(论文阅读)Document-level Relation Extraction as Semantic Segmentation
题目:Document-level Relation Extraction as Semantic Segmentation
来源:2021 IJCAI
原文链接:https://arxiv.org/abs/2106.03618
代码链接:https://github.com/zjunlp/
一、介绍
文档级关系提取是指从文档中提取多个实体对之间的关系。先前提出的graph-based或transformer-based的模型独立地利用实体,而不考虑关系三元组之间的全局信息。本文通过预测实体级关系矩阵来捕获局部和全局信息,与计算机视觉中的语义分割任务类似。具体来说,我们利用编码器模块来捕获实体的上下文信息,利用图像风格特征映射上的U-shape分割模块来捕获三元组之间的全局依赖性。实验结果表明,我们的方法可以在三个基准数据集DocRED、CDR和GDA上获得最先进的性能。
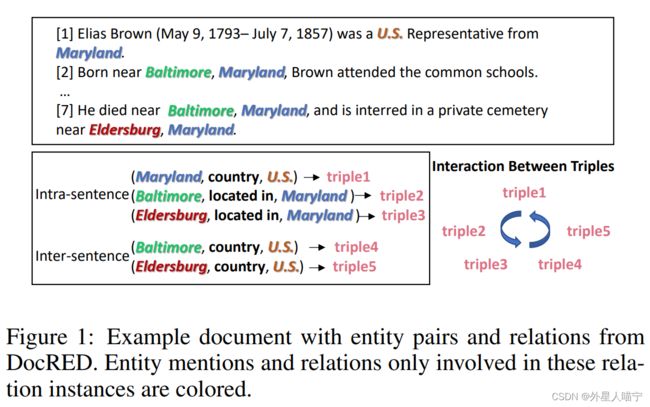
下图为论文中举的具体的例子:
二、主要创新点
1.encoder,捕获实体的上下文信息;
2.U-net捕获句子间三元组的全局依赖考虑了句子间实体对的全局交互;
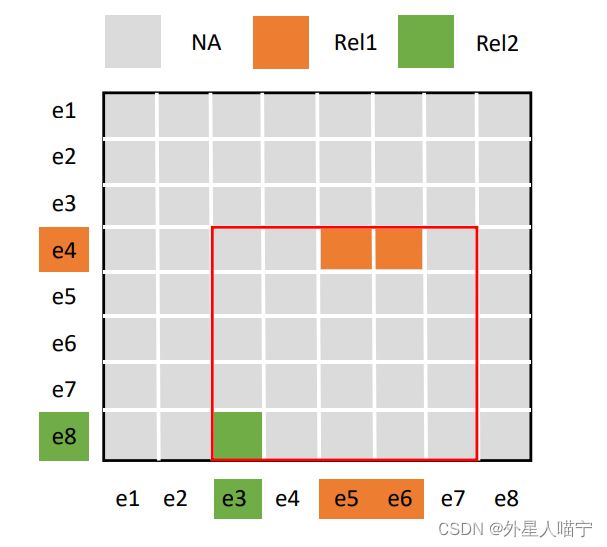
类似通过卷积网络将图像的每个像素标记为对应的表示类,这里将实体对间相关特征作为“图像”,每一个实体对间相关关系类型作为一个“像素点”。如下图.
