Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Encoding论文解读
Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Encoding
基于多粒度上下文编码的文档级事件角色填充提取

paper:Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Encoding (aclanthology.org)
code:xinyadu/doc_event_role (github.com)
data:MUC Data Sets (nist.gov)
期刊:ACL2020
摘要
在事件抽取领域中,很少有超越句子级的事件抽取方法。当识别的事件论元分布在多个句子中时就会存在问题。我们认为文档级事件抽取是一个很困难的任务,因为它需要一个更大的上下文视图来确定哪些文本跨度对应于事件论元填充符。我们首先研究了端到端神经序列模型(具有预训练的语言模型表示)在文档级角色填充提取中的表现,以及探究的上下文长度如何影响模型的性能。为了动态聚合在不同粒度级别(例如,句子和段落级别)学习的神经表示捕获的信息,我们提出了一种新的多粒度阅读器。我们在MUC-4事件抽取数据集上评估了我们的模型,并表明我们的最佳系统比以前的工作表现得更好。我们还展示了上下文长度和神经模型在任务中的表现之间的关系的发现。
1、简介
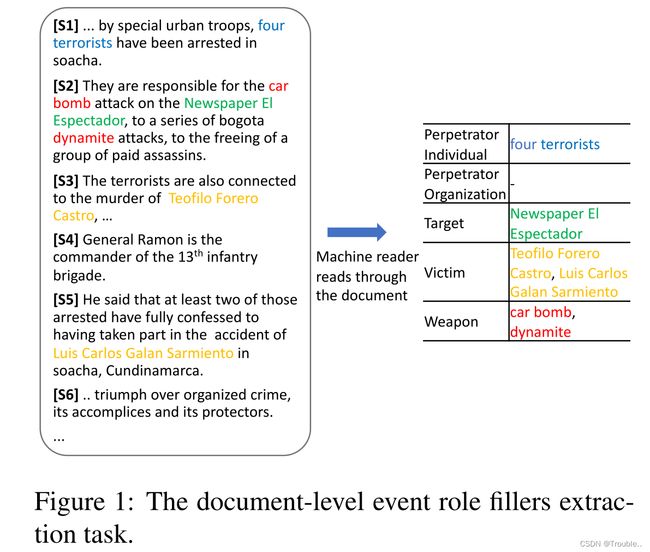
文档级事件提取的目标是在文章中识别预先指定类型的事件及其特定的事件角色填充符,即论元。完整的文档级抽取问题通常需要角色填充词提取抽取、名词短语共指消解和事件跟踪(即确定提取的角色填充词属于哪个事件)。本文主要关注的是文档级角色填充符抽取。图1展示了示例。给定一个文档,包含了多个段落或句子,和一组固定的事件类型(恐怖事件)和关联角色(肇事者个人、受害者、武器)。我们的目标是识别那些文本中描述的每个事件的角色填充符的文本跨度。这通常需要句子级的理解和对句子之外的上下文的准确解释。例如,将“Teofilo Forero Castro”(在S3中提到)确定为汽车炸弹袭击事件的受害者(在S2中提到的),确定S4中没有角色填充(这两种情况都主要取决于句子层面的理解,以及将S1中的“四名恐怖分子”确定为肇事者个人(这需要跨句子边界的共指解决方案)。生成事件的文档级提取对于促进信息检索和文章摘要等下游应用以及世界事件趋势分析等现实应用至关重要。
最近在文档级事件角色填充方面的工作采用了一种流水线架构,为每一种类型的角色和相关的上下文检测进行分类。然而这些方法可能(1)遭受到不同流水线阶段的错误传播;(2)要求大量的特征工程(用于候选角色填充词抽取的词汇句法模式特征;用于文档级别检测事件相关句子的词汇桥和语篇桥特征)。此外,这些特征是为特定领域手动设计的,这需要语言直觉和领域专业知识。
神经网络端到端的模型已经被证明在句子级信息抽取任务中表现出色,例如命名实体识别和句子内事件ACE类型抽取。然而,据我们所知,目前还没有研究将文档级事件角色填充抽取作为端到端神经序列学习任务。与从独立句子中抽取事件及其角色填充词相比,文档级事件抽取对神经序列学习模型提出了特殊挑战。首先,捕获长序列中的长期依赖性仍然是循环神经网络的基本挑战。为了对长序列建模,大多数基于RNN的方法使用时间反向传播。但这些模型仍然很难扩展到很长的序列。其次,尽管与RNN架构相比,预训练的双向transformer模型(如BERT),可以更好地捕捉长距离依赖关系,但它们仍然对序列的最大长度有限制,这低于许多关于事件的文章的长度。
