Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Encoding阅读笔记
Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Encoding阅读笔记
- Purpose
- Background
- Methods
-
- Constructing Paired Token-tag Sequences from Documents and Gold Role Fillers
- k-sentence Reader
- Multi-Granularity Reader
- Results
- Conclusions
Purpose
作者首先研究了端到端神经网络模型如何在文档级的角色抽取上执行,以及上下文长度对模型性能的影响。为了动态聚合在不同粒度的信息(句子级、段落级),作者提出了一个新的多粒度阅读器。
Background
给定一篇由多个段落和句子组成的文章,一组预定义的事件类型和相关角色,作者的目标是识别文本中描述的每个事件对应的角色的文本范围,这通常需要句子层面的理解,以及上下文的精确解释。
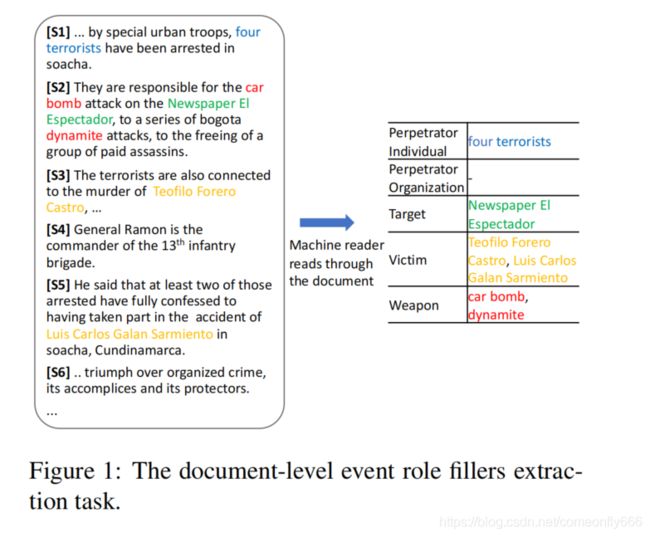
比如,识别 “Teofifilo Forero Castro”(S3)为car bomb attack(S2)中的victim,确定S4中不存在角色(这两个都主要依赖于句子级的理解),识别“four terrorists”(S1)为perpetrator individual(需要跨句子边界的关联解析)。
近期关于文档级事件角色抽取使用了pipeline架构,针对每个角色和相关上下文检测使用单独的分类器。然而这些方法在不同的阶段存在错误传递,并且严重依赖特征工程,此外,这些特征是针对特定领域的,需要语感和专家知识。
神经网络端到端模型在句子级的信息抽取任务中表现出色,但是之前没有研究将文档级事件角色提取作为端到端神经序列学习任务。首先,长序列中的长期依赖性是循环神经网络中一个很大的挑战。另外,即使使用BERT等模型适当减轻了长期依赖的影响,它们在序列的最大长度上仍有限制,少于大部分的关于事件的文章。
Methods
作者首先将问题转化为针对文档中的一系列连续句子上的序列标注任务,为了解决现有方法存在的问题,作者研究了上下文长度(即最大输入长度)对模型性能的影响,寻找最合适的长度。作者还提出了一个多粒度阅读器,能够动态聚合本地上下文(如句子级)和更广泛的上下文(如段落级)中学习到的信息。
Constructing Paired Token-tag Sequences from Documents and Gold Role Fillers
作者引入BIO(Beginning, Inside, Outside)标注模式,给定一个文档和每个角色的正确标注。
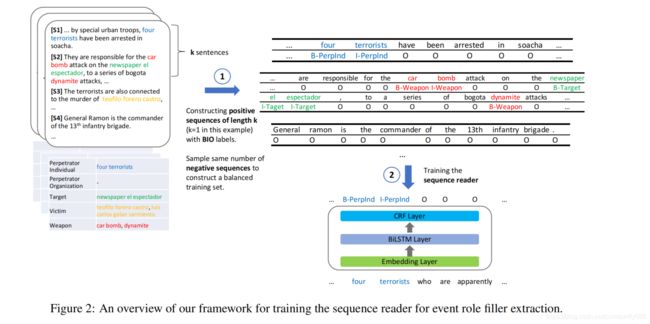
作者构造不同上下文长度的示例序列训练和测试端到端k-sentence阅读器(即单句,双句,段落和块阅读器)。这里的“块”是指符合BERT序列长度约束(512)的句子块。使用一个句子拆分器将文档分为句子s1,s2,…sn。
构造训练集时,从每个句子i开始,将k个连续句子连接起来,形成长度为k的重叠候选序列,即序列1为{s1,…sk},序列2为{s2,…sk+1}。为了使训练集平衡,作者从候选序列中采样相同数量的正序列和负序列,其中“正”序列包含至少一个事件角色,而“负”序列不包含事件角色。
构造验证集时,将连续k个句子组合在一起,生成 n k \frac{n}{k} kn个序列,即序列1为{s1,…sk},序列2为{sk+1,…s2k}。
