基于知识图谱的多轮对话系统
基于知识图谱的多轮对话系统
一.项目来源
之前实习的时候,天天开会听大佬们利用rasa构建知识图谱多轮对话,虽然那个时候啥都没有吸收到,但知识图谱多轮对话系统渐渐扎根在我的脑海里面,一定要实现一个demo
这边很感谢B站up主 “每天都要机器学习”,跟着老师的知识图谱视频也慢慢懂了怎么搭建图谱,怎么意图识别,怎么槽位填充,还有哪些不足之处?
二.项目架构
老师的PPT里面对这个项目的整体流程图进行了解析

简化版代码运行流程图如下所示

这个项目已实现的功能:
1.知识图谱的构建
2.基于知识图谱的多轮对话
效果图:
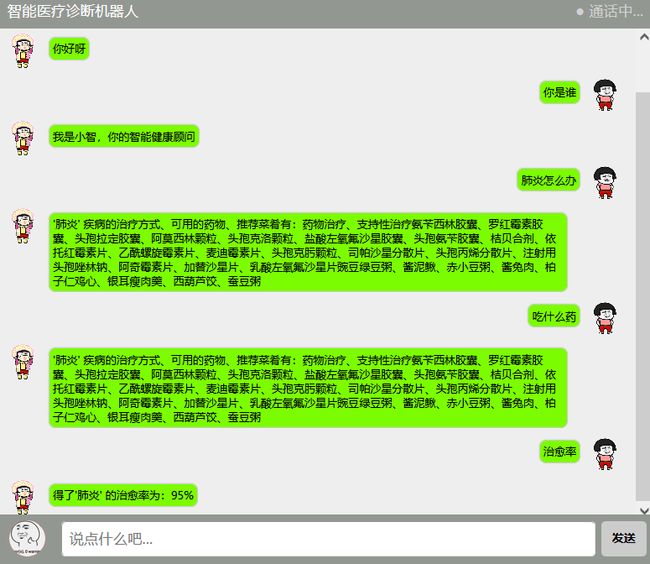
具体代码运行流程图如下所示

以用户输入“请问糖尿病是什么”为例:
NLU模块
1)先进入分类模型 1,判断是否是闲聊类的意图,包括:greet、goodbye、deny、isbot、accept、diagnose
如果命中前四个意图,那就进入gossip_robot,从准备好的回复预料中随机抽取一条返回给用户,对话结束;

命中accept意图,则在进行问题澄清时发生作用

命中diagnosis,进入medical_robot;

对于“请问糖尿病是什么”这句话,命中的是diagnosis,进入medical_bot
2)在medicall_bot,中,先进入分类模型(意图识别)(bert+textcnn),该模型是针对13个医疗类的意图进行判断,之后进入实体抽取模型(bilstm+crf),进行实体识别与提取;
意图识别的结果:
{'confidence': 0.9402524828910828, 'name': '定义'}
可以看出来模型对“请问得了糖尿病是什么”识别出来客户想问的是糖尿病的定义
实体抽取的结果:
[{'entities': [{'type': 'disease', 'word': '糖尿病'}], 'recog_label': 'model', 'string': '糖尿病是什么'}, {'entities': [{'recog_label': 'dict', 'type': 'disease', 'word': '糖尿病'}], 'string': '糖尿病是什么'}]
DST模块
3)得到意图和实体之后,先用实体填充槽位
参考https://www.writebug.com/explore/userinfo/kailai大佬的说法,NLU和DST的关系非常紧密,都是在槽位填充过程中发挥了作用,但是在这个过程中扮演了不同的角色:
NLU模块是对用户的输入进行意图的分类,同时对输入中的实体进行标注,
{'entities': [{'type': 'disease', 'word': '糖尿病'}], 'recog_label': 'model', 'string': '糖尿病是什么'}
这里标出了实体的类型(type),对应知识图谱中的结点,同时标出对应的字段(word),但是还没有填充,只是把实体找出来了
DST模块则是基于对话历史,为槽位列表中的每一个槽位找到了一个槽位值
"定义":{
"slot_list" : ["Disease"],
"slot_values":None,
"cql_template" : "MATCH(p:疾病) WHERE p.name='{Disease}' RETURN p.desc",
"reply_template" : "'{Disease}' 是这样的:\n",
"ask_template" : "您问的是 '{Disease}' 的定义吗?",
"intent_strategy" : "",
"deny_response":"很抱歉没有理解你的意思呢~"
}
上面这个是“定义”这个意图下的信息(form),槽位列表中只有一个槽位“Disease”
"治疗方法":{
"slot_list" : ["Disease"],
"slot_values":None,
"cql_template" : ["MATCH(p:疾病) WHERE p.name='{Disease}' RETURN p.cure_way",
"MATCH(p:疾病)-[r:recommand_drug]->(q) WHERE p.name='{Disease}' RETURN q.name",
"MATCH(p:疾病)-[r:recommand_recipes]->(q) WHERE p.name='{Disease}' RETURN q.name"],
"reply_template" : "'{Disease}' 疾病的治疗方式、可用的药物、推荐菜肴有:\n",
"ask_template" : "您问的是疾病 '{Disease}' 的治疗方法吗?",
"intent_strategy" : "",
"deny_response":"没有理解您说的意思哦~"
}
上面这个是“治疗方法”这个意图下的信息(form),槽位列表中只有一个槽位“Disease”
“在每一轮对话中,DST 模块都会查看截止目前的所有对话历史,然后确定哪个文本可以填充为槽位列表中某个特定槽位的槽位值,这个过程谓之追踪(Dialogue State Tracking)。”
“在这个项目中,这一步是通过遍历槽位列表和实体识别的结果进行匹配完成的。”
比如在“糖尿病是什么”这个例子中,识别到意图为“定义”,又NER判断的type是“disease",则对应form中slot_values:{“disease”:糖尿病},你可以理解成,slot_list就是需要填充的槽位,而各个槽位上的值则交给slot_values
PL模块
4)之后根据意图的置信度"confidence"确定回复策略
这里分成了三种简单的情况:
=0.8,根据识别到的意图去neo4j中查询答案,返回给用户
0.3~0.8,反问用户,进行问题澄清,例如机器人会说"请问您是问糖尿病的治疗方法吗?"
<0.3,返回已经准备好的兜底话术,例如"I am sorry"
“DST 模块 +PL 模块组成了任务型对话机器人中的对话管理(DM)模块,在这个项目中界限并不是特别明显,主要实现逻辑都在 modules.py 文件的 semantic_parser 函数中。”
这次就先说到这里,下次再结合数据集和运行测试,如何避免我走的坑再细说
注:可以反复看看前面发的流程图,核心思想都在里面啦~~~~~~~~~
最后也感谢各位google上面的大佬的博文讲解
之后附上gitee个人仓库链接