在下面的部分,我们研究如何训练和应用端到端的神经网络模型来进行事件角色填充符抽取。我们首先将问题形式化为文档中一组连续句子中标记的序列标注任务。为了解决应用于长序列的神经模型的上述挑战,(1)我们研究了上下文长度(即最大输入段长度)对模型性能的影响,并找到最合适的长度;(2)提出了一种多粒度阅读器,该阅读器动态地聚合从本地上下文(句子级)和更广泛的上下文(段落级)中学习到的信息。对我们在MUC-4数据集上的方法进行的定量评估和定性分析都表明,多粒度阅读器比基线模型和先前的工作有了实质性的改进。
2、相关工作
事件提取主要在两种范式下进行研究:检测事件触发词和从单个句子中提取论元(例如ACE任务),而在文档级别(例如MUC-4模板填充任务)。
句子级事件抽取。ACE事件提取任务需要从句子中提取事件触发器及其论元。例如,在句子“ … Iraqi soldiers
were killed by U.S. artillery …”中,目标是确定被炸死者触发的“死亡”事件和相应的论点(place、victim、instrument)等。目前已经提出了许多方法来改进此特定任务的性能。手工制造特征、循环神经网络(RNN)、卷积神经网络(CNN)。Wadden利用预训练的上下文表示。这个方法通常侧重句子级上下文,以提取事件触发器和论元,很少推广到文档事件抽取。
只有少数模型超越了单个句子来做出决定。Ji和Grishman在文档中实施事件角色一致性。Liao和Grishman探索了事件类型共现模式,以传播事件分类决策。同样,Yang和Mitchell提出在文档上下文中联合提取事件和实体。尽管这些方法使用跨句信息进行决策,但它们的提取仍在句子层面。
文档级事件抽取。主要在经典MUC范式下进行了研究。整个任务包括构建答案关键模板,每个事件一个模板(数据集中的一些文档描述了多个事件)。通常涉及三个步骤——角色填充符提取、角色填充符共指消解和事件跟踪)。在这项工作中,我们将重点放在角色填充提取上。
从建模角度来讲,最近的工作探究了本地和额外的上下文,来做角色填充提取提取决策。GLACIER联合考虑了概率框架中的交叉句和名词短语证据,以提取角色填充词。TIER建议首先使用分类器确定文档类型,然后识别文档中与事件相关的句子和角色填充词。Huang和Riloff提出了一种自下而上的方法,首先积极识别候选角色填充词(具有词汇句法模式特征),然后通过衔接分类器(具有语篇特征)去除虚假句子中的候选词(即与事件无关)。与Huang和Riloff相似,我们还结合了句内和跨句特征(段落级特征),但我们的模型没有使用手动设计的语言信息,而是自动学习如何动态地结合文章的学习表示。此外,与之前基于流水线的工作相比,我们的方法将任务处理为端到端序列标记问题。
还开展了无监督事件模式归纳和文档中的开放域事件提取的工作:主要思想是将对应于相同角色的实体分组到事件模板中。另一方面,我们的模型是以受监督的方式训练的,事件模式是预定义的。
除了事件提取,人们对跨句子关系提取的兴趣也在增加。这项工作假设提供了提及,因此更多的是提及/实体级别的分类问题。相反,我们的工作侧重于使用序列标记方法提取角色填充词;角色填充类型在此过程中确定。
捕获神经网络序列模型的长期依赖性。对于训练神经网络序列模型(如RNN),捕获序列中的长期依赖仍然是一项基本挑战。大多数方法使用时间反向传播(BPTT),但很难扩展到很长的序列。已经提出了许多模型变体来减轻长序列长度的影响,例如长期短期记忆(LSTM)网络和门控递归单元网络(GRU)。基于transformer的模型也显示了对长文本建模的改进。在我们的文档级事件角色填充提取工作中,我们还实现了模型中的LSTM层,并利用双向transformer模型BERT提供的预训练表示。从应用程序的角度来看,我们研究了在文档级提取设置中用于神经网络序列标记模型的合适上下文长度。我们还研究了如何通过在模型中动态合并句子级和段落级表示来缓解与长序列相关的问题(图3)。
