(保姆级教程)基于YOLOX(pytorch)的安全帽检测
文章目录
前言
一、资料下载
1.YOLOX代码及YOLOX预训练权重文件下载
2.安全帽数据集下载
二、环境配置
1.在anconda中创建虚拟环境并激活
2.配置pytorch-gpu
3.检查pytorch-gpu是否配置成功
4.其他库的配置
三.数据集标注
四.训练以及预测
五.预测结果展示
前言
本文章是基于pytorch利用YOLOX对安全帽进行检测,也可扩展为自己训练自己想要训练的数据集.https://gitee.com/mazhichengccc/yolox-pytorch这个文章高包括具体的训练步骤与预测方法,本文是对这篇文章的补充与完善,内容详细,特别适合于新手小白。
一、资料下载
1.YOLOX代码及YOLOX预训练权重文件下载
https://gitee.com/mazhichengccc/yolox-pytorch https://gitee.com/mazhichengccc/yolox-pytorch下载完毕并解压之后,如下图:
https://gitee.com/mazhichengccc/yolox-pytorch下载完毕并解压之后,如下图:
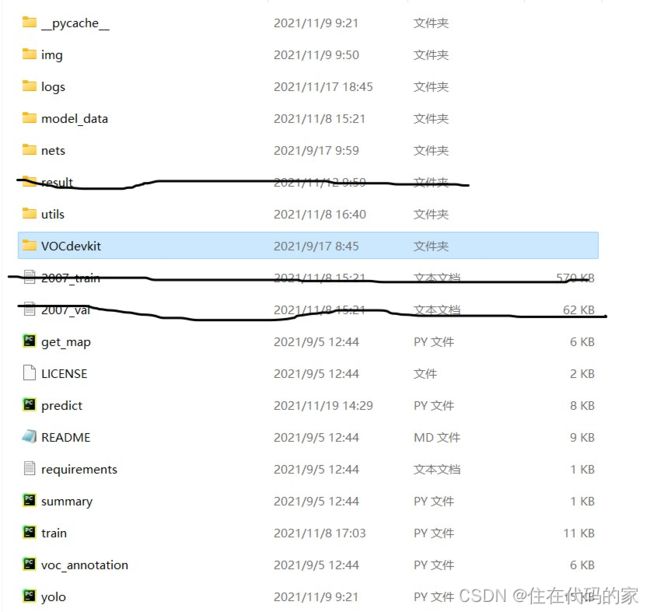
划黑线的result文件夹是自己后来创建的,用来保存测试结果的
剩下两个划黑线的是后面生成的,在后面会说明如何生成
其余的文件都是下载后都有的,接下来一一介绍:
img:用来存放需要测试的图片
logs:用来存放训练后生成的权重文件
model_data:用来存放yolox的预训练权重文件以及要训练的类别类型
nets:用来存放yolox的网络框架
utils:用来存放yolox参数的配置文件
VOCdevkit:用来存放待训练的数据集
get_map.py:计算评估结果(评估阶段)
predict.py:生成预测结果
README:解释说明性文件
requirements:需要配置的库(可不看)
summary.py:展示yolox的网络框架(可不看)
train.py:用来训练生成权重文件
voc_annotation.py:运行之后生成划黑线的两个文件,即2007_train,2007_val
yolo.py:yolox的主干网络
2.安全帽数据集下载
http://链接:https://pan.baidu.com/s/1NaFiW7I1ozc7z_8jFXiLUA 提取码:0jxkhttp://链接:https://pan.baidu.com/s/1NaFiW7I1ozc7z_8jFXiLUA 提取码:0jxk
将下载好的数据集放在VOCdevkit文件夹下的JPEGImages文件夹下,剩下两个文件夹的作用分别是:Annotations存放标注好的文件,ImageSets存放数据集序列
如果你要训练自己的数据集,需要别的数据集,可参考我上一篇文章,获取数据集
https://blog.csdn.net/mazhicheng123456/article/details/121517164?spm=1001.2014.3001.5501
二、环境配置
1.在anconda中创建虚拟环境并激活
代码如下:
#创建虚拟环境
conda create -n 自己要创建的环境名字 python=3.6
例如:
conda create -n torch1.7 python=3.6
#激活上面创建的虚拟环境
conda activate 自己上面创建环境的名字
例如:
conda activate torch1.7
电脑中若未安装anconda,请参考https://blog.csdn.net/wq_ocean_/article/details/103889237?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165180699516782248561279%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165180699516782248561279&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-103889237-null-null.142^v9^control,157^v4^control&utm_term=anconda%E5%AE%89%E8%A3%85&spm=1018.2226.3001.4187https://blog.csdn.net/wq_ocean_/article/details/103889237?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165180699516782248561279%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165180699516782248561279&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-103889237-null-null.142%5Ev9%5Econtrol,157%5Ev4%5Econtrol&utm_term=anconda%E5%AE%89%E8%A3%85&spm=1018.2226.3001.4187
2.配置pytorch-gpu
https://blog.csdn.net/qq_42005540/article/details/110237468?ops_request_misc=&request_id=&biz_id=102&utm_term=torch-gpu%E5%BA%93%E5%A6%82%E4%BD%95%E5%AE%89%E8%A3%85&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-110237468.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187https://blog.csdn.net/qq_42005540/article/details/110237468?ops_request_misc=&request_id=&biz_id=102&utm_term=torch-gpu%E5%BA%93%E5%A6%82%E4%BD%95%E5%AE%89%E8%A3%85&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-110237468.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187
3.检查pytorch-gpu是否配置成功
(1)在anconda中输入python,激活python环境
再输入:
import torch
print(torch.__version__)
print(torch.cuda.is_available())如果输出结果为True,表示配置成功
例如:

4.其他库的配置
若缺少其他库,可直接输入如下代码进行安装
pip install 所缺少的库如下载的速度太慢,可在后面加镜像源,如:
pip install 锁缺少的库 -i https://pypi.tuna.tsinghua.edu.cn/simple至此,虚拟环境配置完毕
三.数据集标注
使用labelimg软件进行标注
1.在anconda中下载
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelimg
因为我下载过了,所以显示:Requirement already satisfied

2.直接输入:labelimg 就可以自动打开软件了,如下图:

3.Open Dir是选择要标注的数据集文件夹路径,点击 Open Dir 选择你上面你下载数据集保存的文件路径,即VOCdevkit文件夹下的JPEGImages文件
4.Change Save Dir是保存标注好的文件路径,选择VOCdevkit文件夹下的Annotations文件
5.在View中选中Auto Save mode,目的是是标注好的图片标注自动保存
6.开始标注文件
选中Create RectBox,框选出要识别的物体(如:安全帽),类别类型填写你要识别的物体(如:hat),如下图:
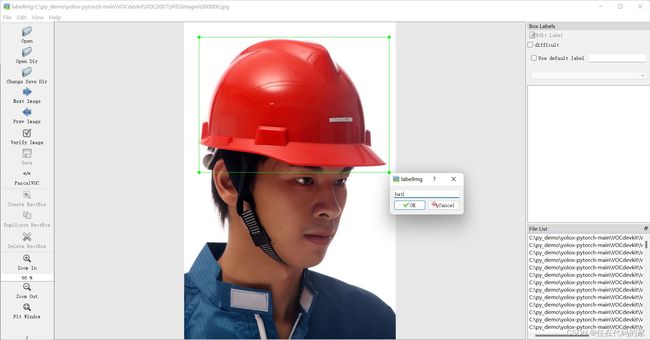
7.然后通过D键切换下一张图片,按上一步骤依次标注
四.训练以及预测
按照https://gitee.com/mazhichengccc/yolox-pytorch训练步骤更改需要修改的参数并进行训练以及训练完毕后的预测
五.预测结果展示


可见识别效果良好,能达到接近90%的准确率