我们基于FPN的Faster R-CNN系统以ResNet-50为backbone时在单个NVIDIA M40 GPU上单张图片的推理时间为0.148秒,ResNet-101作为backbone推理时间为0.172秒。作为比较,表3(a)中的单尺度的ResNet-50基线运行时间为0.32秒。我们的方法通过在FPN中添加额外的层来引入少量的额外成本,但是head网络的参数更少。总的来说,我们的系统比基于ResNet的Faster R-CNN对应版本系统更快。我们相信我们的方法的高效性和简单性将有助于未来的研究和应用。
5.2.3 与COCO竞赛冠军比较
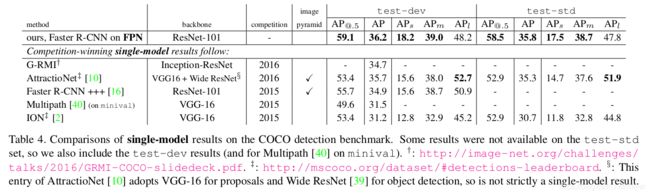
我们发现表5中的ResNet-101模型在默认学习率设置下没有得到充分的训练。因此,我们在训练Fast R-CNN时,每种学习速率的训练次数都增加到2倍。这将minival上的AP提高到35.6,而且还没有共享特性。这个模型是我们提交给COCO检测排行榜的模型,如表4所示。由于时间有限,我们还没有评估它的特性共享的版本,正如表5所示,结果应该会好一些。
表4将我们的方法与COCO竞赛冠军的单模型结果进行了比较,包括2016年的冠军G-RMI和2015年的冠军Faster R-CNN+++。在不使用任何辅助增强手段的情况下,我们的单模型已经超越了这些性能优越、设计精良的竞争对手。在测试开发集上,我们的方法与现有的最佳结果相比AP提高了0.5个百分点(36.2 vs.35.7)和[email protected]提高了3.4个点(59.1比55.7)。值得注意的是,我们的方法不依赖于图像金字塔,只使用单一尺度的图像,但对小尺度对象的AP指标仍然表现优秀。用以前的方法只能通过使用高分辨率图像来实现。
此外,我们的方法没有使用任何现在流行的提升精度方法,如迭代回归[9]、困难负样本挖掘[35]、上下文建模[16]、更强的数据增强[22]等。这些改进是对FPN的补充,应该会进一步提高精度。
最近,FPN在COCO竞赛的所有赛道上都获得了最好的结果,包括检测、实例分割和关键点估计。详见[14]。
6. 分割中的候选框
我们的方法是一种通用的金字塔表示法,可以用于除目标检测以外的其他应用。在本节中,我们在DeepMask/SharpMask框架[27,28基础上],使用fpn生成分割建议。
DeepMask/SharpMask使用裁剪过的图像进行训练,以预测实例分割和对象/非对象得分。在推理时,这些模型用卷积在图像中生成密集的建议框。为了实现在多个尺度上的分割,图像金字塔[27,28]是必不可少的。
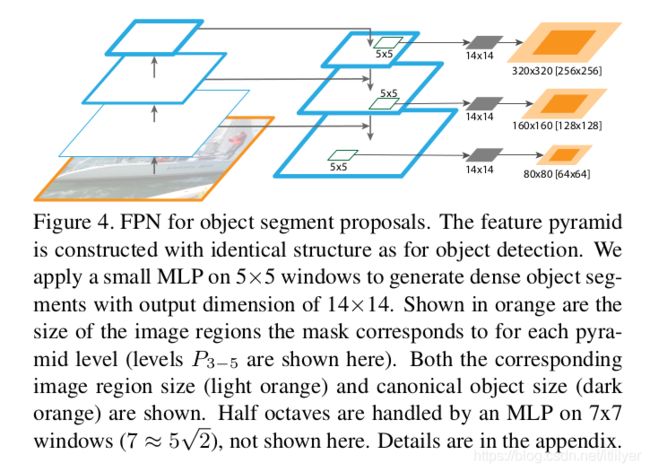
使用FPN来生成mask Proposal非常容易。练和推理我们都是使用全卷积来实现。我们像5.1章节中说的那样来构建特征金字塔,设d=128。在特征金字塔的每个层次上,我们用一个小的5×5的MLP,以全卷积的方式预测一个14×14个Mask和目标得分,见图4。此外,受[27,28]图像金字塔中每octave使用2个尺度的影响,我们使用了输入大小为7×7的第二个MLP来处理half-octave(个人理解:两个octave之间应该是4倍关系,这里直译两倍关系,所以称为half octave)。两个MLP的作用类似与anchor在RPN中起的作用。该体系结构经过端到端的训练;完整的实现细节在附录中给出。
6.1 分割建议的结果
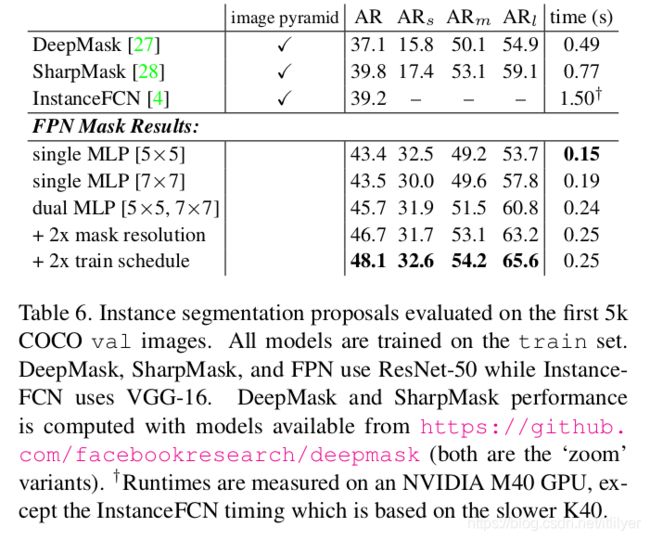
结果见表6。我们展示了分割精度指标AR和针对小、中、大对象的精度指标AR,都使用了1000个候选建议。我们的基线FPN模型使用一个5×5的MLP AR达到了43.4。换成稍大一点的7×7 MLP,精度基本不变。同时使用两中大小的MLP可以将精度提高到45.7 AR。将Mask输出初度从14×14增大到28×28又使AR值得到进一步的提高(较大的尺寸精度开始降低)。最后,将训练迭代次数加倍,AR提高到48.1。
我们还展示了与DeepMask[27]、Sharp Mask[28]和InstanceFCN[4] (是之前表现最好的生成mask Proposal的方法)的比较。我们比这些方法的精度高出8.3个百分点,特别是在小目标上,我们的精度几乎翻了一番。
现有的生成Mask Proposal方法[27,28,4]主要靠对图像金字塔进行密集采样(例如,在[27,28]中按2{−2:0.5:1}缩放),使得它们的计算开销很大。我们基于FPN的方法要快得多(我们的模型的运行速到可以达到6到7 FPS)。这些结果表明,我们的模型是一个通用的特征抽取器,可以代替图像金字塔来处理其他多尺度检测问题。
7. 总结(Conclusion)
我们提出了一个在ConvNets中构建特征金字塔的简洁框架。我们的方法比几个表现优异的方法和竞赛优胜者有显著的提升。从而为特征金字塔的研究和应用提供了一种实用的解决方案,而不需要计算图像金字塔。最后,我们的研究表明,尽管deep ConvNets具有强大的表示能力和对尺度变化的隐式鲁棒性,但是使用金字塔表示来显式地解决多尺度问题仍然是至关重要的。
A. 分割候选的具体实现
我们使用我们的特征金字塔网络来高效地生成目标分割建议,采用了一种在目标检测中流行的以图像为中心的训练策略[11,29]。我们的FPN Mask生成模型继承了DeepMask/SharpMask[27,28]的许多思想和动机。然而,与这些使用裁剪的图片进行训练然后使用对图像金字塔进行密集采样来完成推理的模型相比,我们使用全卷积的训练来实现Mask的预测。虽然这需要改变许多细节,但我们的实现思想仍然与DeepMask相似。具体地说,为了给每个滑动窗口的Mask实例定义一个标签,我们将这个窗口看作是从输入图像上裁剪得来的,这样我们就可以从DeepMask继承正/负样本的定义。接下来我们将给出更多细节,如图4所示。