3、方法
在下文中,我们描述了(1)如何将文档转换为成对的token-tag序列,并将任务形式化为序列标注问题(第3.1节);(2) 我们的基本k-sentence阅读器(第3.2节)和多粒度阅读器的架构(第3.3节)。
3.1 从文档和正确角色填充构建成对token标记序列
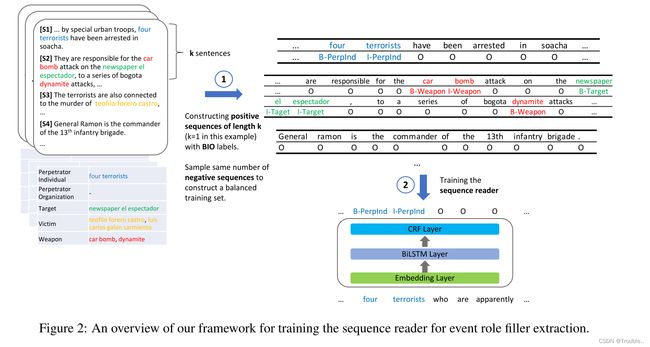
我们正式将文档级事件角色填充抽取作为一个端到端的序列标注任务。图2展示了这个大体的想法。给出一个文档和每个角色的正确标准填充符相关的文本跨度,我们采用BIO标注模式将文档转化为成对token-tag的序列。
我们构建了不同上下文长度的示例序列,用于训练和测试我们端到端的k-sentence阅读器。通过块,我们指的是BERT-512的序列长度约束范围内的连续句子块。更具体的来说,我们使用一个句子分割器去划分一个文档转化为句子 s 1 , s 2 , . . . , s n s_1,s_2,...,s_n s1,s2,...,sn。为了去构建训练集,从句子 i i i开始,连接 k k k个连续的句子 ( s i 到 s k + i − 1 ) (s_i到s_{k+i-1}) (si到sk+i−1),为了形成长度为 k k k的重叠候选序列,序列1由句子 { s 1 , . . . , s k } \{ s_1,...,s_k\} {s1,...,sk},序列2由句子 { s 2 , . . . , s k + 1 } \{ s_2,...,s_{k+1}\} {s2,...,sk+1}。为了平衡训练集的正负样本,我们从候选序列中进行正负样本采样,正样例的样本应该至少包含一个事件角色填充符,负样本的样本不能包含事件角色填充符。为了构建训练集和测试集,我们简单地将连续的 k k k个句子按顺序分组在一起,生成 n k \frac{n}{k} kn序列(第一个序列为 { s 1 , . . . , s k } \{ s_1,...,s_k\} {s1,...,sk},第二个序列为 { s k + 1 , . . . , s 2 k } \{ s_{k+1},...,s_{2k}\} {sk+1,...,s2k})。对于段落阅读器,我们设置 k k k为训练集的平均段落长度,并设置为测试集的真实段落长度。
我们将序列中的token表示为 x x x,则输入的k-sentence阅读器可以表示为 X = { x 1 ( 1 ) , x 2 ( 1 ) . . . , x l 1 ( 1 ) , . . . , x 1 ( k ) , x 1 ( k ) , . . . , x 1 ( k ) } X=\{ x_1^{(1)},x_2^{(1)}\,...,x_{l_1}^{(1)},...,x_1^{(k)},x_1^{(k)},...,x_1^{(k)}\} X={x1(1),x2(1)...,xl1(1),...,x1(k),x1(k),...,x1(k)}。其中 x i ( k ) x_i^(k) xi(k)表示为第 k k k个句子的第 i i i个token, l k l_k lk表示为第 k k k个句子的长度。
3.2 K-sentence 阅读器
由于我们的一般k-sentence阅读器不识别句子边界,我们简化输入序列为 { x 1 , x 2 , . . . , x m } \{ x_1,x_2,...,x_m \} {x1,x2,...,xm}。
嵌入层。对于嵌入层,我们将输入序列中的每个token x i x_i xi表示为其字嵌入和上下文标记表示的串联。