对于段落阅读器,在训练集中,k为平均段落长度,在测试集中,k为真实段落长度。
k-sentence阅读器的输入为X = { x 1 ( 1 ) x_1^{(1)} x1(1), x 2 ( 1 ) x_2^{(1)} x2(1),…, x l 1 ( 1 ) x_{l_{1}}^{(1)} xl1(1),…, x 1 ( k ) x_1^{(k)} x1(k), x 2 ( k ) x_2^{(k)} x2(k),…, x l k ( k ) x_{l_{k}}^{(k)} xlk(k)},其中 x i ( k ) x_i^{(k)} xi(k)是第k句的第i个token, l k l_k lk是第k句的长度。
k-sentence Reader
由于k-sentence阅读器不能识别句子边界,作者将输入句子简化为{ x 1 x_1 x1, x 2 x_2 x2, …, x m x_m xm}。
嵌入层
在嵌入层,作者将输入句子的每个token表示为其本身的词嵌入与上下文表示的连接。
词嵌入:使用100维Glove预训练模型,对于给定的一个token x i x_i xi,x e i e_i ei = E( x i x_i xi)。
预训练LM表示:研究证明,预训练语言模型产生的上下文嵌入能够在句子边界之外建模,提升一系列任务的性能。这里作者使用了BERT-base作为预训练模型,使用12层表示的平均值。对于给定的{ x 1 x_1 x1, x 2 x_2 x2, …, x m x_m xm}序列:
x b 1 b_1 b1, x b 2 b_2 b2,…, x b m b_m bm = BERT( x 1 x_1 x1, x 2 x_2 x2, …, x m x_m xm)
连接后每个token为 x i x_i xi = concat(x e i e_i ei, x b i b_i bi)
BiLSTM层
为了帮助模型更好的捕获序列token之间特定于抽取任务的特征,使用一个3层BiLSTM编码器:
{ p 1 p_1 p1, p 2 p_2 p2, …, p m p_m pm} = BiLSTM({ x 1 x_1 x1, x 2 x_2 x2, …, x m x_m xm})
CRF层
基于联合的方式对标注决策进行建模能够获得更好的性能(如"I-Weapon"不应该在"B-Victim"后面),作者使用了CRF进行联合标注决策建模。
{ p 1 p_1 p1, p 2 p_2 p2, …, p m p_m pm} 经过线性层之后,获得大小为m × 标注种类的矩阵P,其中 P i , j P_{i,j} Pi,j代表第i个token在标注j上的得分。对于一个标注序列{ y 1 y_1 y1, y 2 y_2 y2, …, y m y_m ym}:
score(X,y) = ∑ i = 0 m A y i , y i + 1 \sum_{i = 0}^{m}A_{y_i,y_{i+1}} ∑i=0mAyi,yi+1 + ∑ i = 1 m P i , y i \sum_{i = 1}^{m}P_{i,y_i} ∑i=1mPi,yi
其中A是得分矩阵的转移矩阵, A i , j A_{i,j} Ai,j表示从标注j到标注i的转移得分。在所有可能的标注序列得分上应用一个softmax函数,从而产生正确序列的可能。在训练过程中,最大化正确标注序列的可能性。
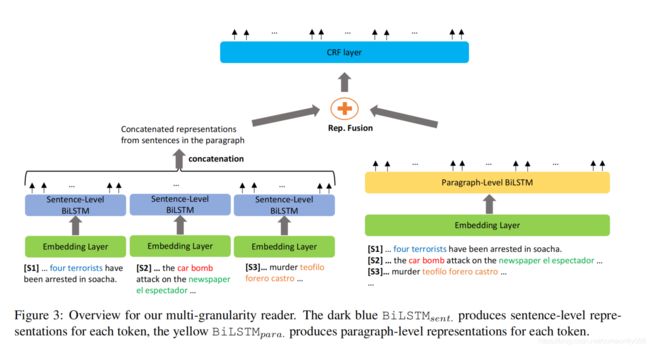
Multi-Granularity Reader
为了探索聚合不同粒度的上下文token表示(句子级和段落级),作者提出了多粒度阅读器。
