【自监督论文阅读笔记】Instance Localization for Self-supervised Detection Pretraining
(2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR))
先前关于自监督学习的研究已经在 图像分类 方面取得了相当大的进展,但通常 在目标检测方面的 迁移性能下降。本文的目的是推进 专门用于目标检测的 自监督预训练模型。
基于分类和检测之间的内在差异,本文提出了一种新的自监督前置任务,称为 实例定位 instance localization 。图像实例 被粘贴在不同的位置 并缩放到背景图像上。前置任务是 在 给定 合成图像 以及 前景边界框 的情况下 预测实例类别。
将边界框集成到预训练中 可以 促进迁移学习的更好的 任务对齐和 架构对齐。此外,本文 在边界框上 提出了一种 增强方法,以进一步增强特征对齐。结果,本文的模型在 Imagenet 语义分类方面变得更弱,但在图像块定位方面更强,具有 整体更强 的目标检测预训练模型。
实验结果表明,本文的方法为 PASCAL VOC 和 MSCOCO 上的目标检测产生了最先进的迁移学习结果。
1. Introduction
在计算机视觉中训练深度网络的主要范式是 预训练 和 微调。通常,预训练被优化以 找到一个 单一的通用表示,然后将其 迁移到各种下游应用。例如,使用图像级标签 [26、25] 的监督预训练模型 和 通过对比学习 [22] 进行的自监督预训练模型都 可以很好地迁移到许多任务,例如图像分类、目标检测、语义分割 和 人体姿态估计。
本文质疑 迁移学习的这种 通用 generic and universal 表示的存在。最近,提高图像分类性能的自监督表示 [3 SwAV, 21BYOL ] 可能 无法将优势转化为目标检测。此外,发现 高级特征 在迁移到 检测 和 分割 中并 不是真正重要的。当前的自监督模型可能会 过度拟合分类任务,而对其他感兴趣的任务则变得不那么有效。
导致迁移学习中 任务不对准 task misalignment 的两个问题。
首先是 预训练的网络 需要 重新用于 目标网络架构以进行 微调。这通常涉及重要的 架构更改,例如 插入特征金字塔 [27] 或 使用具有 大膨胀的卷积核 [4]。
其次,对于典型的对比学习模型,预训练前置任务 在 实例判别 中 整体地考虑图像 [41],而 不需要对区域进行 显式空间建模。尽管它增强了分类的 可迁移性,但这种做法 与空间推理任务的 兼容性较差,例如目标检测。
在本文中,提出了一种 新的自监督前置任务,称为 实例定位 instance localization,专门用于目标检测的下游任务。与为单个图像实例 学习分类器的 实例鉴别 instance discrimination 类似,实例定位 还考虑了 边界框信息 以进行表示学习。
本文 通过 裁剪前景图像 并将它们 以不同的纵横比 和 比例 粘贴到 背景图像的不同位置 来创建本文的训练集。接下来是 自监督预训练,使用 边界框 提取RoI特征 并 使用实例标签执行对比学习。这样,不仅网络架构在迁移过程中保持一致性,而且预训练任务还包括 定位建模 localization modelling ,这对于目标检测至关重要。
将边界框引入预训练 可以鼓励 卷积特征 和 前景区域 之间的 显式对齐。因此,特征响应 对 图像域中的转变 变得敏感,有利于检测 [10]。可以通过 对边界框坐标进行增强 来 加强特征对齐。具体来说,空间抖动的边界框 是从一组候选框锚框 中随机选择的。