- 字嵌入。我们使用从网络爬虫爬取6百万数据进行训练的100维Glo e预训练单词嵌入。我们保持预训练的单词嵌入固定。给定一个token x i x_i xi,我们有它的单词嵌入: x e i = E ( x i ) xe_i=E(x_i) xei=E(xi)。
- 预训练语言表征。由预训练语言模型产生的上下文词嵌入已经证明有能力建模句子边界之外的上下文,并提高各种任务的性能。在这里,我们使用BERT-base生成上下文文本表征来作为我们k-sentence的标记标记模型。更准确的来说,我们使用12层的表征的平均值,经过实证经验并在预训练的时候冻结权重。对于输入序列文本 { x 1 , x 2 , . . . , x m } \{x_1,x_2,...,x_m\} {x1,x2,...,xm},其表征为:
x b 1 , x b 2 , . . . , x b m = B E R T ( x 1 , x 2 , . . . , x m ) xb_1,xb_2,...,xb_m=BERT(x_1,x_2,...,x_m) xb1,xb2,...,xbm=BERT(x1,x2,...,xm)
- 我们将为每一个token连接两种表征作为其词嵌入:
x i = c o n c a t ( x e i , x b i ) x_i=concat(xe_i,xb_i) xi=concat(xei,xbi)
- BiLSTM 层。为了帮助模型更好地捕获序列标注之间的任务特定特征。我们在token表示之上使用多层(3层)双向LSTM编码器,我们将其表示为BiLSTM:
{ p 1 , p 2 , . . . , p m } = B i L S T M ( { x 1 , x 2 , . . , x m } ) \{ p_1,p_2,...,p_m\}=BiLSTM(\{ x_1,x_2,..,x_m\}) {p1,p2,...,pm}=BiLSTM({x1,x2,..,xm})
- CRF 层。受到序列标注模型NER等启发。使用条件随机场有利于序列标注任务性能的提升。再通过线性层传递 { p 1 , p 2 , . . . , p m } \{ p_1,p_2,...,p_m \} {p1,p2,...,pm}之后,我们得到 P P P的大小为 m × s i z e m \times size m×size的标注空间,其中 P i , j P_{i,j} Pi,j代表的是序列第 i i i个token在第 j j j个标记的得分。对于序列 y = { y 1 , y 2 , . . . , y m } y=\{ y_1,y_2,...,y_m\} y={y1,y2,...,ym},我们将序列的对设置为:
s c o r e ( X , y ) = ∑ i = 0 m A y i , y i + 1 + ∑ i = 1 m P i , y i score(X,y)=\sum_{i=0}^m A_{y_i,y_{i+1}}+\sum_{i=1}^mP_{i,y_i} score(X,y)=i=0∑mAyi,yi+1+i=1∑mPi,yi
- A A A是发射矩阵, A i , j A_{i,j} Ai,j表示标签 i i i到标签 j j j的得分。对所有可能的标签序列的得分应用softmax函数,这产生正确序列 y g o l d y_{gold} ygold的概率。在训练期间,正确标签序列的对数概率最大化。在解码期间,模型预测获得最大分数的输出序列。
3.3 多粒度阅读器
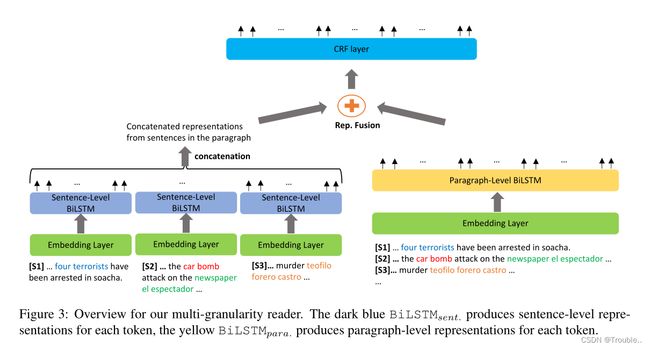
去探索不同粒度(句子级和段落级)聚合上下文token的表示效果,我们提出多粒度阅读器。
