李宏毅学习笔记15.Transformer
文章目录
- Sequence to Sequence
- Self-Attention
-
- 生成过程
- 并行过程
- 小结
- Multi-head Self-attention(2 heads as example)
- Positional Encoding
- Seq2seq with Attention
- 总结
-
- 应用
在线LaTeX公式编辑器
看封面就知道,这节课是讲transformer,它的主要应用是BERT,BERT就是unsupervisored transformer。怎么感觉这节应该放在BERT那节的前面。

那transformer是什么?
transformer实际上是Seq2seq model with “Self-attention”
Sequence to Sequence
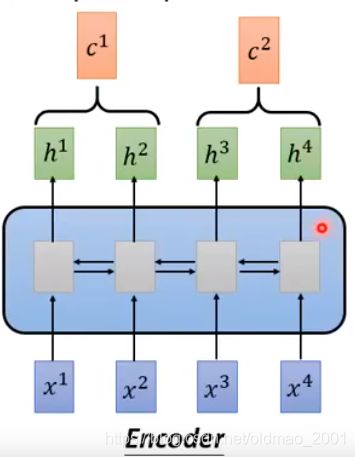
下面是之前讲RNN的时候讲过的Seq2seq 模型,这个模型有个问题就是输出和输入很难parallel(并行),什么意思?就是要输出 b 4 b^4 b4要把前面的 a 1 ∼ a 4 a^1\sim a^4 a1∼a4都看过才可以。

因此,提出了用CNN来替代RNN。

三角形的是filter,小圆圈是卷积的结果。经过stride,得到一排结果
换个filter

若干个filter后的结果可以堆叠起来:

可能你会觉得这样没有办法看到整个句子的关系,没关系,再上面还可以加卷积层:
这个时候,蓝色的filter就可以看到整个的句子。而且卷积计算可以并行。
但是低层次的filter仍然是没有办法看到整个句子的信息,因此又可以并行又可以看到所有句子信息的模型提出来了:
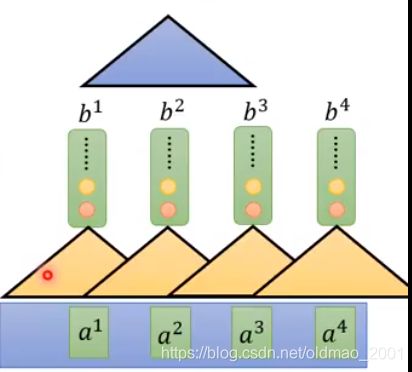
Self-Attention
Self-Attention就是替代之前的RNN layer,它的输入是Sequence,输出也是Sequence。

这里 b i b^i bi是基于整个Sequence来生成的。
b 1 ∼ b 4 b^1\sim b^4 b1∼b4可以并行计算。
论文笔记:

生成过程
第一步,先是输入Sequence x x x,然后先经过embedding得到a。

然后进入attention layer
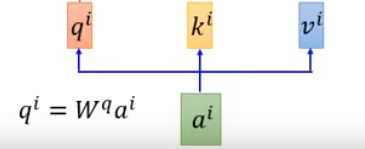
进去先分别乘上三个transformation(matrix):q、k、v


第二步,拿每个 query q 去对每个key k做attention(attention操作有很多种算法,通常是输入两个向量,输出两个向量的相似度。)

