论文笔记 ACL 2020|Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Enc
文章目录
-
- 1 简介
-
- 1.1 动机
- 1.2 创新
- 2 背景知识
-
- 2.1 句子级事件抽取
- 2.2 文档级事件抽取
- 3 方法
-
- 3.1 构建token-tag序列
- 3.2 k个句子阅读器
- 3.3 多粒度阅读器
- 4 实验
- 5 总结
1 简介
论文题目:Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Encoding
论文来源:ACL 2020
论文链接:https://arxiv.org/pdf/2005.06579.pdf
代码链接:https://github.com/xinyadu/doc_event_role
1.1 动机
- 以前的文档级事件角色填充抽取使用管道结构,遭受错误传播和需要巨大的特征工程。
- 基于神经序列学习模型的文档级事件提取,有一个挑战:捕捉长依赖。
1.2 创新
- 第一个使用端到端的深度序列模型,进行文档级角色填充抽取。
- 提出一个多粒度阅读器可以动态聚合从本地上下文(如句子级别)和更广泛的上下文(如段落级别)中学到的信息。
2 背景知识
事件抽取主要研究在两个范式下:检测事件触发词和抽取论元从一个句子中(ACE 任务)、在文档级别中(MUC-4 template-filling 任务)。
2.1 句子级事件抽取
ACE事件抽取任务,从一个句子中抽取事件触发词和论元。
2.2 文档级事件抽取
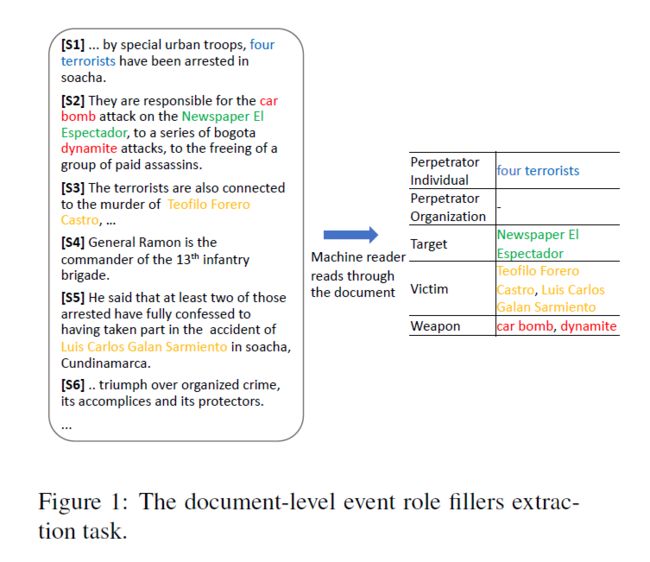
文档级事件抽取主要研究在MUC任务中,整个任务包括构建答案模板,每个事件一个模板(数据集中的一些文档描述了多个事件)。通常包括三部分:角色填充抽取、名词短语共指消解和事件追踪(判断抽取的论元属于文档中的哪个事件)。下图为角色填充抽取的一个例子。
3 方法
模型分为下面三部分,模型结构如下图。
- 将文档转换为成对的token-tag序列和将该任务定义为序列标注任务
- k个句子阅读器的结构
- 多个粒度的阅读
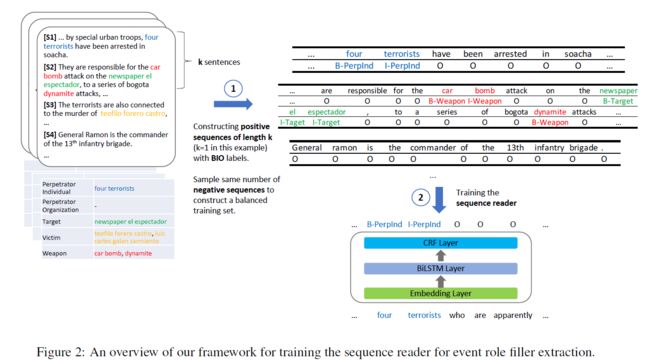
3.1 构建token-tag序列
使用BIO标注策略,将文档转换为成对的token/BIO-tag序列。
在训练集中,从句子i开始,合并k个连续的句子,形成长度为k的重叠候补序列。(如第一个序列包括 { s 1 , . . . , s k } \{s_1,...,s_k\} {s1,...,sk},第二个包括 { s 2 , . . . , s k + 1 } \{s_2,...,s_{k+1}\} {s2,...,sk+1})。为了保证训练集平衡,从候选序列中取样相同数量的正例和负例。正例至少包括一个事件角色填充,负例不包含事件角色填充。
