论文阅读——Reduce Information Loss in Transformers for Pluralistic Image Inpainting-CVPR 2022
原文链接:
[2205.05076] Reduce Information Loss in Transformers for Pluralistic Image Inpainting (arxiv.org)
代码链接:
liuqk3/PUT: Paper 'Reduce Information Loss in Transformers for Pluralistic Image Inpainting' in CVPR2022 (github.com)
本文创新点:
- 提出了patch-based auto-encoder(P-VQVAE),在VQVAE的基础上将patch作为输入;
- 提出了Un-Quantized Transformer(UQ-Transformer),直接将P-VQVAE编码器的特征作为输入,不进行量化,减少信息的损失。
目录
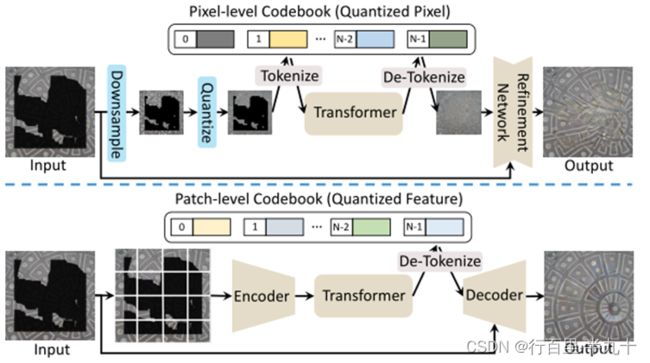
网络结构
P-VQVAE
patch-based encoder
Dual-Codebook
Multi-Scale Guided Decoder
训练P-VQVAE
UQ-Transformer
训练UQ-Transformer
网络结构
网络整体由P-VQVAE和UQ-Transformer两个部分构成。
P-VQVAE
作用:避免输入下采样的信息丢失,同时保证transformer的计算效率。
P-VQVAE主要由三个部分组成:patch-based encoder、dual-codebook 和multi-scale guided decoder。
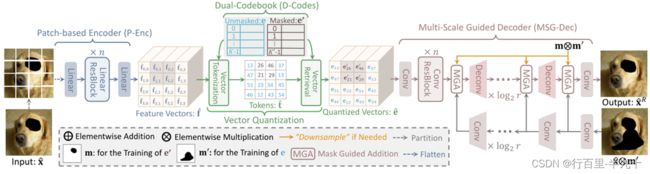
patch-based encoder
编码器由几个线性层构成,首先将图像划分成![]() 个patch(r为patch的大小,默认为8),然后将每个patch展平,并投影到一个特征向量中。特征向量可以用下式表示:
个patch(r为patch的大小,默认为8),然后将每个patch展平,并投影到一个特征向量中。特征向量可以用下式表示:
![]()
其中,C为特征向量的维度(默认为256),ε(•)为编码操作。
对于每个patch,如果包含缺失像素,则成为masked patch,否则为unmasked patch。
Dual-Codebook
双码本由两个部分构成,![]() 负责unmasked patch特征向量的映射,
负责unmasked patch特征向量的映射,![]() 负责masked patch特征向量的映射(K和K'为潜在向量的个数)。
负责masked patch特征向量的映射(K和K'为潜在向量的个数)。
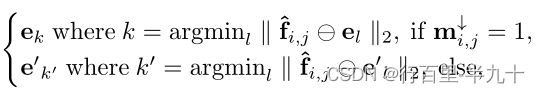
其中,m↓为1代表unmasked patch,0代表masked patch,㊀代表元素相减,
![]() ,
,![]() 为特征向量
为特征向量![]() 的量化向量和tokens。
的量化向量和tokens。
Multi-Scale Guided Decoder
设![]() 为transformer修复的token,
为transformer修复的token,![]() 是基于