由于q和k要做点乘,所以他们两个的维度一样。他们两个维度越大,点乘后的variance越大,所以要除以一个 d \sqrt{d} d

第三步: α \alpha α经过softmax得到 α ^ \hat \alpha α^,其实这样就会使得 α ^ \hat \alpha α^之和为1
α ^ 1 , i = e x p ( α 1 , i ) ∑ j e x p ( α 1 , i ) \hat \alpha_{1,i}=\cfrac{exp(\alpha_{1,i})}{\sum_jexp(\alpha_{1,i})} α^1,i=∑jexp(α1,i)exp(α1,i)
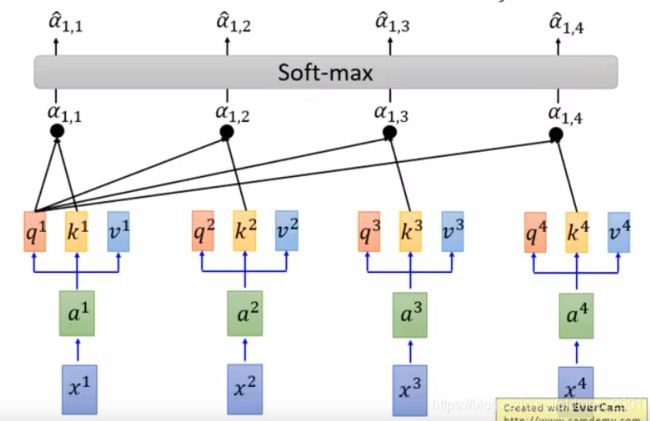
最后第四步,用 α ^ \hat \alpha α^分别乘以 v i v^i vi然后求和得到b
b 1 = ∑ i α 1 , i v i b^1=\sum_i\alpha_{1,i}v^i b1=∑iα1,ivi

b 1 b^1 b1就是第一个结果,在计算 b 1 b^1 b1的过程用到了整个序列的信息。当然如果要只考虑附近单词的信息,可以把其他的 α \alpha α设置为0即可。
整个self attention的思想就是:天涯若比邻!无论单词距离多远,都可以有attention的关系。
同样的,我们可以同时计算 b 2 b^2 b2

并行过程
第一步:把q、k、v、a分别并起来,变成QKVI

第二步:把k并起来然后转置,计算 α \alpha α

依次类推:

第三步,把A中每一列做softmax得到 A ^ \hat A A^
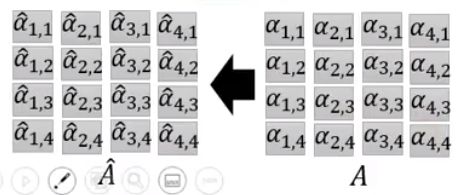
第四步,把 A ^ \hat A A^每一列分别和V点乘得到O

小结
整个过程就是输入序列I,输出序列O


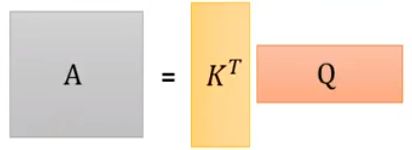

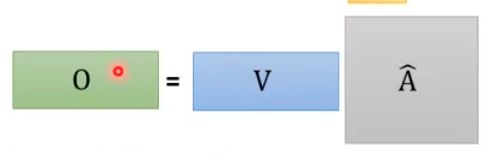
可以看到从输入到输出是一堆矩阵乘法。GPU可以很容易加速。
Multi-head Self-attention(2 heads as example)
一个头:
现在两个头,所以qkv分成两份:

其中:

现在开始做attention操作:
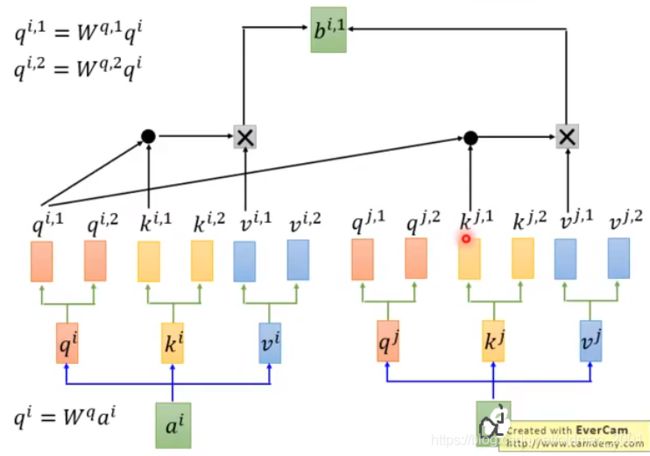
上的attention操作只针对q1之和k1,最后得 b i , 1 b^{i,1} bi,1,然后针对q2之和k2计算 b i , 2 b^{i,2} bi,2