和k-sentence阅读器类似,我们使用相同的embedding layer来表示token。但我们将嵌入层应用于段落文本的两个粒度(句子和段落级别)。尽管来自不同粒度的嵌入层的单词嵌入是相同的,但当标记在句子上下文或段落上下文中编码时,每个标记的上下文化表示是不同的。
对应的是,我们建立了两个BiLSTM模型( B i L S T M s e n t , B i L S T M p a r a BiLSTM_{sent},BiLSTM_{para} BiLSTMsent,BiLSTMpara)去表示句子级上下文token表征 { x ~ 1 ( 1 ) , . . . , x ~ l 1 ( 1 ) , . . . , x ~ l k ( k ) , . . . , x ~ l k ( k ) } \{ \tilde x_1^{(1)},...,\tilde x_{l_1}^{(1)},...,\tilde x_{l_k}^{(k)},...,\tilde x_{l_k}^{(k)}\} {x~1(1),...,x~l1(1),...,x~lk(k),...,x~lk(k)},段落级上下文token表征 { x ^ 1 ( 1 ) , . . . , x ^ l 1 ( 1 ) , . . . , x ^ l k ( k ) , . . . , x ^ l k ( k ) } \{ \hat x_1^{(1)},...,\hat x_{l_1}^{(1)},...,\hat x_{l_k}^{(k)},...,\hat x_{l_k}^{(k)}\} {x^1(1),...,x^l1(1),...,x^lk(k),...,x^lk(k)}
句子级BiLSTM。
{ p ~ 1 ( 1 ) , p ~ 2 ( 1 ) , . . . , p ~ l 1 ( 1 ) } = B i L S T M s e n t ( { x ~ 1 ( 1 ) , x ~ 2 ( 1 ) , . . . , x ~ l 1 ( 1 ) } ) \{ \tilde p_1^{(1)},\tilde p_2^{(1)},...,\tilde p_{l_1}^{(1)}\}=BiLSTM_{sent}(\{ \tilde x_1^{(1)},\tilde x_2^{(1)},...,\tilde x_{l_1}^{(1)}\}) {p~1(1),p~2(1),...,p~l1(1)}=BiLSTMsent({x~1(1),x~2(1),...,x~l1(1)})
最后得到每个token句子级的表征在段落中 { p ~ 1 ( 1 ) , . . . , p ~ l 1 ( 1 ) , . . . , p ~ l k ( k ) , . . . , p ~ l k ( k ) } \{ \tilde p_1^{(1)},...,\tilde p_{l_1}^{(1)},...,\tilde p_{l_k}^{(k)},...,\tilde p_{l_k}^{(k)}\} {p~1(1),...,p~l1(1),...,p~lk(k),...,p~lk(k)}。
段落级BiLSTM。
{ p ~ 1 ( 1 ) , p ~ 2 ( 1 ) , . . . , p ~ l 1 ( 1 ) } = B i L S T M p a r a ( { x ~ 1 ( 1 ) , x ~ 2 ( 1 ) , . . . , x ~ l 1 ( 1 ) } ) \{ \tilde p_1^{(1)},\tilde p_2^{(1)},...,\tilde p_{l_1}^{(1)}\}=BiLSTM_{para}(\{ \tilde x_1^{(1)},\tilde x_2^{(1)},...,\tilde x_{l_1}^{(1)}\}) {p~1(1),p~2(1),...,p~l1(1)}=BiLSTMpara({x~1(1),x~2(1),...,x~l1(1)})