3.存在很多对实体间没有特定关系,使用balanced softmax method。
三、方法
1. 符号定义
文档 d包含的实体表示为 ![]()
抽取从 e s e_s es到 e o e_o eo之间的关系,需要定义一个 N × N N×N N×N大小的矩阵 Y Y Y,使用 Y s , o Y_{s,o} Ys,o表示从 e s e_s es到 e o e_o eo的关系类型。接着,我们获得输出矩阵 Y Y Y,用于语义分割任务。在 Y Y Y中的实体顺序由它们第一次出现在文档中的顺序决定。特征图的获取是通过计算entity-to-entity相关性评估,并且将特征图看做一个图像。
2. Encoder 模块
在开头和结尾处插入特殊符号,来标记实体位置。
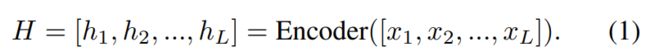
x i x_i xi是构成文档 d d d的token, h i h_i hi是对应的embedding。
注意到一些文档长度超过512,因此使用dynamic window(动态窗口)编码整个文档,对不同窗口的重叠标记的嵌入进行平均以获得最终表示。
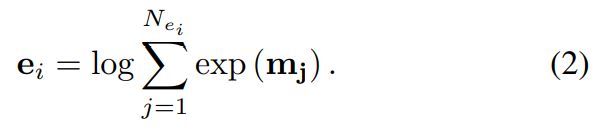
我们利用max pooling的平滑版本,即logsumexp pooling 每个实体 e i e_i ei,得到实体嵌入 ∗ ∗ e ∗ ∗ i **e**_i ∗∗e∗∗i
接着,我们基于entity-entity相似度计算实体级的关系矩阵,对于在矩阵中的每个实体 e i e_i ei,他们相似度通过一个D维的特征向量 F ( e s , e o ) F(e_s,e_o) F(es,eo)计算,这里使用两种策略计算:
- similarity-based method
- context-based method
对于similarity-based method,为基础的方法。将 e s e_s es与 e o e_o eo的逐元相似度、余弦相似度和双线性相似度的运算结果拼接起来,得到基于相似度的方法为:
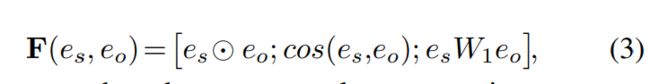
对于context-based method,我们利用实体感知的注意和仿射变换,得到如下特征向量:
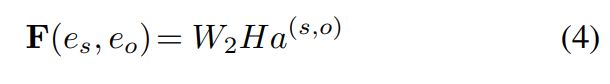
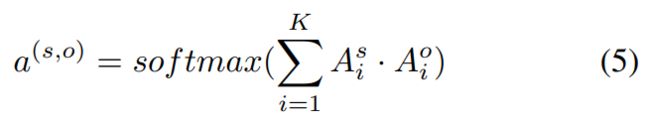
a代表attention权重,H是document embedding。
3. U-shape 分割模块
U-Net在CV领域是知名的语义分割模型。结构图如下:
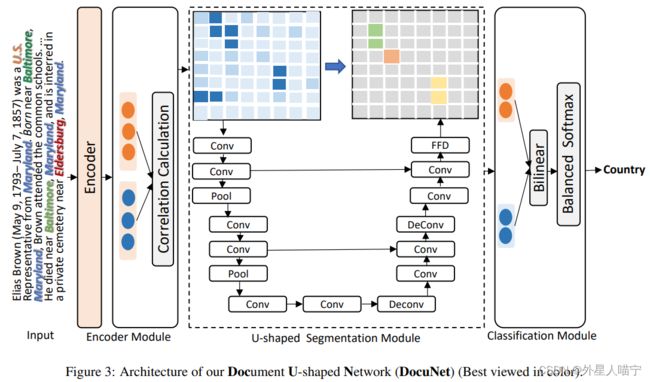