本文在 动量对比 MoCo 的框架内实施该方法。该网络将 合成的图像 和 边界框作为输入,并 提取 区域嵌入 进行对比学习。与考虑整体实例的基线方法相比,对最后一层特征的线性探测显示图像分类的性能降低,同时在回归边界框位置方面取得了改进。在实验上,本文研究了两个流行的检测骨干网络 ResNet50-C4 和 ResNet50-FPN。对于这两个骨干网络,本文的实例定位方法 大大提高了性能,超过了 PASCAL VOC [17] 和 MSCOCO [28] 上最先进的迁移学习结果。值得注意的是,本文的模型对于 小数据机制 下的目标检测更加有利。
2. Related Work:
Self-supervised Learning:
自监督学习的中心思想是 从视觉数据中创建 免费的监督标签,并使用 免费监督 获得可泛化和可转移的表示。
- 前置任务 的最简单形式之一是 使用 生成模型 重建输入图像。生成模型中的隐表示 被认为是 捕捉输入分布的 高级结构 和 语义流形manifolds 。
自动编码器 [39] 和玻尔兹曼机 [37] 在手写数字上显示出这种能力,但无法处理自然图像。后来,GANs [47] 的进步通过将隐表示的神经反应分解为面部属性、姿势和光照条件来实现对生成内容的操作。最近关于 BigBiGAN [14] 和 Image-GPT [6] 的工作表明,极大的生成模型可以提供非常有前途的视觉识别表示。然而,仍然存在的一个基本问题是学习生成图像像素如何与高级视觉理解相关联。
- 另一种前置任务是 保留部分数据,然后 从另一部分预测它。
Colorization [44] 保留颜色信息并尝试从灰度值中预测它。上下文预测 [12] 将空间内容拆分为 3×3 块网格。然后训练网络来预测patch之间的空间关系。制定前置任务的方式 强烈影响 从数据中学到的知识。当同一类别中的对象 共享相同颜色时,着色方法往往会起作用。上下文预测假设一个类别的对象 共享相同的空间配置。由于不同的前置任务提取不同方面的视觉知识,因此结合各自知识的 多任务方法 [13] 可以提高学习性能。
- 自监督学习的一种流行的前置任务是 对比学习,或者更具体地说是 实例判别[41]。训练数据集中的 每个实例 都被视为自己的一个类别。学习目标只是 将每个实例与其他实例进行分类。
对比学习的关键组成部分是用于 诱导不变性 的 数据增强。理想的数据增强应该反映 类内变化,常用的增强包括 裁剪、缩放、颜色抖动和模糊。
最近对比学习的研究集中在 开发更好的增强[3 SwAV]、设计投影头结构[21 BYOL],甚至 减轻对负样本的需求[21]。虽然领先的对比学习方法 BYOL 和 SwAV 使用线性读取分类器将 ImageNet 性能提升到了令人印象深刻的 74%,但它们在目标检测中的传输性能实际上低于 MoCo [22]。
这表明这些自监督方法过度拟合到单个下游分类任务,牺牲了对其他任务的泛化能力。
本文提出了一种用于自监督预训练的新前置任务,重点是 迁移到目标检测。在实例判别的基础上,本文 在预训练阶段引入了边界框的使用。为了改进定位,本文的方法学习了一种表示,其中 边界框 与其对应的前景特征之间 存在对齐。CPC [33] 和上下文预测 [12] 基于一个图像内 块的内容对 空间排列 进行推理。相比之下,本文的前置任务 考虑了合成在一起的两个不同图像之间的 空间关系。
图像和视频上的自监督学习还有一系列其他前置任务,例如图像修复 [35]、旋转预测 [19]、拼图游戏 [32] 和运动分割 [34],以及时间顺序 [ 31]、时间速度 [2] 和视频上的同步 [1]。每个前置任务的详细调查和描述超出了本文的范围。
用图像合成学习:
通过将前景目标 复制到背景上 来创建合成图像是一种流行的数据增强技术。本文的工作还可以合成 图像合成,但不需要目标掩码 或 干净的轮廓。
使用未标记数据进行 自训练:
除了迁移学习,自训练是在标记数据有限时 利用未标记数据的一个有前途的方向。通过对少数标记样本使用监督学习来引导模型,以在未标记样本上生成伪标签。该模型通过 对标签和伪标签的监督学习 进一步优化。然而,当 标记集稀缺 时,自训练可能会变得脆弱。正如 SimCLR-v2 [8] 中所探讨的,迁移学习 和 自训练可以集成。
