pytorch语义分割中CrossEntropyLoss()损失函数的理解与分析
最近在尝试使用pytorch深度学习框架实现语义分割任务,在进行loss计算时,总是遇到各种问题,针对CrossEntropyLoss()损失函数的理解与分析记录如下:
1.数据准备
为了便于理解,假设输入图像分辨率为2x2的RGB格式图像,网络模型需要分割的类别为2类,比如行人和背景。训练的时候,网络输入图像的shape为(1,3,2,2)。
网络的输出预测图像的shape为(1,2,2,2),其中,1表示batchsize为1,即每次训练只输入一张图像;第一个2表示分割的类别数;最后两个2表示网络输出的尺寸为2x2,即高和宽都为2。
定义网络输出的预测结果如下:
import torch.nn.functional as F
import torch
from torch import nn
pred_output = torch.tensor([[[[0.12,0.36],[0.22,0.66]],[[0.13,0.34],[0.52,-0.96]]]])
打印输出如下:
print("pred_output :",pred_output )
pred_output : tensor([[[[ 0.1200, 0.3600],
[ 0.2200, 0.6600]],
[[ 0.1300, 0.3400],
[ 0.5200, -0.9600]]]])直观形象的表示如下图:
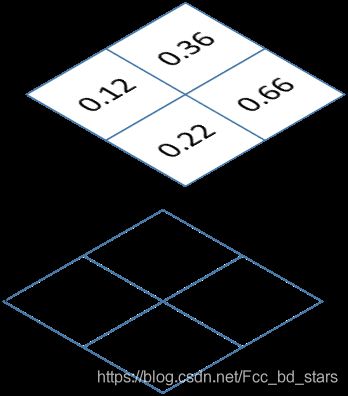
直观理解就是网络输出的预测图像为2层,对应要分割的两种类别。
定义图像标签:0像素表示背景,1像素表示行人。标签的shape为(1,2,2)
target = torch.tensor([[[1,0],[0,1]]])
# print("target:",target)
# target: tensor([[[1, 0],
# [0, 1]]])直观的表示如下图: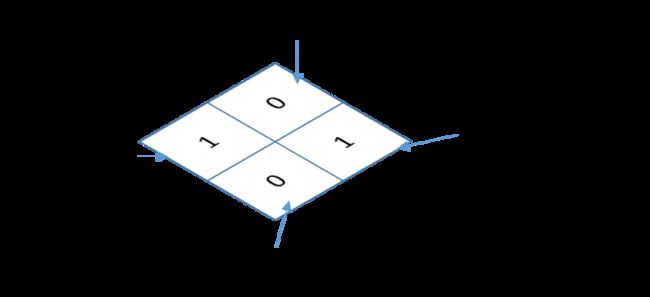
通常标签是png格式图像,直观的理解就是标签只有1层,其中第一个像素为1 表示该像素点代表行人,第二个为0表示该像素点代表背景,其余的同理。
好了,以上操作就是把损失函数的输入数据准备好。接下来开始讨论CrossEntropyLoss损失函数
2.CrossEntropyLoss损失函数分析
看pytorch官网对CrossEntropyLoss的介绍,感觉只能用于图像类别的分类,不能用来做语义分割。其实,语义分割本质是对像素的分类,因此这个损失函数是能用于语义分割。
看源码可以知道 CrossEntropyLoss的计算过程等价于 :softmax计算+log计算+nll_loss计算,接下来一个一个分析。我们先分别计算,最后和直接使用CrossEntropyLoss做对比。