将实体级关系矩阵 F F F为 R N × N × D R^{N×N×D} RN×N×D作为Dchannel图像,我们在 F F F中将文档级关系预测作为像素级掩码,其中N是从所有数据集样本中计算出的最大的实体数量。具体来说,N是实体的最大数量,从所有数据集样本中统计。为此,我们利用了U-Net [Ronneberger et al., 2015],这是计算机视觉中一个著名的语义分割模型。如图3所示,模块形成u形分割结构,其中包含两个下采样块和两个具有跳跃连接的上采样块。一方面,每个下采样块有两个后续的max pooling和独立的卷积模块。在每个下采样块中,通道数量增加一倍。如图2所示,实体级关系矩阵中的分割区域为实体对之间的关系共现。u形分割结构可以促进接受域类比中实体对之间的信息交换向隐式推理转变。具体来说,CNN和下采样块可以扩大当前实体对嵌入 F ( e s , e o ) F(e_s, e_o) F(es,eo)的接受域,从而为表示学习提供丰富的全局信息。另一方面,该模型有两个上采样块和一个后续的反卷积神经网络和两个独立的卷积模块。与下采样不同,每个上采样块的信道数减半,可以将聚合的信息分布到每个像素上。
最后,我们结合编码模块和U-shaped分割模块来捕获局部和全局信息 Y Y Y,如下所示:
![]()
Y Y Y属于 R N × N × D " R^{N×N×D^"} RN×N×D"是实体级关系矩阵, U U U为U-shape分割模块。
4. 分类模块
使用实体级关系矩阵 Y Y Y表示 e s e_s es和 e o e_o eo,使用前馈神经网络映射称为隐藏表示 z z z。之后,使用双线性函数得到关系成立的概率:
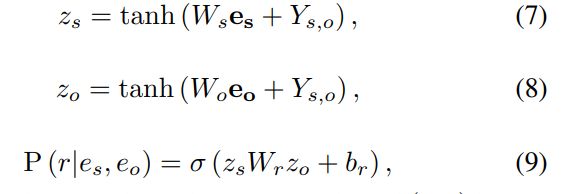
Y s , o Y_{s,o} Ys,o是实体对 ( s , o ) (s,o) (s,o)在矩阵 Y Y Y的表示。
5. balanced softmax method for training
由于之前的工作[Wang et al., 2019]观察到RE(关系抽取)存在不平衡的关系分布(许多实体对具有NA关系),我们引入了一种平衡的softmax训练方法,该方法受到了计算机视觉中的circle loss[Sur et al., 2020]的启发。具体来说,我们引入了一个额外的类别0,希望目标类别的分数都大于 s o s_o so,而非目标类别的分数都小于 s o s_o so。在形式上,我们有:
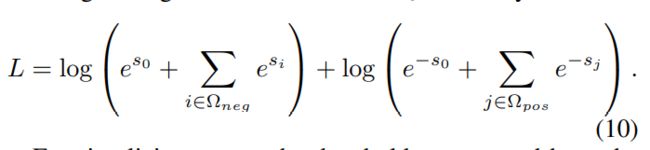
在这里,选取阈值为0,有下面的公式:
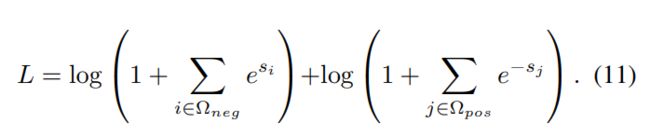
四、实验
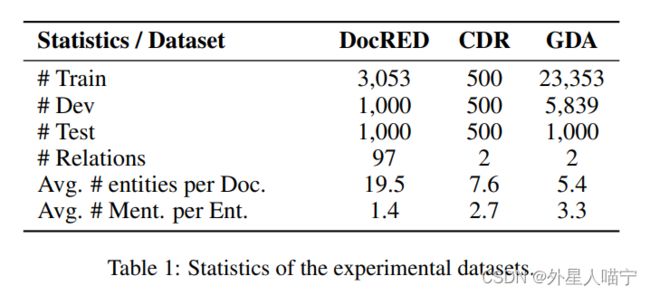
数据集:
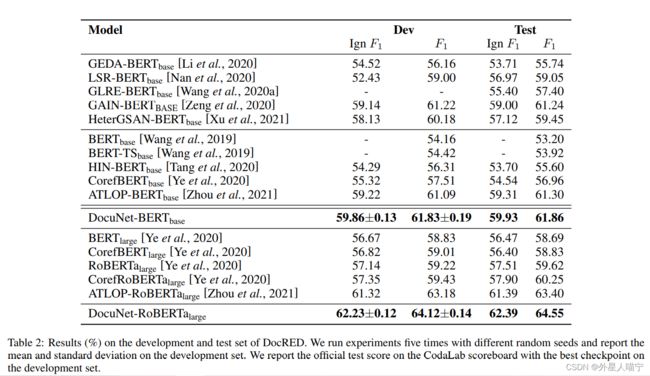
实验结果1:
一个例子:
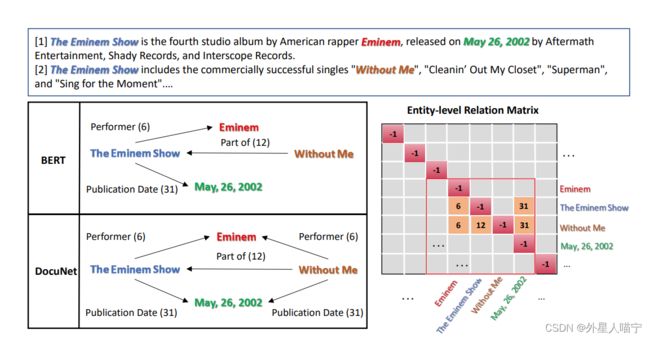
结论:使用U-net能提取更多的隐含关系。
更多试验结果参照论文。
谢谢阅读!磕盐人,加油吧!