3. Pretext Task – Instance Localization
图像分类需要 平移translation 和 尺度 不变性 invariance,相比之下,目标检测 需要 平移translation 和 尺度 等变性 equivariance。用于目标检测的特征表示 应该能够保留和反映 有关目标大小和位置的信息。这两个任务之间的内在差异 需要对每个任务进行专门的建模。最近在对比学习方面的工作侧重于设计图像分类技术。通过 学习图像的两个随机视图之间的一致性 来强制执行 平移和尺度不变性。结果,实例判别的 前置任务 过拟合 整体的分类,无法促进空间推理。
(PS:CNN中的equivariant vs. invariant - 知乎
等变性 equivariant:
通俗解释:对于一个函数,如果你对其输入施加的变换也会同样反应在输出上,那么这个函数就对该变换具有等变性。更严谨些:对于一个函数/特征f以及一个变换g, 如果我们有:f(g(x))=g(f(x))则称f对变换g有等变性。
举一个例子,假设我们的变换g是将图像向右平移一段距离,我们的函数f是检测一个人脸的位置(比如说输出坐标),f(g(x))就是先将图片像右移,接着我们在新图较之原图偏右的位置检测到人脸;g(f(x))则是我们先检测到人脸, 然后再将人脸往右移一点。这二者的输出是一样的,与我们施加变换的顺序无关。
不变性 invraiant:
通俗解释:对于一个函数,如果对其输入施加的某种操作丝毫不会影响到输出,那么这个函数就对该变换具有不变性。更严谨些:假设我们的输入为x,函数为f, 此时我们先对输入做变换g:g(x)=x′,此时若有:则称f对变换g具有不变性。
举个例子我们的函数是检测图像中是否有红色, 此时如果我们的变换是旋转/平移, 那么这些变换都不会对函数结果有任何影响, 就可以说该函数对该变换具有不变性。
)
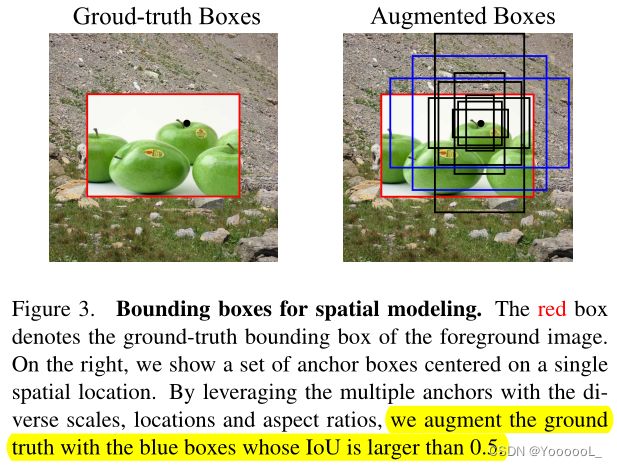
本文提出了一种新的前置任务,称为 实例定位 (InsLoc),作为实例判别的扩展。如图 3 所示,本文通过 将 前景实例 叠加到背景上 来合成 图像合成。目标是 使用边界框信息 区分前景和背景。为了完成这项任务,必须 先定位 前景实例,然后 提取前景特征。
将覆盖在边界框 b 上的前景图像 I 得到的合成图像 表示为 I' 。任务 T 是为 I 预测实例标签 y,
![]()

4. Learning Approach
本文的目标是学习一种 不仅在语义上强大,而且在 平移和尺度等变化 的表示。本文在4.1 节中 首先描述了 将 边界框表示 引入到 对比学习框架中的方法。 在第 4.2 节中,边界框上的数据增强 被认为是提高定位能力的有效方法。最终在第 4.3 节中 给出了 本文在两个流行的检测主干 R50-C4 和 R50-FPN 上的方法的架构细节。
4.1. Instance Discrimination with Bounding Boxes
Instance Discrimination:
对比学习采用两个随机“视图”作为query Iq 和 key Ik+ 图像,它们来自同一实例的随机增强。对应的特征 vq 和 vk+ 首先由骨干网络 f(例如 vq = f(Iq))提取,然后通过 head网络 φ 投影到单位球体。对比损失,即 InfoNCE [33],计算为:

其中τ和N分别是温度和负样本数。
Spatial Modeling with Bounding Boxes:
本文的目标是 强制输入区域 和 卷积特征之间的 空间对齐,以及 判别实例的对比学习。为此,给定图像 I,本文首先对随机背景图像 B 进行采样,将其简单地作为训练集中的任何其他图像。然后本文定义 合成操作C,它将图像 I 的 随机裁剪 复制并粘贴到 背景 B 上的随机位置和比例。操作返回合成图像I' 和 边界框参数b。
