Progressive Learning for Person Re-Identification with One Example[reading notes]
—————————————————————————————
博文发表于夏木青 | JoselynZhao,欢迎访问博文原文。
这里是论文PDF链接。
—————————————————————————————
Progressive Learning for Person Re-Identification with One Example
- 导言
- Abstract
-
- 研究领域
- 其中关于索引标记数据(index- labeled data)
- 引入索引标记数据的好处
- I. INTRODUCTION
-
- 与EUG相同的策略
-
- 渐进采样策略
- 基于距离的采样标准
- 与EUG不同的点
- 索引标记数据
- 本文贡献
- II. RELATED WORKS
- III. THE PROGRESSIVE MODEL
-
- A. Framework Overview
-
- Training
- Label estimation
- Next Training
- B. Preliminaries
- C. The Joint Learning Method
-
- Exclusive Loss
- The Joint objective Function.
- D. The Effective Sampling Criterion
-
- 有效的采样标准
- 标签估计方法
- E. The overall iteration strategy
- IV. EXPERIMENTAL ANALYSIS
导言
这篇文章是Yu Wu在继Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning(EUG)之后发表的一篇文章,文中工作基于EUG进行,对其进行进行了优化。建议阅读本文之前先阅读EUG对工作内容有初步了解,本博文也针对Progressive Learning这篇论文相对了EUG的不同点来进行讲解。
Abstract
研究领域
研究领域为行人重识别。
相对于EUG中的两种训练数据:标记数据、伪标记数据。本文提出了三种训练数据:
- 标记数据
- 伪标记数据
- 索引标记数据
其中关于索引标记数据(index- labeled data)
We select a few candidates with most reliable pseudo labels from unlabeled examples as the pseudo-labeled data, and keep the rest as index-labeled data by assigning them with the data indexes.
我们从未标记的示例中选择一些具有最可靠伪标签的候选者作为伪标记数据,并通过为它们分配数据索引将其余部分保留为索引标记数据。
引入索引标记数据的好处
在EUG中每次训练都只选择了置信度较高的部分伪标签,而大量的置信度不高的数据并没被利用其来。本文引入索引标记数据就是为了将这部分数据也很好的利用起来训练更好的模型。
I. INTRODUCTION
与EUG相同的策略
本文沿用了EUG中提出的取得了较大进行的策略:
- 动态采样策略——渐进采样策略
- 有效采样标准——基于距离的采样标准
渐进采样策略
以更保守的方式(以较慢的速度)放大采样的带伪标记数据子集
该模型可以获得更好的性能
基于距离的采样标准
以特征空间中的欧几里得距离作为可靠性的度量,通过特征空间中最近的标记邻居,给每个未标记数据分配标签。
标签估计的置信度定义为未标记数据与其最近标记邻居之间的距离。
候选者选择,则根据他们的标签估计置信度选择一些最可靠的伪标记数据。
与EUG不同的点
Different from [8], in this paper, we consider the one-shot image-based re-ID setting, where only one image instead of a tracklet is labeled for each identity.
We therefore propose to leverage the unlabeled data in a self-supervised manner to help to learn a robust model. The previous pseudo labelling in [8] utilizes part of the unlabelled data, but overlooks a large number of unlabelled data (unselected data) whose pseudo labels are not reliable.
We propose to use the remaining unselected data (which is unreliable during pseudo labeling) on top of the pseudo-labeled data. We label these data by their indexes and design the exclusive loss to optimize the CNN model by these index-labeled data.
总结如下:
- 对于每个身份,训练数据只有一个图形,而不是一个踪迹。
- 鉴于初始模型不可靠,提出以自我监督的方式利用未标记的数据来帮助学习稳健的模型。
- 由于初始迭代时的大量数据,这些人类图像也保留了数据分布信息。建议在伪标记数据之上使用剩余的未选择数据。我们通过其索引标记这些数据,并设计exclusive loss,以通过这些索引标记的数据优化CNN模型。exclusive loss的目标是排斥任何两个未标记的数据方式。
索引标记数据
对于那些索引标记的数据,我们使用exclusive loss来优化模型而不使用任何标识标签。
分类丢失拉动相同身份数据的表示彼此接近,而排他性损失推动所有索引标记样本的表示彼此远离。
本文贡献
- 动态采样策略
- 基于距离的采样标准
- 联合学习方法
- 较高的性能、易扩展到少数标记情况(20%标记数据)
其中前两点在EUG中已有实现,本文的突破在于联合学习方法,即将标记数据、伪标记数据、索引标记数据联合起来进行模型学习。
II. RELATED WORKS
本文的相关工作介绍,从完全监督的行人重识别、半监督学习和渐进学习到半监督的行人重识别,再到无监督的域自适应的渐进学习,过程中引入的了渐进范式、Curriculum Learning (CL)课程学习、Self- Paced Learning (SPL)自我学习、半监督区域度量、动态匹配方法(DGM)、KNN等方法的相关引文和方法介绍。相比与EUG而言,这部分的介绍更为详细和周全,文中所用到了所有方法策略都对其现有的研究情况进行了充分的调研。
III. THE PROGRESSIVE MODEL
A. Framework Overview
![Progressive Learning for Person Re-Identification with One Example[reading notes]_第1张图片](http://img.e-com-net.com/image/info8/d9f1dd98aa8e4d979b1c096cc5405d0d.jpg)
图2展示了本文模型的框架结构。相比于EUG的表达,这个框架图更为直观和清晰。
整个框架图划分了三个模块:Training、Label estimation、 Next Training
Training
在Training这部分中,很直观的体现了训练数据由标记数据、伪标记数据、索引标记数据三部分组成,且他们在特征提取过程中是共享的网络结构,对同一套权重进行维护和更新的。不同的是,标记数据和伪标记数据采用是CE loss(交叉熵损失),而索引标记数据采用的是exclusive loss。
Label estimation
Label estimation(标签评估)阶段,基本和EUG保持一致。将标记数据集和未标记数据集都输入到神经网络,进行特征提取。将提取的特征映射到特征空间中,利用欧几里得距离对未标记数据进行标签评估。不同的是,对于那些伪标签置信度不高的样本,本文将其处理为索引标记数据。
Next Training
下一次训练,输入标记数据和更新后的置信度较高的伪标记数据和更新后的索引标记数据。
B. Preliminaries
带标签的数据集 L = { ( x 1 , y 1 ) , . . . , ( x n l , y n l ) } L = \left\{(x_1,y_1),...,(x_{n_l},y_{n_l})\right\} L={(x1,y1),...,(xnl,ynl)}
不带标签的数据集 U = { ( x n l + 1 ) , . . . , ( x n l + n u ) } U = \left\{(x_{n_l+1}),...,(x_{n_l+n_u})\right\} U={(xnl+1),...,(xnl+nu)}
∣ L ∣ = n l |L| = n_l ∣L∣=nl
∣ U ∣ = n u |U| = n_u ∣U∣=nu
C. The Joint Learning Method
Exclusive Loss
目的:
在没有任何标记的情况下,在M上学习有差别的嵌入。
通过学习区分样本而不是学习身份来优化CNN模型