与k-sentence阅读器相似,作者使用相同的嵌入层表示token,但将其应用于两个粒度。词向量在不同粒度时相同,上下文表示却不同。
相应的,作者在句子级上下文表示和段落级上下文表示上,建立了两个BiLSTM( B i L S T M s e n t BiLSTM_{sent} BiLSTMsent和 B i L S T M p a r a BiLSTM_{para} BiLSTMpara)
Sentence-Level BiLSTM
B i L S T M s e n t BiLSTM_{sent} BiLSTMsent针对段落中的每个句子:
{ p ~ 1 ( 1 ) \tilde{p}_{1}^{(1)} p~1(1), p ~ 2 ( 1 ) \tilde{p}_{2}^{(1)} p~2(1), …, p ~ l 1 ( 1 ) \tilde{p}_{l_1}^{(1)} p~l1(1)} = B i L S T M s e n t BiLSTM_{sent} BiLSTMsent({ x ~ 1 ( 1 ) \tilde{x}_{1}^{(1)} x~1(1), x ~ 2 ( 1 ) \tilde{x}_{2}^{(1)} x~2(1), …, x ~ l 1 ( 1 ) \tilde{x}_{l_1}^{(1)} x~l1(1)})
···
{ p ~ 1 ( k ) \tilde{p}_{1}^{(k)} p~1(k), p ~ 2 ( k ) \tilde{p}_{2}^{(k)} p~2(k), …, p ~ l k ( k ) \tilde{p}_{l_k}^{(k)} p~lk(k)} = B i L S T M s e n t BiLSTM_{sent} BiLSTMsent({ x ~ 1 ( k ) \tilde{x}_{1}^{(k)} x~1(k), x ~ 2 ( k ) \tilde{x}_{2}^{(k)} x~2(k), …, x ~ l k ( k ) \tilde{x}_{l_k}^{(k)} x~lk(k)})
最终获得段落中每一个token的句子级表示{ p ~ 1 ( 1 ) \tilde{p}_{1}^{(1)} p~1(1),…, p ~ l 1 ( 1 ) \tilde{p}_{l_1}^{(1)} p~l1(1), …, p ~ 1 ( k ) \tilde{p}_{1}^{(k)} p~1(k),…, p ~ l k ( k ) \tilde{p}_{l_k}^{(k)} p~lk(k)}
Paragraph-Level BiLSTM
B i L S T M p a r a BiLSTM_{para} BiLSTMpara针对完整的段落,捕获tokens之间的依赖性:
{ p ^ 1 ( 1 ) \hat{p}_{1}^{(1)} p^1(1),…, p ^ l 1 ( 1 ) \hat{p}_{l_1}^{(1)} p^l1(1), …, p ^ 1 ( k ) \hat{p}_{1}^{(k)} p^1(k),…, p ^ l k ( k ) \hat{p}_{l_k}^{(k)} p^lk(k)} = B i L S T M p a r a BiLSTM_{para} BiLSTMpara({ x ^ 1 ( 1 ) \hat{x}_{1}^{(1)} x^1(1),…, x ^ l 1 ( 1 ) \hat{x}_{l_1}^{(1)} x^l1(1), …, x ^ 1 ( k ) \hat{x}_{1}^{(k)} x^1(k),…, x ^ l k ( k ) \hat{x}_{l_k}^{(k)} x^lk(k)})
Fusion and Inference Layer