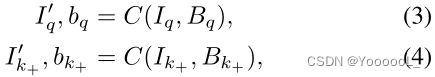
其中 Iq 和 Ik+ 是来自同一图像实例的裁剪,Bq 和 Bk+ 是它们各自的背景图像2。在实践中,前景图像的大小调整为 随机纵横比 和 128 到 256 像素之间的随机比例。给定 边界框参数 b,使用 RoIAlign 在卷积特征图上 提取前景特征,
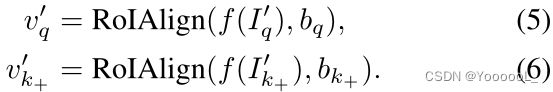
使用 query 和 key特征,对比学习类似于等式 2。图 3 说明了本文的框架。本文用 IoU 大于 0.5 的蓝色框来 增强真值。
使 检测复杂化 的一个问题是 图像区域 与 其空间对应的深层特征 之间的差异。由于池化的深层特征的感受野 通常在图像中远远超出池化区域,因此 池化特征 受到其附近以外的图像内容的影响。因此,对于 覆盖前景的边界框,其特征会受到周围背景的影响,使其更难定位。
本文的 边界框实例判别 以 数据驱动 的方式解决了这个问题。通过鼓励 相同实例 但具有不同背景的 池化前景特征之间的 相似性,学习 有效感受野 以匹配边界框的空间范围。在 卷积特征与其有效感受野 之间建立这种明确的对应关系 有助于使用学习的表示进行定位。
4.2. Bounding-Box Augmentation
图像增强在表示的对比学习中起着关键作用。本文假设 类似的增强策略 也可能对边界框有效。真值位置 周围的抖动框 可能包括背景区域。因此,可以进一步 引导表示 在空间上忽略背景 并获得定位能力。
Augmentations as predefined anchors:
本文不是直接在空间上移动边界框,而是 利用 区域生成网络(RPN)中的锚框 来涵盖 增强框的多样性。锚框是一组 预定义的 候选边界框,具有不同的比例、位置和纵横比。给定一个真值框,本文针对所有anchors计算它的IoU。从被滤出的 具有高重叠(大于 0.5)的锚框中 随机选择一个作为增强框。由于基于锚框的设计,本文能够获得 具有 动态 IoU 范围 的多样的候选框集合。本文在 query编码器的 RoIAlign 模块上 应用 边界框增强,而 动量编码器 始终使用真值 进行池化。
4.3. Architectural Alignment:
导致迁移学习中的任务不对齐 的一个关键问题是重要的 架构调整。预训练的网络需要通过 附加的区域级操作 和 head网络 重新用于检测网络。本文 引入边界框表示 可以 最大限度地减少预训练和微调之间的 架构差异。具体来说,预训练中的 RoIAlign 操作引入了 区域级表示,它紧密地 模仿了微调中的检测行为。本文提供了预训练期间检测架构 R50-C4 和 R50-FPN 的详细信息。
(ROIPooling和ROIAlign的区别(通俗易懂) - 小丑_jk - 博客园)
R50-C4:
在标准的 ResNet50 架构上,本文在第 4 个残差块的输出上 插入 RoI 操作。然后使用 边界框坐标 来提取区域特征。整个第 5 个残差块被视为用于区域分类的头网络。
R50-FPN:
R50-FPN 使用 横向连接 在 ResNet50 之上形成 4 层的特征层次结构。每个层级的特征 都负责 以相应的比例 对 对象 进行建模。本文在 FPN 层次结构的所有级别上插入 RoI 操作。实例定位任务 在所有 4 个特征级别上同时执行 [43],其中每个级别 维护一个单独的负样本内存队列,以避免跨级别作弊。这样,不仅可以预训练 ResNet50 网络,还可以预训练 FPN 层。
5. Experimental Results