在验证集和测试集中,按顺序对k个连续的句子进行分组,生成 n k \frac nk kn个序列。(如第一个序列包括 { s 1 , . . . , s k } \{s_1,...,s_k\} {s1,...,sk},第二个包括 { s k + 1 , . . . , s 2 k } \{s_k+1,...,s_{2k}\} {sk+1,...,s2k})。
用x表示序列中的token,k句子阅读器的输入为 X = { x 1 ( 1 ) , x 2 ( 1 ) , . . . , x l 1 ( 1 ) , . . . , x 1 ( k ) , x 2 ( k ) , . . . , x l k ( k ) } {X=\{x_1^{(1)},x_2^{(1)},...,x_{l_1}^{(1)},...,x_1^{(k)},x_2^{(k)},...,x_{l_k}^{(k)}\}} X={x1(1),x2(1),...,xl1(1),...,x1(k),x2(k),...,xlk(k)},其中 x i ( k ) x_i^{(k)} xi(k)为第k个句子的第i个token, l k l_k lk为第k个句子的长度。
3.2 k个句子阅读器
token的编码由词编码和上下文token表示两部分组成, x i = c o n c a t ( x e i , x b i ) x_i=concat(xe_i,xb_i) xi=concat(xei,xbi)
- 使用Glove词编码, x e i = E ( x i ) xe_i=E(x_i) xei=E(xi)
- 使用BERT的12层表示的平均值作为上下文表示, x b 1 , x b 2 , . . . , x b m = B E R T ( x 1 , x 2 , . . . , x m ) xb_1,xb_2,...,xb_m=BERT(x_1,x_2,...,x_m) xb1,xb2,...,xbm=BERT(x1,x2,...,xm)
为了帮助模型在序列的token中更好地捕捉具体任务的特征,使用3层双向LSTM进行编码。
{ p 1 , p 2 , . . . , p m } = B i L S T M ( { x 1 , x 2 , . . . , x m } ) \{p_1,p_2,...,p_m\}=BiLSTM(\{x_1,x_2,...,x_m\}) {p1,p2,...,pm}=BiLSTM({x1,x2,...,xm})
之后, { p 1 , p 2 , . . . , p m } \{p_1,p_2,...,p_m\} {p1,p2,...,pm}通过一个线性层,然后使用条件随机场对标签进行联合决策,公式如下