我们按照5.1节中描述的架构,使用P2-6来构建特征金字塔,我们设d=128。我们的特征金字塔的每一层级都用于预测不同尺度的mask。与DeepMask一样,我们将其宽和高的最大值作为掩码的尺度。具有{32、64、128、256、512}像素的mask分别对应到{p2、p3、p4、p5、p6},并由5×5的MLP处理。由于DeepMask的金字塔中使用了half octave,因此我们使用尺寸稍微大一些的MLP(7×7(7≈5 2 \sqrt{2} 2))来处理我们模型中的half-octave(例如,使用7×7 MLP预测了P4得到的128 2 \sqrt{2} 2尺度的mask)。中间大小的尺度上映射到对数空间中大小最接近的尺度。
由于MLP要为每个金字塔层级(特别是half octave)预测多个尺度的对象,因此必须在标准对象大小周围填充一些额外的数据。我们额外填充25%的数据。这意味着对于5x5的MLP,{p2、p3、p4、p5、p6}上的mask输出对应{40、80、160、320、640}大小的图像区域(对于7x7 MLP,映射到 2 \sqrt{2} 2倍的对应大小)。
特征图中的每个空间位置用来预测不同位置的mask。具体地说,例如Pk尺度的特征图,特征图中的每个空间位置用于预测中心位于该位置2k像素范围内的mask(对应到特征图中±1个单元偏移)。如果没有对象中心落在该范围内,则该位置被视为负样本,并且与DeepMask一样,仅用于训练box分类和得分分支,而不用于训练mask分支。
我们用MLP来预测mask和box得分非常简单。我们使用一个512个输出的5x5的卷积核,后面跟了两个并行的全卷积层:一个用来预测14x14的mask(142个输出); 另一个是目标得分(1个输出)。该模型以全卷积的方式实现(使用1×1卷积代替完全连接的层)。处理half octave大小物体的7×7mlp与5×5mlp相同,只是输入区域更大。
在训练过程中,我们每个mini-batch中以1:3的正/负样本比例随机抽取2048个样本(每幅图像128个样本,一共16张图像)。mask 损失函数的权重比box得分损失函数的权重高10倍。该模型使用同步SGD(每个GPU 2张图片)在8个GPU上进行端到端的训练。我们从0.03的学习率开始,训练80k个小批次,在60k个小批次之后,将学习率除以10。在训练和测试期间,图像比例设置为800像素(我们不使用比例抖动)。在推理过程中,我们的完全卷积模型预测所有位置和尺度的分数,和1000个得分最高的位置的mask。我们不执行任何非极大值抑制或后处理。
参考文献
[1] E. H. Adelson, C. H. Anderson, J. R. Bergen, P. J. Burt, and J. M. Ogden. Pyramid methods in image processing. RCA engineer, 1984.
[2] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016.
[3] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos. A unified multi-scale deep convolutional neural network for fast object detection. In ECCV, 2016.
[4] J. Dai, K. He, Y. Li, S. Ren, and J. Sun. Instance-sensitive fully convolutional networks. In ECCV, 2016.
[5] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, 2005.
[6] P. Dollár, R. Appel, S. Belongie, and P. Perona. Fast feature pyramids for object detection. TPAMI, 2014.
[7] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part-based models. TPAMI, 2010.
[8] G. Ghiasi and C. C. Fowlkes. Laplacian pyramid reconstruction and refinement for semantic segmentation. In ECCV, 2016.
[9] S. Gidaris and N. Komodakis. Object detection via a multi-region & semantic segmentation-aware CNN model. In ICCV, 2015.
[10] S. Gidaris and N. Komodakis. Attend refine repeat: Active box proposal generation via in-out localization. In BMVC,
2016.
[11] R. Girshick. Fast R-CNN. In ICCV, 2015.
[12] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
[13] B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and fine-grained localization. In CVPR, 2015.
[14] K. He, G. Gkioxari, P. Dollár, and R. Girshick. Mask r-cnn. arXiv:1703.06870, 2017.