本文在主流目标检测基准上 评估本文的迁移学习模型的泛化能力:PASCAL VOC [17] 和 MSCOCO [28]。 5.1 节介绍了与最先进的比较的主要实验结果。关于 语义分类 和 定位之间 权衡的消融研究和讨论在第 5.2 节中进行。在 5.3 节中,展示了一个在 MSCOCO 的迷你版上的实验,以证明本文的模型在少量标记数据下的快速泛化能力。
Dataset:
具有 130 万张图像的 ImageNet 数据集 [11] 用于预训练,而 PASCAL VOC [17] 和 MSCOCO [28] 用于迁移学习。 PASCAL VOC0712 包含约 16.5K 图像,包含 20 个对象类别中的边界框注释。 MSCOCO 包含大约 118K 图像,包含 80 个对象类别中的边界框和实例分割注释。
Pretraining:
本文主要遵循 MoCo-v2 [9] 官方实现的超参数。在 8 个 GPU 上使用同步 SGD 优化模型,权重衰减为 0.0001,动量为 0.9,每个 GPU 上的批量大小为 32。优化需要 200-400 个 epoch,初始学习率为 0.03,余弦学习率计划 [30]。一个两层的 MLP 头用于对比学习,在 Eq 2 中温度参数设置为 0.2。本文还维护了一个 65536 个负样本的内存队列。动量系数设置为 0.999 用于更新密钥编码器。
Data augmentations:
在预训练期间,前景内容的图像增强遵循 MoCo-v2 [9]。具体来说,本文应用了随机调整大小的裁剪、颜色抖动、灰度、高斯模糊和水平翻转。更强大的增强可能会进一步提高迁移性能 [38, 7],但不在本文工作的重点。
Fine-tuning:
主干网络从预训练任务迁移到下游任务。遵循MoCov2 [9] ,同步批标准化 用于所有层,包括新初始化的批标准化层。使用detectron2 [40]实现和微调检测器。
5.1. Main Results
本文提供了目标检测的实验结果,并将性能与最先进的方法进行了比较。 SimCLR [7] 和 BYOL [21] 的预训练权重是从第三方(mmselfsup)实现中借用的,而 MoCo [22]、InfoMin [38] 和 SwA V [3] 的预训练权重是从他们的官方实现中收集的。
本文的方法 还优于所有以前的方法,而 无需使用复杂且更强大的数据增强,例如 RandAugment 或 Multi-crop。本文的预训练模型在这个基准上获得了最先进的结果。
经过 400 个 epoch 的预训练,InsLoc 达到了新的状态性能,超越了所有先前的可能具有 更强的图像增强的自监督模型。值得注意的是,当模型的预训练时间较长时,InfoMin 会降低迁移性能。 BYOL 和 SwAV 对 R50-FPN 主干具有竞争力,但对 R50C4 主干相对较弱。本文的模型 在各个方面都始终如一地强大。
5.2. Ablation Study
改进是否是由于更强的语义特征:
最近的方法倾向于将线性目标分类作为学习表示的核心评估指标,基于这样一种假设,即具有更强语义的表示总是能很好地转化为其他下游任务。为了进一步研究和理解所提出的目标检测方法的改进,本文设计了一个新的读出任务 来评估 预训练模型的定位能力。
具体来说,给定一个输入图像,本文将整个图像分成 M 个块。任务是 使用 线性分类器 根据 patch 的区域特征 预测每个 patch 的位置。图 4 说明了 M 等于 9 的任务。

虽然早期的上下文预测工作 [12] 预测两个patch之间的相对空间位置,但本文的评估任务改为考虑patch相对于 完整图像的空间排列。对于每个patch,本文通过将其前馈通过主干网络、提取 RoI 特征 并 将它们传递给头网络 来提取其向量表示。附加一个线性分类器 来 预测patch索引。本文认为这项任务类似于检测流程,并反映了预训练模型的定位能力。