聚合和推理层。对于每一个token x i ( j ) x_i^{(j)} xi(j)(第 j j j个句子中的第 i i i个token),混合句子级( p ~ i ( j ) \tilde p_i^{(j)} p~i(j))和段落级( p ^ i ( j ) \hat p_i^{(j)} p^i(j))的表征。我们提出两种选项,第一个是使用求和运算,第二个是使用门控融合运算。
- 简单的求和融合。
p i ( j ) = p ~ i ( j ) + p ^ i ( j ) p_i^{(j)}=\tilde p_i^{(j)}+\hat p_i^{(j)} pi(j)=p~i(j)+p^i(j)
门控机制融合。
g i ( j ) = s i g m o i d ( W 1 p ~ i ( j ) + p ^ i ( j ) ) g_i^{(j)}=sigmoid(W_1 \tilde p_i^{(j)}+\hat p_i^{(j)}) gi(j)=sigmoid(W1p~i(j)+p^i(j))
p i ( j ) = g i ( j ) ⊙ p ~ i ( j ) + ( 1 − g i ( j ) ) ⊙ p ^ i ( j ) p_i^{(j)}=g_i^{(j)} \odot \tilde p_i^{(j)}+(1-g_i^{(j)})\odot \hat p_i^{(j)} pi(j)=gi(j)⊙p~i(j)+(1−gi(j))⊙p^i(j)
⊙ \odot ⊙是逐个元素点积运算。相似与普通的k-sentence阅读器,我们使用CRF层在顶部进行特征融合,每一个token将被融入段落 { p 1 ( 1 ) , . . . , p l 1 ( 1 ) , . . . , p l k ( k ) , . . . , p l k ( k ) } \{ p_1^{(1)},..., p_{l_1}^{(1)},...,p_{l_k}^{(k)},...,p_{l_k}^{(k)}\} {p1(1),...,pl1(1),...,plk(k),...,plk(k)},能够帮助联合建模段落中标记之间的决策标记。
4、实验和分析
我们在MUC4事件提取基准上评估了模型的性能,并与之前的工作进行了比较。我们还报告了上下文长度对端到端阅读器在该文档级任务中表现的影响的研究结果。
4.1 数据集和评价指标
MUC-4 Event Extraction Dataset
Evaluation Metrics:Precision、Recall、F-measure(F-1)
4.2 基准系统和我们的系统
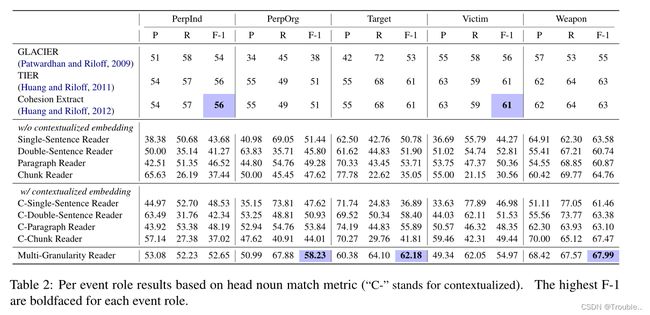
为了研究神经模型如何在可变长度(单句、双句、段落或更长)的上下文中捕获长依赖性,我们将 k k k中的 k k k句子读取器初始化为不同的值,以构建:单句读取器( k = 1 k=1 k=1),该读取器逐句阅读文档以提取事件角色填充符;双句子阅读器( k = 2 k=2 k=2),它以两个句子的步长阅读文档;段落阅读器( k k k为段落中的句子数),逐段阅读文档;块读取器( k k k合预训练LM模型长度约束的最大句子数),它以最长的步长(BERT模型的约束)读取文档。
表1和表2的结果展示了**多细粒度阅读器(Multi-Granularity Reader)**的实验效果。和段落级阅读器相似,它逐段阅读文档,但是学习句子内和句子间的上下文表示。