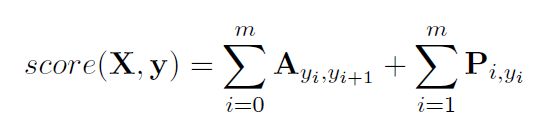
3.3 多粒度阅读器
为了探索不同粒度(句子级别和段落级别)对聚合上下文token表示的影响,提出多粒度阅读器如下图。
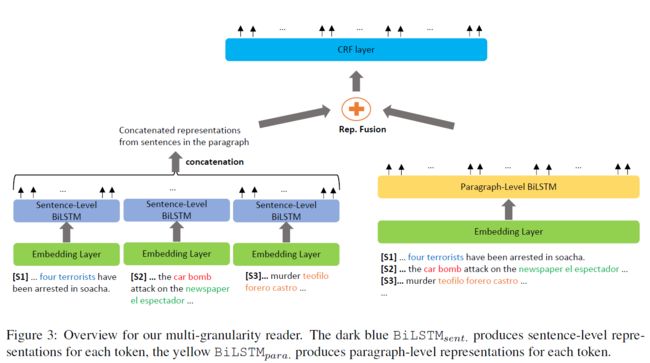
对于不同的粒度词编码是一样的,但是对于每个token上下文表示是不同的。相对的,构建两个BiLSTMs( B i L S T M s e n t BiLSTM_{sent} BiLSTMsent和 B i L S T M p a r a BiLSTM_{para} BiLSTMpara)。
句子级别的BiLSTM是 B i L S T M s e n t BiLSTM_{sent} BiLSTMsent按顺序应用到段落中的每个句子,公式如下:
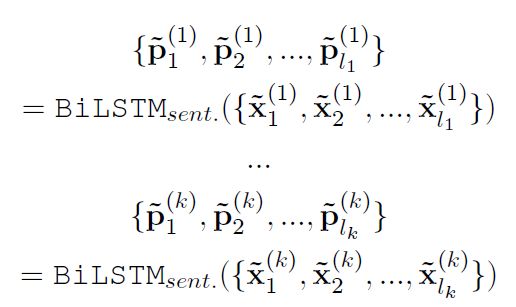
段落级别的BiLSTM为 B i L S T M p a r a BiLSTM_{para} BiLSTMpara应用到整个段落上,公式如下。
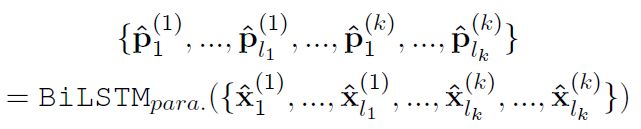
对于每个token,使用下面两种方法,合并从句子级别 ( p ~ i ( j ) ) (\widetilde{p}_i^{(j)}) (p i(j))和段落级别 ( p ^ i ( j ) ) (\widehat{p}_i^{(j)}) (p i(j))学习到的表示
- 相加: p i ( j ) = p ~ i ( j ) + p ^ i ( j ) p_i^{(j)}=\widetilde{p}_i^{(j)}+\widehat{p}_i^{(j)} pi(j)=p i(j)+p i(j)
- 门控合并:使用向量控制两种表示中的多少信息应该被合并,公式如下:
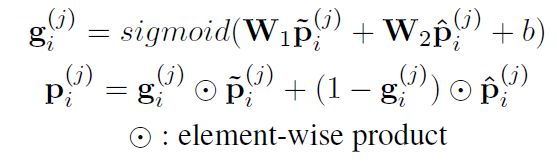
最后类似k句子阅读器,在段使用条件随机场对段落中的标签进行联合决策。
4 实验
使用MUC-4事件抽取数据集评测模型的表现,为了比较以前的结果,使用head noun phrase match评估抽取的结果,实验结果如下。
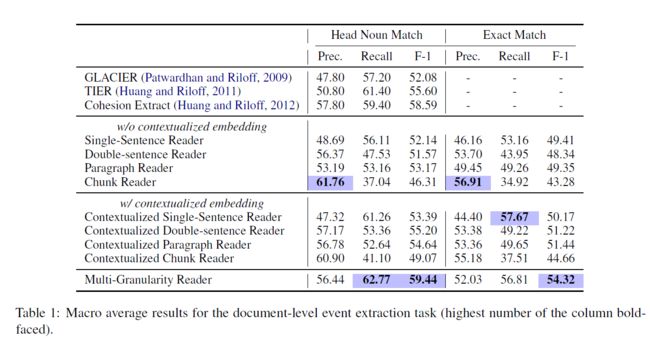
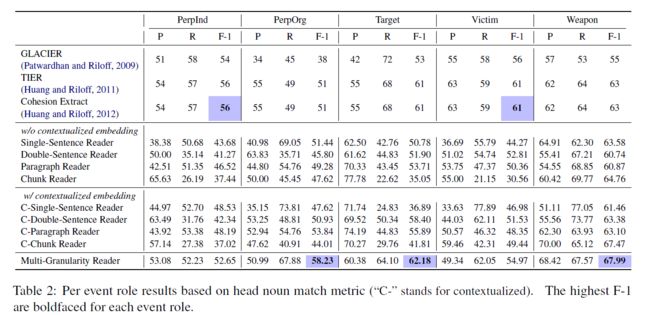
每个事件角色的实验结果如下:
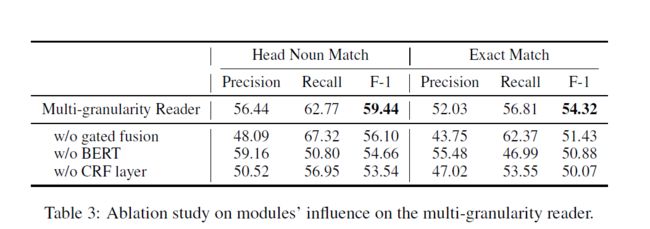
设置消融实验,探索模型中各个模块对文件级别抽取任务的影响,实验结果如下。
5 总结
- 提出一个多粒度阅读器可以动态聚合段落级别和句子级别的上下文表示。
- 探索上下文长度对神经序列阅读器性能的影响,得出结论:对于神经模型来说,很长的上下文可能很难捕获,并导致性能降低。