是基于![]() 码本中检索到的量化向量,
码本中检索到的量化向量,
![]()
![]() 为修复图像,
为修复图像,![]() 为输入的掩码图像。
为输入的掩码图像。
解码器有两个分支:一个是从量化向量![]() 开始的主分支,使用几个反卷积层来生成修复图像,另一个是参考分支,从掩码图像
开始的主分支,使用几个反卷积层来生成修复图像,另一个是参考分支,从掩码图像![]() 中提取多尺度特征图。参考分支的主要作用就是保证掩码图像中已有的像素值保持不变。
中提取多尺度特征图。参考分支的主要作用就是保证掩码图像中已有的像素值保持不变。
参考分支的特征通过Mask Guided Addition (MGA)与主分支进行特征融合:
![]()
其中,![]() 是主分支的特征,
是主分支的特征,![]() 是参考分支的特征,大小为
是参考分支的特征,大小为![]() 。
。
训练P-VQVAE
在训练P-VQVAE的时候,会用随机掩码m'![]() 去除x
去除x![]() 中的一些像素当做参考分支的输入。
中的一些像素当做参考分支的输入。
![]()
![]()
训练损失
![]()
![]() 为commitment loss,主要是约束encoder的输出和embedding空间保持一致,以避免encoder的输出变动较大(从一个embedding向量转向另外一个)。
为commitment loss,主要是约束encoder的输出和embedding空间保持一致,以避免encoder的输出变动较大(从一个embedding向量转向另外一个)。
![]() 为codebook loss,sg指的是stop gradient操作,这意味着这个L2损失只会更新embedding空间,而不会传导到encoder。在实际操作中使用指数移动平均(exponential moving averages,EMA)来更新embedding空间,采用EMA这种更新方式往往比直接采用L2损失收敛速度更快。在每次迭代 t 时,潜在向量
为codebook loss,sg指的是stop gradient操作,这意味着这个L2损失只会更新embedding空间,而不会传导到encoder。在实际操作中使用指数移动平均(exponential moving averages,EMA)来更新embedding空间,采用EMA这种更新方式往往比直接采用L2损失收敛速度更快。在每次迭代 t 时,潜在向量![]() 更新为
更新为
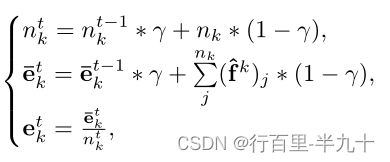
其中,![]() 为
为![]() 中分配给
中分配给![]() 的特征向量,
的特征向量,![]() 为
为![]() 为特征向量的个数,γ为衰减参数,实验中设为0.99。
为特征向量的个数,γ为衰减参数,实验中设为0.99。
UQ-Transformer
Transformer的输入是encoder输出的特征,而不是离散的token,输出是masked token属于码本中向量的概率,目的是避免量化引入信息损失。
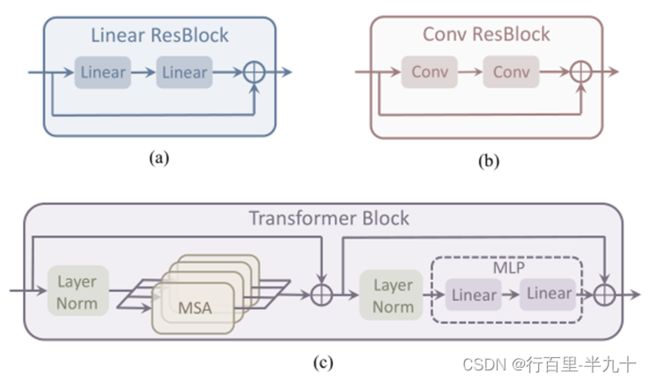
训练UQ-Transformer
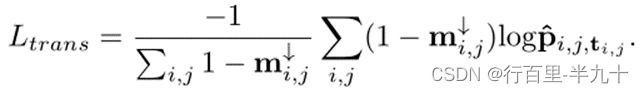
其中,![]() ,为ground-truth tokens。
,为ground-truth tokens。
VQVAE参考生成模型之VQ-VAE - 知乎 (zhihu.com)