对每个token x i ( k ) x_i^{(k)} xi(k)(第k个句子中的第i个token),为了融合句子层面( p ~ i ( k ) \tilde{p}_{i}^{(k)} p~i(k))和段落层面( p ^ i ( k ) \hat{p}_{i}^{(k)} p^i(k))学习到的表示,作者进行了两种操作:
-
简单求和: p i ( k ) p_i^{(k)} pi(k) = p ~ i ( k ) \tilde{p}_{i}^{(k)} p~i(k) + p ^ i ( k ) \hat{p}_{i}^{(k)} p^i(k)
-
门控制融合:控制从两个表示中获得多少信息。
g i ( k ) = sigmoid ( W 1 p ~ i ( k ) + W 2 p ^ i ( k ) + b ) \mathbf{g}_{i}^{(k)}=\operatorname{sigmoid}\left(\mathbf{W}_{1} \tilde{\mathbf{p}}_{i}^{(k)}+\mathbf{W}_{2} \hat{\mathbf{p}}_{i}^{(k)}+b\right) gi(k)=sigmoid(W1p~i(k)+W2p^i(k)+b)
p i ( k ) = g i ( k ) ⊙ p ~ i ( k ) + ( 1 − g i ( k ) ) ⊙ p ^ i ( k ) \mathbf{p}_{i}^{(k)}=\mathbf{g}_{i}^{(k)} \odot \tilde{\mathbf{p}}_{i}^{(k)}+\left(1-\mathbf{g}_{i}^{(k)}\right) \odot \hat{\mathbf{p}}_{i}^{(k)} pi(k)=gi(k)⊙p~i(k)+(1−gi(k))⊙p^i(k)其中 ⊙ \odot ⊙表示点乘
{\mathbf{p}}{i}{(k)}+\left(1-\mathbf{g}_{i}{(k)}\right) \odot \hat{\mathbf{p}}{i}^{(k)}$
其中 ⊙ \odot ⊙表示点乘
与k-sentence阅读器相似,作者在融合表示之上为段落中每个token引入了CRF层。
Results
数据集采用MUC-4,包括1700个带有相关角色的文档,使用head noun phrase match比较结果,使用精确匹配的准确率了解模型对角色边界的识别效果。
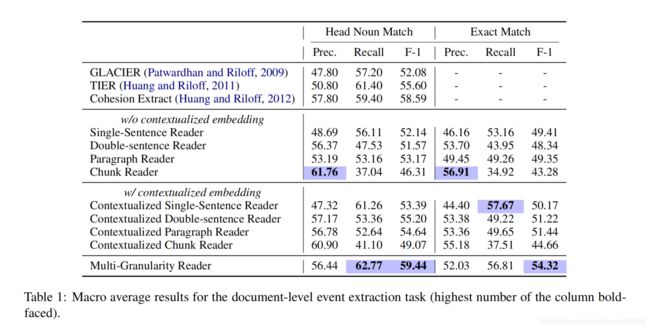
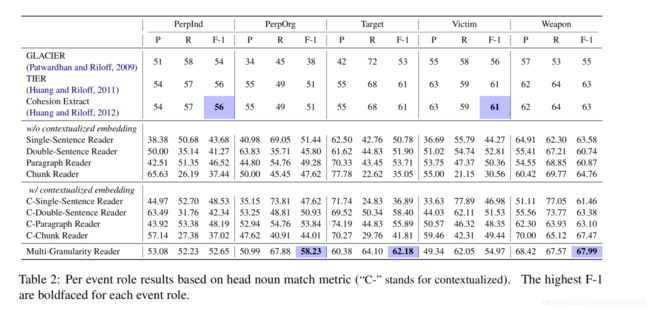
端到端模型能够达到甚至超越pipeline模型的性能。尽管作者的模型不依赖于人工设计的特征,contextualized 双句阅读器和段落阅读器在头名词匹配上达到与CE相同的分数,多粒度阅读器达到了接近60的F1分数。结果表明,序列上下文嵌入提高神经网络阅读器的性能。在文档级任务上,并不是越长的上下文会有越好的标注模型,对此任务来说,关注句间上下文和段落级的上下文同等重要。

设置消融实验,去除门控融合证明了动态组合上下文的重要性;去除BERT后召回率和F1都显著下降;替换掉CRF层对每个token独立标注决策时精确率和召回率都显著下降。
Conclusions
作者证明文档级事件角色抽取任务可以使用端到端神经网络序列模型解决,通过研究输入上下文长度对神经网络序列阅读器的影响,如果长度太长,可能会难以捕获,造成性能下降。作者提出了新的多粒度阅读器,动态组合段落级和句子级上下文表示。在benchmark数据集上的评估和分析证明了作者模型比之前的工作有了很大的改进。
在未来工作中,将进一步探索模型如何应用到联合抽取、处理共引用及构建事件模板上。