表 3a 显示了语义和定位精度的比较。 Instance Localization 为线性定位任务引入了 2.3% 的明显改进,而在线性分类中的性能低于 MoCo-v2 6.0%。这表明 目标检测的整体改进 主要是 由更好的空间定位 带来的,而不是更强的语义。这些结果也符合最近的一项发现 [46],即自监督预训练不会迁移高级语义用于目标检测,而是低级和中级的语义特征的迁移更重要。本文在表 3a 中进一步包括了 BYOL 和 SwAV 的定位评估条目。它们较差的定位能力限制了转移到目标检测的有效性。
Effectiveness of instance localization pretext task:
表 3b 展示了多个组件的消融研究:架构对齐、实例定位任务 和 提出的边界框增强。本文首先集成 RoiAlign 操作以减轻基线模型的架构变化。具体来说,从网络中汇集和提取整体表示,然后进行对比学习。此外,在 FPN 层次结构(第 4.3 节)上应用了多个对比损失,导致整体 +0.4 APbb 改进。这些改进证明了为检测迁移 调整架构的有效性。然后,通过复制粘贴操作 和 边界框表示 对合成图像应用实例定位任务,性能达到 41.1 APbb,比 MoCov2 明显领先 +1.3。最后,当对边界框应用空间抖动时,结果进一步提升到 41.4 APbb。这些结果有力地验证了新前置任务的有效性,即 实例定位 和 相应的增强。
Effects of fine-tuning schedules:
通过增加迭代次数 来 微调下游目标检测任务 可以提高目标检测性能。本文研究了微调计划如何影响预训练模型的相对改进。在表 4 中,研究了在 1x 和 2x 微调计划下目标检测转移到 COCO。使用 R50-C4,使用 1x schedule可提高 0.6 APbb,使用 2x schedule提高了 0.7 APbb。 R50-FPN 也获得了类似的观察结果。这些结果表明,更长的微调可能不会显著削弱 相对的改进,证明了预训练模型在迁移学习中的实用性。
Effects of longer pretraining:
ImageNet 线性分类准确性大大受益于更长的预训练。例如,通过将预训练时期的数量从 200 增加到 800,MoCo-v2 从 67.5% 提高到 71.1%。但是,对于目标检测,更长的预训练可能是有害的,如 InfoMin [38] 所示。在表 4 中,报告了在 COCO 上使用预训练模型进行 400 次优化的传输性能。与预训练了 200 个 epoch 的模型相比,更长的预训练获得了一致的改进 和 新的最先进的性能。使用 800 个 epoch 进行更长时间的预训练在计算上是昂贵的,本文将其留给未来的工作。
5.3. Evaluation on Mini COCO
由于其数据集的规模,迁移学习到 COCO 的意义可能有限。以前的文献 [5] 还表明,在 COCO 上从头开始训练,学习时间很长,可以提供强大的基线。为了证明本文的预训练模型在少量标记数据下的泛化能力,在 COCO 数据集的迷你版本上进行了实验。
表 5 总结了结果。本文相对于 MoCo-v2 获得了 3.3 APbb 和 2.4 APmk 的大幅改进,相对于监督方法获得了 3.1 APbb 和 2.3 APmk 的大幅改进,展示了卓越的泛化和迁移能力。请注意,Mini COCO 的增益远大于原始 COCO 的增益。这样的结果清楚地表明,本文的预训练模型 对于迁移学习来说 数据效率更高。
6. Conclusion
本文提出了一个 实例定位 的新前置任务,并介绍了 边界框 在自监督表示学习中的使用。预训练模型在 整体图像分类 方面表现较弱,但在 图像块定位 方面表现更强。当迁移到目标检测时,它相对于基线 MoCo 取得了显著的改进,并在 VOC 和 COCO 上获得了最先进的结果。当标记数据特别小时,本文的方法可以获得更大的收益。实验结果表明,可以通过 改进 任务对齐 来 增强目标检测的迁移性能。