(1)softmax函数
这个函数,简单的来说就是用来计算概率的。这个函数的输入是网络的输出预测图像,即上面定义的pred_output。输出是在dim=1上计算概率。softmax的计算公式如下:
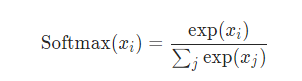
这里说一下dim=1,pred_output的shape是(1,2,2,2),从左往右看,dim依次是0,1,2,3,也就是说类别数所在的维度表示dim=1.应在这个维度上计算概率。先看计算结果:输出结果的shape同样是(1,2,2,2)。
temp1 = F.softmax(pred_output,dim=1)
print("temp1:",temp1)
输出结果:
temp1: tensor([[[[0.4975, 0.5050],
[0.4256, 0.8348]],
[[0.5025, 0.4950],
[0.5744, 0.1652]]]])直观的理解如下图所示:
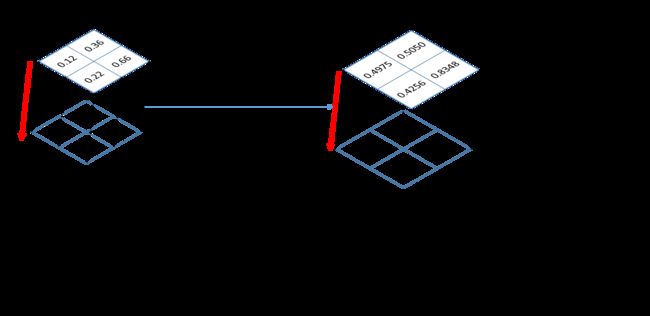
(2)log函数
这个函数比较简单,好理解,就是对输入矩阵的每个元素求对数,默认底数为e,也就是ln函数。(接上面的代码)
temp3 = torch.log(temp1)
print("temp3:",temp3)打印输出结果:
temp3: tensor([[[[-0.6982, -0.6832],
[-0.8544, -0.1806]],
[[-0.6882, -0.7032],
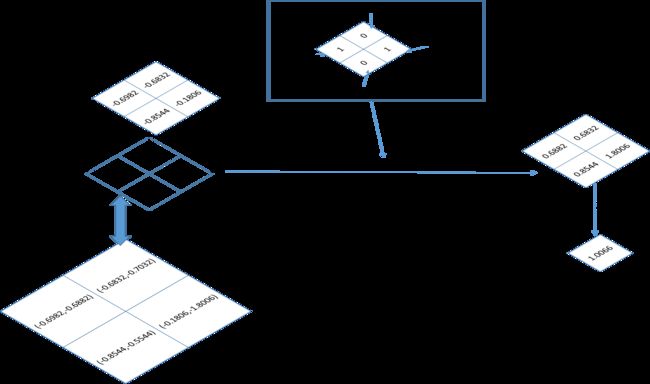
[-0.5544, -1.8006]]]])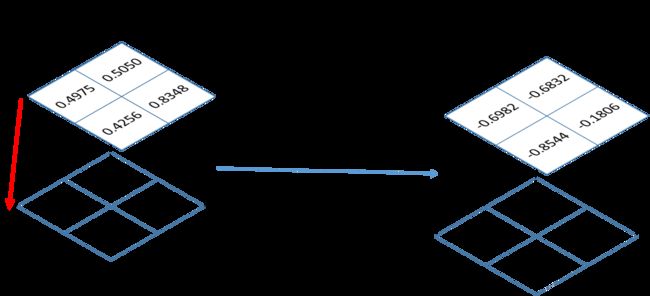
(3)nll_loss函数
这个函数目的就是把标签图像的元素值,作为索引值,在temp3中选择相应的值,并求平均。(接上面的代码)
target = target.long()
loss1 = F.nll_loss(temp3,target)
print('loss1: ', loss1)打印输出结果:
loss1: tensor(1.0066)还是用图来直观的表达:
(4)CrossEntropyLoss函数直接计算
直接用CrossEntropyLoss损失函数计算损失值,
loss2 = nn.CrossEntropyLoss()
result2 = loss2(pred_output, target)
print('result2: ', result2)打印结果:
result2: tensor(1.0066)
对比结果可以发现 通过 对CrossEntropyLoss函数分解并分步计算的结果,与直接使用CrossEntropyLoss函数计算的结果一致。