[15] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
[16] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
[17] S. Honari, J. Yosinski, P. Vincent, and C. Pal. Recombinator networks: Learning coarse-to-fine feature aggregation. In CVPR, 2016.
[18] T. Kong, A. Yao, Y. Chen, and F. Sun. Hypernet: Towards accurate region proposal generation and joint object detection. In CVPR, 2016.
[19] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
[20] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E.Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation, 1989.
[21] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft COCO: Common objects in context. In ECCV, 2014.
[22] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. Reed. SSD: Single shot multibox detector. In ECCV, 2016.
[23] W. Liu, A. Rabinovich, and A. C. Berg. ParseNet: Looking wider to see better. In ICLR workshop, 2016.
[24] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
[25] D. G. Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 2004.
[26] A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In ECCV, 2016.
[27] P. O. Pinheiro, R. Collobert, and P. Dollar. Learning to segment object candidates. In NIPS, 2015.
[28] P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Dollár. Learning to refine object segments. In ECCV, 2016.
[29] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
[30] S. Ren, K. He, R. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps. PAMI, 2016.
[31] O. Ronneberger, P. Fischer, and T. Brox. U-Net: Convolutional networks for biomedical image segmentation. In MICCAI, 2015.
[32] H. Rowley, S. Baluja, and T. Kanade. Human face detection in visual scenes. Technical Report CMU-CS-95-158R, Carnegie Mellon University, 1995.
[33] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015.
[34] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.
[35] A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online hard example mining. In CVPR, 2016.
[36] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
[37] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. IJCV, 2013.
[38] R. Vaillant, C. Monrocq, and Y. LeCun. Original approach for the localisation of objects in images. IEE Proc. on Vision, Image, and Signal Processing, 1994.
[39] S. Zagoruyko and N. Komodakis. Wide residual networks. In BMVC, 2016.
[40] S. Zagoruyko, A. Lerer, T.-Y. Lin, P. O. Pinheiro, S. Gross, S. Chintala, and P. Dollár. A multipath network for object detection. In BMVC, 2016.