然后把 b i , 1 b^{i,1} bi,1和 b i , 2 b^{i,2} bi,2concat起来得到 b i b^i bi
如果对 b i b^i bi的维度不满意,可以降维:

在原论文中的描述中,不同的head可以关注不同点,例如有的head关注比较近的单词,有的关注比较远的单词。
Positional Encoding
从self attention的机制来看,它的思想是天涯若比邻,也就是说这个机制是不在乎单词之间的距离的,距离远和近都可以获得的attention。这个其实相当于没有单词的顺序信息,不好(例如我们不希望:你好=好你),因此加入位置信息是很必要的。
Original paper:each position has a unique positional vector e i e^i ei(not learned from data)
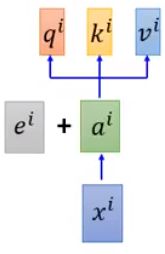
注意这里是相加,不是concat,为什么?
因此这里相加相当于对原始的x和一个独热编码做了一个concat操作:
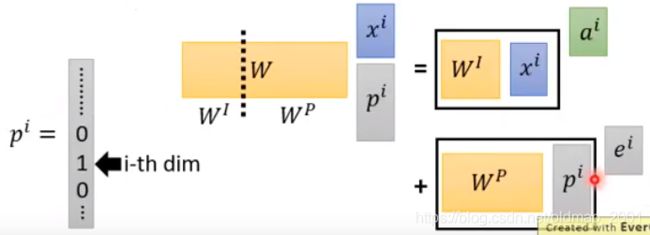
如果把 W P W^P WP可视化就是:

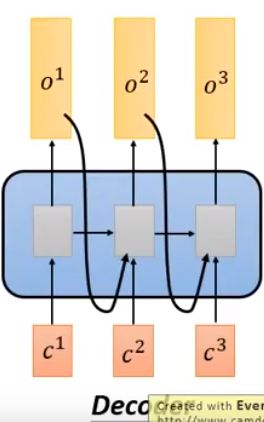
Seq2seq with Attention
中间替换为自注意力模型


https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
最后是总结:
总结
这里讲了一点Layer Norm,一般是和RNN一起使用,和Batch Norm不一样。

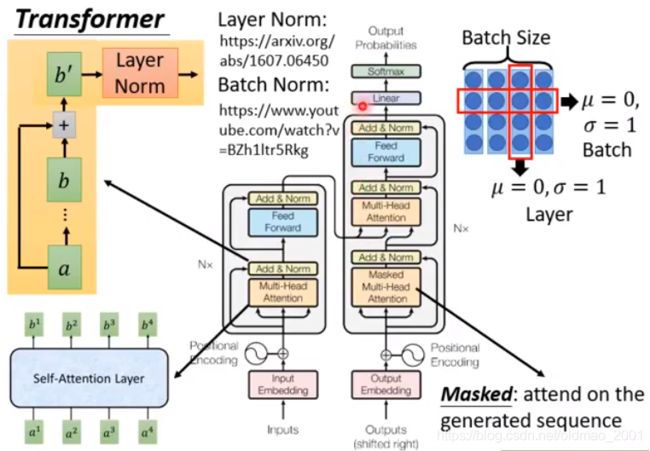
应用

与之前不一样的是,摘要变长了,可以几万字摘要出几千字。这个事情在以前的模型做不了的。
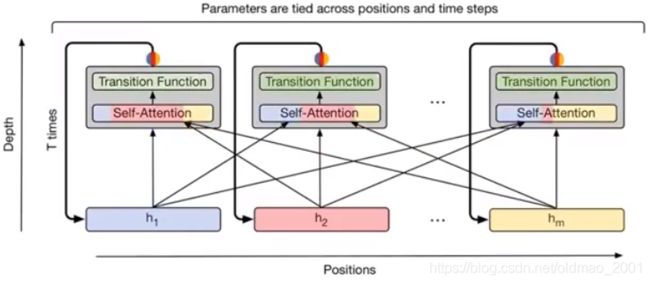
Universal Transformer:还可以把注意力模型堆叠,变深。
Self-Attention GAN:图像上可以应用注意力机制找出像素关注的点。
