第一个卷积神经网络:LeNet
目录
一、LeNet网络的介绍
二、LeNet-5的网络结构和工作原理编辑
二、pytorch的代码实现
三、模型的修改和测试
1、将两个平均池化层修改为最大池化层
2、将激活函数改为ReLu函数,lr=0.1,epoch=20
3、增加卷积层
四、用手写字体MNIST测试
一、LeNet网络的介绍
LeNet是Yann LeCun在1998年发表的论文《Gradient-based learning applied to document
LeNet是3个模型的统称:
LeNet-1:5 层模型,一个简单的 CNN。
LeNet-4:6 层模型,是 LeNet-1 的改进版本。
LeNet-5:7 层模型,最著名的版本。(最常用)
其中LeNet是以LeCun的名字命名,后面的数字代表研究成果的代号。现在最常用的是LeNet-5.
二、LeNet-5的网络结构和工作原理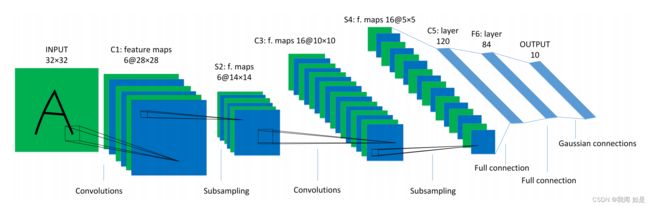
从图中可以看出,LeNet-5网络由7层构成:2个卷积层,2个下采样层,3个全连接层。
卷据层的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
采样[7]又分为上采样和下采样两种。上采样主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上;下采样又称为池化,主要目的:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。

经过卷积后,图片大小没变,通道数变多,经过下采样后,图片尺寸变小。卷积的作用是减少噪声,更好的提取图像特征。Pooling层的主要作用就是减少数据,降低数据纬度的同时保留最重要的信息。
其各个层的参数配置如下表所示。
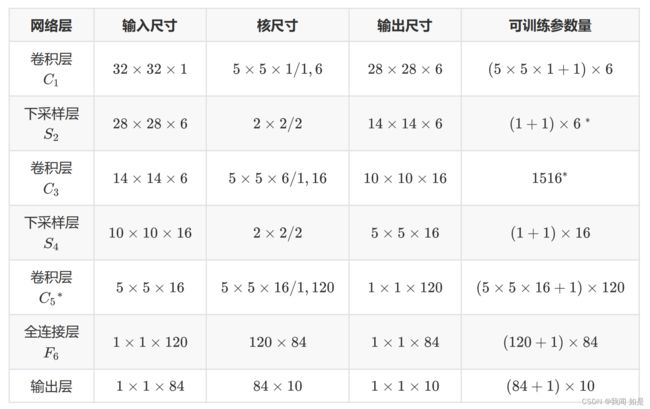
其中,核尺寸:5*5*1/1,6代表:卷积核尺寸为5*5*1, 步长为1,个数为6。
输出参数的计算公式为:

比如第1层,输入图片尺寸为32*32,也就是input_size=32,kernel_size=5,padding=0,stride=1,带入上式,计算出output_size=28,通道数为6。具体过程参考文献[2]的内容。
二、pytorch的代码实现
代码的实现主要参考李沐的《动手学深度学习》教材上的代码[5]:
setp1:导入需要的库
#导入需要的库
import torch
from torch import nn
from d2l import torch as d2l #pip install d2l导入需要的库,由于d2l中已经有数据集,所以导入这三个库就行了。
step2:建立网络结构
下图对网络结构进行了简化,编写程序的时候可以按照下图逐个输入即可。

#编写网络结构,根据LeNet的网络结构编写
#sequential是一个序列容器,模块将按照在构造函数中传递的顺序被添加到里面,
#最后返回最后一个模块的输出
net=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,padding=2), #第1个卷积层
nn.Sigmoid(), #sigmoid激活层
nn.AvgPool2d(kernel_size=2,stride=2), #平均池化层
nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5),#第2个卷积层
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
#三个全连接层
nn.Flatten(), #将连续的几个维度展平成一个tensor
nn.Linear(in_features=16*5*5,out_features=120),
nn.Sigmoid(),
nn.Linear(in_features=120,out_features=84),
nn.Sigmoid(),
nn.Linear(in_features=84,out_features=10) #因为是10个类,所以最后输出特征为10
)模型修改的时候,就可以修改网络结构。
sttep3:查看各层是否满足要求
#随机产生一个单通道的数据,大小为28*28,数据格式为float32
X=torch.rand(size=(1,1,28,28),dtype=torch.float32)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)打印出来的层为:

step4:导入数据集
batch_size=256
train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size=batch_size)setp5:定义计算精度函数和训练函数
gpu计算精度函数:
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
训练函数:
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')step6:训练模型
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())因为模型数据每次都会有所偏差,所以代码运行4次的结果:

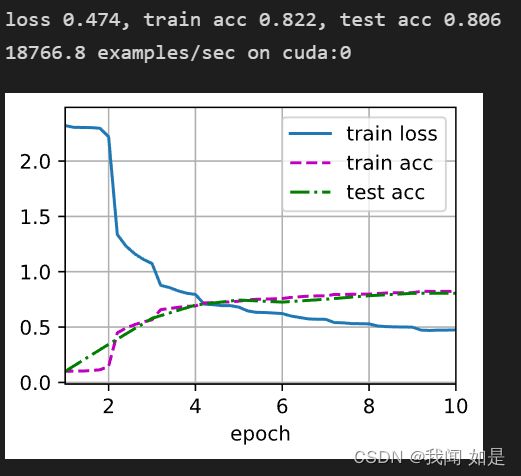


从结果可以看出,loss值0.46-0.8之间,训练集精度在0.82左右,变化很小。测试集从0.7-0.82之间变化,变化值还是比较大。而且普遍表现出来数据集在训练集上表现好,测试集上表现差的情况,有过拟合现象。
为了提高精度,做一些修改。
三、模型的修改和测试
1、将两个平均池化层修改为最大池化层
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
# nn.AvgPool2d(kernel_size=2, stride=2),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
# nn.AvgPool2d(kernel_size=2, stride=2),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))输出4次结果:



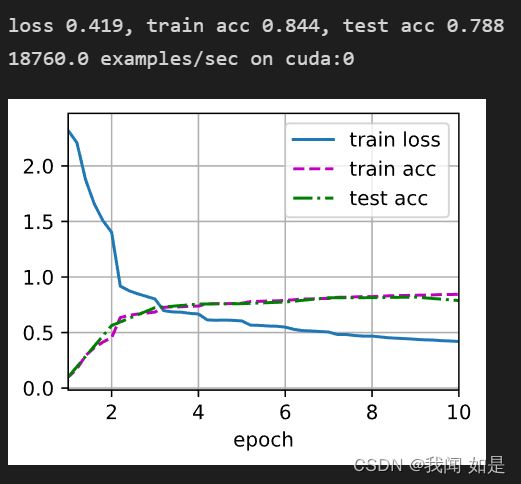
从结果可以看出,loss变化浮动比较大,测试集上数据有所改善,但是还是有过拟合现象。
2、将激活函数改为ReLu函数,lr=0.1,epoch=20
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(),
# nn.AvgPool2d(kernel_size=2, stride=2),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(),
# nn.AvgPool2d(kernel_size=2, stride=2),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.ReLU(),
nn.Linear(120, 84), nn.ReLU(),
nn.Linear(84, 10))为了防止不收敛,将学习率由0.9改为0.1,epoch由10改为20.
输出结果:

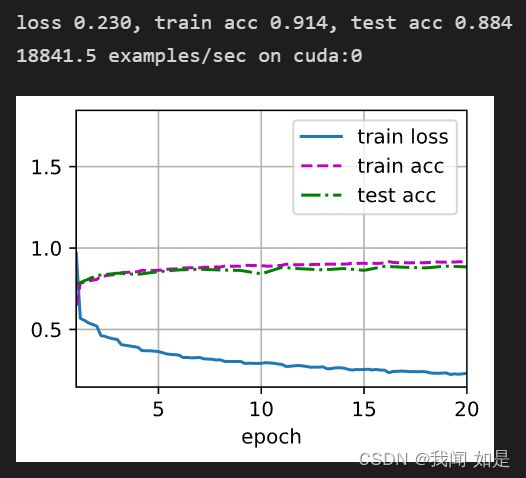

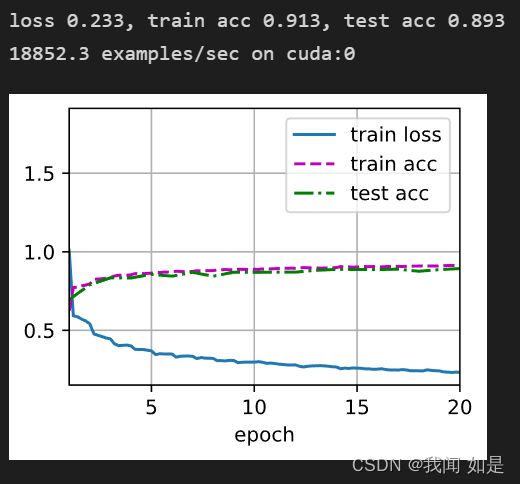
从结果可以看出,loss变化很明显,由0.4到0.2左右了。训练集精度达到了0.9以上,测试集精度也到了0.88左右。
3、增加卷积层
net = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=5, padding=2), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
# nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
# nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 32, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
# nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(32 * 3 * 3, 128), nn.Sigmoid(),
nn.Linear(128, 64), nn.Sigmoid(),
nn.Linear(64, 32), nn.Sigmoid(),
nn.Linear(32, 10)
)输出结果:
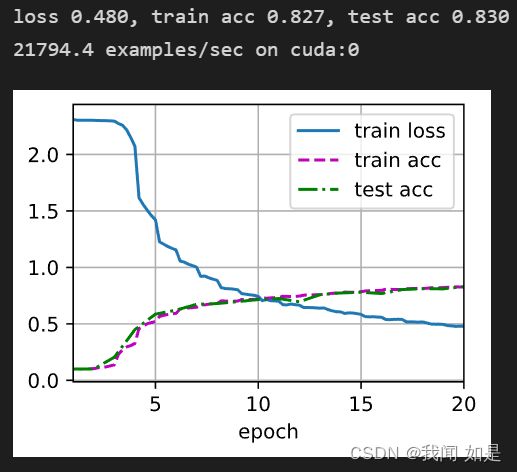

从结果可以看出,加上卷积层的效果会变差。
四、用手写字体MNIST测试
拿最好的结果进行训练,导入MNIST数据集进行测试。
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
batch_size=256
trans = transforms.ToTensor()
mnist_train=datasets.MNIST(root='./data/',train=True,transform=trans,download=True)
# mnist_train = datasets.MNIST(root="./data", train=True, transform=trans, download=True)
mnist_test = datasets.MNIST(root="./data", train=False, transform=trans, download=True)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=0)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size, shuffle=True,num_workers=0)

结果非常好,已经达到99%。
参考文献:
[4] 从0开始撸代码--手把手教你搭建LeNet-5网络模型
[5] 23 经典卷积神经网络 LeNet【动手学深度学习v2】
[6] 1.LeNet5--手写数字识别(Pytorch)
[7] 采样层介绍