4.3 结果和发现
从表1和表2的结果,我们发现了以下特点:
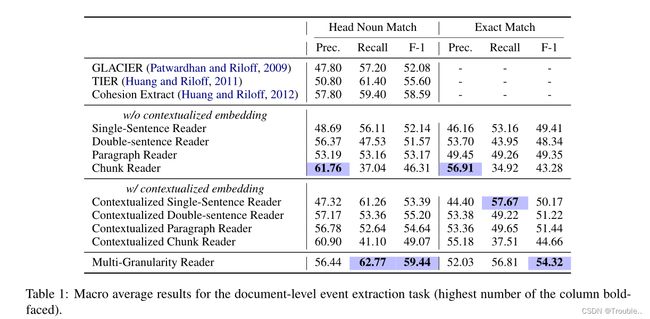
- 端到端的神经网络读取器可以实现与管道系统几乎相同的水平或显著更好的结果。尽管我们的模型不依赖于手工设计的特征,但根据头部-名词匹配度量,与内聚提取(CE)相比,上下文化双句读取器和段落读取器达到了几乎相同的F-1水平。我们的多粒度阅读器性能明显更好(接近60)比现有技术更高。
- 序列的上下文嵌入始终提高了神经网络阅读器的性能。结果表明,语境化的k-sentence阅读器都优于非语境化的阅读器,尤其是当 k > 1 k>1 k>1时。这些趋势也表现在每事件角色分析中(表2)。值得注意的是,我们在训练期间冻结了transformer的参数(微调会产生更糟糕的结果)。
- 建模较长的上下文不会产生更好的神经网络序列标注在文档级任务上。当将输入上下文从一个句子增加到两个句子时,阅读器的准确度更好,召回率更低,导致没有更好的F-1;当输入上下文长度进一步增加到整个段落时,准确度增加,召回率保持不变,导致F-1更高;当我们不断增加输入上下文的长度时,阅读器变得更加保守,F-1显著下降。所有这些都表明,关注局部(句内)和更广泛(段落级)的上下文对这项任务都很重要。关于上下文长度的类似结果也在文档级共指解析中发现)。
- 我们的多粒度阅读器动态地结合了句子级和段落级的上下文信息,在macro average F-1指标上,它的性能明显优于非端到端系统和我们的基本k-sentence阅读器。就每一个事件角色表现而言,我们的阅读器:(1) substantially outperforms CE with a ∼ 7 F-1 gap on the
PERPETRATOR ORGANIZATION role; (2) slightly outperforms CE (∼1 on the Target category); (3) achieves nearly the same-level of F-1 for PERPETRATOR INDIVIDUAL and
worse F-1 on VICTIM category.
5、更长远的分析
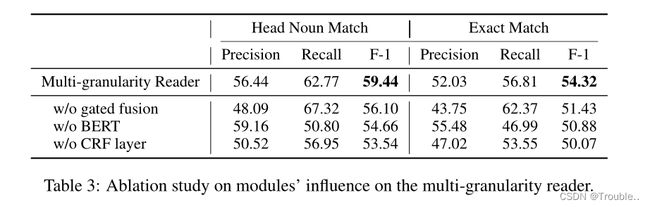
我们对多粒度阅读器的模型如何影响文档及抽取任务的性能进行了消融实验,如表3所示。结果发现:(1)当使用简单的操作来代替门控机制的融合操作,对句子级和段落级表征融合,那么precision和F-1将会下降特别快。(2)当去除BERT的上下文表征,这个模型将变得更加保守,产生的recall和F-1显著降低。(3)当替换CRF层并对每一个token做出独立的标注时,precision和recall都会显著下降。
6、总结
我们已经证明,使用端到端的神经序列模型可以成功地解决文档级事件角色填充提取问题。对输入上下文长度如何影响神经序列阅读器性能的研究表明,很长长度的上下文可能很难被神经模型捕获,并导致较低的性能。我们提出了一种新颖的多粒度阅读器,以动态地结合段落和句子级别的上下文表示。对基准数据集的评估和定性分析证明,我们的模型比以前的工作有了实质性的改进。在未来的工作中,我们将有兴趣进一步探索该模型如何适用于联合提取角色填充、处理相关提及和构建事件模板。
文长度如何影响神经序列阅读器性能的研究表明,很长长度的上下文可能很难被神经模型捕获,并导致较低的性能。我们提出了一种新颖的多粒度阅读器,以动态地结合段落和句子级别的上下文表示。对基准数据集的评估和定性分析证明,我们的模型比以前的工作有了实质性的改进。在未来的工作中,我们将有兴趣进一步探索该模型如何适用于联合提取角色填充、处理相关提及和构建事件模板。