式(1)可以优化为:

The Joint objective Function.
标记样本的目标函数:

伪标记样本的目标函数:

每一次训练的总的目标函数:
![Progressive Learning for Person Re-Identification with One Example[reading notes]_第2张图片](http://img.e-com-net.com/image/info8/5fe5724dd5ea4788804865bf530f5de2.jpg)
D. The Effective Sampling Criterion
有效的采样标准
将特征空间中的距离作为伪标签可靠性的度量。
采用最近邻(NN)分类器而不是学习的身份分类。
标签估计方法
![Progressive Learning for Person Re-Identification with One Example[reading notes]_第3张图片](http://img.e-com-net.com/image/info8/f68c8e191e2f4c738ecd8d1412e990bd.jpg)
候选指示集:
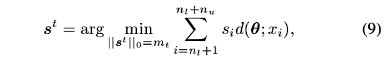
E. The overall iteration strategy
![Progressive Learning for Person Re-Identification with One Example[reading notes]_第4张图片](http://img.e-com-net.com/image/info8/3ee838104d934c668c339103ecddd392.jpg)
总体的迭代策略如Algorithm 1 The proposed framework 所示。
其中除了第4步天剑了对Mt的更新以外,其余步骤皆与EUG相同。
IV. EXPERIMENTAL ANALYSIS
在实验部分,作者对实验的数据集、评估指标、实验设置以及实现细节都进行了详细的介绍。月state-of-the- art methods进行了对比和分析。结果如下:
![Progressive Learning for Person Re-Identification with One Example[reading notes]_第5张图片](http://img.e-com-net.com/image/info8/724ad526d3b24cdbb2fa3a1b899e3479.jpg)
从实现结果来看,本文方法确实交DGM+IDE和Stepwise有了较为显著的提升,在距离完全监督的方法的实验效果还是存在进步空间的。
另外,值得一提的是,作者在实验结果的对比时,并未将其上一篇EUG的结果纳入其中,在此附上EUG的实验结果。
![Progressive Learning for Person Re-Identification with One Example[reading notes]_第6张图片](http://img.e-com-net.com/image/info8/b9b98e8d1594476e84c4ae6a4ace1ed4.jpg)
对比之下可见,本文是在EUG的基础上提出的优化方案,但效果并未在EUG的基础上有太明显的提升。